一种账号风险评估方法和设备与流程
本申请涉及互联网安全技术领域,特别涉及一种账号风险评估方法。本申请同时还涉及一种账号风险评估设备。
背景技术:
随着互联网技术的日新月异以及不断发展,人们越来越倾向于通过网络上能够提供服务的在线系统完成自身所需要的各类需求。正因于此,目前的在线系统所面临的安全攻击也日趋复杂化、多元化、海量化。举例来说,现有的恶意用户往往通过对在线系统实现“盗用支付账户、盗用银行卡、诈骗、营销作弊、倒买倒卖”等一系列违法的行为,在恶意用户实行这些违法行为的过程中,其账号往往扮演了很重要的角色。
发明人在实现本申请的过程中发现,现有的在线系统中的用户账号的数量都是海量级别的,而对于在线系统的管理人员而言,其所知晓的是否具有风险的用户账号的数量只是很小一部分,因此如何基于已知风险的用户账号,准确且高效地对在线系统中其他未知风险的用户帐户进行风险评估,成为本领域技术人员亟待解决的技术方案。
技术实现要素:
针对现有技术中尚缺乏有效的方式来对网络中各用户帐户的风险进行评估的缺陷,本申请提出了一种账号风险评估方法,用以实现高效地评估网络中的风险,该方法包括:
根据待评估账号当前各个风险特征的量化值生成所述待评估账号的综合特征值,所述量化值根据所述风险特征对应的原始变量的取值以及账户样本 中各所述原始变量的样本数据生成;
判断所述综合特征值是否大于预设的阈值,;
若是,确定所述待评估账号存在风险;
若否,确定所述待评估账号无风险。
优选地,在根据待评估账号当前各个风险特征的量化值生成所述待评估账号的综合特征值之前,还包括:
获取所述待评估账号的各个风险特征所对应的原始变量的取值,以及各所述原始变量在账户样本中样本数据,所述帐户样本为在线系统中具有操作记录的;
根据所述取值以及所述样本数据确定所述风险特征的量化值;
根据所述量化值以及为所述风险特征预设的风险权重生成与所述风险特征对应的子特征值;
根据所述子特征值以及当前存在的其他风险特征的子特征值生成所述综合特征值。
优选地,所述样本数据包含所述帐户样本中好样本的数量以及坏样本的数量,通过以下公式确定所述风险特征的量化值:
其中,nbad和ngood为对所述取值进行分bin操作后每个bin内所述坏样本和所述好样本的数量,Nbad和Ngood为所述坏样本和所述好样本的数量。
优选地,在获取所述待评估账号的各个风险特征所对应的原始变量的取值之前,还包括:
根据直接数据源以及间接数据源获取当前存在的所有账号的原始变量的取值,所述直接数据源对应于在系统中具有操作行为记录的第一账号,所述间接数据源对应于与所述第一账号具有关联操作的第二账号;
根据当前存在的所有账号,以及所述所有账号的原始变量的取值,生成所述数据库;
根据历史帐户风险处理数据从所述数据库中筛选所述账户样本。
优选地,根据所述子特征值以及当前存在的其他风险特征的子特征值生成所述综合特征值,具体为:
判断所述风险特征是否存在上一层的分类特征;
若存在所述分类特征,根据所述分类特征包含的风险特征的子特征值以及为所述分类特征预设的权重生成所述分类特征的分类特征值,并根据所述分类特征值以及当前存在的其他分类特征的分类特征值生成所述综合特征值;
若不存在所述分类特征,将所述子特征值与当前存在的其他风险特征的子特征值的综合作为所述综合特征值。
相应地,本申请还提出了一种账号风险评估设备,包括:
第一生成模块,根据待评估账号当前各个风险特征的量化值生成所述待评估账号的综合特征值,所述量化值根据所述风险特征对应的原始变量的取值以及账户样本中各所述原始变量的样本数据生成;
判断模块,判断所述综合特征值是否大于预设的阈值,;
若是,所述判断模块确定所述待评估账号存在风险;
若否,所述判断模块确定所述待评估账号无风险。
优选地,还包括:
第一获取模块,获取所述待评估账号的各个风险特征所对应的原始变量的取值,以及各所述原始变量在账户样本中样本数据,所述帐户样本为在线系统中具有操作记录的;
确定模块,根据所述取值以及所述样本数据确定所述风险特征的量化值;
第二生成模块,根据所述量化值以及为所述风险特征预设的风险权重生 成与所述风险特征对应的子特征值;
第三生成模块,根据所述子特征值以及当前存在的其他风险特征的子特征值生成所述综合特征值。
优选地,所述样本数据包含所述帐户样本中好样本的数量以及坏样本的数量,所述确定模块通过以下公式确定所述风险特征的量化值:
其中,nbad和ngood为对所述取值进行分bin操作后每个bin内所述坏样本和所述好样本的数量,Nbad和Ngood为所述坏样本和所述好样本的数量。
优选地,还包括:
第二获取模块,根据直接数据源以及间接数据源获取当前存在的所有账号的原始变量的取值,所述直接数据源对应于在系统中具有操作行为记录的第一账号,所述间接数据源对应于与所述第一账号具有关联操作的第二账号;
第四生成模块,根据当前存在的所有账号,以及所述所有账号的原始变量的取值,生成所述数据库;
筛选模块,根据历史帐户风险处理数据从所述数据库中筛选所述账户样本。
优选地,所述第三生成模块具体用于:
判断所述风险特征是否存在上一层的分类特征;
若存在所述分类特征,所述第三生成模块根据所述分类特征包含的风险特征的子特征值以及为所述分类特征预设的权重生成所述分类特征的分类特征值,并根据所述分类特征值以及当前存在的其他分类特征的分类特征值生成所述综合特征值;
若不存在所述分类特征,所述第三生成模块将所述子特征值与当前存在的其他风险特征的子特征值的综合作为所述综合特征值。
通过应用上述技术方案,在根据待评估账号当前各个风险特征的量化值生成待评估账号的综合特征值后,再判断综合特征值是否大于预设的阈值,若是则确定待评估账号存在风险,若否则确定待评估账号无风险,由于量化值是根据风险特征对应的原始变量的取值以及账户样本中各原始变量的样本数据生成,因此本申请能够从数据的角度对用户账户进行有效的风险评估,提高网络的安全性。
附图说明
图1为本申请实施例公开的一种账号风险评估方法的流程示意图;
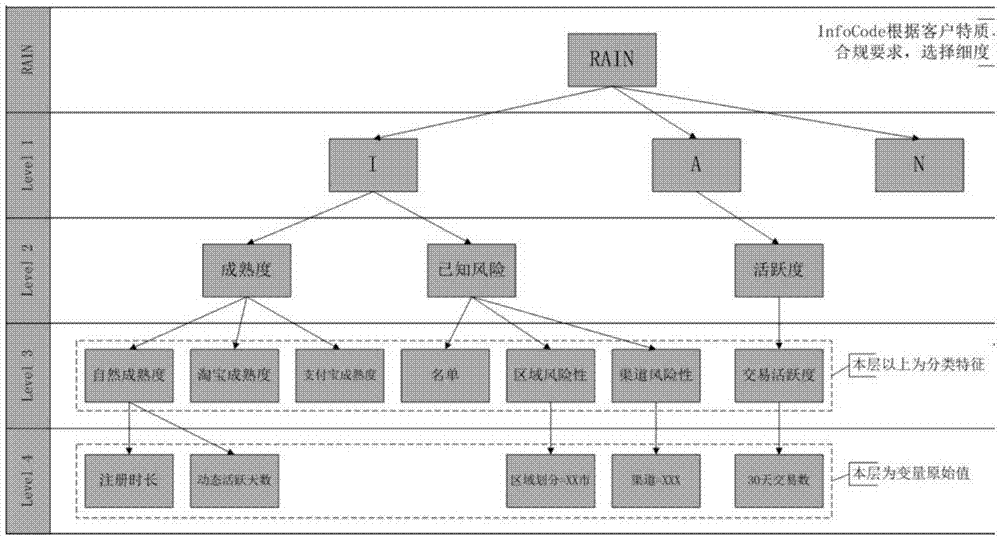
图2为本申请实施例公开的一种多层次的特征体系的示意图;
图3为本申请实施例公开的一种账号风险评估设备的结构示意图。
具体实施方式
如背景技术所述,现有技术中没有有效地方式来对网络中的风险进行评估的缺陷,本申请提出了一种账号风险评估方法,用以在已有的帐户样本基础上对其他用户帐户的风险进行高效且准确的风险评估,从而提高网络的安全性。
如图1所示,该方法包括以下步骤:
步骤101、根据待评估账号当前各个风险特征的量化值生成所述待评估账号的综合特征值,所述量化值根据所述风险特征对应的原始变量的取值以及账户样本中各所述原始变量的样本数据生成。
由于本申请旨在针对网络中的存在风险的用户帐户进行评估,因此本申请中的待评估对象是与用户在使用网络过程中关联广泛而紧密的账号。在网络特别是移动互联网普及的过程中,考虑到手机号与自然人以及账号等逐渐建立了广泛的捆绑映射关系,因此待评估对象可以是手机号,除此以外,也可以 是其他的,例如微信号,qq号,电话号码等等。
需要说明的是,在该步骤中所涉及的原始变量为与用户账户相关的信息,如注册时长、动态活跃天数、划分区域、渠道以及交易数量等,原始变量的取值为该原始变量所对应的数据。例如已注册天数、具体的区域(可以通过IP地址识别、)以及渠道等。
具体地,在本申请的优选实施例中,通过以下步骤生成综合特征值:
步骤a)获取所述待评估账号的各个风险特征所对应的原始变量的取值,以及各所述原始变量在账户样本中样本数据,所述帐户样本为在线系统中具有操作记录的;
步骤b)根据所述取值以及所述样本数据确定所述风险特征的量化值;
步骤c)根据所述量化值以及为所述风险特征预设的风险权重生成与所述风险特征对应的子特征值;
步骤d)根据所述子特征值以及当前存在的其他风险特征的子特征值生成所述综合特征值。
基于上述步骤,当拥有足够数量且有可靠样本标记的数据时,本申请的具体实施例将建立风控模型。其中可靠样本标记的含义为:手机号数据中,对每个手机号是否有风险,都有基于历史事实信息的准确的“good”或者“bad”的打标。可靠样本标记一般从历史数据(例如赔付、用户投诉被盗用等)以及人工判断(例如通过回护用户等)等方式获得。
以手机号1为例,例如手机号1对应的账号中购物记录(历史数据)有6条,都是正常的(好样本),也即对应的好样本的数量为6,而手机号1还对应有欺诈的1个评价,对应的坏样本的数量为1,当然,除了可以通过历史数据来对待评估对象的原始数据进行是否有风险的评判以外,还可以以人工的方式进行评估,以人工的方式来判断待评估对象的原始数据是否存在风险, 以及认为有风险的数量和没有风险的数量。
在本申请的具体实施例中,样本数据包含帐户样本中好样本的数量以及坏样本的数量,在基于样本数据确定量化值时,可采用以下公式:
其中,nbad和ngood为对所述取值进行分bin操作后每个bin内所述坏样本和所述好样本的数量,Nbad和Ngood为所述坏样本和所述好样本的数量。
需要说明的是,尽管本申请提出了以上具体的实施方式生成待评估账号的综合特征值,但本申请并不仅限于此,在基于量化值生成综合特征值以及根据风险特征对应的原始变量的取值以及账户样本中各原始变量的样本数据生成量化值的基础上,技术人员可以采取其他方式同样获取到综合特征值以及量化值,这些都属于本申请的保护范围。
此外,为了保证样本数据的稳定以及可靠,在该步骤中提供准确的帐户样本,本申请优选实施例在该步骤之前还可执行以下步骤:
步骤a)根据直接数据源以及间接数据源获取当前存在的所有账号的原始变量的取值,所述直接数据源对应于在系统中具有操作行为记录的第一账号,所述间接数据源对应于与所述第一账号具有关联操作的第二账号;
步骤b)根据当前存在的所有账号,以及所述所有账号的原始变量的取值,生成所述数据库;
步骤c)根据历史帐户风险处理数据从所述数据库中筛选所述账户样本。
仍以手机号为例来进行说明,存在直接关系的数据源中包含的数据是在系统中通过手机号进行过注册,支付等历史操作的手机号,例如某购物网站中注册的账户对应的手机号;而存在间接关系的数据源中包含的数据则为在 系统中没有历史行为,但是与系统中已有手机号通过通信、社交网络等建立明确关系的手机号,例如在购物网站1中注册的帐号关联有手机号2,而手机号3与购物网站1中注册的账号都不关联,但是手机号3与手机号2存在通信联系,在此情况下,手机号3就属于存在间接关系的数据源中的数据,通过在存在直接关系的数据源以及存在间接关系的数据源转换提取样本数据,可以保证足够的数量
步骤102、判断所述综合特征值是否大于预设的阈值。
为了便于对帐户风险进行评估,本申请优选实施例中构建了层次化的特征体系,用于保证特征体系的可拓展、可折叠,从而对特征有清晰的梳理避免重复遗漏,并且可以应对不同层次的特征解释需求。因此,在本申请的优选实施例中,基于各个风险特征的子特征值,首先判断所述风险特征是否存在上一层的分类特征,随后基于以下情况分别进行处理:
(1)若存在所述分类特征,根据所述分类特征包含的风险特征的子特征值以及为所述分类特征预设的权重生成所述分类特征的分类特征值,并根据所述分类特征值以及当前存在的其他分类特征的分类特征值生成所述综合特征值;
(2)若不存在所述分类特征,将所述子特征值与当前存在的其他风险特征的子特征值的综合作为所述综合特征值。
在图2所示的具体体系示意图中,原始特征构建的是最底层,也即图2中的第4层,后续基于第4层的特征向上构建第3层的特征,再由第3层的特征构建第2层的特征,以此类推,直到构建出最高层,其中构建的多层次的特征体系中,上一层的特征会对应有下一层的一个或多个特征,例如第2层中的成熟度特征就对应有3个第3层的特征(分别为自然成熟度,淘宝成熟度,支付宝成熟度),由于每层都是整体风险的一种表达方式,同一层特征 之间具有可比性,因此逐层向下拆解为更细化的特征,逐层向上汇总成更高层的特征。具体的,图2中各个层级的解释及说明如下:
Level 1中包括:Activity(行为类特征),Identity(身份特质类特征),Network(关系网络类特征);
Level 2中包括:在Level 1的三个大类下细化的子类特征,例如:Activity_Anomaly(行为异常性),Activity_Pattern(行为模式性)。
Level 3中包括:在Level 2的基础上进一步细化的子类特征,例如:Activity_Anomaly_Purchase(购物行为异常性)。
Level 4,也即原始特征的层次,保存的是用于构造Level 3特征的原始特征。因为原始特征是构建多层次特征体系的基础,因此最底层的数据会基于安全进行保密。
以图2中的特征注册时长为例,若样本数据中包含有1000个样本,也即800个好样本,200个坏样本,在此情况下,会对该特征进行二次取样,例如取样为100个,二次取样中的好样本数量为78,而坏样本的数量为22,在此情况下,基于公式来进行计算该特征的子特征值WOE(weight of evidence),其中,nbad和ngood为对特征进行二次取样的操作后二次取样的样本中坏样本的数量(在此为22)和好样本的数量(在此为22),Nbad和Ngood为全量样本种坏样本的数量(在此为200)和好样本的数量(在此为800),后续可以基于最底层的各特征的子特征值以及对应关系来确定上一层的特征的子特征值,例如最底层的特征有3个,分别为特征1(子特征值0.31),特征2(子特征值0.33),特征3(子特征值0.51),而次底层中有特征4,其中特征4对应的最底层的特征为特征1和特征3(也即特征4在最底层的特征细化为特征1和特征3),在此情况下,特征4的子特征值即为特征1的子特征值与特征3的子特征值的和,也即0.82=0.31+0.51, 至于其他的层次中的其他特征,以此类似,基于对应关系以及特征的子特征值进行累加处理,基于这种方式,各个特征的重要性是等价的,也即特征的权重是一样的,例如特征4的子特征值可以表示为0.82=0.31×1+0.51×1,在对特征4进行风险评估是,特征1和特征3的权重是一样的。
在确定了最高层的特征的综合特征值也即待评估对象的综合特征值之后,可以与预设的一个或多个阈值进行比较,从而确定是否存在风险以及风险等级,当然也可以有别的方式来进行确定,在此不再进行赘叙。
具体的,仍以手机号为例,当手机号1的确定是存在风险的,在此情况下,由于账号1以及用户1是与手机号1关联的,因此可以基于手机号1来确定账号1以及用户1也存在风险,当然具体的,由于对象有所不同,其对应的风险级别可能是不同的,具体可以基于具体的环境进行调整,这些都属于本申请的保护范围。
由此可见,通过采用上述技术方案,在根据待评估账号当前各个风险特征的量化值生成待评估账号的综合特征值后,再判断综合特征值是否大于预设的阈值,若是则确定待评估账号存在风险,若否则确定待评估账号无风险,由于量化值是根据风险特征对应的原始变量的取值以及账户样本中各原始变量的样本数据生成,因此本申请能够从数据的角度对用户账户进行有效的风险评估,提高网络的安全性。
为达到以上技术目的,本申请实施例还公开了一种账号风险评估设备,如图3所示,包括:
第一生成模块310,根据待评估账号当前各个风险特征的量化值生成所述待评估账号的综合特征值,所述量化值根据所述风险特征对应的原始变量的取值以及账户样本中各所述原始变量的样本数据生成;
判断模块320,判断所述综合特征值是否大于预设的阈值,;
若是,所述判断模320块确定所述待评估账号存在风险;
若否,所述判断模块320确定所述待评估账号无风险。
优选地,还包括:
第一获取模块,获取所述待评估账号的各个风险特征所对应的原始变量的取值,以及各所述原始变量在账户样本中样本数据,所述帐户样本为在线系统中具有操作记录的;
确定模块,根据所述取值以及所述样本数据确定所述风险特征的量化值;
第二生成模块,根据所述量化值以及为所述风险特征预设的风险权重生成与所述风险特征对应的子特征值;
第三生成模块,根据所述子特征值以及当前存在的其他风险特征的子特征值生成所述综合特征值。
优选地,所述样本数据包含所述帐户样本中好样本的数量以及坏样本的数量,所述确定模块通过以下公式确定所述风险特征的量化值:
其中,nbad和ngood为对所述取值进行分bin操作后每个bin内所述坏样本和所述好样本的数量,Nbad和Ngood为所述坏样本和所述好样本的数量。
优选地,还包括:
第二获取模块,根据直接数据源以及间接数据源获取当前存在的所有账号的原始变量的取值,所述直接数据源对应于在系统中具有操作行为记录的第一账号,所述间接数据源对应于与所述第一账号具有关联操作的第二账号;
第四生成模块,根据当前存在的所有账号,以及所述所有账号的原始变量的取值,生成所述数据库;
筛选模块,根据历史帐户风险处理数据从所述数据库中筛选所述账户样本。
优选地,所述第三生成模块具体用于:
判断所述风险特征是否存在上一层的分类特征;
若存在所述分类特征,所述第三生成模块根据所述分类特征包含的风险特征的子特征值以及为所述分类特征预设的权重生成所述分类特征的分类特征值,并根据所述分类特征值以及当前存在的其他分类特征的分类特征值生成所述综合特征值;
若不存在所述分类特征,所述第三生成模块将所述子特征值与当前存在的其他风险特征的子特征值的综合作为所述综合特征值。
通过本申请提出的上述实施例,通过采用上述技术方案,在根据待评估账号当前各个风险特征的量化值生成待评估账号的综合特征值后,再判断综合特征值是否大于预设的阈值,若是则确定待评估账号存在风险,若否则确定待评估账号无风险,由于量化值是根据风险特征对应的原始变量的取值以及账户样本中各原始变量的样本数据生成,因此本申请能够从数据的角度对用户账户进行有效的风险评估,提高网络的安全性。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到本申请可以通过硬件实现,也可以借助软件加必要的通用硬件平台的方式来实现。基于这样的理解,本申请的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施场景所述的方法。
本领域技术人员可以理解附图只是一个优选实施场景的示意图,附图中的模块或流程并不一定是实施本申请所必须的。
本领域技术人员可以理解实施场景中的装置中的模块可以按照实施场景描述进行分布于实施场景的装置中,也可以进行相应变化位于不同于本实施场景的一个或多个装置中。上述实施场景的模块可以合并为一个模块,也可 以进一步拆分成多个子模块。
上述本申请序号仅仅为了描述,不代表实施场景的优劣。
以上公开的仅为本申请的几个具体实施场景,但是,本申请并非局限于此,任何本领域的技术人员能思之的变化都应落入本申请的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!