刷量工具检测方法和装置与流程
本发明涉及网络数据检测领域,特别是涉及一种刷量工具检测方法和装置。
背景技术:
移动终端(以手机为例)上的应用是指通过手机通信终端接入或办理相关应用型功能的软件,应用渠道就是指所有可以获取手机应用安装包和用户信息的平台,主要包括ios渠道(如APP Store)和Android渠道(如手机助手)两大类。每一个用户在注册或登录了手机应用的账号后,手机应用的供应商都要给应用渠道支付一定的推广费用。目前,一些应用渠道为了骗取推广费用,就会利用刷量工具来进行作弊。刷量工具指安装到手机上可以在同一部手机上生成多个虚假新用户的应用,这类应用可以随机或基于已有用户数据文件生成手机设备号IMEI(International Mobile Equipment Identity,国际移动设备身份码)、IMSI(International Mobile Subscriber Identification Number,国际移动用户识别号码)、MAC地址、屏幕分辨率、机型、SIM卡号、手机号、运营商编号或名称、手机操作系统(OS)版本等各种参数。其中,IMEI是由15位数字组成的"电子串号",每个手机在组装完成后都将被赋予一个全球唯一的一组号码,这个号码从生产到交付使用都将被制造生产的厂商所记录,每个不同的IMEI代表一个新的用户;IMSI是储存在SIM卡中用于区别移动用户的标志,可用于区别移动用户的有效信息。为了防止这种作弊事件的发生,很有必要检测应用渠道是否使用了刷量工具。
传统的检测方法主要有两种:第一种检测方法是检测当前应用渠道下硬件属性的分布是否正常。比如,若当前应用渠道下用户的手机机型(手机所属的厂家及型号,如samsung_GN708T)分布情况与正常情况下用户的手机机型分布情况有很大差异,则当前应用渠道可能使用了刷量工具,或者如果当前应用渠道下用户的手机OS版本(如android 4.0.1)分布情况与正常情况下用户的手机OS版本分布情况有很大差异,则当前应用渠道可能使用了刷量工具,针对其他 硬件属性的分布异常检测类似。第二种检测方法是检测应用渠道的留存率(登录用户数/新用户数*100%)是否正常,因为刷量工具生成的新用户可能不会再次登录,使得其留存率出现异常。
然而,好的刷量工具生成的虚假新用户所对应的硬件属性与正常情况下的硬件属性在分布上是一致,这使得第一种检测方法具有一定的局限性;而留存率更多地作为评价手机应用质量的指标,留存率越高代表手机应用越好,这使得第二种检测方法得到的检测结果不够准确。
技术实现要素:
基于此,有必要针对传统检测方法具有局限性和检测结果不准确的技术问题,提供一种刷量工具检测方法和装置。
一种刷量工具检测方法,所述方法包括:
获取应用信息,所述应用信息包括应用的渠道标识;
获取安装所述应用的用户信息,所述用户信息包括用户的应用安装列表;
采用SimHash算法计算所述应用安装列表的SimHash值;
根据所述SimHash值对用户进行聚类统计;
根据所述聚类统计结果检测所述渠道标识对应的应用渠道是否使用了刷量工具。
一种刷量工具检测装置,所述装置包括:
第一获取模块,用于获取应用信息,所述应用信息包括应用的渠道标识;
第二获取模块,用于获取安装所述应用的用户信息,所述用户信息包括用户的应用安装列表;
计算模块,用于采用SimHash算法计算所述应用安装列表的SimHash值;
聚类统计模块,用于根据所述SimHash值对用户进行聚类统计;
检测模块,用于根据所述聚类统计结果检测所述渠道标识对应的应用渠道是否使用了刷量工具。
上述刷量工具检测方法和装置,考虑到刷量工具可以在一个移动终端上生成多个虚假新用户,但这个移动终端上安装的都是同样的应用,因此通过采用SimHash算法计算所述应用安装列表的SimHash值,并根据所述SimHash值对用户进行聚类统计,这样可以找到具有相同应用安装列表的用户集合以获得应用渠道作弊更为直接的证据,根据所述聚类统计结果检测应用渠道是否使用了刷量工具,这样不会受一些好的刷量工具因硬件属性的分布情况与正常情况下的一致性所带来的局限性,刷量工具的使用会直接导致很多用户的应用安装列表相同,因此,应用安装列表的相似性比留存率更能准确地反应出应用渠道是否使用了刷量工具。
附图说明
图1为一个实施例中刷量工具检测系统的应用环境图;
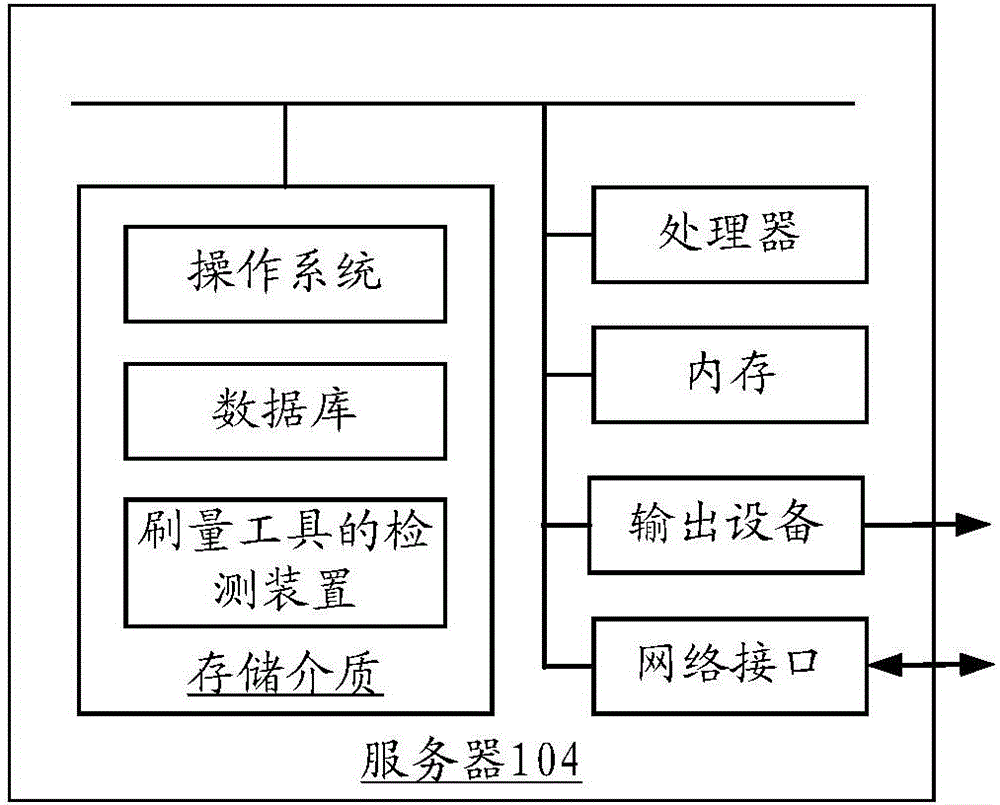
图2为一个实施例中服务器的结构示意图;
图3为一个实施例中刷量工具检测方法的流程示意图;
图4为一个实施例中采用SimHash算法计算应用安装列表的SimHash值的方法流程示意图;
图5为一个实施例中根据SimHash值对用户进行聚类统计的方法流程示意图;
图6为一个实施例中根据所述聚类统计结果检测所述渠道标识对应的应用渠道是否使用了刷量工具的方法流程示意图;
图7为一个具体应用场景中手机与服务器的交互示意图;
图8为一个实施例中刷量工具检测装置的结构框图;
图9为一个实施例中计算模块的结构框图;
图10为一个实施例中聚类统计模块的结构框图;
图11为一个实施例中检测模块的结构框图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实 施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图1所示,在一个实施例中,提供了一种刷量工具检测系统,包括多个移动终端102、服务器104。其中,移动终端102上运行有应用程序,至少提供应用信息和用户信息的发送功能,所述应用信息包括应用的渠道标识,所述用户信息包括用户的应用安装列表。正常情况下,每个移动终端102对应唯一的用户。服务器104用于接收所述移动终端102发送的应用信息和用户信息,并检测所述渠道标识对应的应用渠道是否使用了刷量工具。
在一个实施例中,上述图1中的服务器104的内部结构图如图2所示。服务器104包括通过系统总线连接的处理器、内存、存储介质、网络接口和输出设备。其中,该服务器的存储介质存储有操作系统和一种刷量工具检测装置,该刷量工具检测装置用于实现一种刷量工具检测方法。该服务器的处理器被配置为执行一种刷量工具检测方法。该输出设备包括显示屏。
如图3所示,在一个实施例中,提供了一种刷量工具检测方法,本实施例以该方法应用于上述图2中的服务器来举例说明。
该刷量工具检测方法具体包括如下步骤:
步骤S302:获取应用信息,所述应用信息包括应用的渠道标识。
具体地,渠道标识是指定的为用户提供应用安装包的应用渠道的唯一标识。用户通过某个应用渠道下载的应用安装包中都会自带有相应的渠道标识。渠道标识可以是包括数字、字母和标点符号中的至少一种的字符的字符串。步骤S302可以在步骤304之前或之后执行。
步骤S304:获取安装所述应用的用户信息,所述用户信息包括用户的应用安装列表。
具体地,应用安装列表是指移动终端的用户安装的APP名称的集合。移动终端可以直接向服务器发送用户信息,所述用户信息包括APP安装列表,服务器也可以使用第三方工具获得用户对应的移动终端的软硬件属性。
举例说明,如果移动终端对应的A用户通过第三方电子市场这么一个应用渠道下载了一个网络聊天工具的应用安装包,那么这个应用安装包中会自带有 渠道标识。当移动终端给服务器上报数据时,服务器可以获取到网络聊天工具的渠道标识,同时可以获取到A用户的应用安装列表。
步骤S306:采用SimHash算法计算所述应用安装列表的SimHash值。
Simhash算法是一种降维技术,它可以将高维向量映射到一维的指纹,常用于网页去重。Simhash算法的输入是一个向量,输出是一个f位的指纹。其中,f为一个特定的数值,如32、64或128。在本实施例中,Simhash算法输入的向量是一个应用安装列表的特征集合,每一个特征都可以设置一个权重。
步骤S308:根据所述SimHash值对用户进行聚类统计。
每一个用户的应用安装列表经步骤S306计算后都会得到一个SimHash值。具有相同SimHash值的应用安装列表为相同或相似。
步骤S310:根据所述聚类统计结果检测所述渠道标识对应的应用渠道是否使用了刷量工具。
聚类统计结果可以直接反应出用户的应用安装列表的相同或相似的情况。比如,根据所述聚类统计结果得知有大量的用户的应用安装列表都是相同的,很明显这样是使用了刷量工具。
请参照图4,为一个实施例中采用SimHash算法计算应用安装列表的SimHash值的方法流程示意图。
具体地,采用SimHash算法计算应用安装列表的SimHash值具体包括以下步骤:
步骤S402:将所述应用安装列表按应用属性进行排序。
应用属性可以是应用名称,也可以是应用的安装时间等。在本实施例中,所述应用安装列表是按应用名称进行排序。具体地,首先比较应用名称的首字母,并按首字母顺序进行排序,如果应用名称的首字母都是一样的,那么就比较应用名称的第二个字母进行排序,以此类推。
举例说明,假设一个用户的应用安装列表为:Bab、Bcc、Ddd、Aaa,那么,经过步骤S402后的应用安装列表变为:Aaa、Bab、Bcc、Ddd。
步骤S404:以相邻两个应用名称组成的字符串作为一个特征构造特征集合。
有些应用名称会非常高频地出现在不同用户的应用安装列表中,如果分别 将每个单独的应用名称作为一个特征串,这样,这些高频的应用名称在不同用户的应用安装列表中同时出现的概率很高。在本实施例中,以相邻两个应用名称作为一个特征串,可以有效地降低一些高频的应用名称对SimHash算法计算结果的影响。
举例说明,假设一个用户的应用安装列表经步骤S402排序后为:Aaa、Bab、Bcc、Dac、Ddb、Ddc,那么,经过步骤S404后形成的字符串为:Aaa Bab、Bab Bcc、BccDac、DacDdb、DdbDdc。
假设Aaa这个应用名称是一个很高频的应用名称,如果分别将每个单独的应用名称作为一个特征串,这样Aaa在不同用户的应用安装列表中同时出现的概率较高。在本实施例中,以相邻两个应用名称作为一个特征串,即使Aaa可能在很多用户的应用安装列表中都有出现,但不同用户的应用安装列表中同时出现Aaa和Bab的概率就会低很多,这样可以有效地降低一些高频的应用名称对SimHash算法计算结果的影响。
步骤S406:采用SimHash算法计算所述特征集合的SimHash值。
Simhash算法具体如下:
(1)将一个f维的向量V初始化为0,f位的二进制数S初始化为0;
(2)对每一个特征产生一个f位的指纹b,如果b的第i位为1,则V的第i个元素加上该特征的权重;否则,V的第i个元素减去该特征的权重,其中,i为1~f之间的数。
(3)如果V的第i个元素大于0,则S的第i位为1,否则为0;
(4)输出指纹S。
在本实施例中,f取64,因为每个特征的重要性都是一样的,所以每个特征的权重设为1。输出的指纹S就是一个SimHash值。
下面通过一段代码示例来说明SimHash算法计算的过程:
请参照图5,为一个实施例中根据SimHash值对用户进行聚类统计的方法流程示意图。
具体地,根据SimHash值对用户进行聚类统计包括以下步骤:
步骤S502:将具有相同SimHash值的用户聚类到一个簇中。
聚类是指将物理或抽象对象的集合分成由类似的对象组成的多个类的过程。由聚类所生成的簇是一组数据对象的集合,同一个簇中的对象彼此相似,与其他簇中的对象相异。
步骤S504:统计所述簇的不同属性值。
簇的属性包括相似用户数量、相似用户比例、最大簇用户数量、最大簇用户比例、Top5簇用户数量以及Top5簇用户比例。其中,相似用户数量为用户数量大等于用户阈值的簇中的用户数量总和,如果有很多用户的安装列表相似,则说明应用渠道可能使用了刷量工具;相似用户比例为相似用户数量与新用户总数量的比值,如果有相当比例的用户的安装列表相似,则说明应用渠道可能使用了刷量工具;最大簇用户数量为用户数量最多的簇中的用户数量,如果最大簇的用户数量很多,则表明这个簇中用户的安装列表都很相似,则说明应用渠道可能使用了刷量工具;最大簇用户比例为最大簇用户数量与新用户总数量的比值,如果最大簇的用户数量新用户总数量的比例很高,则说明应用渠道可能使用了刷量工具;Top5簇用户数量为用户数量最多的5个簇中的用户数量总和,如果Top5簇用户数量很大,表明这些用户的安装列表存在相似情况,则应用渠道可能使用了刷量工具;Top5簇用户比例为Top5簇的用户数量与新用户总数量的比值,如果Top5簇用户比例很高,则应用渠道可能使用了刷量工具。所述簇的属性及属性值的计算具体如表1所示。
表1 簇属性列表
新用户是指在当天通过应用渠道下载并安装应用的用户。为了节约数据、减少数据的计算量,本实施例只针对新用户进行刷量工具检测,即本实施例中提到的用户均为新用户。
举例说明,设新用户总数量为55、用户阈值为15,假如根据SimHash值将渠道中的用户聚类到A、B、C、D、E、F六个簇中,其中A簇中有10个用户,B簇中有15个用户,C簇中有20个用户、D簇中有2个用户、E簇中有5个用户、F簇中有3个用户。
那么相似用户数量的属性值就等于B簇中用户与C簇中用户数量的累加数,即35;相似用户比例的属性值等于35/55;最大簇用户数量的属性值为20个;最大簇用户比例的属性值为20/55;Top5簇用户数量的属性值为A、B、C、E、F五个簇中用户数量的累加数,即10+15+20+5+3=53;Top5簇用户比例的属性值为53/55。
请参照图6,为一个实施例中根据所述聚类统计结果检测所述渠道标识对应的应用渠道是否使用了刷量工具的方法流程示意图。
根据所述聚类统计结果检测所述渠道是否使用了刷量工具具体包括以下步骤:
步骤S602:将所述簇的不同属性值与相应的属性阈值进行比较。
如上述,本实施例中统计了相似用户数量、相似用户的比例、最大簇的用户数量、最大簇的用户比例、Top5簇的用户数量以及Top5簇的用户比例六个属性。这六个属性中每个属性都有一个对应用的属性阈值。属性阈值的定义一般基于该属性的分布,比如大多数渠道下安装列表相似用户的比例不高于5%,而有少量渠道下安装列表相似用户的比例达到25~50%甚至更高,而这是极其不正常的情况。在本实施例中,安装列表相似用户的比例对应的属性阈值设置为0.25。
在本实施例中,需要将所述簇的六个属性值依次与他们的属性阈值进行比较。
步骤S604:根据所述比较结果检测所述渠道标识对应的应用渠道是否使用了刷量工具。
具体地,检测所述簇的不同属性值中是否至少有一个属性值大于等于其相应的属性阈值,若是,则所述渠道标识对应的应用渠道使用了刷量工具:
如果相似用户数量的属性值大等于其相应的阈值,则所述渠道标识对应的应用渠道使用了刷量工具;如果相似用户比例的属性值大等于其相应的阈值,则所述渠道标识对应的应用渠道使用了刷量工具;如果最大簇用户数量的属性值大等于其相应的阈值,则所述渠道标识对应的应用渠道使用了刷量工具;如果最大簇的用户比例的属性值大等于其相应的阈值,则所述渠道标识对应的应用渠道使用了刷量工具;如果Top5簇用户数量的属性值大等于其相应的阈值,则所述渠道标识对应的应用渠道使用了刷量工具;如果Top5簇的用户比例的属性值大等于相应的阈值,则所述渠道标识对应的应用渠道使用了刷量工具。
可以理解,在其他实施例中,还可以对比较顺序进行调整。进一步地,在其他实施例中,可以不需要将所述簇的六个属性值全部都与他们的属性阈值比较一遍,而是只要检测到有一个属性值大于等于其对应的属性阈值就可以停止下一个属性值的比较了。
上述刷量工具检测方法,考虑到刷量工具可以在一个移动终端上生成多个虚假新用户,但这个移动终端上安装的都是同样的应用,因此通过采用SimHash 算法计算所述应用安装列表的SimHash值,并根据所述SimHash值对用户进行聚类统计,这样可以找到具有相同应用安装列表的用户集合以获得应用渠道作弊更为直接的证据,根据所述聚类统计结果检测应用渠道是否使用了刷量工具,这样不会受一些好的刷量工具因硬件属性的分布情况与正常情况下的一致性所带来的局限性,刷量工具的使用会直接导致很多用户的应用安装列表相同,因此,应用安装列表的相似性比留存率更能准确地反应出应用渠道是否使用了刷量工具。
下面通过具体应用场景来说明上述刷量工具检测方法的原理,该应用场景以手机作为移动终端、第三方电子市场作为具体的应用渠道为例进行说明。
请参照图7,一个具体应用场景中手机与服务器的交互示意图。当天,总共有三部手机(702、704、706)对应的用户通过第三方电子市场下载并安装了同一个导航应用,服务器708可以获取到这个导航应用的渠道标识(对应第三方电子市场)和这三个用户的应用安装列表。正常情况下,每部手机都对应唯一一个用户。
假设第三方电子市场为了从这个导航应用的供应商处骗取推广费用,通过刷量工具在手机706上生成了15个虚假用户,这使得服务器708总共获取了18个用户的应用安装列表。有16个用户对应同一部手机706,因此这16个用户的应用安装列表是相同的。
服务器708会获取这18个新用户的应用安装列表。经采用SimHash算法计算出这18个用户的应用安装列表的SimHash值,并根据所述SimHash值对用户进行聚类统计,使具有相同simhash值的用户同处于一个簇中。这18个新用户中会有16个用户的应用安装列表的SimHash值相同,那么这18个新用户就会被分别聚类到三个簇中。假设一个簇的用户数量一般不会超过3,即不应该有3个以上的用户的应用安装列表相同或相似,则表示具有16个用户的这个簇是有问题的,最后的检测结果为该渠道标识对应的应用渠道(第三方电子市场)使用了刷量工具。
如图8所示,在一个实施例中,提供了一种刷量工具检测装置800,具有实现上述各个实施例的刷量工具检测方法的功能。该刷量工具检测装置800包括第一获取模块802、第二获取模块804、计算模块806、聚类统计模块808以及检测模块810。
第一获取模块802用于获取应用信息,所述应用信息包括应用的渠道标识。
第二获取模块804用于获取安装所述应用的用户信息,所述用户信息包括用户的应用安装列表。
计算模块806用于采用SimHash算法计算所述应用安装列表的SimHash值。
聚类统计模块808用于根据所述SimHash值对用户进行聚类统计。
检测模块810用于根据所述聚类统计结果检测所述渠道标识对应的应用渠道是否使用了刷量工具。
如图9所示,在一个实施例中,提供了一种计算模块900。该计算模块900包括排序单元902、构造单元904以及计算单元906。
排序单元902用于将所述应用安装列表按应用属性进行排序。
构造单元904用于以相邻两个应用名称组成的字符串作为一个特征构造特征集合。
计算单元906用于采用SimHash算法计算所述特征集合的SimHash值。
如图10所示,在一个实施例中,提供了一种聚类统计模块1000。该聚类统计模块1000包括聚类单元1002和统计单元1004。
聚类单元1002用于将具有相同SimHash值的用户聚类到一个簇中。
统计单元1004用于统计所述簇的不同属性值。
如图11所示,在一个实施例中,提供了一种检测模块1100。该检测模块1100包括比较单元1102和检测单元1104。
比较单元1102用于将所述簇的不同属性值与相应的属性阈值进行比较。
检测单元1104用于根据比较结果检测所述渠道标识对应的应用渠道是否使用了刷量工具。
具体地,检测单元1104用于检测所述簇的不同属性值中是否至少有一个属性值大于等于其相应的属性阈值,若是,则所述渠道标识对应的应用渠道使用 了刷量工具。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)等非易失性存储介质,或随机存储记忆体(Random Access Memory,RAM)等。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!