异构计算系统中的工作窃取的制作方法
本文包含的是受到版权保护的材料。当它出现在专利和商标局专利文件或记录中时,版权拥有者不反对任何人复制该专利公开,但无论如何在其它方面保留对版权的所有权利。
技术领域
本文描述的实施例一般涉及异构计算系统。具体地说,本文描述的实施例一般涉及异构计算系统中的工作窃取。
背景技术:
计算机除了部署为中央处理单元(CPU)的通用处理器之外还经常具有一个或多个硬件加速器装置。此类硬件加速器装置的一个广泛使用的示例是图形处理单元(GPU)。GPU传统上已经用作主要驱动一个或多个显示器的图形子系统的一部分。GPU帮助从CPU卸载工作,由此允许CPU资源用于其它任务。CPU通常实现为通用处理器,并且一般将适合于执行各种不同类型的算法(例如一般性质的处理)。相比之下,GPU经常实现为专用处理器或至少更专业化的处理器,其一般更适合于执行有限数量的专业化算法(例如图形相关算法)。GPU经常具有高度并行的计算硬件,其倾向于允许它们快速处理图形数据。
近来,已经认识到GPU可用于其它非图形应用。例如,GPU上的通用计算(GPGPU)一般表示利用GPU执行传统上已经预留用于CPU的类型的通用型计算。经常可采用GPU的高度并行计算硬件来显著地加速此类计算。当以这种方式使用时,至少当正确实现时,GPU可帮助显著加速计算密集应用。
然而,使用GPU加速非图形应用的一个挑战(例如在GPGPU的情况下)涉及工作调度。为了有效地利用CPU和GPU,重要的是在CPU与GPU之间以有效方式调度和分布工作。在一个可能方法中,CPU可以仅仅向GPU卸载或指配特定任务。CPU然后可等待或执行其它任务,而GPU完成指配的任务并提供结果。然而,在这种方法中,在处理相同工作负载时在CPU与GPU之间没有实际协作。也就是说,CPU和GPU可能不同时对相同工作负载的不同部分工作。它实际上不是混合执行。
根据另一方法,CPU和GPU可参与混合执行,其中它们对在CPU和GPU上静态调度的并行工作负载的不同部分协作地工作。此类混合执行可提供在相同工作负载上同时利用CPU和GPU的潜在优点。然而,倾向于有挑战的是有效地在CPU与GPU之间调度工作负载的不同部分。例如,CPU和GPU可以不同时钟速度操作,和/或可具有不同存储器层级,和/或可具有不同的基于工作负载的性能特性。可在CPU和GPU之一上有效地执行的代码可能没有在另一个上执行得那么有效。其它竞争的工作负载和/或功率约束的存在可进一步倾向于使先验有效地调度工作负载的能力复杂化。缺点是,如果工作负载未有效调度,则CPU和GPU之一可变得负担过度,而另一个可能利用不足。
附图说明
通过参考用于说明本发明实施例的如下描述和附图可最好地理解本发明。在附图中:
图1是异构计算或计算机系统的实施例的框图。
图2是同步工作窃取器系统的实施例的框图。
图3是在异构计算机系统中窃取工作的方法的实施例的流程框图。
图4是图示在CPU的实施例与GPU的实施例之间的双向同步工作窃取的实施例的框图。
图5是可使用同步工作窃取器系统的实施例的环境的框图。
图6是异构计算或计算机系统的示例实施例的框图。
图7是异构计算或计算机系统的示例实施例的框图。
具体实施方式
在如下描述中,阐述了大量特定细节(例如特定处理单元、异构计算机系统、操作序列、逻辑分割/集成细节、系统组件的类型和相互关系等)。然而,要理解到,本发明的实施例可以在没有这些特定细节的情况下实行。在其它实例中,众所周知的电路、结构和技术未详细示出,以免模糊对此描述的理解。
图1是异构计算或计算机系统100的实施例的框图。在各种实施例中,异构计算系统可表示台式计算机、膝上型计算机、笔记本计算机、上网本计算机、工作站、个人数字助理(PDA)、智能电话、蜂窝电话、移动计算装置、服务器、因特网器具或本领域已知的各种其它类型计算机系统或其它计算系统。
异构计算系统包含至少两个异构(即不同)类型的硬件计算单元。硬件计算单元在本文也可被称为计算单元。在所图示的实施例中,异构计算机系统包含第一类型的第一硬件计算单元101-1和第二不同类型的第二硬件计算单元101-2。第一和第二计算单元例如可通过互连111耦合在一起。其它实施例可包含三个或更多异构计算单元。适当计算单元的示例包含但不限于处理器、核、硬件线程、线程槽、能够维持独立执行状态的硬件等。
在一些实施例中,第一计算单元101-1可以是通用计算单元(或至少比第二计算单元101-2相对更通用),而第二计算单元101-2可以不是通用计算单元和/或可以是专用计算单元(或至少比第一计算单元101-1相对更通用)。在一些实施例中,第一计算单元101-1可以是CPU、通用处理器和通用核中的一个,而第二计算单元可以不是。例如,第二计算单元101-2可以是图形处理器(例如GPU、图形协处理器、图形核等)、硬件加速器装置(例如专用加速器、固定功能加速器等)、密码处理器、通信处理器、网络处理器、专用处理器、专用核、高度并行专用硬件、数字信号处理器(DSP)、现场可编程门阵列(FPGA)等中的一个。
在一些实施例中,第一计算单元101-1可以是CPU,而第二计算单元可以是图形处理器(例如GPU、图形协处理器、图形核等),尽管本发明的范围不如此限制。在此类实施例中,异构计算系统可表示GPGPU系统、CPU-GPU协作系统等。在这个具体实施方式中,经常CPU和GPU被用作第一和第二异构计算单元的示例,不过要认识到,在备选实施例中,可替代地使用异构计算单元的其它不同组合(例如相对更通用处理器连同从专用处理器、专用核、硬件加速器装置、DSP、FPGA等之间选择的相对更专用处理器)。
再次参考图1,当部署在异构计算系统中时,第一计算单元101-1和第二计算单元101-2各可操作以例如通过互连108、109与共享存储器102耦合。共享存储器对第一和第二计算单元可存取并由它们共享。在一些实施例中,共享存储器可表示共享虚拟存储器。共享存储器或共享虚拟存储器可表示实现在一个或多个存储器类型的一个或多个存储器装置中的物理存储器的一部分。在一些实施例中,共享存储器可实现在动态随机存取存储器(DRAM)中,尽管本发明的范围不如此限制。
在一些实施例中,对应于第一计算单元101-1的第一工作队列104-1和对应于第二计算单元101-2的第二工作队列104-2可存储在共享存储器102中。第一工作队列104-1可以可操作以对用于第一计算单元101-1的工作接收并排队。第二工作队列104-2可以可操作以对用于第二计算单元101-2的工作接收并排队。在图示中为了简化,仅示出两个工作队列,不过在一些实施例中,可能存在用于第一计算单元(例如用于多个核中的每个)的多个工作队列和/或用于第二计算单元(例如可选地用于多个多处理器或其它组核中的每个)的多个工作队列。
再次参考图1,在一些实施例中,第一计算单元101-1(例如CPU、通用处理器、通用核等)可包含第一工作调度器模块103-1。第一工作调度器模块103-1可以可操作以调度第一计算单元101-1上的工作。在一些实施例中,第二计算单元101-2(例如GPU、图形核、硬件加速器、专用处理器、专用核等)可包含第二工作调度器模块103-2。第二工作调度器模块103-2可以可操作以调度第二计算单元101-2上的工作。在一些实施例中,第一和第二工作调度器模块可以可操作以调度第一和第二计算单元上的工作,以实现异构计算单元上的公共工作负载的不同部分(例如数据并行工作负载的不同部分)上的混合执行和/或协作/合作计算。例如,在一些实施例中,CPU和GPU可一起工作在GPGPU中。
作为示例,工作负载可被分成组块、工作单元或其它部分。这些组块、工作单元或部分可在第一和第二计算单元之间调度,并在对应的第一和第二工作队列中排队。在一些实施例中,此类队列例如可通过编码一系列最小和最大索引范围的数据并行操作来实现,其中工作的单个单元可表示为元组(例如min1, max1)。数据并行操作的总索引范围可被分成工作的组块。在一些情况下,组块的大小可选地可选择成使得它对应于计算单元(例如GPU)的多个所述数量的硬件线程、SIMD道或核。更进一步说,它可选地可大于硬件线程、SIMD道或核的总数除以计算单元同时支持的屏障的数量。尽管不需要,但这可帮助确保工作的组块有效地利用计算资源,并且初始调度通过硬件线程调度器是有效的,如果存在一个的话。组块然后例如可在工作队列之间均匀分布,或者基于各种算法/准则分布。在运行时间期间,每一个计算单元可从其对应工作队列中检索并处理组块或工作单元。
这可继续直到工作负载已经完成。作为示例,完成可由所有队列为空来指示。在一些情况下,可选地可使用终止令牌。例如,终止令牌可将最大整数值表示为终止令牌TERM EMPTY。在所有计算工作者按确定次序窃取并且没有工作者生成更多工作的实施例中,返回值EMPTY一般将指示终止。在允许随机窃取操作的实施例中,在它自身用完工作之后,足以让至少一个工作者(例如CPU线程)按确定次序穿过所有队列。如果它发现所有队列空,则它可向所有队列或至少向另一计算单元(例如GPU)的所有工作队列写EMPTY终止令牌。这可帮助终止数据并行工作负载。
在一些实施例中,例如可执行工作窃取,以便帮助改进负载平衡,提高性能,降低功耗等。术语“工作窃取”是在本领域使用的术语。本文所使用的术语“工作窃取”广义上用于指将工作从一个计算单元重新指配或重新任务分配给另一计算单元,将工作从一个计算单元的队列移动到另一计算单元的队列,允许计算单元主张或负责之前由另一计算单元主张或由其负责的工作等。
再次参考图1,在一些实施例中,第一计算单元101-1(例如CPU、通用处理器、通用核等)可选地可包含第一同步工作窃取器系统105-1的实施例,尽管这不是要求的。第一同步工作窃取器系统105-1可以可操作以从第二计算单元101-2执行同步工作窃取,以便第一计算单元101-1做该工作,尽管本发明的范围不如此限制。在一些实施例中,第一同步工作窃取器系统105-1可存取第一工作队列104-1和第二工作队列104-2。第一同步工作窃取器系统可用软件、固件和硬件的任何组合实现。
在一些实施例中,第二计算单元101-2(例如GPU、图形核、硬件加速器、专用处理器、专用核等)可包含第二同步工作窃取器系统105-2的实施例。在一些实施例中,第二同步工作窃取器系统105-2可以可操作以从第一计算单元101-1执行同步工作窃取,以便第二计算单元101-2做工作。窃取的工作可从第一工作队列104-1取得,并添加到第二工作队列104-2。在一些实施例中,第二同步工作窃取器系统105-2可存取第一工作队列104-1和第二工作队列104-2。第二同步工作窃取器系统可用软件、固件和硬件的任何组合实现。
在一些实施例中,工作窃取可基于第一工作队列104-1和第二工作队列104-2的当前充满。例如,在一些实施例中,如果第二工作队列104-2变空,填充在阈值等级以下,或被第二同步工作窃取器系统105-2感知为未充分充满,则第二同步工作窃取器系统105-2可从第一工作队列104-1窃取工作,并将窃取的工作放入第二工作队列104-2中。作为另一示例,在一些实施例中,如果第二同步工作窃取器系统103-2感知到第一工作队列104-1是满的,填充在阈值等级以上,或者另外太满,则第二同步工作窃取器系统103-2可从过度填充的第一工作队列104-1中窃取工作。在其它实施例中,当第一工作队列104-1填充不足时和/或当第二工作队列104-2填充过度时,第一同步工作窃取器系统103-1可执行类似或相互类型的工作窃取。还考虑了工作窃取的其它原因。
在一些实施例中,工作窃取在第一与第二计算单元之间在任一方向上可以是双向的。例如,第一同步工作窃取器系统105-1可从第二计算单元101-2窃取工作用于第一计算单元101-1去做(例如将工作从第二工作队列104-2移动到第一工作队列104-1),并且第二同步工作窃取器系统105-2可从第一计算单元101-1窃取工作用于第二计算单元101-2去做(例如将工作从第一工作队列104-1移动到第二工作队列104-2)。在一些实施例中,可执行双向相互同步的工作窃取。在一些实施例中,可选地可使用随机基本上同时的双向相互同步的工作窃取。在其它实施例中,第二计算单元101-2可选地可从第一计算单元101-1窃取工作,无需第一计算单元从第二计算单元窃取工作。这可能不提供为巨大优势,但如果期望的话,可帮助允许更简单实现。在此类情况下,第一计算单元可选地可省略同步工作窃取器系统105-1。
再次参考图1,在一些实施例中,可选地可执行同步工作窃取操作106、107。在一些实施例中,可通过同步存取工作窃取队列104-1、104-2和/或同步存取共享存储器103来执行同步工作窃取操作。例如,第二计算单元101-2可发出帮助实现同步工作窃取(例如同步工作窃取106)的同步(例如原子存取/操作110)。在一些实施例中,同步工作窃取操作可用于帮助防止两个实体窃取相同工作和/或执行相同工作。这还可帮助防止用于实现工作队列的共享数据结构的破坏,并且可帮助允许它们从一个有效状态转变到另一有效状态。在一些实施例中,同步工作窃取操作可充分完成,因为工作可能不从队列窃取,但不由窃取计算单元执行。
在一些实施例中,可通过一个或多个存储器存取同步原语和/或指令和/或操作执行同步工作窃取操作。在一些实施例中,退出队列和窃取操作可利用由第一和第二计算单元支持的一组存储器存取排序原语/指令/操作。在一些实施例中,存储器存取同步原语/指令/操作可在支持第一与第二计算单元(例如CPU与GPU)之间任何期望的此类存储器存取同步原语/指令/操作的硬件上实现。适当的此类原语/指令/操作的示例包含但不限于存储器栅栏和/或屏障宏指令、原子存储器存取宏指令、OpenCL原子操作、CUDA存储器存取同步操作或在本领域已知的其它方法。
作为示例,在原子存储器接入操作中,处理器可基本上同时(例如在相同总线循环中)读存储器位置和向存储器位置写。此类原子操作可帮助防止其它计算单元或外部装置写或读存储器位置直到原子操作完成之后。一般而言,原子存储器存取操作将完全执行或者根本不执行。此类原子存储器存取原语/指令/操作的示例包含但不限于读-修改-写、比较并互换、比较并交换、测试并设置、比较并设置、加载链路/有条件存储指令等以及它们的各种组合。这些可通过宏指令、OpenCL原子操作、CUDA存储器存取同步操作或通过在本领域已知的其它方法进行。
在一些实施例中,这些可包含一个或多个存储器存取栅栏指令。存储器存取栅栏指令在本领域中(例如在一些架构中)有时也被称为存储器存取屏障指令。此类存储器存取栅栏和/或屏障指令的示例包含但不限于加载栅栏/屏障(例如LFENCE指令)、存储栅栏/屏障(例如SFENCE指令)以及加载并存储栅栏/屏障(例如MFENCE指令)等以及它们的各种组合。此类栅栏或屏障操作可通过宏指令、OpenCL操作、CUDA操作或通过在本领域已知的其它方法实现。
有利地,此类工作窃取可帮助允许第一与第二计算单元之间的更有效的工作调度和分布,这可导致更好地利用资源和提高性能。因为允许工作窃取,并且特别是当允许双向工作窃取时,不要求能够以高度有效方式在异构计算单元之间静态调度工作负载。如在背景技术部分中所讨论的,此类静态工作负载调度先验倾向于由于若干原因(例如,由于潜在不同时钟速度、不同存储器层级、不同代码执行有效性、其它工作负载的存在、功率极限等)是困难的。而是,如果由于某种原因工作最初以低效方式调度,并且它导致一个计算单元变得负担过度(或利用不足),则可执行工作窃取连同负载平衡,以便帮助重新平衡工作负载,并且由此帮助减轻各种计算单元的利用过度和/或利用不足。在其它实施例中,可选地可执行工作窃取而不是负载平衡以帮助实现其它目的,诸如例如最大化处理速度,降低功耗等。
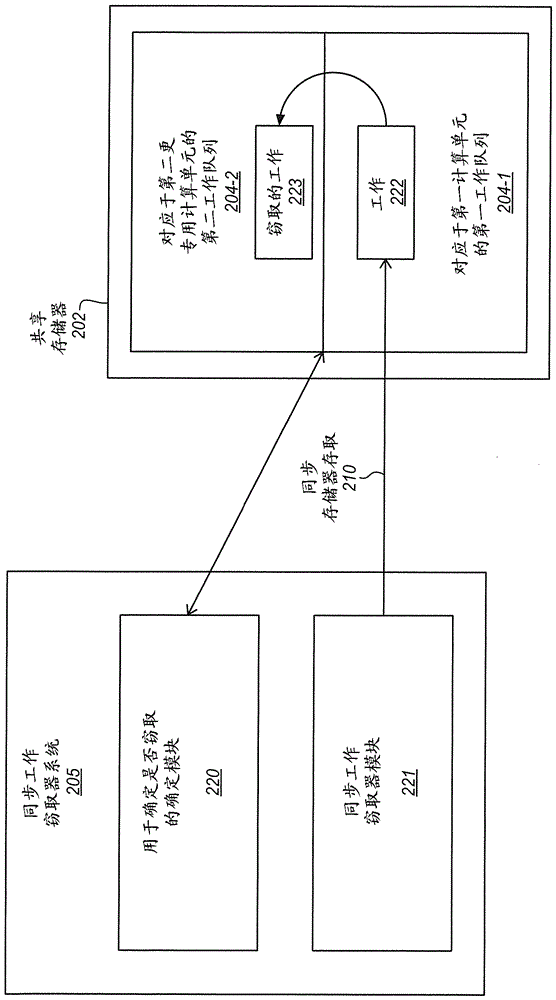
图2是同步工作窃取器系统205的实施例的框图。还示出的是共享存储器202中的第一工作队列204-1和第二工作队列204-2。在一些实施例中,图2的同步工作窃取器系统可包含在图1的第二硬件计算单元101-2和/或异构计算系统100中。备选地,图2的同步工作窃取器系统可包含在类似的或不同的计算单元或异构系统中。而且,图1的第二硬件计算单元和异构系统可包含与图2的类似的或不同的同步工作窃取器系统。
同步工作窃取器系统205包含确定模块220。确定模块可操作以确定是否从第一类型的第一硬件计算单元(例如第一计算单元101-1)窃取工作222用于第二不同类型的第二硬件计算单元(例如第二计算单元101-2)。在一些实施例中,第二类型可比第一类型更专用。工作222可在对应于第一硬件计算单元的第一工作队列204-1中排队。第一工作队列在共享存储器202中,其由第一和第二硬件计算单元共享。如所示,在一些实施例中,确定模块可与第一工作队列204-1和/或第二工作队列204-2耦合,或者以其他方式通信。在一些实施例中,确定模块可确定是否基于充满或一个或多个工作队列窃取工作。这可如在本文其它地方所描述的进行。
同步工作窃取器系统205还包含同步工作窃取器模块221。同步工作窃取器模块可操作以从第一硬件计算单元和/或第一队列204-1窃取工作222,并将它作为窃取的工作223提供用于第二硬件计算单元,和/或将它添加到第二工作队列204-2。在一些实施例中,同步工作窃取器模块可操作以通过对第一工作队列204-1的同步存储器存取210窃取工作。在一些实施例中,同步存储器存取210可相对于对来自第一硬件计算单元的第一工作队列的存储器存取同步。
图3是在异构计算机系统中窃取工作的方法335的实施例的流程框图。在一些实施例中,图3的操作和/或方法可由图1的同步工作窃取系统105-2和/或图2的同步工作窃取系统205执行,和/或在其内执行。这些系统的本文描述的组件、特征或特定可选细节可选地还适用于在实施例中可由这些系统和/或在这些系统内执行的操作和/或方法。备选地,图3的操作和/或方法可由类似或不同的同步工作窃取系统执行和/或在其内执行。而且,图1和/或图2的同步工作窃取系统可执行与图3的类似或不同的操作和/或方法。
该方法包含在块336确定从第一类型的第一硬件计算单元窃取工作用于比第一类型更专用的第二类型的第二硬件计算单元。在一些实施例中,工作可在对应于第一硬件计算单元的第一工作队列中排队。在一些实施例中,第一工作队列可存储在由第一和第二硬件计算单元共享的共享存储器中。
该方法还包含在块337窃取工作。在一些实施例中,窃取工作可包含执行对第一工作队列的同步存储器存取。在一些实施例中,同步存储器存取可相对于对来自第一硬件计算单元的第一工作队列的存储器存取同步。
图4是图示在CPU 401-1的实施例与GPU 401-2的实施例之间的双向同步工作窃取406、407的实施例的框图。CPU的所图示的示例具有四个核,即CPU核0、CPU核1、CPU核2和CPU核3。其它CPU可具有更少或更多的核。在所图示的实施例中,这些核中的每个都具有对应于CPU的第一组工作队列404-1中的不同工作队列。具体地说,在所图示的示例中,工作队列ws_q[0]对应于CPU核0,工作队列ws_q[1]对应于CPU核1,工作队列ws_q[2]对应于CPU核2,并且工作队列ws_q[3]对应于CPU核3。在其它实施例中,可使用核与工作队列之间的多对一或者一对多的对应关系。
CPU的所图示的示例具有四个工作组,即工作组0、工作组1、工作组2和工作组3。这些工作组还可被称为流播单元或多处理器。在图示中,每个工作组具有16个SIMD道,尽管其它实施例可具有更少或更多的SMID道。而且,其它GPU可具有更少或更多的工作组。例如,一些GPU具有大约数十个多处理器或工作组。这些工作组中的每个可包含一个或多个核,或者潜在地包含许多核。例如,一些GPU每个多处理器或工作组具有大约数十个核。在所图示的实施例中,这些工作组中的每个共享对应于GPU的第二工作队列404-2。在其它实施例中,多个工作队列可各用于一个或多个工作组。工作组404-1、404-2可在共享存储器中。
在图示中示出了双向同步工作窃取操作406、407的示例。虽然CPU核0、CPU核1和CPU核3分别从它们自己的对应工作队列ws_q[0]、ws_q[l]和ws_q[3]工作,但CPU核2正在从GPU队列404-2执行同步工作窃取操作407。类似地,工作组0(亦称流播单元0)正在从对应于CPU核3的工作队列ws_q[3]执行同步工作窃取操作406。这只是一个说明性示例。工作窃取操作406、407可类似于本文描述的其它工作窃取操作,或与之相同。
图5是可使用同步工作窃取器系统505的实施例的环境的框图。如所示,在一些实施例中,同步工作窃取器系统可实现在常规运行时间之上,诸如例如在常规OpenCL运行时间542之上。在一些实施例中,同步工作窃取器系统可将工作负载诸如例如常规OpenCL工作负载内核540包装成附加工作窃取调度器代码。在一些实施例中,OpenCL运行时间或其它运行时间(例如CUDA运行时间)可能需要基本上被修改。
图6是异构计算或计算机系统600的示例实施例的框图。系统包含CPU 601-1和具有GPU 601-2的卡652。CPU包含任何期望数量的核650。GPU包含任何期望数量的核651。卡还具有与GPU耦合的存储器653。在一些实施例中,存储器可包含DRAM,尽管这不是要求的。CPU和GPU耦合在一起,并且通过互连608与存储器653耦合。任何已知互连是适合的,诸如例如外围组件互连以及其衍生或扩展。
存储器654包含共享存储器602。共享存储器包含CPU工作队列604-1和GPU工作队列604-2。CPU具有第一同步工作窃取器系统605-1。GPU具有第二同步工作窃取器系统605-2。在一些实施例中,这些同步工作窃取器系统中任一个或二者可类似于在本文其它地方所描述的,或者与之相同。例如,第二同步工作窃取器系统605-2可类似于图1的第二同步工作窃取器系统105-2和/或图2的同步工作窃取器系统205,或与之相同。
图7是异构计算或计算机系统700的示例实施例的框图。系统包含通过互连与存储器754耦合的芯片和/或管芯761。在一些实施例中,存储器754可包含DRAM,尽管这不是要求的。任何已知互连是适合的,诸如例如外围组件互连以及其衍生或扩展。芯片/管芯包含CPU 701-1和集成图形701-2。CPU包含任何期望数量的核750。集成图形包含任何期望数量的核751。CPU和集成图形与片上互连760耦合。在本领域已知的任何片上互连机制是适合的。集成存储器控制器762也与片上互连耦合。存储器控制器通过互连708将芯片/管芯与存储器754耦合。
存储器754包含共享存储器702。共享存储器包含CPU工作队列704-1和集成图形工作队列704-2。CPU具有第一同步工作窃取器系统705-1。集成图形具有第二同步工作窃取器系统705-2。在一些实施例中,这些同步工作窃取器系统中任一个或二者可类似于本文在别的地方所描述的,或者与之相同。例如,第二同步工作窃取器系统705-2可类似于图1的第二同步工作窃取器系统105-2和/或图2的同步工作窃取器系统205,或与之相同。
如下代码说明了适合的同步工作窃取器系统的示例实施例的使用:
/*注释:
1.全局工作窃取队列数据结构ws_q保存CPU核和GPU核的所有工作窃取队列。这个数据结构被分配在CPU与GPU之间的共享存储器中。
2.工作窃取队列ws_q[ 0 ],..., ws_q[num_cpu_threads-1]表示CPU核的队列。ws_q[num_cpu_threads]表示GPU工作窃取队列。num_cpu_threads表示异构系统中的CPU核的总数。所有这些工作窃取队列都被分配在CPU与GPU之间的共享存储器中。每个工作窃取队列在下面的"WSQueue"数据结构中描述。
3.每个GPU计算内核由子例程"actual_kernel" 定义,子例程"actual_kernel"将它在其上操作的迭代空间的索引作为变元。这个子例程的细节是用户应用特定的。
4.下面描述的子例程"kernel_wrapper"是基于软件的包装器,其由编译GPU内核的编译器或由应用本身或由OpenCL运行时间生成。
5. 下面描述的子例程"steal_wrapper"跨CPU和GPU核的工作窃取队列发现工作。如果发现任何工作,则它在对应工作窃取队列上执行窃取操作。如果在所有队列中什么也没发现,则返回EMPTY。
6. 子例程“steal”从给定工作窃取队列执行实际窃取。当它窃取时,它首先确保在队列中至少存在一个工作,并且然后原子地更新队列的顶部指针以确保正确执行同时窃取。
7. 子例程“cas”在CPU与GPU之间的共享存储器上执行比较并设置操作。
*/
/*每个计算内核,例如"actual_kernel"都用这个子例程包装,以执行CPU与GPU工作窃取队列之间的工作窃取;这个包装器代码由用户/编译器或者由OpenCL运行时间执行。*/
__kernel void kernel_wrapper (
global WSQueue *ws_q, / *用于在共享存储器中分配的CPU和GPU的工作窃取队列数据结构*/
int num_cpu_threads /*CPU核的数量*/
) {
int local_id = get_local_id ( 0 ); //工作组内这个工作项的local_id
__local int work_ idx; //总迭代空间中的索引;工作组中的工作项共享这个
barrier (CLK_LOCAL_MEM_FENCE);
//本地存储器屏障;这确保work_idx对工作组中的所有工作项可见;
if (work_idx == EMPTY) return; //如果我们在本地或通过窃取未发现工作则返回
/* 调用实际opencl内核*/
actual_kernel (work_idx + local_id) ;
}
}
/*这个子例程顺序地遍历所有工作窃取队列并尝试寻找工作。如果在所有队列中什么也没发现,则返回EMPTY,指示终止。*/
int steal_wrapper ( global WSQueue *ws_q, int
num_cpu_threads ) {
/*ws_q[num_cpu_threads]表示GPU工作窃取队列,因此我们以相反次序遍历,以首先从GPU队列并且然后CPU队列发现工作。*/
for (int i=num_cpu_threads ; i>=0; i--) {
__global WSQueue each_ws_q = ws_q[i];
work_idx = steal (each_ws_q); //从工作窃取队列执行实际窃取操作
if (work_idx >= 0) return work_idx;
//如果发现了工作,则将索引返回到工作。
}
return EMPTY; //如果在所有队列中都没发现工作,则返回EMPTY。
}
/*此子例程执行用于从给定队列窃取工作的实际窃取操作*/
int steal ( global WSQueue *a_ws_q) {
int top = a_ws_q->top; //指向工作窃取队列中的顶条目
int bottom = a_ws_q->bottom; //指向工作窃取队列中的底条目
__global CircularArray *array = a_ws_q->activeArray ;
//发现存储该对(min,max)的数组
int size = bottom - top; //发现工作窃取队列中的条目数量
if (size <= 0) { // 如果没有工作,返回EMPTY
return EMPTY;
}
int o = (array->segment [top % (l<<array->log_size) ] ).min;
//发现在顶上第一组块的索引
/*既然我们发现了工作并且准备好窃取,我们就在顶部指针上使用比较并设置(cas)执行原子窃取。*/
if ( ! cas ( a_ws_q, top, top+1)){ //在顶部指针上比较并设置
return ABORT;//如果我们未成功执行原子操作则ABORT
}
return o; //从指示实际工作索引的元组(min,max)返回最小索引
}
/*此子例程示出了共享存储器上CPU与GPU之间的比较并设置(cas)操作的实现。*/
bool cas ( __global WSQueue *a_ws_q, int oldVal, int newVal) {
int result;
result = atomic_cmpxchg ( (volatile global int * ) & (a_ws_q->top) , oldVal, newVal);
//在共享存储器上执行原子比较并交换操作
return (result == oldVal);
};
/*用于工作窃取队列实现的数据结构列表*/
/*每个单独工作窃取队列数据结构*/typedef struct WS_Q_s {
volatile int bottom; //工作窃取队列的底部
volatile int top; //工作窃取队列的顶部
CircularArray *activeArray ; //用于保存所有工作组块的基础数组
} WSQueue;
typedef struct CircularArray_s {
int log_size; //用于实现工作组块的循环数组的log大小
pair_t *segment; //用于工作组块的数组
} CircularArray ;
typedef struct pair_s {
int min; //从那开始工作的最小索引,如果被窃取的话
int max; //工作直到的最大索引,如果被窃取的话
}pair_t ;
enum WSQ_Tag{
EMPTY=-2, //指示队列是EMPTY,并且因此终止
ABORT=-1,//指示窃取操作由于竞争而未成功继续
};
对于图1和图4-7中任一个所描述的组件、特征和细节可选地也可用在图2-3中的任一个中。而且,本文对于任何设备描述的组件、特征和细节可选地也可用在本文描述的任何方法中,所述方法在实施例中可由此类设备和/或用此类设备执行。
示例实施例
如下示例涉及另外实施例。在一个或多个实施例中的任何地方都可使用示例中的细节。
示例1是工作窃取器设备。工作窃取器包含:确定模块,用于确定从第一类型的第一硬件计算单元窃取工作用于不同于第一类型的第二类型的第二硬件计算单元。该工作在第一工作队列中排队,第一工作队列对应于第一硬件计算单元并且被存储在由第一和第二硬件计算单元共享的共享存储器中。工作窃取器设备还包含:同步工作窃取器模块,其通过对第一工作队列的同步存储器存取来窃取所述工作,所述同步存储器存取相对于对来自第一硬件计算单元的第一工作队列的存储器存取同步。
示例2包含示例1的主题,并且可选地,其中同步工作窃取器模块将工作添加到第二工作队列。第二工作队列对应于第二硬件计算单元,并且被存储在共享存储器中。第二类型可选地比第一类型更专用。
示例3包含示例1的主题,并且可选地,其中所述同步工作窃取器模块通过包含对第一工作队列执行的原子操作的所述同步存储器存取来窃取所述工作。
示例4包含示例3的主题,并且可选地,其中所述原子操作包括读-修改-写操作、比较并互换操作、比较并交换操作、测试并设置操作、比较并设置操作以及加载链路/有条件存储操作之一。
示例2包含示例1的主题,并且可选地,其中原子操作包括开放计算语言(OpenCL)原子操作。
示例6包含示例3的主题,并且可选地,其中同步工作窃取器模块通过CUDA同步存储器存取来窃取工作。
示例7包含示例1的主题,并且可选地,进一步包括:第二确定模块,用于确定从第二硬件计算单元窃取第二工作用于第一硬件计算单元。第二工作在第二工作队列中排队,第二工作队列对应于第二硬件计算单元并且被存储在共享存储器中。
示例8包含示例7的主题,并且可选地,进一步包括:第二同步工作窃取器模块,其通过对来自第一硬件计算单元的第二工作队列的第二同步存储器存取来窃取第二工作。第二同步存储器存取相对于对来自第二硬件计算单元的第二工作队列的存储器存取同步。
示例9包含示例1-8中任一个的主题,并且可选地,其中当第二工作队列为空和填充在阈值等级以下中的一项时,所述确定模块确定窃取所述工作,第二工作队列对应于第二硬件计算单元并且被存储在所述共享存储器中。
示例10包含示例1-8中任一个的主题,并且可选地,其中第一硬件计算单元包括从通用处理器和中央处理单元(CPU)中选择的一个。第二硬件计算单元包括从图形处理器、硬件加速器装置、密码处理器、通信处理器、网络处理器、专用处理器、专用核、高度并行专用硬件、数字信号处理器(DSP)和现场可编程门阵列(FPGA)中选择的一个。
示例11包含示例10的主题,并且可选地,其中第一硬件计算单元包括所述CPU,并且其中第二硬件计算单元包括从图形处理单元(GPU)和集成图形核中选择的所述图形处理器。
示例12包含示例11的主题,并且可选地,其中图形处理器包括集成图形核,并且其中集成图形核和CPU共享相同的最后一级高速缓存。
示例13是一种在异构计算系统中的方法。该方法包含:确定从第一类型的第一硬件计算单元窃取工作用于比第一类型更专用的第二不同类型的第二硬件计算单元。该工作在第一工作队列中排队,第一工作队列对应于第一硬件计算单元并且被存储在由第一和第二硬件计算单元共享的共享存储器中。该方法还包含:窃取所述工作包含执行对存储在所述共享存储器中的第一工作队列的同步存储器存取,所述同步存储器存取相对于对来自第一硬件计算单元的第一工作队列的存储器存取同步。
示例14包含示例13的主题,并且可选地,进一步包括:将所述工作添加到第二工作队列,其对应于第二硬件计算单元,并且其也存储在所述共享存储器中。
示例15包含示例13的主题,并且可选地,其中执行同步存储器存取包括执行原子操作。
示例16包含示例15的主题,并且可选地,其中执行原子操作包括执行从读-修改-写操作、比较并互换操作、比较并交换操作、测试并设置操作、比较并设置操作以及加载链路/有条件存储操作中选择的原子操作。
示例17包含示例15的主题,并且可选地,其中执行原子操作包括执行开放计算语言(OpenCL)原子操作。
示例18包含示例15的主题,并且可选地,其中窃取包括通过执行CUDA同步存储器存取来窃取工作。
示例19包含示例13的主题,并且可选地,进一步包括:确定窃取第二工作,并从第二硬件计算单元窃取第二工作用于第一硬件计算单元。第二工作在第二工作队列中排队,第二工作队列对应于第二硬件计算单元并且被存储在共享存储器中。
示例20包含示例19的主题,并且可选地,其中窃取第二工作包括执行对来自第一硬件计算单元的第二工作队列的同步存储器存取,所述同步存储器存取相对于对来自第二硬件计算单元的第二工作队列的存储器存取同步。
示例21包含示例13的主题,并且可选地,其中确定包括响应于第二工作队列为空和填充在阈值等级以下中的一项而确定窃取所述工作,第二工作队列对应于第二硬件计算单元并且被存储在所述共享存储器中。
示例22包含示例13的主题,并且可选地,其中第一硬件计算单元是从通用处理器、中央处理单元(CPU)以及具有多个通用核的片上系统中选择的一个。还有,其中第二硬件计算单元是从图形处理器、硬件加速器装置、密码处理器、通信处理器、网络处理器、专用处理器、专用核、片上系统上的专用核、高度并行专用硬件、数字信号处理器(DSP)和现场可编程门阵列(FPGA)中选择的一个。
示例23包含示例22的主题,并且可选地,其中第一硬件计算单元包括所述CPU,并且其中第二硬件计算单元包括从图形处理单元(GPU)和集成图形核中选择的所述图形处理器。
示例24包含示例22的主题,并且可选地,其中图形处理器包括集成图形核,并且其中集成图形核和CPU的核共享相同的最后一级高速缓存。
示例25是异构计算机系统。异构计算机系统包含互连。异构计算机系统还包含与互连耦合的第一类型的第一硬件计算单元。异构计算机系统还包含与互连耦合的第二不同类型的第二硬件计算单元。第二类型比第一类型更专用。异构计算机系统还包含与互连耦合的动态随机存取存储器(DRAM),DRAM包含由第一和第二硬件计算单元共享的共享存储器。共享存储器包含将第一硬件计算单元的工作排队的第一工作队列和将第二硬件计算单元的工作排队的第二工作队列。异构计算机系统还包含:工作窃取器设备,其确定窃取并通过对第一工作队列的同步存储器存取从第一队列窃取工作并将它添加到第二队列。同步存储器存取相对于对来自第一硬件计算单元的第一工作队列的存储器存取同步。
示例26包含示例25的主题,并且可选地,其中工作窃取器设备通过包含第一工作队列上的原子操作的同步存储器存取来窃取工作。
示例27包含示例25-26中任一个的主题,并且可选地,进一步包括:第二工作窃取器设备,其确定窃取并通过对第二工作队列的第二同步存储器存取从第二工作队列窃取第二工作并将它添加到第一工作队列,第二同步存储器存取相对于对来自第二硬件计算单元的第二工作队列的存储器存取同步。
示例28是存储指令的一个或多个计算机可读存储介质,所述指令如果由机器执行则将使机器执行操作。操作包含确定从第一类型的第一硬件计算单元窃取工作用于比第一类型更专用的第二不同类型的第二硬件计算单元的操作。该工作在第一工作队列中排队,第一工作队列对应于第一硬件计算单元并且被存储在由第一和第二硬件计算单元共享的共享存储器中。操作包含通过对第一工作队列执行的同步存储器存取来窃取工作的操作。同步存储器存取相对于对来自第一硬件计算单元的第一工作队列的存储器存取同步。
示例29包含示例28的主题,并且可选地,其中机器可读存储介质进一步提供指令,所述指令如果由机器执行则将使机器执行包含将工作添加到第二工作队列的操作,第二工作队列对应于第二硬件计算单元并且被存储在共享存储器中。
示例30包含示例28-29中任一个的主题,并且可选地,其中机器可读存储介质进一步提供指令,所述指令如果由机器执行则将使机器执行包含通过包含执行第一队列的原子操作的同步存储器存取来窃取工作的操作。
示例31是存储指令的机器可读存储介质,所述指令如果由机器执行则使所述机器执行示例13-24中任一个的方法。
示例32是包括用于执行示例13-24中任一个的方法的部件的设备。
示例33是用于执行示例13-24中任一个的方法的设备。
示例34是用于基本上执行本文所描述的方法的设备。
示例35是包括用于基本上执行本文所描述的方法的部件的设备。
在说明书和权利要求书中,可已经使用了术语“耦合”和“连接”,连同它们的派生词。应该理解,这些术语不打算作为彼此的同义词。而是,在具体实施例中,“连接”可用于指示两个或更多元件彼此直接物理接触或电接触。“耦合”可意味着两个或更多元件直接物理接触或电接触。然而,“耦合”也可意味着,两个或更多元件彼此不直接接触,但仍彼此协同操作或交互。例如,处理器可通过一个或多个中间组件(例如一个或多个互连和/或芯片集)与装置耦合。在附图中,使用箭头示出连接和耦合。
在说明书和权利要求书中,可能已经使用了术语“逻辑”。本文所使用的逻辑可包含诸如硬件、固件、软件或它们的组合的模块。逻辑示例包含集成电路、专用集成电路、模拟电路、数字电路、编程的逻辑装置、包含指令的存储器装置等。
可已经使用了术语“和/或”。本文所使用的术语“和/或”意味着一个或另一个或二者(例如A和/或B意味着A或B,或者A和B)。
在以上描述中,为了说明目的,已经阐述了大量特定细节以便提供本发明实施例的全面理解。然而,对于本领域技术人员将显而易见的是,在没有这些特定细节中的一些细节的情况下,也可实践一个或多个其它实施例。所描述的具体实施例不是提供用于限制本发明,而是用于通过示例实施例说明它。本发明的范围不由特定示例确定而仅由权利要求书确定。在其它实例中,已经以框图形式或没有细节示出了众所周知的电路、结构、装置和操作,以便避免模糊描述的理解。
在视为合适的情况下,在附图中已经重复了附图标记或附图标记的末端部分以指示对应或类似元件,它们可选地可具有类似或相同特性,除非另外规定或清楚地显而易见。在一些情况下,已经描述了多个组件,它们可被合并成单个组件。在已经描述了单个组件的其它情况下,它可被分割成多个组件。
已经描述了各种操作和方法。在流程图中以比较基本的形式描述了其中一些方法,但可选地可向方法添加操作和/或从方法移除操作。此外,虽然流程图示出了根据示例实施例的操作的具体次序,但具体次序是示范性的。备选实施例可选地可按不同次序执行操作,组合某些操作,重叠某些操作等。
一些实施例包含制品(例如计算机程序产品),其包含机器可读介质。介质可包含提供例如存储机器可读形式的信息的机制。机器可读介质可提供或其上存储有一个或多个指令,指令如果和/或当由机器执行时可操作以使机器执行和/或导致机器执行本文公开的一个或多个操作、方法或技术。
在一些实施例中,机器可读介质可包含有形和/或非暂时性机器可读存储介质。例如,有形和/或非暂时性机器可读存储介质可包含软盘、光存储介质、光盘、光数据存储装置、CD-ROM、磁盘、磁光盘、只读存储器(ROM)、可编程ROM(PROM)、可擦除和可编程ROM (EPROM)、电可擦除和可编程ROM (EEPROM)、随机存取存储器(RAM)、静态RAM (SRAM)、动态RAM (DRAM)、闪存、相变存储器、相变数据存储材料、非易失性存储器、非易失性数据存储装置、非暂时性存储器、非暂时性数据存储装置等。非暂时性机器可读存储介质不包括暂时性传播信号。在另一实施例中,机器可读介质可包含暂时性机器可读通信介质,例如电、光、声或其它形式的传播信号,诸如载波、红外信号、数字信号等。
适当机器的示例包含但不限于台式计算机、膝上型计算机、笔记本计算机、平板计算机、笔记本、智能电话、蜂窝电话、服务器、网络装置(例如路由器和交换机)、移动因特网装置(MID)、媒体播放器、智能电视、上网机、机顶盒和视频游戏控制器以及其它计算机系统、计算装置或具有一个或多个处理器的电子装置。
还应该认识到,此说明书通篇提到“一个实施例”、“实施例”或“一个或多个实施例”例如意味着具体特征可包含在本发明的实践中。类似地,应该认识到,在描述中各种特征有时一起组合在单个实施例、附图或其描述中以便使本公开流畅并帮助理解各个发明方面。然而,公开的这个方法不被解释为反映本发明需要比在每个权利要求中明确阐述的特征更多的特征的意图。而是,如随附权利要求书反映的,发明方面可在于少于单个公开的实施例的所有特征。从而,遵循具体实施方式的权利要求书由此被明确合并到此具体实施方式中,其中每个权利要求独立作为本发明的独立实施例。
- 还没有人留言评论。精彩留言会获得点赞!