基于预算支持向量集的LS‑SVMs在线学习方法与流程
基于预算支持向量集的LS-SVMs在线学习方法技术领域本发明属于数据挖掘与机器学习领域,涉及数据挖掘和数据处理的方法,具体地说,涉及一种基于预算支持向量集合的LS-SVMs在线学习方法。
背景技术:
LS-SVMs是在结构风险最小化原则基础上建立的典型核学习模型。作为具有良好光滑化结构的凸优化问题,LS-SVMs模型的KKT条件可以转化为(2,2)块为1阶的特殊鞍点系统。当前求解LS-SVMs模型的主流方法主要包括:(一)利用预处理子将上述鞍点系统等价转化为两个正定系统,并使用经典的共轭梯度算法求解正定系统;(二)将鞍点系统表示为两个线性方程组,并采用零空间法方法进行求解;(三)采用最小残差法直接求解鞍点系统。这些方法都属于批处理技术,算法的计算复杂度为O(n3),其中n为样本个数。然而,许多实际应用问题面向的数据具有数据流的特性,如动态工业生产过程、垃圾邮件处理系统等,采集的样本都是以数据流的形式随时间推移不断出现的。批处理算法由于计算复杂度太高,不适合处理上述数据流问题。为此,国内外的学者们开始研究LS-SVMs的在线学习算法,以降低计算复杂度,减少模型运行时间,标志性成果是H.M.Chi和O.K.Ersoy提出的LS-SVMs递归更新算法。该方法利用Sherman-Morrison-Woodbury公式迭代更新LS-SVMs模型的鞍点系统,将计算复杂度从O(n3)降到O(n2)。由于采集样本量将随时间线性增长,LS-SVMs模型的规模、存储空间、运行时间都将随之不断增加。为解决上述问题,亟需建立一种固定预算的在线LS-SVMs学习方法,在保证模型精度的同时有效控制模型的存储空间和训练时间,以适应数据流环境。
技术实现要素:
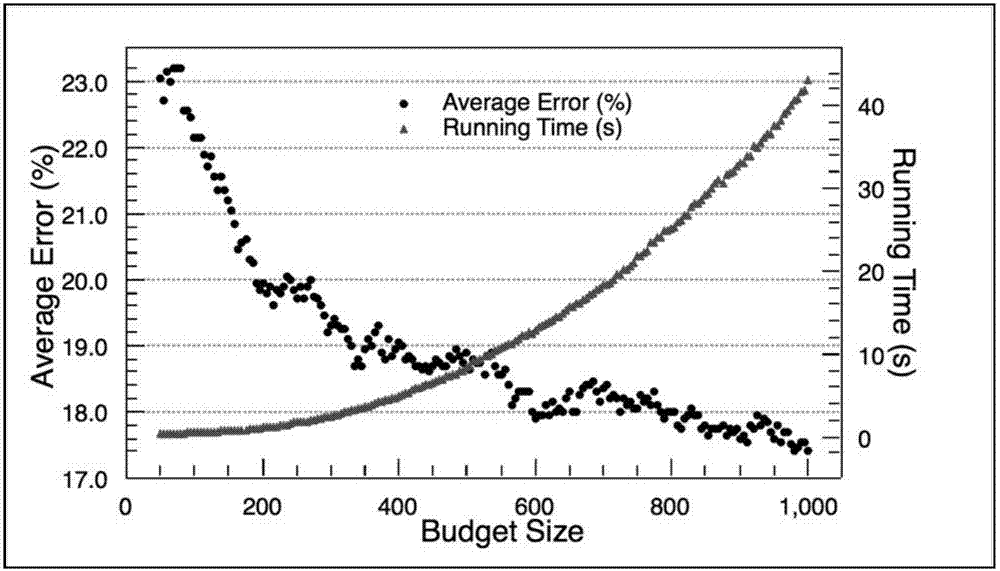
本发明的目的在于针对现有LS-SVMs在线学习方法无法有效控制模型规模等上述不足,提供了一种基于预算支持向量集合的LS-SVMs在线学习方法,该方法能够降低模型存储空间,减少运行时间,满足应用问题的实时性需求。根据本发明一实施例,提供了一种基于预算支持向量集合的LS-SVMs在线学习方法,含有以下步骤:(一)利用训练样本确定预算范围。(二)按照预算随机选取初始支持向量集合,建立LS-SVMs模型,通过KKT条件将LS-SVMs模型转化为鞍点系统,将鞍点系统等价转化为两个正定系统并采用共轭梯度法进行求解,得到预测器。(三)以mini-batch的形式采集数据流,采用预测器对数据流中的样本进行预测。(四)将错误预测样本加入支持向量集合,并按照最大相似性或时间准则剔除相应数量支持向量,维持预算稳定。(五)利用低秩矩阵校正方法以及Sherman-Morrison-Woodbury公式更新LS-SVMs模型,得到在线预测器,通过在线预测器对数据流进行在线预测。在根据本发明实施例的学习方法中,步骤(一)中,确定预算范围的具体步骤为:(1)确定训练样本集合和测试样本集合;为降低各个输入特征在数量级上的差异对模型性能所产生的影响,采用如下标准化处理方式对样本数据进行预处理,其中表示原始采集数据,m(xj)表示第j个特征的平均值,σ(xj)表示第j个采集变量的标准差。(2)根据实际问题特征确定待测预算集合。(3)依次选取预算n,按照预算n在训练样本集合中随机选取相应数目的样本,建立LS-SVMs模型,并应用测试样本集合测试该预算n的精度。(4)执行步骤(3)10次,并计算各个预算的平均测试精度及平均测试时间。(5)利用平均测试精度和平均测试时间绘制双纵轴曲线,综合考虑时间成本和LS-SVMs模型精度确定合理预算。在根据本发明实施例的学习方法中,步骤(二)中,得到预测器的具体步骤为:按照确定的预算n随机选取训练样本构造支持向量集合,建立LS-SVMs模型,LS-SVMs模型表示为:其中,w为分类超平面的法向量,b为分类超平面的截距项,ei为误差项,v为模型正则化参数,表示特征映射,通过指定核函数的方式隐式确定。通过KKT条件将LS-SVMs模型转化为鞍点系统,表示为:其中,k(·,·)为核函数,由用户指定。将鞍点系统等价转化为两个正定系统,表示为:采用共轭梯度法求解所述两个正定系统,得到决策系数α和偏置系数b为:进而获得预测器为:在根据本发明实施例的学习方法中,作为优选,步骤(四)中,当采集到样本真实标签后,对比预测器的预测输出,忽略正确预测样本,记录错误预测样本并将错误预测样本加入支持向量集合,按照最大相似性准则从支持向量集合中剔除相应数量支持向量以维持向量预算稳定。在根据本发明实施例的学习方法中,步骤(五)中,利用低秩矩阵校正方法以及Sherman-Morrison-Woodbury公式更新LS-SVMs模型,得到在线预测器的具体步骤为:(1)采用数据流中的样本取代原支持向量集合的样本(2)构造校正矩阵U∈Rn+1,m,具体表示为:以及构造矩阵V∈Rn+1,m,具体表示为:(3)将校正矩阵U∈Rn+1,m和校正矩阵V∈Rn+1,m与鞍点矩阵相加,即:通过上述公式(7)进行鞍点矩阵的更新。(4)利用Sherman-Morrison-Woodbury公式得到更新后鞍点矩阵的逆矩阵为:Q-1-Q-1V(I+UTQ-1V)-1UTQ-1(8)式中,Q-1=A-1-A-1U(I+VA-1U)-1VTA-1,(5)根据支持向量集合更新鞍点系统的右端向量并计算出新的可得决策系数和偏置系数,获得更新后的预测器,更新后的预测器即为在线预测器。本发明提出的基于预算支持向量集合的LS-SVMs在线学习方法,在训练集上确定预算范围,选择初始支持向量集合,建立LS-SVMs模型,采用共轭梯度法求解LS-SVMs模型,并利用低秩矩阵校正方法以及Sherman-Morrison-Woodbury公式更新LS-SVMs模型得到在线预测器,实现了对数据流的在线预测,该方法采用固定预算策略,能有效控制在线学习模型的规模、节约存储空间、计算复杂度低、易于实现。通过根据本发明实施例的基于预算支持向量集合的LS-SVMs在线学习方法,能够灵活处理具有数据流特征的在线应用问题,数据可以以数据块的形式收集,与传统批处理方式以及当前的在线学习方法相比,大幅度降低了计算复杂难度和模型运行时间,可以同时处理回归问题和分类问题,能够高效处理LS-SVMs模型选择问题,特别是处理留一法交叉验证问题时计算复杂难度仅为O(n3),而传统方法的计算复杂度为O(n4)。附图说明附图1为本发明实施例基于预算支持向量集合的LS-SVMs在线学习方法示意图。附图2a为本发明实施例中预算BudgetSize对模型精度和运行时间的影响分析图。附图2b为本发明实施例中数据块规模ChunkSize对模型精度和运行时间的影响分析图。附图3为本发明实施例中双螺旋分类图。附图4为本发明实施例中利用滑动窗口方法建立在线预报模型。附图5为本发明学习方法和已有学习方法在基准数据集german上平均在线测试精度比较示意图。附图6为本发明学习方法和已有学习方法在基准数据集spambase上的平均在线测试精度比较示意图。附图7为本发明学习方法和已有学习方法在基准数据集adult9上的平均在线测试精度比较示意图。附图8为本发明学习方法和已有学习方法在基准数据集ijcnn1上的平均在线测试精度比较示意图。具体实施方式以下结合附图对本发明实施例作进一步说明。实施例1:以双螺旋分类问题为例进行说明。如图1所示为根据本发明实施例提供的一种基于预算支持向量集合的LS-SVMs在线学习方法的示意图,该在线学习方法含有以下步骤:步骤一:利用训练样本确定预算范围。其具体步骤为:(1)选择待处理数据集合,本实施例中,以基准数据集Adult9为例进行说明。取样本块规模为1,从Adult9中随机选取2000个样本点构造训练集并选取1000个样本点构造测试集,应用标准化公式对样本点进行预处理。选择Gaussian径向基函数作为核函数,核宽参数σ取默认值,即样本点的维数。(2)确定预算集合为{5,10,15,…,995,1000}。(3)从上述步骤(2)的集合中依次选取预算,按照预算在训练样本集中随机选取相应数目的样本建立LS-SVMs模型,并应用测试集测试该预算的精度。(4)依次执行上述步骤(3)10次,并计算各个预算的平均测试精度以及运行时间。(5)利用平均测试时间和平均测试精度绘制双纵轴曲线,如图2a所示,综合考虑时间成本与模型精度以确定预算范围为550-650之间。本实施例中,为了不失一般性,选择预算为600。确定样本块规模集合为{1,2,3,…,19,20},从该集合中一次选取样本块规模,预算设定为600,在训练样本集中随机选取600个样本建立LS-SVMs模型,测试样本依次以样本块的形式输入LS-SVMs模型进行精度测试。依次执行上述步骤10次,并计算各样本块规模对应的平均测试精度以及运行时间。利用平均测试时间和平均测试精度绘制双纵轴曲线,如图2b所示,综合考虑时间成本与模型精度以确定样本块规模为3。步骤二:按照预算随机选取初始支持向量集合,建立LS-SVMs模型,通过KKT条件将LS-SVMs模型转化为鞍点系统,将鞍点系统等价转化为两个正定系统并采用共轭梯度法进行求解,得到预测器。其具体步骤为:按照预算随机选取初始支持向量集合,建立LS-SVMs模型,LS-SVMs模型表示为:其中,w为分类超平面的法向量,b为分类超平面的截距项,ei为误差项,v为模型正则化参数,表示特征映射,通过指定核函数的方式隐式确定。通过KKt条件将LS-SVMs模型转化为鞍点系统,表示为:其中,k(·,·)为核函数,由用户指定。将鞍点系统等价转化为两个正定系统,表示为:采用共轭梯度法求解所述两个正定系统,得到决策系数α和偏置系数b为:进而获得预测器为:步骤三:如图3所示,以mini-batch的形式采集数据流,采用预测器对数据流中的样本进行预测。步骤四:将错误预测样本加入支持向量集合,并按照最大相似性或时间准则剔除相应数量支持向量,维持预算稳定。当采集到样本真实标签后,对比预测器的预测输出,忽略正确预测样本,记录错误预测样本并将错误预测样本加入支持向量集合,如图3中的(b)图所示两个菱形标识样本点是错分样本,将其加入支持向量集合,并按照最大相似性准则从支持向量集合中剔除相应数量支持向量以维持向量预算稳定。步骤五:利用低秩矩阵校正方法以及Sherman-Morrison-Woodbury公式更新LS-SVMs模型,得到在线预测器,通过在线预测器对数据流进行在线预测。如图3中(d)图所示,经过4次更新后LS-SVMs模型可以正确实现分类。实施例二:如图4,以应用滑动窗口技术为例。与实施例一不同的是,在本实施例中,步骤三中,数据流以one-by-one的形式采集数据流,采用预测器对数据流中的样本进行预测;步骤四中,当采集到样本真实标签后对比预测器的预测输出,忽略正确预测样本,记录错误预测样本,将错误预测样本加入支持向量集合,并按照时间准则将支持向量集合中采样时间最早的一个支持向量剔除以维持预算稳定。图5至8为采用本发明在线学习方法与现有随机预算感知机方法和在线梯度下降方法对基准数据集german、基准数据集spambase、基准数据集adult9和基准数据集ijcnn1四种数据集进行处理后的平均在线测试精度比较示意图,由图5至8可以看出,本发明在线学习方法在上述4个基准数据集合上的测试精度一致优于其它两种方法。上述实施例用来解释本发明,而不是对本发明进行限制,在本发明的精神和权力要求的保护范围内,对本发明做出的任何修改和改变,都落入本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1