一种基于空间变换的自然场景下文本识别方法与流程
技术特征:
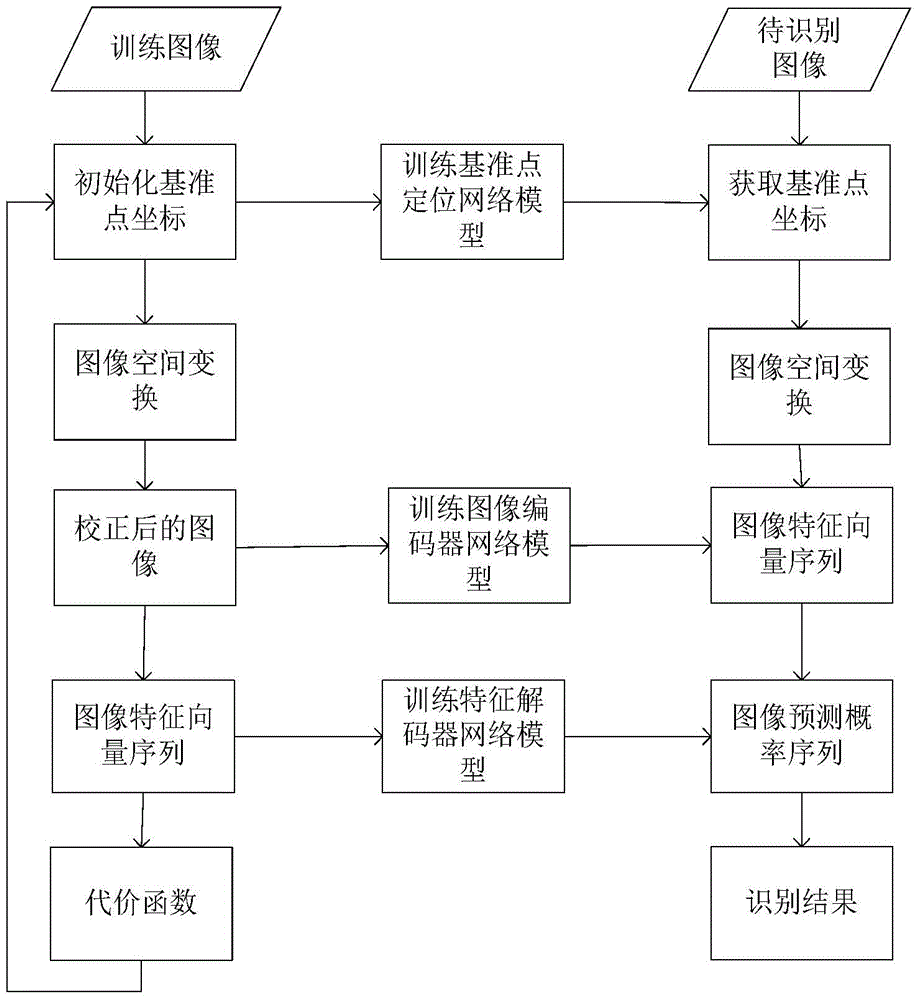
1.一种基于空间变换的自然场景下文本识别方法,其特征在于,所述方法包括下述步骤:(1)训练得到文本识别的参数,所述参数包括基准点定位网络模型、图像预处理网络模型、图像编码器网络模型以及特征解码器网络模型,包括如下子步骤:(1.1)标记训练图像集中所有文本图像的文本内容,得到训练数据集;(1.2)定义用于对待识别图像进行识别的级联网络,所述级联网络由基准点定位网络、图像预处理网络、图像编码器网络以及特征解码器网络构成,根据上述训练数据集,利用反向传导方法训练该级联网络,得到基准点定位网络模型、图像编码器网络模型以及特征解码器网络模型;(2)利用基准点定位网络对待识别图像做空间变换,包括如下子步骤:(2.1)利用基准点定位网络模型计算待识别图像的基准点位置;(2.2)根据所述待识别图像的基准点位置,利用薄板样条函数转换矩阵获取原待识别图像和变换后待识别图像的坐标对应关系;(2.3)根据上述原待识别图像和变换后待识别图像的坐标对应关系获取变换后的待识别图像;(3)对变换后的待识别图像进行识别:(3.1)利用图像编码器网络模型获取变换后的待识别图像的特征向量;(3.2)根据上述待识别图像的特征向量,利用特征解码器网络模型,获取待识别图像的预测概率序列;(3.3)利用上述得到的预测概率序列获取待识别图像最终的识别结果;所述步骤(1.2)具体为:(1.2.1)在训练图像Itr上取两条平行的线段,线段的端点都在训练图像的左右边界上,在这两条线段上分别等间距的取K/2个点作为基准点,其中K为设置的基准点个数,得到K个初始化的基准点,将这些基准点的坐标保存在基准点坐标矩阵Ctr中,记为其中坐标系的原点为图像的中点,ctrk表示第k个基准点,且ctrk=[xctrk,yctrk]T,xctrk和yctrk分别表示该基准点在训练图像Itri上归一化后的横坐标和纵坐标,xctrk∈[-1,1],yctrk∈[-1,1],上标T表示矩阵转置,Itri表示训练图像集中的第i张图像;(1.2.2)以卷积神经网络作为图像基准点定位网络,该卷积神经网络包含四个卷积层、四个最大池化层、两个全连接层以及一个双曲正切输出层;根据基准点坐标初始化所述基准点定位网络的的权重参数和偏置量,其中权重参数均为0,基准点对应的偏置量为1,其他的偏置量均为0;(1.2.3)对训练图像Itr,记图像Itr′为Itr经过变换后的图像,且变换后图像的宽度和高度分别为Wf和Hf,定义变换后的图像的基准点坐标矩阵为Ctr′=[ctr1′,...,ctr′K],其中K为基准点的个数,变换后的图像中的基准点与原训练图像中的基准点是一一对应的,且变换后的图像的基准点等间距的分布在图像Itr′的上下两条边上,其中第ktr个基准点ctr′ktr=[xctr′ktr,yctr′ktr]T,ctr′k对应原始训练图像Itr中的第ktr个基准点ctrktr,xctr′ktr和yctr′ktr分别表示该基准点在图像Itr′上归一化后的横纵坐标,xctr′ktr∈[-1,1],yctr′ktr∈[-1,1];(1.2.4)计算薄板样条函数转换矩阵Tps,记为:其中Os为1×K的矩阵,且Os中所有元素的值均为1,Ctr′为变换后的图像的基准点坐标矩阵,Zs为3×3的矩阵,且Zs中所有元素的值均为0,R为K×K的矩阵,且其第row行、第col列的元素值rrow,col为训练图像Itr的第row个基准点Ctrrow和变换后的图像Itr′的第col个基准点Ctr′col之间的欧式距离,上标T表示矩阵转置,K为基准点的个数,则利用训练图像的基准点坐标矩阵Ctr和薄板样条函数转换矩阵Tps计算转换参数矩阵A=[a1,a2,a3]T,B=[b1,b2,b3]T,F=[f1,...,fK]T,G=[g1,...,gK]T,其中矩阵A、B、F、G中的元素为转换参数,转换参数矩阵计算方程为:CtrT=TpsPa解该方程即可得到转换参数矩阵Pa,对变换后的图像Itr′上的一个点ptr′=[xprt′,yprt′]T,计算其对应于原始训练图像的点其中xptr′和yptr′分别表示点ptr′的在Itr′的横纵坐标,xptr和yptr分别表示点ptr在Itr的横纵坐标,计算公式为:ptr=PaTptr″,ptr″=[1,xptr′,yptr′,rtr1′,...,rtr′K]T,其中dtrktr表示点ptr′与Itr′的第ktr个基准点ctr′ktr之间的欧式距离,对图像Itr′中的每个点都执行上述运算,得到Itr′上每个点与图像Itr中点的对应关系;(1.2.5)对图像Itr′中的每个点ptr′,通过步骤(1.2.4)计算出其在原始图像Itr中对应的点ptr,利用双线性插值的方法通过点ptr周围的像素点的值计算出点ptr′的像素值,得到原始训练图像Itr经过变换后的图像Itr′;(1.2.6)以步骤(1.2.5)中得到的经过变换的图像作为输入,经过由卷积层构成的图像预处理网络,经过图像预处理可以得到D个Wf×Hf的特征图,其中D为常数,Wf和Hf分别表示预设的变换后图像的宽度和高度;对特征图的每一列,将其每个像素在D个特征图上对应的值拼接起来,组成一个D×Hf的特征向量,一共得到Wf个D×Hf的特征向量;然后以双向长短程记忆网络作为图像编码器网络,这些特征向量通过图像编码器网络进行计算得到训练图像的特征序列PItr={Xtr1,...,XtrWf},其中Xtrwtr表示图像Itr′第wtr列的特征向量;(1.2.7)以门限递归单元网络构建特征解码器网络,特征解码由Td个过程构成,其中Td表示特征解码器网络次数,特征解码的第td步具体为:首先计算权重向量αtd,计算方法如下:etd,wtr=vaTtanh(Wastd-1+UaXtrwtr)其中,αtd,wtr表示权重向量αtd的第wtr维的值,Wf表示预设的变换后图像的宽度,va、Wa、Ua为训练得到的参数矩阵,std-1表示解码过程第td-1步的输出,Xtrwtr表示步骤(1.2.6)中得到的图像Itr′第wtr列的特征向量,αtd是一个Wf维的向量;然后计算步骤(1.2.6)中得到的图像特征序列的上下文关系特征向量,记为:其中αtd,wtr表示权重向量αtd的第wtr维的值,Xtrwtr表示步骤(1.2.6)中得到的图像表示序列PItr={Xtr1,...,XtrWf}中的第wtr个向量;然后以得到的上下文关系特征向量otd、特征解码过程第td-1步的输出std-1以及预测的字符l′td-1为输入,经过该特征解码过程,得到输出std,然后将std输入到软最大分类器进行分类,得到预测的概率分布ytd;(1.2.8)将步骤(1.2.2)至(1.2.7)中所述的基准点定位网络、图像预处理网络、图像编码器网络以及特征解码器网络级联在一起,即为文本识别的网络,记为级联网络,利用反向传导的方法对该级联网络进行训练,得到步骤(1.2.2)中的基准点定位网络模型θloc、步骤(1.2.6)中的图像预处理网络模型θconv和图像编码器网络模型θblstm以及步骤(1.2.7)中的特征解码器网络模型θrnn和软最大分类器的模型W,组合在一起即为级联网络的模型,记为θ,该级联网络代价函数为:其中χ为训练数据集,Itri和Ltri分别表示第i个训练图像及其标注的文本内容,Ttri表示文本内容Ltri中字符的个数,ltri,t表示Ltri中的第t个字符,p(ltri,t|Itri,θ)由级联网络最后输出。2.根据权利要求1所述的基于空间变换的自然场景下文本识别方法,其特征在于,所述步骤(2.1)具体为:对待识别图像集中的每一张图像Itst,利用步骤(1.2.2)中训练好的基准点定位网络模型θloc,将图像输入基准点定位网络得到基准点的坐标矩阵其中ctstktst=[xtstktst,ytstktst]T表示图像Itst的第ktst个基准点,K为基准点个数,xtstktst和ytstktst分别表示第ktst个基准点的横纵坐标,且xtstktst∈(-1,1),ytstktst∈(-1,1),上标T表示矩阵转置。3.根据权利要求1所述的基于空间变换的自然场景下文本识别方法,其特征在于,所述步骤(2.2)具体为:对步骤(2.1)中得到的待识别图像的基准点坐标矩阵Ctst,利用步骤(1.2.3)和步骤(1.2.4)的方法计算原待识别图像Itst和变换后待识别图像Itst′之间坐标的对应关系,其中图像Itst′的宽度和高度分别为既定的值Wf和Hf。4.根据权利要求1所述的基于空间变换的自然场景下文本识别方法,其特征在于,所述步骤(2.3)具体为:根据步骤(2.2)中得到的原待识别图像Itst和变换后待识别图像Itst′之间坐标的对应关系,利用步骤(1.2.5)中所述的方法计算Itst′中各个点的像素值,得到变换后的待识别图像Itst′。5.根据权利要求1所述的基于空间变换的自然场景下文本识别方法,其特征在于,所述步骤(3.1)具体为:对步骤(2.3)中获取的变换后的待识别图像Itst′,利用步骤(1.2.6)中所述的方法以及训练得到的图像预处理网络模型θconv和图像编码器网络模型θblstm,得到图像Itst′的编码,即为图像Itst′的特征向量,记为PItst={Xtst1,...,XtstWf}。6.根据权利要求1所述的基于空间变换的自然场景下文本识别方法,其特征在于,所述步骤(3.2)具体为:具体地,对步骤(3.1)中获取的图像Itst′的特征向量序列PItst={Xtst1,...,XtstWf},利用步骤(1.2.7)中所述的方法以及训练好的特征解码器网络模型θrnn和软最大分类器的模型W,获取图像的预测概率分布序列,记为Y={y1,...,yTd},其中Td为步骤(1.2.7)中所述的特征解码的步数。7.根据权利要求1至6中任一所述的基于空间变换的自然场景下文本识别方法,其特征在于,所述步骤(3.3)具体为:具体地,对于没有词典情况,首先由步骤(1.2.7)所述的特征解码器网络的初始状态预测出第一步的概率分布,取最大概率的字符作为第一个字符,并把第一个字符以及第一步特征解码器网络的状态作为第二步的输入,并计算第二个字符的概率分布,同样的取概率最大的字符作为输出,并与第二步的状态一道作为下一步的输入,依次类推直到输出的概率分布中终止符的概率最大为止或者步长到了预设的最大值,则预测结束,此时输出的字符串即为预测的字符串;对于有词典的情况,对于词典中的每个单词,首先由步骤(1.2.7)所述的特征解码器网络的初始状态得到第一步的概率分布,并得到单词中第一个字符的概率,然后把单词中第一个字符以及第一步的状态作为第二步的输入,并得到第二步的字符概率分布,并得到单词中第二个字符的概率,依次进行下去,把整个单词中各个字符的概率相乘就可以得到这个单词对应的概率,算出字典中所有单词的概率,取概率最大的单词作为最终的输出。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1