一种基于SMOTE+Boosting算法的软件缺陷倾向预测方法与流程
本发明属于软件缺陷预测
技术领域:
,涉及软件质量预测中的软件缺陷预测技术,具体是指一种基于SMOTE和Boosting算法的软件缺陷倾向预测方法。
背景技术:
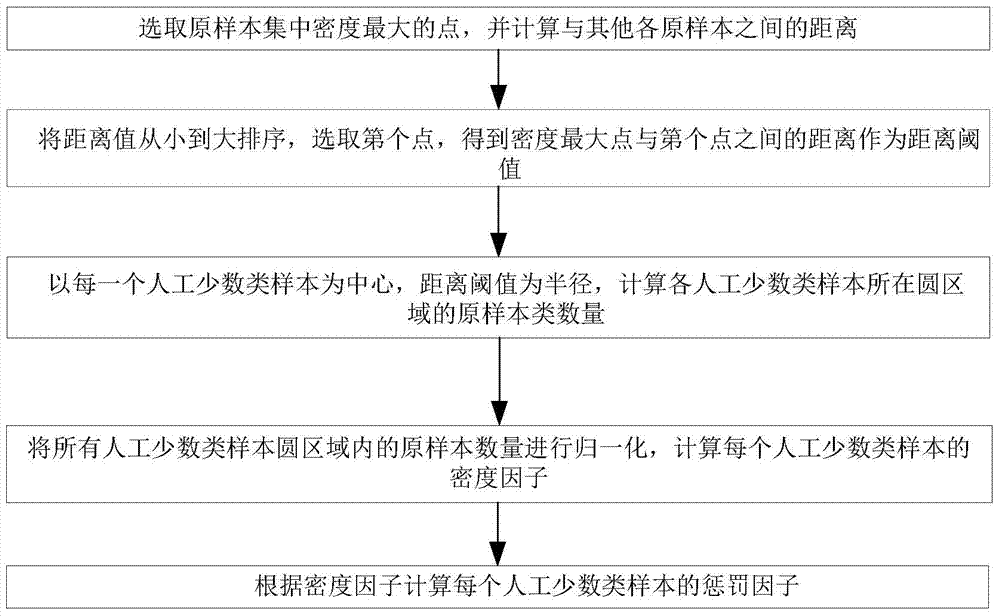
:随着计算机技术的不断发展以及软件在人们的生产和生活中的广泛应用,人们对软件质量和可靠性的要求越来越高。人们期望通过对软件质量进行准确地预测,用来指导软件开发过程的资源分配,保证按期交付软件产品的同时提高软件产品的质量。目前对软件的缺陷进行预测,是通过对软件所含缺陷的风险或数目进行预测以此来衡量软件的质量;采用模式识别算法或统计学理论构建软件缺陷预测模型,这种模型能从以往或相似软件项目中学习经验,并能够预测新开发的软件产品所具有的缺陷风险或数目。模式识别算法根据原始数据的特征向量归纳出判别函数即分类器,给被测对象赋予一个类别标记,实现分类;这种“基于样本的学习”方法是模式识别的一个中心问题。一般分为两个过程:训练和测试。训练是指用一定数量的样本来进行分类器的设计,测试是指用所设计的分类器对待识别的样本进行分类决策。一般而言,模式识别系统基于输入数据有无类标识可将其分为有监督模式识别系统和无监督模式识别系统。无监督模式识别又称聚类,是指将一组无类别的输入数据聚类到一个自然存在某种数据结构的有限离散类中,常用的方法是划分聚类和层次聚类。有监督模式识别是指将一组数据向量映射到有限组离散类中;从一组数据中学习是大多数模式识别系统的一个重要属性。统计模式识别是目前最流行的方法,它将数据视为特征,采用判别函数作为识别函数,选择分类错误率作为准则函数。常用的模式识别算法包括:线性判别算法、分类回归树、优化集精简方法、聚类分析、支持向量机、人工神经网络、逻辑回归、Boosting算法等但是这些学习模型都面临着一个软件缺陷数据不平衡的问题。在软件开发过程中,绝大多数缺陷存在于一少部分模块和代码中。软件缺陷数据样本集中“故障倾向/高风险”样本数目远远多于“非故障倾向/低风险”的样本数目,也就是多数类样本数目远远多于少数类样本数目,不平衡数据集问题导致提供给分类器的少数类信息不足,以分类错误率作为准则的分类器偏向于学习数量较多的多数类,以实现尽可能低的分类错误率为目标,少数类因为数量少,即使全部错判也能达到较低的分类错误率,因此不受分类器重视,导致少数类样本的识别准确率低。目前解决软件缺陷数据不平衡问题的技术主要分为两方面,数据层面和算法层面。数据层面采用数据采样的方法改变样本的分布,使数据达到平衡。采样的方法包括过采样,欠采样和混合采样。数据层面的采样方法中:欠采样随机去掉数据集中的多数类样本,降低数据集的不平衡程度,比较经典的欠采样方法有Tomeklinks(I.Tomek.TwoModificationsofCNN.IEEETransactionsonSystems,ManandCommunicationsSMC-6.769-772,1976.)、邻域清理法NCR(J.Laurikkala.ImprovingIdentificationofDifficultSmallClassesbyBalancingClassDistribution.Proceedingsofthe8thConferenceonAIinMedicineEurope:Artificial.63-66,2001.)、压缩最近邻CNN(M.KUBAT,S.MATWIN,Addressingthecourseofimbalancedtrainingsets:one-sidedselection.Proceedingsofthe14thInternationalConferenceonMachineLearning.SanFrancisco:MorganKaufmann,179-186,1997.),这些方法的不足之处是会丢失原样本的信息。过采样通过对少数类进行样本填充,补充少数类所具有的学习信息,SMOTE算法(N.V.Chawla,K.W.Bowyer.SMOTE:syntheticminorityover-samplingtechnique,JournalofArtificialIntelligenceResearch.Vol(16):341-378,2002.)是过采样中比较流行的方法,这种方法会改变原样本的分布,可能会增加虚假信息,甚至导致过拟合的问题。混合采样则是两种采样方法的结合,同样会产生丢失原样本信息和过拟合问题。算法层面改进传统分类算法,通过加入惩罚因子,赋予样本不同的权重等方法,使分类算法偏向于少数类。在算法层面中,常用的算法包括集成学习算法、代价敏感学习等。基于AdaBoost(R.Schapire,Y.Freund,P.BartlettandW.Lee,Boostingthemargin:Anewexplanationfortheeffectivenessofvotingmethods.InProceedingsInternationalConferenceonMachineLearningpp.LosAltos,pp322–330,1997.)的集成学习是给样本分配不同的权重,多轮迭代训练出多个弱分类器,每轮根据分类错误率更新样本的权重,对上一轮迭代分错的样本加大其对应的权重,对于正确分类的样本,降低其权重,并计算出每个弱分类器的权重,最后把这几个弱分类器按一定的权重叠加起来,得到强分类器;这种方法的优势在于可以集成大部分现有的分类器算法,通过每一轮迭代更新样本权重改变样本的分布空间,有利于挖掘更理想的类别分布和有代表性的样本,将多个分类器集成起来的方法可以降低过拟合的风险。AdaBoost方法在迭代中会给容易判错的少数类分配较高的权重,从而能使分类器偏重学习少数类;但是这种方法对分错的少数类和分错的多数类同样对待,依然会导致多数分类器偏重学习多数类,最终形成的强分类器对改善非平衡数据分类问题能力有限,不能得到令人满意的结果。代价敏感学习基于现实中少数类分错的代价一般大于多数类分错的代价,对不同类别的样本赋予不同的误分代价,对错误分类的少数类样本赋予更高的权重,是分类器更偏好于少数类样本。文献(Y.Sun,M.Kamel,A.Wong,Y.Wang,Cost-sensitiveboostingforclassificationofimbalanceddata,PatternRecognit.40(2007)3358–3378.)介绍了几种代表性的代价敏感学习算法如AdaC1、AdaC2、AdaC3,还有AdaCost(W.Fan,S.J.Stolfo,J.Zhang,P.K.Chan,Adacost:misclassificationcostsensitiveboosting,in:ProceedingsofSixthInternationalConferenceonMachineLearning(ICML-99),Bled,Slovenia,1999,pp.97–105.)、CSB2(K.M.Ting,Acomparativestudyofcost-sensitiveboostingalgorithms,in:Proceedingsofthe17thInternationalConferenceonMachineLearning,StanfordUniversity,CA,2000,pp.983–990.),这些方法需要人为根据实际需要给予样本代价,有较大的主观性影响,实际上很难根据现实信息给出合理的代价参数,不同样本集代价参数不同,使得算法的应用不能独立于数据集。少数类样本向学习器提供的学习信息过少,是软件缺陷非平衡数据给模式识别学习算法带来挑战的根本原因。SMOTE方法添加少数类,已经显示了良好的效果,通过与集成学习算法结合,综合了样本过采用和集成学习算法的优势,成为解决非平衡数据的学习问题的一个新方向。但是现有的算法如SmoteBoost(N.V.Chawla,A.Lazarevic,L.O.HallandK.W.Bowyer.Smoteboost:ImprovingPredictionoftheMinorityClassinBoosting.Proc.ofthe7thEuropeanConferenceonPrinciplesandPracticeofKnowledgeDiscoveryinDatabases,Dubrovnik,Croatia,107-119,2003.),在距离较近的两个样本之间添加样本,使少数类与多数类达到平衡,Databoost-IM(H-Y.GuoandH.L.Viktor.Learningfromimbalanceddatasetswithboostinganddatageneration:theDataBoost-IMapproachSIGKDDExplorations,6(1):30-39,2004.)也是将SMOTE与Boosting方法结合,在迭代过程中的每一轮都采用SMOTE算法对少数类和多数类中较难分类的样本进行采样,根据数据集的不平衡程度决定过采样的倍数,最后对两类数据的权重进行归一化,使两类样本的总权重相等。但是这些方法所添加的数据点往往是在少数类样本的高密度区域,这样添加的信息很有限。虽然通过此思路添加的人工样本具有较高的可信度,对少数类样本的数据分布影响不大,从模式识别学习模型角度分析,高密度样本分布区域已含有较多学习信息,反而在低密度区域学习信息缺乏,应该进行样本添加,当然在低密度区域添加样本,增大样本添加数量会导致所添加信息的可信度降低。原有的基于Boosting框架的非平衡数据学习方法在损失函数方面,没有对原有样本和人工样本进行区别对待,继续使用原有的面向监督性学习的损失函数,完全依赖样本类标准信息的准确度,是限制人工样本添加的区域和数量的根本原因。技术实现要素:本发明为了解决集成算法在数据非平衡的情况下少数类分类精度低的问题,提出了一种基于SMOTE+Boosting算法的软件缺陷倾向预测方法,包括以下几个步骤:步骤一:对每个软件项目中软件模块的多数类样本和少数类样本,分开随机抽取得到原样本集和总测试集;对少数类样本和多数类样本分开抽取,各抽80%作为训练集,20%作为测试集;将少数类样本和多数类样本的训练集合成一个原样本集O,测试集合成一个总测试集;步骤二:针对原样本集O中的少数类样本,采用SMOTE算法生成人工少数类样本集S,原样本集O与人工少数类样本集S共同构成总训练集L;人工少数类样本集S的数量为N。步骤三、计算每一个人工少数类样本的惩罚因子;具体步骤如下:步骤301、选取原样本集O中密度最大的点,并计算与其他各原样本之间的距离;原样本集O中样本的数量为m,密度最大点的选取方法为:针对每个样本,计算该样本到原样本集O中其他各样本之间的距离,得到m-1个距离值,将m-1个距离值从小到大进行排序,再对前k个最小距离值进行求和,找出和最小的样本为密度最大的点。k=C*log10(m)C为整数,取值范围为[3,6];k为选取距离值的个数;步骤302、将距离值从小到大排序,选取第n个点,得到密度最大点与第n个点之间的距离作为距离阈值dth;n=C1+C2*log10(m)C1,C2均为整数,且C1的取值范围为[5,15],C2的取值范围为[1,10]。步骤303、以每一个人工少数类样本为中心,距离阈值dth为半径,计算各人工少数类样本所在圆区域的原样本类数量;圆区域的原样本类数量包括:圆区域的原少数类样本数量与原多数类样本数量之和;计算方法如下:针对每个人工少数类样本,一一计算每个人工少数类样本与其他各原样本之间的距离,如果距离小于dth,则说明原样本属于该人工少数类样本的圆区域内,否则,不予考虑;从而得到每个人工少数类样本所在圆区域的原样本数量;步骤304、将所有人工少数类样本圆区域内的原样本数量进行归一化,计算每个人工少数类样本的密度因子βi;1≤i≤N;N为人工少数类样本数量;密度因子βi取值在[0,1]之间;计算公式如下:xi为第i个人工少数类样本;neighbood_numbers(xi)为第i个人工少数类样本所在圆区域的原样本数量;(neighbood_numbers(xi))max是指N个人工少数类样本所在圆区域的原样本数量中的最大值;步骤305、根据密度因子βi计算每个人工少数类样本的惩罚因子v(xi):k∈Z+,用于控制曲线的陡峭程度。步骤四、将每个人工少数类样本的惩罚因子v(xi)加入Boosting算法,确定损失函数C(F);xj为总训练集L中第j个训练样本;1≤j≤M;M为总训练集L的样本数量,M=m+N;当训练样本xj属于原样本集O时Ij∈O=1,Ij∈S=0,当训练样本xj属于人工少数类样本集S时,Ij∈S=1,Ij∈O=0。yj表示样本的类别,取1表示训练样本xj属于多数类样本,取-1表示训练样本xj属于少数类样本或者人工少数类样本。F(xj)表示联合分类器对训练样本xj的判别输出,取值为+1或-1。Adaboost的损失函数使用的是指数函数的形式,即C(z)=e-z,代入公式C(F),损失函数C(F)分为两部分,一部分是原样本集O的损失函数,另一部分是人工少数类样本集S的损失函数,将惩罚因子v(xi)加入到人工少数类样本集S的损失函数中,原样本集O仍用原来的损失函数,从而使分类器区别学习原样本集O和人工少数类样本集S。步骤五、求解损失函数C(F)得到推导样本权重和分类器权重;根据损失函数C(F)推导样本权重Dt(xj):Ft(xj)表示第t轮迭代得到的联合分类器对训练样本xj的判别输出;分类器权重ωt+1等于第t+1轮学习所得的分类器分对的样本权重之和与分错样本的权重之和的比值;计算公式如下:ft+1(xj)表示第t+1轮迭代训练所得的基本分类器对训练样本xj的预测输出。ft+1(xj)=yj表示基本分类器ft+1对训练样本xj的预测输出,等于训练样本xj的类别yj,则表示基本分类器ft+1对训练样本xj分类正确。反之ft+1(xj)≠yj表示基本分类器ft+1对训练样本xj分类错误。步骤六、设置循环迭代利用总训练集L训练基本分类器,形成强分类器F(x);T为循环迭代次数;ft(x)是第t轮迭代所得的基本分类器;步骤七、用总测试集对强分类器F(x)进行测试验证;通过测试验证,该强分类器F(x)的各项评价指标均有所提高,提高了少数类识别能力的软件缺陷倾向预测。本发明的优点:(1)一种基于SMOTE+Boosting算法的软件缺陷倾向预测方法,不是对所有样本都等同对待,而是给人工少数类样本添加惩罚因子,使样本的权重分布更合理。(2)一种基于SMOTE+Boosting算法的软件缺陷倾向预测方法,根据样本本身信息计算惩罚因子,避免人工设置惩罚因子带来的主观性。(3)一种基于SMOTE+Boosting算法的软件缺陷倾向预测方法,不需要复杂的人工样本添加算法,采用SMOTE算法生成的人工样本分布更具随机性,通过惩罚因子过滤不合理的人工样本。(4)一种基于SMOTE+Boosting算法的软件缺陷倾向预测方法,距离阈值dth计算简单,反映了样本自身的分布信息,避免了大量的距离计算。(5)一种基于SMOTE+Boosting算法的软件缺陷倾向预测方法,与AdaBoost算法相比,提高了总体分类精度和少数类分类精度。附图说明图1是本发明基于SMOTE+Boosting算法的软件缺陷倾向预测方法流程图;图2是本发明计算每个人工少数类样本的惩罚因子流程图。具体实施方式下面将结合附图对本发明作进一步的详细说明。本发明结合过采样增加数据信息和AdaBoost算法减少过拟合问题的优势,先用SMOTE方法给训练集增加人工少数类样本的数量,使少数类与多数类数量达到平衡,然后再对每个人工少数类样本所在区域的原样本密度归一化,作为惩罚因子,将惩罚因子加入到人工少数类样本的损失函数中,原样本仍使用原来的损失函数,惩罚因子调节人工少数类样本的权重,使分类器区别对待人工少数类样本与原样本,更加偏重学习原样本和可信度高的人工少数类样本,最终确定新Boosting的损失函数,每一轮迭代新的AdaBoost算法更新样本的权重。最后基于新的损失函数形成新的Boosting算法,使新Boosting在新提出的损失函数的指导下,搜索最优解函数。一种基于SMOTE+Boosting算法的软件缺陷倾向预测方法,如图1所示,包括以下几个步骤:(以下距离均使用欧氏距离):步骤一:对每个软件项目中软件模块的多数类样本和少数类样本,分开随机抽取得到原样本集和总测试集;少数类样本是指故障倾向/高风险模块;多数类样本是指非故障倾向/低风险模块;对数据集中少数类样本和多数类样本分开随机抽取,各抽80%作为训练集,20%作为测试集;保证最终的训练集和测试集中少数类与多数类比例不变。将少数类样本和多数类样本的训练集合成一个原样本集O,测试集合成一个总测试集;步骤二:针对原样本集O中的少数类样本,采用SMOTE算法生成人工少数类样本集S,原样本集O与人工少数类样本集S共同构成总训练集L;调用数据挖掘软件weka的SMOTE函数,对原样本集O中的少数类样本进行采样,将生成的人工少数类样本集S添加进原样本集O中,形成总训练集L;采样倍数为多数类样本数量与少数类样本数量的比值。人工少数类样本的数量N。步骤三、计算每一个人工少数类样本的惩罚因子v(xi);如图2所示,具体步骤如下:步骤301、选取原样本集O中密度最大的点,并计算与其他各原样本之间的距离;密度最大点的选取方法为:用原样本集O中每个样本到离其最近的k个样本的距离之和作为其密度衡量,到邻近的k个样本距离之和最小的那个样本就是密度最大的样本。具体为:针对每个样本,计算该样本到原样本集O中其他各样本之间的距离,得到m-1个距离值,将m-1个距离值从小到大进行排序,再对前k个最小距离值进行求和,找出和最小的样本为密度最大的点。k=C*log10(m)C为整数,取值范围为[3,6];k为选取距离值的个数;本实施例选取10个。因为如果样本位于密度越大的区域,那么它周围的点就越聚集,即到周围的点的距离就越近。步骤302、将距离值从小到大排序,选取第n个点,计算密度最大点与第n个点之间的距离作为距离阈值dth;距离阈值dth根据原样本集O来计算,用于后面计算人工样本的密度。dth取最密集点到其他所有点的距离从小到大排序的第n位点的距离,是一种规定上限的方法,保证样本密度的平滑性,防止样本密度值差距过于悬殊。以dth为半径的圆内样本的数量来衡量样本密度,dth太大样本密集程度可能差异太大而不能准确的衡量样本的密度,dth太小又可能导致过多的离散点产生,尤其是对于小样本集,通常比较稀疏,同样不能恰当地衡量样本的密度。因此,dth的值保证位于最密集区域的样本以dth为半径的圆内最少有C1个样本,并随着样本集数量的增加而以对数形式增加,dth只用原样本数据进行计算,距中心样本的距离小于dth的样本数量衡量中心样本的密度。最密集点的个数半径公式如下:n=C1+C2*log10(m)m为原样本集O中样本的数量;C1,C2均为整数,且C1的取值范围为[5,15],C2的取值范围为[1,10]。本实施例中C1取10,C2取5。步骤303、以每一个人工少数类样本为中心,距离阈值dth为半径,计算各人工少数类样本所在圆区域的原样本类数量;圆区域的原样本类数量包括:圆区域的原少数类样本数量与原多数类样本数量之和;计算方法如下:针对每个人工少数类样本,一一计算每个人工少数类样本与其他各原样本之间的距离,如果距离小于dth,则说明原样本属于该人工少数类样本的圆区域内,否则,不予考虑;从而得到每个人工少数类样本所在圆区域的原样本数量;步骤304、将所有人工少数类样本圆区域内的原样本数量进行归一化,计算每个人工少数类样本的密度因子βi;1≤i≤N;N为人工少数类样本数量;密度因子βi取值在[0,1]之间;计算公式如下:xi为第i个人工少数类样本;neighbood_numbers(xi)为第i个人工少数类样本所在圆区域的原样本数量;(neighbood_numbers(xi))max是指N个人工少数类样本所在圆区域的原样本数量中的最大值;βi与样本的密度成反比,即密度大的区域,认为信息较多,不需要过多地学习,因此给予较低的权重,对于密度较小的区域,信息较少,给予较高的权重,着重学习。步骤305、根据密度因子βi计算每个人工少数类样本的惩罚因子v(xi):k∈Z+,用于控制曲线的陡峭程度,本实施例优选k为2。考虑每个人工样本所在区域的密度,密度大的地方多数类较密集,在此区域生成的人工样本比较危险,容易导致少数类向多数类分布区域过度延伸,应减小惩罚值,不予以过多地学习,反之,密度小的地方增大惩罚值,将所有人工样本的密度值标准化后,用正弦函数映射到[0,1]区间得到惩罚因子v(xi)。步骤四、将每个人工少数类样本的惩罚因子xi加入Boosting算法,确定新的损失函数C(F);首先将Boosting算法的损失函数分为两部分,一部分是原样本的损失函数,另一部分是人工样本的损失函数,将惩罚因子加入到人工样本的损失函数中,原样本仍用原来的损失函数,根据新的损失函数得到新的样本分布权重公式,分类器权重公式,迭代停止的条件仍然不变即保证每一轮迭代所得的基本分类器分错的样本权重之和要小于分对的样本权重之和,因为分类器对训练集的所有样本分错的权重和分对的权重之和等于1,所以分类器分错的样本的权重之和小于0.5,也就是说当分错的权重之和大于0.5时,迭代就停止,不再继续学习,最后的强分类器由前面训练所得的基本分类器联合而得;从而实现对原样本和人工样本的区别学习。M为总训练集L的样本数量,M=m+N;当训练样本xj属于原样本时Ij∈O=1,Ij∈S=0,,当训练样本xj属于人工样本时,Ij∈S=1,Ij∈O=0。yj表示样本的类别,取1表示多数类样本,取-1表示少数类样本或者人工少数类样本。F(xj)表示联合分类器对训练样本xj的判别输出,取值为+1或-1。Adaboost的损失函数使用的是指数函数的形式,即C(z)=e-z,代入公式C(F),步骤五、求解新的损失函数C(F)得到推导样本权重和分类器权重;根据新的损失函数推导样本权重Dt(xj):Ft(xj)表示第t轮迭代得到的联合分类器对训练样本xj的判别输出;每一轮迭代都训练得到一个基本分类器,该轮迭代结束后得到的基本分类器将被加入以前迭代所得的分类器中。分类器权重ωt+1等于该分类分对的样本权重之和与分错样本的权重之和的比值;计算公式如下:ft+1(xj)表示第t+1轮迭代训练所得的基本分类器对训练样本xj的预测输出。ft+1(xj)=yj表示基本分类器ft+1对训练样本xj的预测输出,如果等于训练样本xj的类别yi,则表示基本分类器ft+1对训练样本xj分类正确。反之ft+1(xj)≠yj表示基本分类器ft+1对训练样本xj分类错误。步骤六、设置循环迭代利用训练集训练基本分类器,形成一个强分类器;T为循环迭代次数;ft(x)是第t轮迭代所得的基本分类器,每个样本都有一个权重;每一轮迭代后所有的样本权重都会被更新,在某一轮迭代过程中若某个样本被已训练好的基本分类器分错,那么该样本的样本权重就会提高,分对样本权重就会降低;分别以weka软件中J48,KNN,DecisionStump作为基本分类器,利用训练集训练出T个基本分类器,最终形成一个强分类器;设置循环迭代次数T=100,即利用训练集训练出100个基本分类器,最终形成一个强分类器;步骤七、用测试集对新生成的强分类器进行测试验证;最终的分类器输出将AdaBoost+J48+SMOTE算法,AdaBoost+KNN+SMOTE算法,以及AdaBoost+DecisionStump+SMOTE算法与本发明WeightedSmoteBoost+J48算法,WeightedSmoteBoost+KNN算法,WeightedSmoteBoost+DecisionStump算法分别进行测试,其中KNN分类器中设置K=3,其他均用weka中的默认值,最后比较基本评价指标。计算针对非平衡分类器的基本评价标准:Recall,Precision,F-measure,G-mean.通过测试验证,该强分类器的各项评价指标提高,提高少数类识别能力的软件缺陷倾向预测。具体实施例:实施例的数据来源于公开的NASAMDP(MetricsDataProgram,简称MDP),NASAMDP是美国宇航局收集、验证、组织、存储和传递软件度量数据。选择NASAMDP中的5个相关项目数据,每个项目都包含了详细的度量指标量化值和软件模块的错误数据等信息。这5个相关项目基本情况如下:CM1项目:由C实现的科学仪器项目。总模块数为344;非故障倾向/低风险模块数为302;故障倾向/高风险模块数为42。MC2项目:由C实现的视频向导系统执行软件。总模块数为127;非故障倾向/低风险模块数为83;故障倾向/高风险模块数为44。MW1项目:由C实现的零重力实验软件。总模块数为204;非故障倾向/低风险模块数为237;故障倾向/高风险模块数为27。KC3项目:由JAVA实现的实现卫星数据收集、处理、传递的应用软件。总模块数200;非故障倾向/低风险模块数为164;故障倾向/高风险模块数为36。PC1项目:由C实现的一个已经不再使用的地球轨道卫星飞行软件。总模块数为759;非故障倾向/低风险模块数为698;故障倾向/高风险模块数为61。5个相关项目各个数据集的不平衡比例如表1所示:表1少数类多数类少数类:多数类采样比例PCM1423021:7600MC244831:1.87100MW1272371:8.78800KC3361641:4.56400PC1616981:11.441100首先,对数据集进行采样:将各个数据集随机划分为80%训练集和20%测试集后,分别对各个训练集调用weka软件中的SMOTE算法进行过采样。采样倍数约为少数类和多数类的不平衡比例。然后,对基本分类器进行训练,测试:将数据集进行分割与采样后,用同一训练集,采样集和测试集分别对AdaBoost+基本分类器+SMOTE,本发明算法WeightedSmoteBoost+基本分类器进行训练。对每套数据集分别进行五次随机分割,采样,进行五次训练和测试,最终的结果取五次结果的平均值。最后,对分类效果进行评价:对于非平衡分类问题,取较为流行的Recall、Precision、F-measure、G-mean、Accuracyrate作为各个分类器的评价指标。这些评价指标的定义如下:TP是将正样本(少数类)判对的个数,FN为将正样本判为负样本(多数类)的个数,FP是将负样本判为正样本的个数,TN是负样本判对的个数。Recall(P)又称召回率,表示正样本判对的个数占预测前正样本总数的比例,Recall(N)表示负样本判对的个数占预测前负样本总数的比例。Precision表示正样本判对的个数占预测后正样本总数(包括负样本判为正样本的个数)的比例。F-measure表示Recall(P)和Precision的调和平均数,综合衡量这两个指标。G-mean同时考虑了正样本的召回率和负样本的召回率。Accuracyrate表示总体准确率,即预测正确的样本占总样本的比例。实验所得分类效果如下列各表表示:表2Recall(P)表3Precision表4F_measure表5G_mean表6Accuracyrate从以上各表可以看出本发明提出的SMOTE+Boosting的软件缺陷预测模型提高了少数类分类精度,同时又能减少多数类判错的个数,对Recall、Precision、F-measure、G-mean、Accuracyrate都取得了很好的效果:(1)本发明提出的改进算法通过给人工样本增加惩罚因子,使分类器着重学习可信度高的原样本,避免对人工样本的学习而忽略了原来的少数类样本,甚至导致边界导向不可信的人工样本的伪边界,从而提高少数类的召回率(Recall(P))。其中以J48为基本分类器的Recall(P)比以KNN和DecisionStump为基本分类的Recall(P)提高的更为显著。(2)本发明的方法对在多数类密集的区域生成的人工样本降低了权重,避免分类边界向多数类过度延伸,从而减少多数类判错的数量,提高了Precision、F-measure、G-mean值。(3)总体准确率大样本集PC3提高没有其他较小样本集显著,原因是对大样本集少数类样本更多也更密集,用SMOTE算法生成的人工样本更加聚集,对多数类样本区域的扩张的程度不大,所以人工样本的惩罚程度较小,用AdaBoost算法已经可以取得很好的效果,效果没有其他较小样本显著。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1