一种互联网数据聚类方法及系统与流程
本发明属于数据挖掘技术领域,尤其涉及一种互联网文本数据聚类方法及系统。
背景技术:
随着大数据时代的到来,数据挖掘领域中面临的数据变得越来越复杂。尤其是互联网文本数据,除了数量巨大之外,由矢量空间模型(Vector Space Model)构建的文本数据还具有超高的维度和稀疏度,现有的数据挖掘聚类算法,如k-means、层次聚类、普聚类等应用于文本聚类时,普遍存在不足和局限。
针对高维稀疏数据的子空间聚类问题,学术界提出了许多相关的子空间聚类算法(Subspace Clustering),软子空间聚类算法是其中的一类。依据加权的层数不同,软子空间聚类算法可以分为单层软子空间聚类算法和双层软子空间聚类算法。EW-k-means是典型的单层软子空间聚类算法。它假设特征集在每个聚类簇上都包含一组权重,权重大小由特征对该聚类簇形成的贡献大小决定。FG-k-means是由陈小军等人在2012年提出来的一种双层软子空间聚类算法,它引入了特征组的概念,在组与特征上同时加权,在对超高维稀疏数据进行聚类时,效果明显优于单层软子空间聚类算法。它针对特征空间包含分组信息的数据进行聚类,特征空间定义如下:
1)设训练数据集为X={x1,x2,…,xN},其中xi∈Rd(1≤i≤N)表示数据集中第i个样本;
2)上的特征集为V={v1,v2,…,vd},中的特征包含于组集合G={G1,G2,…,Gk}中且满足
FG-k-means算法需在以上形式的数据集上找出K个聚类簇,同时寻找每个聚类簇在组以及特征上对应子空间。
现有的FG-k-means算法在聚类性能上优于其他算法,但是还存在如下问题:FG-k-means算法需要使用特征组的信息,来完成双层聚类优化的目的,但是一般的文本数据中不会提供此类信息,限制了其应用的范围;FG-k-means存在初始中心点选取不同而导致的聚类结果的不稳定性的问题。
技术实现要素:
本发明提供了一种互联网文本数据聚类方法及系统,旨在至少在一定程度上解决现有技术中的上述技术问题之一。
本发明实现方式如下,一种互联网文本数据聚类方法,包括以下步骤:
一种互联网文本数据聚类方法,包括以下步骤:
步骤a:利用主题模型对文本数据进行训练,得到各个主题下所有关键词的概率分布矩阵,并在文本集合中为对关键词进行分组;
步骤b:根据关键词的分组重新组织文本数据的特征集,得到包含关键词分组特征信息的新的文档数据;
步骤c:在包含关键词分组信息的新文档数据上运行双层软子空间聚类算法,生成聚类中心矩阵和样本归属矩阵;
步骤d:重复n次步骤a至步骤c,得到多个聚类结果;
步骤e:在模型集合上运行聚类集成算法,将多个聚类结果进行集成,得到最终的聚类结果。
本发明实施例采取的技术方案还包括:在所述步骤a中,在主题模型中设置主题数量、聚类集成模型数据量和聚类簇的数量。
本发明实施例采取的技术方案还包括:在所述步骤a中,利用主题模型对文本数据进行训练时,在文本数据集上运行设置的相应主题数量的主题模型算法。
本发明实施例采取的技术方案还包括:在所述步骤c中,所述双层软子空间聚类算法采用FG-k-means算法。
本发明实施例采取的技术方案还包括:在所述步骤e中,所述将多个聚类结果进行集成具体包括:将同一数据集下的多个聚类结果进行融合,得到反应所述数据集内在结构的划分。
本发明实例采取的另一技术方案为:一种互联网文本数据聚类系统,包括文本数据训练模块、文本数据组织模块、文档数据计算模块、聚类结果循环模块和聚类结果集成模块,所述文本数据训练模块用于利用主题模型对文本数据进行训练,得到各个主题下所有关键词的概率分布矩阵,并在文本集合中为对关键词进行分组;所述文本数据组织模块用于根据关键词的分组重新组织文本数据的特征集,得到包含关键词分组特征信息的新的文档数据;所述文档数据计算模块在包含关键词分组信息的新文档数据上运行FG-k-means算法,生成聚类中心矩阵和样本归属矩阵;所述聚类结果循环模块用于重复文本数据训练、文本数据组织和文档数据计算过程,得到多个聚类结果;所述聚类结果集成模块用于在模型集合上运行聚类集成算法,将多个聚类结果进行集成,得到最终的聚类结果。
本发明实施例采取的技术方案还包括:所述文本数据训练模块还用于在主题模型中设置主题数量、聚类集成模型数据量和聚类簇的数量。
本发明实施例采取的技术方案还包括:所述文本数据训练模块在文本集合中为对关键词进行分组时,关键词在某个主题下出现的概率较高证明此关键词可以比较好的表达这个主题,将每个关键词留在出现概率最高的主题下,得到固定数量的不同主题。
本发明实施例采取的技术方案还包括:所述双层软子空间聚类算法是FG-k-means算法。
本发明实施例采取的技术方案还包括:所述聚类结果集成模块将多个聚类结果进行集成具体包括:将同一数据集下的多个聚类结果进行融合,得到反应所述数据集内在结构的划分。
本发明实施例的互联网文本数据聚类方法及系统利用主题模型提供的主题信息作为FG-k-means算法的特征组信息,使得本发明实施例的互联网文本数据聚类方法及系统能够从文本信息中自动提取特征组信息,从而规避了FG-k-means算法本身的限制;另外,本发明实施例的互联网文本数据聚类方法及系统融合了主题模型和特征组K均值的聚类集成方法,能有效降低FG-k-means算法的不稳定性。
附图说明
图1是本发明实施例的互联网文本数据聚类方法的流程图;
图2是本发明实施例的互联网文本数据聚类方法的过程示意图;
图3是本发明实施例的互联网文本数据聚类系统的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
请参阅图1,是本发明实施例的互联网文本数据聚类方法的流程图。本发明实施例的互联网文本数据聚类方法包括以下步骤:
步骤100:利用主题模型对文本数据进行训练,得到各个主题下所有关键词的概率分布矩阵,并在文本集合中为对关键词进行分组;
在步骤100中,可以在主题模型中设置主题数量、聚类集成模型数据量和聚类簇的数量;在文本集合中为对关键词进行分组时,关键词在某个主题下出现的概率较高证明此关键词可以比较好的表达这个主题,将每个关键词留在出现概率最高的主题下,这样就得到固定数量的不同主题。利用主题模型对文本数据进行训练时,在数据集上运行设置的相应主题数量的主题模型算法。
步骤200:根据关键词的分组重新组织文本数据的特征集,得到包含关键词分组特征信息的新的文档数据;
在步骤200中,依据和进行关键词过滤分组,并产生带有组信息的训练数据集合。
步骤300:在包含关键词分组信息的新文档数据上运行FG-k-means算法,生成聚类中心矩阵和样本归属矩阵;
步骤400:重复n次步骤100至步骤300,得到多个聚类结果;
在步骤400中,重复的次数可以为n次,n大于等于2,n可以实际的需求进行设定和更改。
步骤500:在模型集合上运行聚类集成算法,将多个聚类结果进行集成,得到最终的聚类结果。
在步骤500中,将同一数据集下的多个聚类结果进行融合,得到能较好反应该数据集内在结构的划分,聚类集成可有效降低数据集中异常点对聚类结果的影响,提升聚类质量。
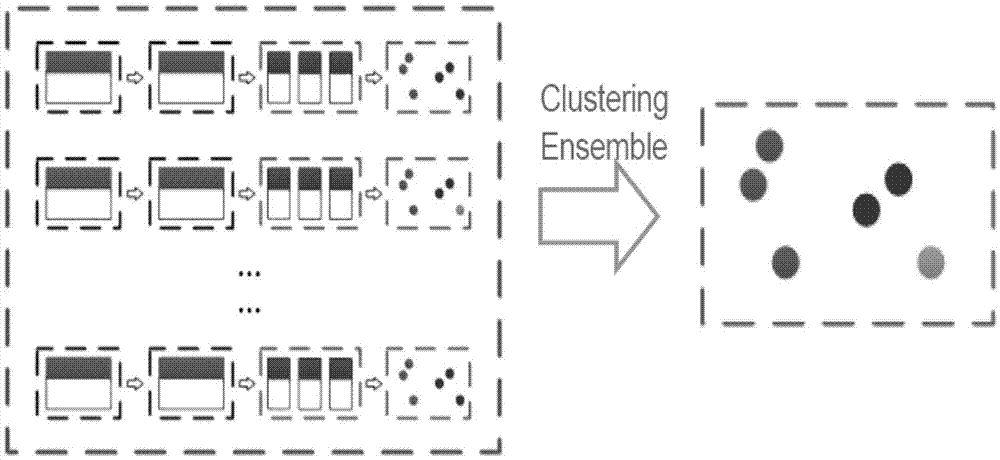
请参阅图2,是本发明实施例的互联网文本数据聚类方法的过程示意图。本发明实施例的互联网文本数据聚类方法的逻辑过程为:
请参阅图3,是本发明实施例的互联网文本数据聚类系统的结构示意图。本发明实施例的互联网文本数据聚类系统包括文本数据训练模块、文本数据组织模块、文档数据计算模块、聚类结果循环模块和聚类结果集成模块。
文本数据训练模块用于利用主题模型对文本数据进行训练,得到各个主题下所有关键词的概率分布矩阵,并在文本集合中为对关键词进行分组。可以在主题模型中设置主题数量、聚类集成模型数据量和聚类簇的数量;在文本集合中为对关键词进行分组时,关键词在某个主题下出现的概率较高证明此关键词可以比较好的表达这个主题,将每个关键词留在出现概率最高的主题下,这样就得到固定数量的不同主题。
文本数据组织模块用于根据关键词的分组重新组织文本数据的特征集,得到包含关键词分组特征信息的新的文档数据。
文档数据计算模块在包含关键词分组信息的新文档数据上运行FG-k-means算法,生成聚类中心矩阵和样本归属矩阵。
聚类结果循环模块用于重复文本数据训练、文本数据组织和文档数据计算过程,得到多个聚类结果。聚类结果循环模块可以重复n次文本数据训练、文本数据组织和文档数据计算过程,重复的次数可以为n次,n大于等于2,n可以实际的需求进行设定和更改。
聚类结果集成模块用于在模型集合上运行聚类集成算法,将多个聚类结果进行集成,得到最终的聚类结果。将同一数据集下的多个聚类结果进行融合,得到能较好反应该数据集内在结构的划分,聚类集成可有效降低数据集中异常点对聚类结果的影响,提升聚类质量。
本发明实施例的互联网文本数据聚类方法及系统利用主题模型提供的主题信息作为FG-k-means算法的特征组信息,使得本发明实施例的互联网文本数据聚类方法及系统能够从文本信息中自动提取特征组信息,从而规避了FG-k-means算法本身的限制;另外,本发明实施例的互联网文本数据聚类方法及系统融合了主题模型和特征组K均值的聚类集成方法,能有效降低FG-k-means算法的不稳定性。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!