一种基于粗糙集约简的图像插值方法与流程
本发明涉及图像处理领域,具体地说涉及一种基于粗糙集约简的图像插值方法。
背景技术:
:
图像插值是利用图像相邻像素之间的相关性,根据相邻的已知像素的灰度值估计未知像素的灰度值的过程。图像插值能够实现对图像的缩放、旋转、图像配准、三维图像重建,便于在不同分辨率的数字设备上传输、处理、输出图像,已被广泛应用于视频处理、医学、军事、通讯等领域。
传统的图像插值方法包括最邻近插值、双线性插值、三次立方插值等,此类方法实现简单,运算速度快,对于灰度变化平滑的区域能获得较好的视觉效果,但无法体现图像中灰度值剧烈跳变的局部特征,导致放大的图像边缘模糊。
图像的边缘包含很多重要信息,消除图像的边缘模糊现象是图像插值技术的关键。各种以消除图像的边缘模糊现象,获取高质量插值图像的方法被相继提出,其中基于学习的插值方法受到了诸多学者的关注。如,王珏等人在文章“基于支持向量机的图象插值及错误隐匿策略”(中国图像图形学报,2002,7(A版)(6):558-564)中利用待插值像素点周围的24个已知像素作为输入样本,取得了满意的插值效果,但样本构造的过程中没有充分利用像素之间的相关性且样本中的特征较多,会影响支持向量机的训练时间。又如,郑胜等人在文章“基于向量机的图像插值算法研究”(中国图像图形学报,2005,10(3):338-343)中利用未知像素点周围的4×4区域的已知像素灰度值作为最小二乘向量机的输入,实现对未知像素的灰度值估计,该算法具有较高的插值效率,但插值精度不高。再如L.Y.Ma等在文章“LocalSpatialPropertiesBasedImageInterpolation SchemeUsingSVMs”(JournalofSystemsEngineeringandElectronics,2008,19(3):618-623)中提出了基于局部空间属性的支持向量机(LPSVM)图像插值算法,该方法利用14维向量作为输入样本,较前两种插值方法取得了更好的插值精度。
专利“基于支持向量机的图像插值算法”(申请号:200610156538.7,公开号:CN101059867)中公开了一种基于周围最邻近6个已知像素区域的图像插值方法,利用选定区域的已知像素的灰度值、灰度平均值及灰度差值构造的14维向量作为输入样本训练支持向量机,然后用训练好的支持向量机先估计行扩展出的未知像素灰度值,然后再估计列扩展出的未知像素灰度值。该方法考虑了像素间的相关性,但插值效率有待提高,还不能满足多种有高准确度要求的应用场合。
总之,现有基于支持向量机的图像插值算法的共有弊端有两个方面,一方面是精度不够高,另一方面是输入样本所含的特征较多、维数较高,导致支持向量机的训练时间增长。
技术实现要素:
:
本发明的目的在于克服现有技术的不足,提供一种利用粗糙集约简样本特征的图像插值方法。
为了解决背景技术所存在的问题,本发明采用以下技术方案:
一种基于粗糙集约简的图像插值方法,它包括如下步骤:
(1)输入待处理图像;
(2)利用已知图像上的像素灰度值构造训练样本集:
构造训练样本集X={X1,X2,…,Xn},其训练样本Xi={x1,x2,…,x11,Y},i=1,…,n,其中输入样本x1,x2,…,x11为11维向量,输出样本Y为1维向量;
(3)利用粗集约简算法约简训练样本集的特征;
(4)利用约简后的训练样本集训练支持向量机,得到预测模型;
(5)利用测试样本及训练好的支持向量机估计偶行偶列的像素灰度值,即进行第一遍插值:
构造插值偶行偶列的像素灰度值的测试样本;
估计偶行偶列的像素灰度值;
(6)利用测试样本及训练好的支持向量机估计偶行奇列和奇行偶列的像素灰度值,即进行第二遍插值;
(7)输出放大图像。
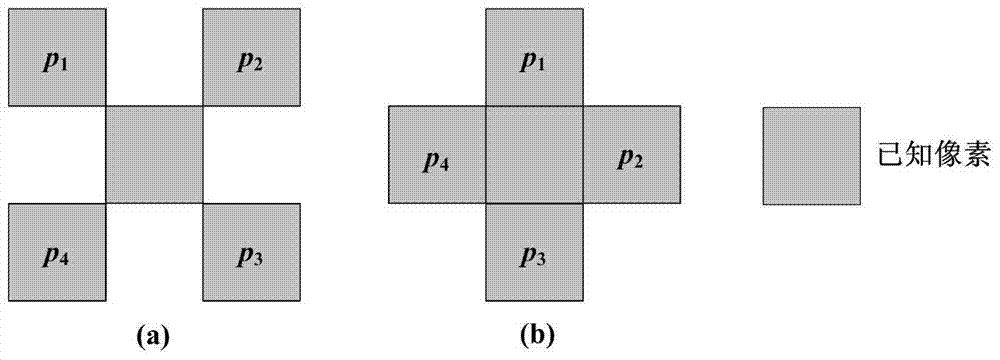
进一步的,所述的步骤(2)构造训练样本集:在原图上,以每个像素为中心点,在其周围的3×3区域内构造训练模式,然后分别利用两个训练模式构造两个训练样本;
两个训练样本的输出样本Y均为所选区域的中心像素的灰度值,输入样本x1,x2,…,x11均是利用中心点周围的四个已知像素构造的11维向量;11维向量包括所选区域中的4个已知像素的灰度值pi,i=1,2,3,4,4个已知像素的灰度平均值,4个已知像素两两之间的灰度值之差di,i=1,...,6,和di的计算公式分别为:
d1=p1-p2
d2=p1-p3
d3=p1-p4
d4=p2-p3
d5=p2-p4
d6=p3-p4
进一步的,所述的步骤(3)中的粗集约简算法,其步骤如下:
对样本集X={X1,X2,…,Xn},A=C∪D是属性集合,其中C是条件属性集合,即输入样本的集合,D是决策属性集合,即输出样本的集合,采用基于属性重要度的粗糙集约减算法,对样本的条件属性C进行属性约简,可以获得约简集reductX(C);
统计约简集reductX(C)出现的频率f,约简出现的频率越高,该约简就越稳定,泛化能力越强;
最终约简输出B取所有属于reductX(C)的约简出现的频率最高的,即
进一步的,所述的步骤(5)中的第一遍插值:
根据插值模式构造测试样本X'={x1',x2',…,x11',Y'},其输入样本x1',x2',…,x11'为11维向量,与训练样本的输入样本的构造方式相同,输出样本Y'为待估计的像素灰度值,即支持向量机的输出;
利用测试样本及步骤(4)中训练好的支持向量机估计出插值模式的中心像素灰度值,即可估计出所有偶行偶列的像素灰度值。
进一步的,所述的步骤(6)中的第二遍插值:
根据插值模式构造插值偶行奇列的测试样本,其输入样本是利用中心点上下的2个已知像素p1和p3,及左右的2个插值出的像素p^2和p^4构造的11维向量,左右的2个像素是步骤5中插值出的偶行偶列的像素灰度值;根据插值模式构造插值奇行偶列的测试样本,其输入样本是利用中心点左右的2个已知像素p2和p4,及上下的2个插值出的像素p^1和p^3构造的11维向量,上下的2个像素是步骤5中插值出的偶行偶列的像素灰度值;
利用测试样本及步骤(4)中训练好的支持向量机,分别估计出偶行奇列插值模式和奇行偶列插值模式的中心像素灰度值,即可估计出所有偶行奇列和奇行偶列的像素灰度值。
本发明对比现有技术有如下的有益效果:本方法简单,能实现对图像的放大,解决放大图像边缘模糊的问题,获取高质量的插值图像。
附图说明:
图1为本发明方法流程图。
图2为本发明训练模式图。
图3为插值模式:
(a)偶行偶列,(b)偶行奇列,(c)奇行偶列。
图4为插值结果:(a)标准图像,(b)LPSVM插值结果,(c)LPSVM插值结果的残差图像,(d)原始图像,(e)本发明插值结果,(f)本发明插值结果的残差图像。
具体实施方式:
下面结合附图,对本发明作进一步详细描述:
图1为本发明方法流程图,一种利用粗糙集约简样本特征的图像插值方法,它包括如下步骤:
(1)输入待处理图像;
(2)利用已知图像上的像素灰度值构造训练样本集:
构造训练样本集X={X1,X2,…,Xn},其训练样本Xi={x1,x2,…,x11,Y},i=1,…,n,其中输入样本x1,x2,…,x11为11维向量,输出样本Y为1维向量;
(3)利用粗集约简算法约简训练样本集的特征;
(4)利用约简后的训练样本集训练支持向量机,得到预测模型;
(5)利用测试样本及训练好的支持向量机估计偶行偶列的像素灰度值,即进行第一遍插值:
构造插值偶行偶列的像素灰度值的测试样本;
估计偶行偶列的像素灰度值;
(6)利用测试样本及训练好的支持向量机估计偶行奇列和奇行偶列的像素灰度值,即进行第二遍插值;
(7)输出放大图像。
详细步骤如下:
步骤1:输入一幅待放大的图像
步骤2:构造训练样本集X={X1,X2,…,Xn},其训练样本Xi={x1,x2,…,x11,Y},i=1,…,n,其中输入样本x1,x2,…,x11为11维向量,输出样本Y为1维向量;
训练样本的构造:在原图上,以每个像素为中心点,在其周围的3×3区域内构造图2所示的训练模式,然后分别利用图2中的两个训练模式构造两个训练样本。
两个训练样本的输出样本Y均为所选区域的中心像素的灰度值,输入样本x1,x2,…,x11均是利用中心点周围的四个已知像素构造的11维向量。11维向量包括所选区域中的4个已知像素的灰度值pi,i=1,2,3,4,4个已知像素的灰度平均值,4个已知像素两两之间的灰度值之差di,i=1,...,6,和di的计算公式分别为:
d1=p1-p2
d2=p1-p3
d3=p1-p4
d4=p2-p3 (2)
d5=p2-p4
d6=p3-p4
按照上述方式,利用原图上的每一个像素作为输出样本,构造两个训练样本,将构造的所有样本组成训练样本集。
步骤3:利用粗糙集约简训练样本集中每个样本的输入特征
为了降低支持向量机的训练时间,提高插值效率,利用粗糙集将输入样本中重要度较小的特征约简掉。该算法记为粗集约简算法,其步骤如下:
(3a)对样本集X={X1,X2,…,Xn},A=C∪D是属性集合,其中C是条件属性集合,即输入样本的集合,D是决策属性集合,即输出样本的集合,采用基于属性重要度的粗糙集约减算法,对样本的条件属性C进行属性约简,可以获得约简集reductX(C);
(3b)统计约简集reductX(C)出现的频率f,约简出现的频率越高,该约简就越稳定,泛化能力越强;
(3c)最终约简输出B取所有属于reductX(C)的约简出现的频率最高的,即
步骤4:利用约简后的训练样本集训练支持向量机,得到预测模型
步骤5:进行第一遍插值,即插值偶行偶列的像素灰度值
(5a)根据图3(a)的插值模式构造测试样本X'={x1',x2',…,x11',Y'},其输入样本x1',x2',…,x11'为11维向量,与训练样本的输入样本的构造方式相同,输出样本Y'为待估计的像素灰度值,即支持向量机的输出
(5b)利用测试样本及步骤4中训练好的支持向量机估计出图3(a)的插值模式的中心像素灰度值,即可估计出所有偶行偶列的像素灰度值
步骤6:进行第二遍插值,即插值偶行奇列和奇行偶列的像素灰度值
(6a)根据图3(b)构造插值偶行奇列的测试样本,其输入样本是利用中心点上下的2个已知像素p1和p3,及左右的2个插值出的像素p^2和p^4(步骤5插值出的偶行偶列的像素灰度值)构造的11维向量;根据图3(c)构造插值奇行偶列的测试样本,其输入样本是利用中心点左右的2个已知像素p2和p4,及上下的2个插值出的像素p^1和p^3(步骤5插值出的偶行偶列的像素灰度值)构造的11维向量
(6b)利用测试样本及步骤4中训练好的支持向量机,分别估计出图3(b)和图3(c)的插值模式的中心像素灰度值,即可估计出所有偶行奇列和奇行偶列的像素灰度值
步骤7:输出放大图像
仿真验证:
采用Lin等开发的SVM软件工具箱(ALibraryforSupportVectorMachines,LIBSVM)在MATLABR2009b中仿真,选择γ-SVR,使用径向基函数RBF,其余参数采用默认设置。实验在Pentium(R)Dual-CoreCPUE54002.7GHz和2.00GB内存的PC机上进行。
对Lena、Cameraman和Peppers等多个分辨率为256×256的标准图像进行测试。首先将标准图像进行1/2欠采样,然后将缩小后的图像应用不同的插值方法进行扩展得到放大后的结果图像。再将不同方法获得的插值结果和标准图像进行主客观的比较。采用峰值信噪比(Peak Signal-to-noise Ration,PSNR)和规格化均方差NMSE(Normalized Mean Square Error,NMSE)对不同方法的插值结果进行客观评价,通过人眼观察的方式进行主观评价。
表1不同插值方法的插值结果比较
从表1可见,本发明的方法获得了最高的PSNR和最小的NMSE,不仅提高了客观指标,还大大降低了插值时间,提高了效率。
观察图4的插值结果,本发明的结果图像在Lena的肩部消除了锯齿现象,在帽子的顶部边缘也没有锯齿现象,从残差图像4(c)中可以看出,LPSVM的插值结果在Lena的肩部锯齿现象很明显。本发明的插值方法在保证处理效率的情况下大大提高了插值效果。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!