用于分级存储系统的管理装置和管理方法与流程
本发明涉及一种用于分级存储系统的管理装置和管理方法。
背景技术:
已经提出一种用于在用户侧上安装的文件服务器与在数据中心侧上安装的文件服务器之间移动文件的分级存储系统(专利文献1)。在这一分级存储系统中,在用户侧文件服务器中存储用户频繁使用的文件,并且在数据中心侧文件服务器中存储用户不频繁使用的文件。引用列表专利文献PTL1:日本专利申请公开号2011-76294
技术实现要素:
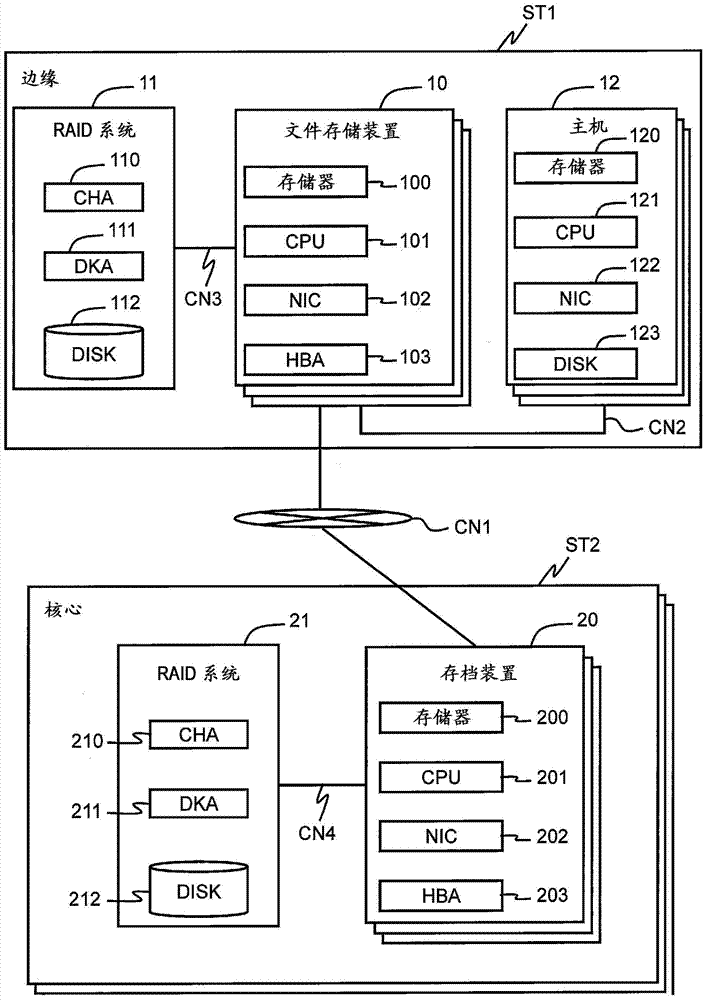
技术问题在现有技术的情况下,由于用户不频繁使用的文件被移向数据中心侧文件服务器,所以在用户试着访问这一文件时,访问需要长时间。这是因为用户侧文件服务器必须通过诸如WAN(广域网)的通信网络从数据中心侧服务器获取访问目标文件。因此,与文件存储在用户侧文件服务器中相比较,在文件存储于数据中心侧文件服务器上时,响应性能大幅降低并且用户可用性也下降。鉴于前文,本发明的一个目的是提供一种分级存储系统的管理装置和管理方法,该管理装置和管理方法使得有可能有效地使用第一文件管理装置的从用户终端可访问的存储区域以存储尽可能多的文件。本发明的另一目的是提供一种用于分级存储系统的管理装置和管理方法,该管理装置和管理方法使得有可能有效地使用第一文件管理装置的存储区域和第二文件管理装置的存储区域。问题的解决方案与本发明的一个方面有关的一种分级存储系统管理装置是一种用于管理分级存储系统的管理装置,该管理装置通过第一文件管理装置和第二文件管理装置分级地管理文件,该分级存储系统管理装置包括:重复处理部分,该重复处理部分在第二文件管理装置中创建在第一文件管理装置中的指定文件的重复件;重复去除处理部分,该重复去除处理部分通过根据预先配置的第一指定条件选择在第一文件管理装置中的另一指定文件作为重复数据去除目标并且将选择的另一指定文件转换成用于引用在指定引用文件中的数据的引用源文件来去除重复数据;以及存根化处理部分,该存根化处理部分根据预先配置的第二指定条件选择存根化候选文件,该存根化候选文件变成用于删除在第一文件管理装置中的指定文件的数据的存根化过程的目标,并且此外仅留下在指定文件的在第二文件管理装置中创建的重复件中的数据,并且也根据预先配置的第三指定条件对存根化候选文件存根化。与本发明的一个方面有关的一种分级存储系统管理装置也可以包括文件访问接收部分,该文件访问接收部分用于在第一文件管理装置以内的复制源文件重复件的创建已经被请求的情况下创建复制源文件的重复件作为引用源文件。可以包括第一文件管理装置作为能够从用户终端直接访问的文件管理装置,并且可以包括第二文件管理装置作为不能从用户终端直接访问的文件管理装置。配置也可以使得指定引用文件存储表示以指定引用文件作为引用的引用源文件的数目的引用数目,并且每当删除引用源文件时或者每当关于引用源文件执行存根化过程时,递减引用数目,并且在引用数目变成0时,文件访问接收部分能够删除指定引用文件。也可以理解本发明为一种用于控制分级存储系统管理装置的计算机程序。附图说明[图1]图1是示出整个实施例的概况的图示。[图2]图2是分级存储系统的硬件框图。[图3]图3是分级存储系统的软件框图。[图4]图4是示出在文件系统与索引节点管理表之间的关系的图示。[图5]图5是具体示出索引节点管理表的图示。[图6]图6是示出索引节点管理表的扩展部分的图示。[图7]图7示出重复过程的概况的图示。[图8]图8示出单示例过程的图示。[图9]图9示出克隆源文件的存储位置的图示。[图10]图10示出如何将正常文件转换成克隆文件的图示。[图11]图11是示出克隆文件如何仅存储相对于克隆源文件的差异数据的图示。[图12]图12是示出其中已经将单实例应用于所谓虚拟桌面环境的情况的示例的图示。[图13]图13是示出其中将单实例应用于文档创建的情况的示例的图示。[图14]图14是示出其中将单实例应用于数据库重复的情况的示例的图示。[图15]图15是示出存根化过程的概况的图示。[图16]图16是示出克隆源文件的图示,该克隆源文件管理从其引用它的多个克隆文件。[图17]图17是示出读过程的概况的图示。[图18]图18是示出写过程的概况的图示。[图19]图19是示出重复过程的概况的图示。[图20]图20是分别示出接收程序执行的读过程和写过程的流程图。[图21]图21是图20的流程图的继续。[图22]图22是接收程序执行的复制过程的流程图。[图23]图23是接收程序执行的删除过程的流程图。[图24]图24是示出数据移动器程序的总体操作的流程图。[图25]图25是示出数据移动器程序执行的存根化过程的流程图。[图26]图26是示出数据移动器程序执行的复制操作的流程图。[图27]图27是示出数据移动器程序执行的文件同步过程的流程图。[图28]图28是示出用于选择重复文件候选的过程的流程图。[图29]图29是示出用于删除重复件的过程的流程图。[图30]图30是示出用于去除重复文件的流程图。[图31]图31是示出克隆源文件和克隆文件变成与第二示例有关的重复过程(和存根化过程)的目标的图示。[图32]图32是示出可以基于克隆文件的上次访问日期/时间估计的克隆源文件的上次访问日期/时间的图示。[图33]图33是示出用于基于克隆文件的上次访问日期/时间估计克隆源文件的上次访问日期/时间的过程的流程图。[图34]图34是用于示出由接收程序执行的读过程和写过程的流程图。[图35]图35是图34的流程图的继续。[图36]图36是图34的流程图的另一继续。[图37]图37是示出由接收程序执行的用于读传送数据的过程的流程图。[图38]图38是由接收程序执行的复制过程的流程图。[图39]图39示出与第三示例有关的由数据移动器程序执行的存根化过程的流程图。具体实施方式以下将通过参照附图说明本发明的一个实施例。然而应当指出该实施例仅为用于实现本发明的示例而未限制本发明的技术范围。可以用多种方式组合在该实施例中公开的多个有特点的特征。在本说明书中,使用表达“aaa表”来说明在该实施例中使用的信息,但是本发明不限于此,并且例如可以使用其它表达、比如“aaa列表”、“aaa数据库”和“aaa队列”。在该实施例中使用的信息可以称为“aaa”信息以表明这一信息未依赖于数据结构。在解释在该实施例中使用的信息的内容时,可以使用比如“标识信息”、“标识符”、“名称”和“ID”的表达,但是这些表达可互换。此外,在说明该实施例的处理操作时,可以解释“计算机程序”作为操作的执行者(主体)。根据微处理器执行计算机程序。因此,处理器也可以用作操作的执行者。图1是作为整体示出该实施例的概况的图示。在图1中示出两个模式、即在附图的左上侧中示出的一个实施例(1)和在左下侧中示出的另一实施例(2)。该实施例的分级存储系统使用在边缘侧上设置的第一文件管理装置1和在核心侧上设置的第二文件管理装置2来分级地管理文件。边缘侧表示用户场站侧。核心侧是从用户侧分离的一侧并且例如等效于数据中心。用户可以经由作为“用户终端”服务的主机计算机(缩写为主机)访问边缘侧文件管理装置1并且可以从/向希望的文件读/写或者创建新文件。主机不能直接访问在核心侧文件管理装置2中的文件。用户不频繁使用的文件变成如以下将进一步说明的单示例过程的目标。此外,自从上次访问日期/时间起已经流逝指定时间段的文件变成以下将进一步说明的存根化过程的目标。在执行存根化过程之前执行以下将进一步说明的重复过程。管理装置3是用于管理分级存储系统的计算机并且例如可以被设置为从相应文件共享装置1和2分离的单独计算机或者可以设置于边缘侧文件管理装置1以内。管理装置3例如包括重复处理部分3A、作为“重复去除处理部分”的单示例处理部分3B、存根化处理部分3C和文件访问接收部分3D。“处理部分”在附图中缩写为“部分”重复处理部分3A是用于在第二文件管理装置2中创建在第一文件管理装置1中的指定文件的重复件的功能。单实例处理部分3B检测和共同地管理重复文件作为单个文件。以下将具体说明单示例过程,但是将先给出简单说明。单实例处理部分3B选择利用频率已经减少的文件作为候选文件,并且比较候选文件与现有克隆源文件。克隆源文件等效于“引用文件”并且是构成数据引用目的地的文件。在候选文件和克隆源文件匹配的情况下,单实例处理部分3B删除候选文件的数据并且配置克隆源文件作为候选文件的引用目的地。根据这一点,将候选文件转换成克隆文件。克隆文件是用于按照需要引用克隆源文件的数据的文件,并且等效于“引用源文件”。这使得有可能防止相同数据分别存储于多个文件中并且使存储区域能够被高效地使用。在该实施例中,有可能以块数据为单位去除重复件。存根化处理部分3C是用于执行存根化过程的功能。以下将具体说明存根化过程,但是将先给出简要说明。首先假设相同文件根据重复处理部分3A的动作分别存储于边缘文件管理装置1中和核心侧文件管理装置2中。在边缘侧文件管理装置1的空闲容量削减时,存根化处理部分3C按从在边缘侧文件管理装置1中存储的一组文件的不频繁使用的文件按顺序选择文件作为存根化目标。删除作为存根化目标选择的文件的数据。包括与存根化的文件相同的数据的文件存在于核心侧文件管理装置2中。因此,在主机访问存根化的文件的情况下,从在核心侧文件管理装置2中存储的重复的文件读并且向边缘侧文件管理装置1传送数据。用于提取存根化的文件的数据的过程在该实施例中称为召回过程。文件访问接收部分3D从主机接收文件访问请求并且根据请求的性质执行指定过程。文件访问请求例如可以是读请求、写请求、复制请求或者删除请求。在主机请求文件复制时,文件访问接收部分3D创建请求的文件(通过对复制源文件复制而得到的文件)作为克隆文件。复制某个文件意味着在复制源文件与副本文件之间重复数据。因而如以下将进一步说明的该实施例使用单实例处理部分3B以将复制源文件转换成克隆文件并且复制这一克隆文件。在图1的上部分中示出的实施例(1)中,在边缘侧文件管理装置1中执行单实例过程,并且存储一个克隆源文件和引用这一克隆源文件的多个克隆文件。在边缘侧文件管理装置1中的克隆文件使用克隆源文件数据(即如下数据,该数据重复构成引用的克隆源文件)并且存储与克隆源文件的数据不同的数据(差异数据)的数据。也就是说,克隆文件仅存储与克隆源文件不同的差异数据。关注核心侧文件管理装置2。在核心侧文件管理装置2中存储在边缘侧文件管理装置1中存储的多个文件(重复的文件)的重复件。然而即使在边缘侧文件管理装置1中存储的文件是克隆文件时,仍然在核心侧文件管理装置2中创建包括与正常文件相同的完整数据的文件(具体而言包括数据的文件,该数据复制克隆源文件的数据而不是仅差异数据)并且创建该文件作为相关克隆文件的重复件。根据实施例(1),可以根据边缘侧文件管理装置1存储许多文件以使边缘侧文件管理装置1的存储区域能够被高效地使用。因此可以对来自主机的访问请求快速地做出响应从而增强用户可用性。然而由于创建克隆文件的重复件,所以在从边缘侧文件管理装置1向核心侧文件管理装置2传送克隆文件数据的情况下,必须向核心侧文件管理装置2传送克隆文件差异数据和克隆源文件引用数据二者。在图1中示出两个克隆文件Fa和Fb。关于一个克隆文件Fa从边缘侧管理装置1向核心侧文件管理装置2传送数据“5”、“2”、“3”和“4”。相似地,关于另一克隆文件Fb从边缘侧管理装置1向核心侧文件管理装置2传送数据“1”、“2”、“6”和“4”这四个数据块。因此,从边缘侧管理装置1向核心侧文件管理装置2执行传送重复数据(在以上示例中传送数据“2”和“4”)。出于这一原因,重复过程的传送大小为大,传送时间长,并且通信信道变成拥塞。此外,在未在核心侧管理装置2中应用重复去除过程(单示例过程)的情况下,不可能高效使用核心侧管理装置2的存储区域。这是因为在核心侧管理装置2中存储核心文件的重复件作为包括与正常文件相同的所有它的数据的文件。因而可设想也在核心侧管理装置2中创建克隆源文件的重复件并且去除克隆源文件和克隆文件的重复数据。也就是说,由于可以在配置使得从边缘侧文件管理装置1向核心侧管理装置2传送克隆源文件数据和克隆文件的仅差异数据的情况下消除数据传送,所以即使在未在核心侧管理装置2中应用重复去除过程(单示例过程)的情况下仍然可以高效地利用核心侧管理装置2的存储区域。然而在核心侧管理装置2中创建克隆源文件重复件时,克隆源文件也变成存根化过程的目标。由于克隆源文件是从一个或者多个克隆文件引用的引用文件,所以管理克隆源文件,从而不可能直接用户访问。一般而言,对于存根化过程按照从最旧文件开始的顺序以文件作为目标,并且这样,用户不能访问的克隆源文件更易于在用户可访问克隆文件之前变成存根化过程目标。在克隆源文件被存根化并且数据不再保留于边缘侧文件管理装置1中时,引用这一克隆源文件的所有克隆文件的响应性变差。这是因为边缘侧文件管理装置1必须通过WAN等从核心侧文件管理装置2获取待引用的数据。克隆文件的响应性在召回过程完成之后暂时提高。然而在克隆源文件被最终存根化时,克隆文件的响应性再次减少。因此,即使引用克隆源文件的克隆文件被频繁使用时,向这一克隆文件提供数据的克隆源文件被确定不频繁使用并且变成存根化目标。因而在图1的左下部中示出的实施例(2)中,适当评估克隆源文件的利用频率,并且执行克隆源文件存根化过程。在实施例(2)中,基于引用这一克隆源文件的相应克隆文件的索引值估计用于确定对克隆源文件存根化的适当性的索引值。例如在实施例(2)中,计算克隆源文件的上次访问日期/时间为引用这一克隆源文件的相应克隆文件的上次访问日期/时间的平均值。根据实施例(2),由于也可以在核心侧文件管理装置2中存储单实例化的文件,所以可以有效地利用核心侧文件管理装置2的存储区域。此外,由于可以从边缘侧文件管理装置1向核心侧文件管理装置2仅发送克隆源文件数据和相应克隆文件的存储的差异数据,所以可以减少传送数据的大小从而消除通信拥塞。此外,由于适当评估克隆源文件利用频率,所以有可能阻止克隆源文件在克隆文件之前的存根化。作为这一点的结果,可以维持克隆文件的响应性从而使得有可能防止用户可用性降低。示例1图2是示出分级存储系统的总体配置的硬件框图。图3是分级存储系统的软件框图。将先描述与图1的对应关系。作为“第一文件管理装置”的文件存储装置10对应于图1的边缘侧文件管理装置1,作为“第二文件管理装置”工作的存档装置20对应于图1的核心侧文件管理装置2,并且作为“用户终端”工作的主机12对应于图1中的主机。提供图1的管理装置3作为文件存储装置10的功能。更具体而言,根据在文件存储装置10中的软件组和在存档装置20中的软件组的协作实现管理装置3执行的功能。将说明边缘侧场站ST1的配置。边缘侧场站ST1设置于用户侧上并且例如设置于每个企业办公室或者分公司办公室中。边缘侧场站ST1例如配备有至少一个文件存储装置10、至少一个RAID(廉价盘冗余阵列)系统11和至少一个主机计算机(或者客户端终端)12。例如经由WAN或者其它这样的场站间通信网络CN1耦合边缘侧场站ST1和核心侧场站ST2。例如经由比如LAN(局域网)的现场通信网络CN2耦合文件存储装置10和主机计算机(下文为主机)12。例如经由比如FC-SAN(光纤信道-存储区域网络)或者IP-SAN(网际协议-SAN)的通信网络CN3耦合文件存储装置10和RAID系统11。可以配置这些通信网络CN1、CN2、CN3中的多个或者所有通信网络作为共享的通信网络。文件存储装置10例如包括存储器100、微处理器(在附图中为CPU:中央处理单元)101、NIC(网络接口卡)102和HBA主机总线适配器103。CPU101通过执行在存储器100中存储的指定程序P100至P106来实现以下将进一步说明的指定功能。存储器100可以包括主存储存储器、闪存设备或者硬盘设备。以下将进一步说明存储器100的存储内容。NIC102是用于文件存储装置10经由通信网络CN2与主机12通信以及用于文件存储装置10经由通信网络CN1与存档装置20通信的通信接口电路。HBA103是用于文件存储装置10与RAID系统11通信的通信接口电路。RAID系统11管理由文件存储装置10管理的一组文件的数据作为块数据。RAID系统11例如包括信道适配器(CHA)110、盘适配器(DKA)111和存储设备112。CHA110是用于控制与文件存储装置10的通信的通信控制电路。DKA111是用于控制与存储设备112的通信的通信控制电路。根据CHA110和DKA111的协作向存储设备112写入从文件存储装置10输入的数据以及向文件存储装置10传送从存储设备112读取的数据。存储设备112例如包括硬盘设备、闪存设备、FeRAM(铁电随机存取存储器)、MRAM(磁阻随机存取存储器)、相变存储器(双向统一存储器)或者RRAM(电阻RAM:注册商标)。将说明主机12的配置。主机12例如包括存储器120、微处理器121、NIC122和存储设备123。主机12可以被配置为服务器计算机或者可以被配置为个人计算机或者手持终端(以包括蜂窝电话)。以下将说明的应用程序P120存储于存储器120和/或存储设备123中。CPU121执行应用程序并且使用由文件存储装置10管理的文件。主机12通过NIC122与文件存储装置10通信。将说明核心侧场站ST2。核心侧场站ST2例如设置于数据中心等中。核心侧场站ST2包括存档装置20和RAID系统21。经由场站内通信网络CN4耦合存档装置20和RAID系统21。RAID系统21是与边缘侧RAID系统11相同的配置。核心侧CHA210、DKA211和存储设备212分别对应于边缘侧的CHA110、DKA111和存储设备112,并且这样将省略其说明。存档装置20是用于备份由文件存储装置10管理的一组文件的文件存储装置。存档装置20例如包括存储器200、微处理器201、NIC202和HBA203。由于存储器200、微处理器201、NIC202和HBA203与文件存储装置10的存储器100、微处理器101、NIC102和HBA103相同,所以将省略其说明。文件存储装置10和存档装置20的硬件配置趋同,但是它们的软件配置不同。参照图3,将先说明边缘侧场站ST1的软件配置。文件存储装置10例如包括文件共享程序P100、数据移动器程序P101、文件系统程序(在附图中缩写为FS)P102以及内核和驱动器(在附图中缩写为OS)P103。此外,文件存储装置10例如包括接收程序P104(参照图7)、选择程序P105(参照图8)和重复检测程序P106(参照图8)。以下将进一步说明每个程序的操作,但是简要地说明,文件共享程序P100例如是用于使用比如CIFS(公共因特网文件系统)或者NFS(网络文件系统)的通信协议来向主机12提供文件共享服务的软件。数据移动器程序P101是用于执行以下将进一步说明的重复过程、文件同步过程、存根化过程和召回过程的软件。文件系统是为了在卷114上实现称为文件的管理单位而构建的逻辑结构。文件系统程序P102是用于管理文件系统的软件。内核和驱动器P103是用于作为整体控制文件存储装置10的软件。内核和驱动器P103例如控制调度在文件存储装置10上运行的多个程序(进程)并且控制来自硬件部件的中断。接收程序P104是用于从主机12接收文件访问请求、执行指定过程并且返回其结果的软件。选择程序P105是用于选择用于应用单实例过程的单实例候选的软件。重复检测程序P106是用于为选择的单实例候选执行单实例过程的软件。RAID系统11包括用于存储OS等的逻辑卷113和用于存储文件数据的逻辑卷114。可以通过将多个存储设备112的物理存储区域一起汇集成单个存储区域并且从这一物理存储区域剪取指定大小的存储区域来创建逻辑卷113、114,这些逻辑卷是逻辑存储设备。主机12例如包括应用程序(下文缩写为应用)P120、文件系统程序P121以及内核和驱动器P122。应用P120例如包括字处理程序、客户管理程序或者数据库管理程序。将说明核心侧场站ST2的软件配置。存档装置20例如包括数据移动器程序P201、文件系统P202以及内核和驱动器P203。以下将按照需要进一步说明这些多款软件的作用。RAID系统21例如包括用于存储OS等的逻辑卷213和用于存储与RAID系统11相同的文件数据的逻辑卷214。将省略其说明。图4是以简化形式示出在文件系统与索引节点管理表T10之间的关系的图示。如在图4的顶部所示,文件系统例如包括超块、索引节点管理表T10和数据块。超块例如是用于共同地存储文件系统管理信息的区域,文件系统管理信息比如文件系统的大小和文件系统空闲容量。索引节点管理表T10是用于管理在每个文件中配置的索引节点的管理信息。一个索引节点各自是针对在文件系统中的每个目录或者文件而对应地管理的。在索引节点管理表T10中的相应条目中,仅包括目录信息的条目称为目录条目。可以通过使用目录条目以遵循文件路径来访问其中存储目标文件的索引节点。例如在遵循如图4中所示“/home/user-01/a.txt”时,可以通过按照该顺序遵循索引节点#2->索引节点#10->索引节点#15->索引节点#100访问目标文件的数据块。其中存储文件实体的索引节点(在图4的示例中为“a.txt”)例如包括比如文件所有者、访问权限、文件大小和数据存储位置的信息。在图4的底部,示出在索引节点与数据块之间的引用关系。在图4中向数据块指派的标号100、200、250表示块地址。在访问权限项目中显示的“u”是用于用户的缩写,“g”是用于组的缩写,并且“o”是用于除了用户之外的个人的缩写。另外,在访问权限项目中示出的“r”是用于读的缩写,“x”是用于执行的缩写,并且“w”是用于写的缩写。记录上次访问日期/时间为年(四位)、月、日、小时、分钟和秒的组合。图5示出其中在索引节点管理表中存储索引节点的状态。在图5中,给出索引节点编号“2”和“100”作为示例。图6是示出在这一示例中已经向索引节点管理表T10添加的部分的配置的图示。索引节点管理表T10例如包括索引节点编号C100、所有者C101、访问权限C102、大小C103、上次访问日期/时间C104、文件名C105、扩展部分C106和数据块地址C107。扩展部分C106是出于这一示例的目的而添加的有特点的部分,并且例如包括引用目的地索引节点编号C106A、重复标志C106B、存根化标志C106C、链接目的地C106D和引用计数C106E。引用目的地索引节点编号C106A是用于标识数据引用目的地索引节点的信息。在克隆文件的情况下,在引用目的地索引节点编号C106A中配置克隆源文件索引节点编号。在克隆源文件的情况下,在引用目的地索引节点编号C106A中配置值。这是因为引用目的地不存在。重复标志C106B是示出重复过程是否已经结束的信息。在重复过程已经结束并且已经在存档装置20中创建重复件的情况下,在重复标志中配置ON。在尚未执行重复过程的情况下,即在尚未在存档装置20中创建重复件的情况下,配置重复标志为OFF。存根化标志C106C是示出是否已经执行存根化过程的信息。在已经执行存根化并且已经将文件转换成存根化的文件的情况下,在存根化标志中配置ON。在尚未将文件转换成存根化的文件的情况下,配置存根化标志为OFF。链接目的地C106D是用于引用在存档装置20以内的重复的文件的链接信息。在已经完成重复过程的情况下,在链接目的地C106D中配置值。在文件存储装置10执行召回过程等的情况下,可以通过引用链接目的地C106D来从存档装置20获取重复的文件数据。引用计数C106E是用于管理克隆源文件的生命的信息。每当创建引用克隆源文件的克隆文件时将引用计数C106E的值递增1。因此例如在从五个克隆文件引用的克隆源文件的引用计数C106E中配置“5”。在删除或者存根化引用克隆源文件的克隆文件时将引用计数C106E的值递减1。因此在以上提到的情况下,引用计数C106E的值在一个克隆文件已经被删除并且另一克隆文件已经被存根化的情况下转变成“3”。在引用计数C106E的值达到0时,删除克隆源文件。在这一示例中,在引用克隆源文件的克隆文件消失时,删除这一克隆源文件并且文件区域增加。图7示出重复过程的概况。以下将使用图26来进一步具体说明重复过程。文件存储装置10的数据移动器程序P101有规律地接收重复请求(S10)。重复请求例如由主机12发布。重复请求包括重复目标文件名等。数据移动器程序P101向接收程序P104发布读请求以获取用于重复目标的文件数据(S11)。接收程序P104从在RAID系统11中的主卷(逻辑卷,该逻辑卷是复制源)114读取重复目标文件的数据,并且向数据移动器程序P101递送这一数据(S12)。数据移动器程序P101向存档装置20的数据移动器程序P201发送获取的文件数据和元数据(S13)。存档装置20的数据移动器程序P201向存档装置20的接收程序P204发布写请求(S14)。接收程序P204向RAID系统次卷(复制目的地逻辑卷)214写入从文件存储装置10获取的文件(S15)。例如与文件数据块一起发送的元数据是索引节点管理表T10。在存档装置20中创建重复件时,配置重复源文件的重复标志C106B为ON。该配置可以使得使用记录重复文件名的重复文件列表而不是重复标志以管理重复的文件。关联在主卷114中的重复源文件和在次卷214中的重复文件为配对。在更新重复源文件时,向存档装置20重新传送文件。根据这一点,同步在文件存储装置10以内的重复源文件和在存档装置20以内的重复文件。在这一示例中,使用列表来管理用于文件同步过程的目标的文件。也就是说,在更新已经经历重复处理的文件的情况下,在列表上记录这一文件。文件存储装置10在适当时间向存档装置20传送在列表上记录的文件。取代列表,可以向索引节点管理表T10添加表示需要同步的标志。在已经更新文件时,配置表示对于这一文件是否需要同步的标志为ON,并且在文件同步过程已经结束时,配置这一标志为OFF。图8示出单实例过程的概况。以下将使用图28、29和30来进一步具体说明单实例过程。选择程序P105有规律地搜寻对于定义的时间段尚未访问的文件(例如对于定义的时间段尚未更新的文件)并且创建用于记录相关文件的名称的列表T11(S20)。列表T11是用于管理文件的信息,该文件将变成用于单实例过程的候选。有规律地执行的重复检测程序P106比较在列表T11上记录的单实例过程候选与现有克隆源文件。在候选文件和现有克隆源文件是匹配的情况下,重复检测程序P106删除在候选文件中的数据(S21)。重复检测程序P106在候选文件索引节点管理表T10的引用目的地索引节点编号C106A中配置克隆源文件的索引节点编号(S21)。根据这一点,将这一候选文件转换成引用克隆源文件的克隆文件。在候选文件和现有克隆源文件未匹配的情况下,重复检测程序P106创建与这一候选文件对应的新克隆源文件。重复检测程序P106删除候选文件的数据,并且此外还在候选文件的引用目的地索引节点编号C106A中配置新创建的克隆源文件的索引节点编号。图9是示出克隆源文件管理方法的图示。克隆源文件如上文说明的那样是用于存储将从一个或者多个克隆文件引用的数据的重要文件。因此,在这一示例中,在用户不可访问的具体目录之下管理克隆源文件以便保护克隆源文件免于用户错误。这一具体目录在这一示例中称为索引目录。为每个文件大小排行、如例如“1K”、“10K”、“100K”和“1M”在索引目录中提供子目录。克隆源文件使用与它自己的文件大小对应的子目录来管理。例如创建克隆源文件的文件名作为文件大小和索引节点编号的组合。具有文件大小780字节和索引节点编号10的克隆源文件的文件名变成“780.10”。相似地,具有文件大小900字节和索引节点编号50的克隆源文件的文件名变成“900.50”。使用“1KB”子目录用于管理小于1KB的克隆源文件来管理这两个克隆源文件“780.10”和“900.50”。在用于管理文件大小等于或者大于1KB、但是小于10KB的克隆源文件的“10K”子目录中管理具有文件大小7000字节和索引节点编号3的克隆源文件。因此,在这一示例中,克隆源文件按照文件大小来分类并且存储于子目录中,并且此外还使用文件大小和索引节点编号的组合作为文件名。因此可以快速地选择将与克隆候选文件(单实例过程候选文件)比较的克隆源文件从而使得有可能在相对短的时间段内完成查询处理。取代文件大小和索引节点编号的组合,例如可以从文件大小和哈希值的组合或者文件大小、索引节点编号和哈希值的组合创建克隆源文件的文件名。通过向哈希函数输入克隆源文件数据来获得哈希值。图10示出如何将在列表T11中作为单实例处理候选而记录的文件转换成克隆文件。在图10(a)的左侧上示出克隆候选文件NF。在图10(a)的右侧上示出现有克隆源文件OF。为了方便而在图10中示出元数据的部分。克隆候选文件NF和克隆源文件OF的数据均为“1234”,并且二者数据匹配。因而如图10(b)中所示,文件存储装置10删除克隆候选文件的数据,并且此外还在克隆候选文件的引用目的地索引节点编号C106A中配置“10”,它是克隆源文件的索引节点编号。根据这一点,将克隆候选文件NF转换成引用克隆源文件OF的克隆文件CF。可以以数据块为单位去除重复数据、即与克隆源文件的数据匹配的克隆文件数据,因为在克隆源文件中的所有数据被引用。图11示出更新克隆文件的情况。在克隆文件被主机12更新并且是与克隆源文件的数据的部分未匹配的情况下,克隆文件仅存储相对于克隆源文件的差异数据。在图11的示例中,在克隆文件的头部的两个数据块从“1”和“2”更新成“5”和“6”。因而克隆文件仅存储作为差异数据的“5”和“6”并且对于其它数据“3”和“4”继续引用克隆源文件。虽然在附图中未具体示出,但是可以使用游程长度或者某种其它这样的数据压缩方法来压缩克隆源文件和克隆文件中的任一文件或者二者。可以通过执行数据压缩来进而更高效地使用文件存储装置10的存储区域。将通过参照图12至14说明单实例过程的多个应用示例。在图12至14中,仅示出边缘侧场站的配置。图12是将单实例处理应用于虚拟桌面环境的情况。在图12的示例中,主机12被配置为虚拟服务器并且启动多个虚拟机1200。客户端终端13经由每个虚拟机1200对文件进行操作。客户端终端13例如可以被配置为未包括辅助存储装置的瘦客户端终端。在文件存储装置10中的文件系统管理虚拟机1200的启动盘映像(VM映像)作为克隆文件。已经变成克隆文件的每个启动盘映像引用黄金映像(GI)。分别管理在每个启动盘映像与黄金映像之间的差异数据作为差异数据(DEF)。因此,在已经将单实例处理应用于虚拟桌面环境的情况下,可以减少虚拟机的启动盘映像的大小。因此即使在已经创建大量虚拟机1200的情况下仍然可以使作为整体的数据存储区域更小。图13示出将单实例处理应用于文档管理系统的情况的示例。文件存储装置10的文件系统管理多个客户端终端12共享的共享文件和从共享的文件得到的多个有关文档。从共享的文件得到的有关文档是引用共享的文档作为克隆源文件的克隆文件。因此,在多个用户基于共享的文档创建有关文档的情况下,可以在创建有关文档作为克隆文件时高效地使用存储区域。图14是示出将单实例处理应用于数据库系统的情况的示例。用于测试使用的数据库服务器12A、用于开发使用的数据库服务器12B和用于操作使用的数据库服务器12C各自包括数据库程序1201。用户经由客户端终端13访问他被授权从在服务器12A至12C之中使用的服务器并且使用数据库。文件存储装置10的文件系统管理母版表、黄金映像(该黄金映像是母版表的副本)和作为用于引用黄金映像的克隆文件而创建的克隆数据库。测试数据库服务器12A和开发数据库服务器12B的数据库开发程序1201使用分别已经作为克隆文件而创建的数据库。用作为克隆文件而创建的数据库对应地管理在作为克隆文件而创建的数据库与黄金映像之间的差异数据。因此,在向多个客户端终端13提供数据库访问的情况下,可以在为每个数据库应用预备作为克隆文件而创建的数据库时高效地使用存储区域。以上已经描述应用单实例处理的多个示例,但是以上给出的描述仅为示例,并且本发明也可以应用于其它配置。图15示出存根化过程的概况。数据移动器程序P101在定义的时间启动并且校验主卷114的空闲容量而在空闲容量小于阈值的情况下按照从具有最旧上次访问日期/时间的文件起的顺序执行存根化(S30)。存根化是指用于使目标文件成为存根化的文件的过程。存根化过程删除在文件存储装置10这一侧上的数据并且仅留下存档装置20的重复的文件的数据。在主机12访问存根化的文件时,从存档装置20读取并且在文件存储装置10中存储存根化的文件的数据(召回过程)。图16示出克隆源文件删除条件。如关于图6的引用计数C106E说明的那样,每当创建以克隆源文件作为引用目的地的克隆文件时,将克隆源文件的引用计数C106E的值递增1。备选地,在将克隆文件转换成存根化的文件时,或者在删除克隆文件时,每次将引用计数C106E递减1。然后,在引用计数C106E的值达到0的时间点,不再有直接引用这一克隆源文件的任何克隆文件,并且克隆源文件变成删除目标。图17示出接收程序P104的读请求过程的概况。接收程序P104在从主机102接收读请求(S40)时从主卷114获取读目标文件(S41)。在读目标文件已经被存根化或者在主卷114中无数据的情况下,接收程序P104实施召回过程并且从次卷214读取该读目标文件的数据(S42)。接收程序P104在主卷114中存储从存档装置20的次卷214读取的数据之后向主机12传送这一数据(S43)。在已经召回读目标文件时,接收程序P104从主卷114读取这一文件数据并且向主机12传送它。由于存储装置120被多个主机12共享,所以可能有根据更早接收的另一访问请求来召回读目标存根化的文件。可以通过校验索引节点管理表T10的块地址C107的值是否为0来确定是否已经完成召回。在已经完成召回的情况下,在块地址中配置除了0之外的地址。图18示出通过接收程序P104的写请求过程的概况。接收程序P104在从主机12接收写请求(S44)时校验写目标文件是否已经被转换成存根化的文件(S45)。在写目标文件已经被转换成存根化的文件的情况下,也就是说,在写目标文件被存根化的情况下,接收程序P104从存档装置20获取写目标文件的所有数据。接收程序P104向文件存储装置10的文件系统写入获取的数据并且配置写目标文件的存根化标志C106C为OFF(S46)。然后,接收程序P104向写目标文件写入该写数据,并且此外还在更新列表中记录写目标文件的名称(S47)。由于写目标文件的内容根据向它写的写数据改变,所以使写目标文件成为文件同步的目标。在写目标文件尚未被存根化的情况下,省略以上描述的步骤S46,并且执行步骤S47。图19示出文件复制过程的概况。共享文件存储装置10的用户可以按照需要重新使用在文件存储装置10中的文件并且可以创建新文件。在重新使用文件时,产生文件的副本。可以如对于正常文件完成的那样照常确切地复制所有数据,但是根据这一点在文件存储装置10中存储重复数据。因而在这一示例中,单实例过程用来在文件副本创建时减少存储容量。接收程序P104在从主机12接收复制请求(S48)时创建作为复制源(图19的克隆文件1)而选择的文件的副本(克隆文件2)(S49)。也就是说,接收程序P104通过仅复制元数据而不是复制数据来创建指定文件的副本。在作为复制源文件指定文件不是克隆文件的情况(比如正常文件的非克隆文件情况)下,接收程序P104先将复制源文件转换成克隆文件。接着,接收程序P104通过复制被转换成克隆文件的复制源文件的元数据(索引节点管理表T10)并且重新使用这一元数据的部分来创建副本文件(该副本文件是克隆文件)。由于克隆文件数目增加,所以克隆源文件的引用计数C106E的值被递增1,该克隆源文件是这一克隆文件的引用目的地。图20是示出接收程序P104执行的读过程和写请求过程的流程图。接收程序P104在从主机12接收读请求或者写请求时启动和执行以下处理。接收程序P104确定主机12请求的目标文件的存根化标志C16C是否被配置为ON(S100)。在存根化标志未被配置为ON(S100:否)的情况下,接收程序P104移向以下将进一步说明的图12的处理,因为目标文件尚未被转换成存根化的文件。在目标文件的存根化标志被配置为ON(S100:是)的情况下,接收程序P104判决来自主机12的处理请求类型是否为读请求或者写请求(S101)。在读请求(S101:读)的情况下,接收程序P104引用目标文件的索引节点管理表T10并且确定块地址是否有效(S102)。在块地址有效(S102:是)的情况下,接收程序P104读取目标文件的数据并且向主机12发送这一数据,该主机是请求源(S103)。在块地址有效的情况、也就是块地址被配置为除了0之外的值的情况下,目标文件尚未被转换成存根化的文件。因此,召回过程是不必要的。接收程序P104更新目标文件索引节点管理表T10的上次访问日期/时间C104的值并且结束这一处理(S105)。在目标文件块地址无效(S102:否)的情况下,接收程序P104请求数据移动器程序P101执行召回过程(S104)。数据移动器程序P101执行召回过程。接收程序P104向主机12发送从存档装置20获取的目标文件(S104)、更新目标文件索引节点管理表T10的上次访问日期/时间C104并且结束这一处理(S105)。在来自主机12的处理请求是写请求(S101:写)的情况下,接收程序P104请求数据移动器程序P101执行召回过程(S106)。数据移动器程序P101响应于这一请求执行召回过程。接收程序P104向从存档装置20获取的目标文件写入该写数据并且更新文件数据(S107)。接收程序P104也更新目标文件索引节点管理表T10的上次访问日期/时间C104(S107)。接收程序P104配置用写数据更新的文件的存根化标志C106C为OFF并且此外还配置重复文件的存根化标志为ON(S108)。接收程序P104在更新列表中记录用写数据更新的文件的名称并且结束这一处理(S109)。参照图21,在主机12的处理目标文件的存根化标志C106C中配置OFF(S100:否)的情况下,接收程序P104移向图23的步骤S110。接收程序P104确定来自主机12的处理请求是否为读请求或者写请求(S110)。在读请求(S110:读)的情况下,接收程序P104确定读目标文件是否为克隆文件(S111)。在读目标文件不是克隆文件(S111:否)的情况下,接收程序P104根据读目标文件索引节点管理表T10的块地址读取数据并且向主机12发送这一数据(S112)。接收程序P104更新读目标文件的上次访问日期/地址C104(S119)。在读目标文件是克隆文件(S111:是)的情况下,接收程序P104合并从克隆源文件获取的数据与在读目标克隆文件中存储的差异数据并且向主机12发送这一合并的数据(S113)。接收程序P104更新克隆文件的上次访问日期/时间C104,该克隆文件是读目标文件(S119)。在来自主机12的处理请求是写请求(S110:写)的情况下,接收程序P104确定写目标文件是否为重复件(S114)。在写目标文件是重复件(S114:是)的情况下,接收程序P104在更新列表中记录写目标文件的名称(S115)。这是因为写数据文件被写数据更新并且不再与在存档装置20中的重复件匹配。在写目标文件不是重复件(S114:否)的情况下,接收程序P104略过步骤S115并且移向步骤S116。接收程序P104确定写目标文件是否为克隆文件(S116)。在写目标文件不是克隆文件(S116:否)的情况下,接收程序P104基于写目标文件的块地址C107向写目标文件写入该写数据(S117)。接收程序P104更新其中写人该写数据的写目标文件的上次访问日期/时间C104(S119)。在写目标文件是克隆文件(S116:是)的情况下,接收程序P104根据克隆文件的块地址写入该写数据(S118)。接收程序P104仅关于克隆文件写数据而未更新克隆源文件的数据。根据这一点,写目标克隆文件存储与克隆源文件的数据不同的差异数据(S118)。图23是示出接收程序P104执行的复制处理的流程图。接收程序P104在从主机12接收复制请求时执行这一处理。接收程序P104确定作为复制源而指定文件的存根化标志C106C是否被配置为ON(S130)。在复制源文件的存根化标志被配置为ON(S130:是)的情况下,接收程序P104确定复制源文件的块地址是否有效(S131)。即使在已经将复制源文件转换成存根化的文件时仍然可能有已经根据另一访问请求完成召回过程的情况。在复制源文件块地址有效(S131:是)的情况下,接收程序P104根据这一块地址获取文件数据和元数据(索引节点管理表T10)(S132)。在复制源文件块地址无效(S131:否)的情况下,接收程序P104请求数据移动器程序P101执行与复制源文件的数据有关的召回过程(S133)。接收程序P104在获取复制源文件的文件数据和元数据时在主卷114以内创建复制源文件的副本(S134)。这一副本文件是正常文件(非克隆文件)。接收程序P104更新复制源文件的上次访问日期/时间C104(S135)。接收程序P104确定用于在步骤S134中创建的副本文件的重复处理是否已经结束(S136)。在重复处理已经结束(S136:是)的情况下,接收程序P104结束这一处理。在重复处理尚未结束(S136:否)的情况下,接收程序P104请求数据移动器程序P101执行重复处理(S137)。在复制源文件的存根化标志C106C被配置为OFF(S130:否)的情况下,接收程序P104确定复制源文件是否为克隆文件(S138)。在复制源文件不是克隆文件(S138:否)的情况下,接收程序P104调用重复去除程序(图30)并且将复制源文件转换成克隆文件(S139)。不是克隆文件的文件包括克隆源文件和正常文件,但是主机12不能识别并且不能直接访问克隆源文件。接收程序P104被转换成克隆文件的克隆源文件的复制管理表T10的信息并且创建复制源文件的副本文件(S140)。也就是说,也创建副本文件作为克隆文件。接收程序P104将复制源文件引用的克隆源文件的引用计数C106E的值递增1(S141)。这是因为在步骤S139至步骤S140中新创建克隆文件。接收程序P104更新复制源文件的上次访问日期/时间C104(S135)并且移向步骤S136。将省略后续步骤S136和S137的说明。图23是示出接收程序P104执行的删除过程的流程图。接收程序P104在从主机12接收删除请求时执行这一处理。接收程序P104确定删除目标文件的存根化标志C106C是否被配置为ON(S150)。接收程序P104在删除目标文件的存根化标志被配置为ON(S150:是)的情况下删除该删除目标文件的索引节点管理表T10(S151)。此外,接收程序P104指令存档装置20删除文件,该文件是删除目标文件的重复件(S152),并且结束这一处理。在删除目标文件的存根化标志被配置为OFF(S150:否)的情况下,接收程序P104确定删除目标文件是否为非克隆文件(S153)。非克隆文件是除了克隆文件之外的文件、也就是正常文件。在删除目标文件是正常文件(S153:是)的情况下,接收程序P104删除该删除目标文件的索引节点管理表T10(S154)并且结束处理。在删除目标文件不是正常文件(S153:否)的情况下,接收程序P104确定删除目标文件是否为克隆文件(S155)。在删除目标文件不是克隆文件(S155:否)的情况下,接收程序P104结束处理。在删除目标文件是克隆文件(S155:是)的情况下,接收程序P104删除该删除目标克隆文件的数据(差异数据),并且此外还将引用目的地克隆源文件的引用计数C106E递减1(S156)。接收程序P104确定克隆源文件引用计数C106E的值是否为0(S157)。在引用计数C106E的值不是0(S157:否)的情况下,接收程序P104结束处理。在克隆源文件引用计数C106E的值是0(S157:是)的情况下,接收程序P104删除克隆源文件的文件数据和元数据(S158)。图24是示出数据移动器程序P101的处理。这一处理是根据事件的出现而开始的由事件驱动的处理。数据移动器程序P101确定预先配置的指定事件中的任何事件是否已经出现(S160)。在事件出现(S160:是)时,数据移动器程序P101确定表示经过定义的时间的事件是否已经出现(S161)。在指示经过定义的时间的事件已经出现(S161:是)的情况下,数据移动器程序P101执行存根化处理(S162)。以下将使用图25来进一步具体说明存根化过程。在指示经过定义的时间的事件尚未出现(S160:否)的情况下,数据移动器程序P101确定它是否为需要执行重复处理的事件(S163)。在它是需要执行重复处理的事件(S163:是)的情况下,数据移动器程序P101执行重复处理(S164)。以下将使用图26来进一步具体说明重复过程。在它不是需要执行重复处理的事件(S163:否)的情况下,数据移动器程序P101确定它是否为需要文件同步的事件(S165)。在它是需要文件同步的事件(S165:是)的情况下,数据移动器程序P101执行文件同步处理(S166)。以下将使用图27进一步具体说明文件同步过程。在它不是需要文件同步的事件(S165:否)的情况下,数据移动器程序P101确定它是否为需要执行召回处理的事件(S167)。在它是需要执行召回处理的事件(S167:是)的情况下,数据移动器程序P101从存档装置20获取文件数据并且向文件存储装置10发送这一文件数据(S168)。由于已经在文件存储装置10中留下源数据,所以仅需从存档装置20获取文件数据。图25是具体示出数据移动器程序P101执行的存根化过程的流程图。数据移动器程序P101校验文件存储装置10的文件系统的空闲容量RS(S170)。数据移动器程序P101确定空闲容量RS是否小于指定空闲容量阈值ThRS(S171)。在空闲容量RS等于或者大于阈值ThRS(S171:否)的情况下,数据移动器程序P101结束这一处理并且返回到图24的处理。在空闲容量RS小于阈值ThRS(S171:是)的情况下,数据移动器程序P101按照具有最旧上次访问日期/时间的文件起的顺序选择重复的文件直至空闲容量RS变成等于或者大于阈值ThRS(S172)。数据移动器程序P101删除选择的文件的数据、配置这一文件的存根化标志为ON,并且配置这一文件的重复标志为OFF(S173)。根据这一点,将在步骤S172中选择的文件转换成存根化的文件。此外,在克隆文件被转换成存根化的文件的情况下,数据移动器程序P101将这一克隆文件引用的克隆源文件的引用计数C106E的值递减1(S173)。图26是具体示出数据移动器程序P101执行的重复过程的流程图。数据移动器程序P101从存档装置20获取重复文件存储目的地(S180)。数据移动器程序P101在重复目标索引节点管理表T10的链接目的地C106D中配置获取的存储目的地(S181)。数据移动器程序P101向接收程序P104发布读请求并且获取文件,该文件是重复处理的目标(S182)。数据移动器程序P101向存档装置20传送重复目标文件(S183)。数据移动器程序P101配置重复目标文件的重复标志C106B为ON(S184)。图27是示出数据移动器程序P101执行的文件同步过程的流程图。数据移动器程序P101向接收程序P104发布读请求并且获取在更新列表中记录的文件的数据和元数据(S190)。更新列表是用于从在重复处理已经被完成的文件之中标识更新的并且其中差异数据在重复处理之后出现的文件的信息。更新列表是用于管理将被执行文件同步处理的文件的信息。数据移动器程序P101向存档装置20传送获取的数据(S191)并且删除更新列表的内容(S192)。图28是示出选择程序P105的操作的流程图,该选择程序是用于执行单实例处理的计算机程序的部分。选择程序P105向接收程序P104发布对于文件系统管理的每个文件的读请求(S200)。选择程序P105选择上次访问日期/时间LT(在索引节点管理表T10的列C104中记录的值)比指定访问日期/时间阈值ThLT更旧的所有文件(S200)。选择程序P105向单实例目标文件T11添加选择的文件的名称(S200)。图29是示出重复检测程序P106的操作的流程图,该重复检测程序与选择程序P105一起是用于执行单实例处理的计算机程序的部分。重复检测程序P106从单实例目标列表T11获取目标文件名(S210)。重复检测程序P106调用重复去除程序(图30)并且执行目标文件的单实例化(创建克隆文件)(S211)。重复检测程序P106执行步骤S210和S211直至单实例处理已经被应用于在列表T11中记录的所有文件(S212)。图30是示出重复去除程序的操作的流程图。重复去除程序在索引目录(图9)之下的子目录中搜寻与目标文件的大小对应的子目录(S220)。重复去除程序比较目标文件与在子目录中的克隆源文件(S221)并且确定是否有与目标文件匹配的克隆源文件(S222)。在搜索目标子目录中的现有克隆源文件都未与目标文件匹配(S222:否)的情况下,重复去除程序添加新克隆源文件(S223)。也就是说,重复去除程序向搜索目标子目录添加目标文件作为新克隆源文件。重复去除程序在新创建的克隆源文件的引用计数C106E中配置“0”(S224)。重复去除程序在目标文件引用目的地索引节点编号C106A中配置克隆源文件索引节点编号(S225)。重复去除程序删除目标文件的数据(S226)并且将克隆源文件引用计数C106E的值递增1(S227)。根据以这一方式配置的示例,可以高效地使用文件存储装置10的存储区域(文件系统区域)。出于这一原因,可以在文件存储装置10中存储更多的大量文件从而增加在访问时间的响应性并且此外还增强用户可用性。在这一示例中,由于克隆源文件不是重复处理的目标,所以作为用于执行重复处理的前提的存根化过程也未被应用于克隆源文件。因此有可能防止不能被用户直接访问的克隆源文件被转换成存根化的文件,因为它看来具有低利用频率。作为这一点的结果,有可能维持引用克隆源文件的克隆文件的响应性能。在这一示例中,在已经接收文件复制请求的情况下,创建副本文件作为克隆文件。出于这一原因,无需复制文件数据从而使文件存储装置10的存储区域被高效地使用。在这一示例中,在已经接收文件复制请求并且与复制目标文件匹配的克隆源文件不存在的情况下,创建与复制目标文件匹配的新克隆源文件,并且将复制目标文件转换成克隆文件。因此,可以快速地应用单实例处理,可以缩短重复数据存在的时间,并且可以有效地使用文件存储装置10的存储区域。也就是说,可以在文件复制的在按照正常周期执行单实例处理之前的时间点立即去除重复数据。在这一示例中,每当创建引用克隆源文件的克隆文件时,将克隆源文件的引用计数C106E的值递增1。然后在这一示例中,每当删除克隆文件或者将克隆文件转换为存根化的文件时,将引用计数C106E的值递减1,而在引用计数C106E的值达到0时删除克隆源文件。因此只要有引用克隆源文件的克隆文件就可以延续克隆源文件从而使得有可能维持克隆文件响应性能。此外,由于在无引用克隆源文件的克隆文件的情况下删除克隆源文件,所以可以有效地使用文件存储器装置10的存储区域。在这一示例中,在对于克隆文件特有的数据(差异数据)以及从克隆源文件数据引用的数据二者被存储的状态中,在存档装置20中存储克隆文件。也就是说,在存档装置20中存储的克隆文件存储所有数据。因此,在文件存储装置10中存储的克隆文件或者克隆源文件如果被损坏的情况下,可以从存档装置20向文件存储装置10回写完整克隆文件。在这一示例中,在对用户不可见的特殊目录(索引目录)中存储克隆源文件。这使得有可能保护克隆源文件免于用户错误并且增强分级存储系统的可靠性。在这一示例中,在索引目录中通过文件大小排行来设置子目录,并且在对应文件大小的子目录中管理克隆源文件。因此,可以基于目标文件的大小缩小用于克隆源文件的搜索范围从而使与目标文件匹配的克隆源文件能够被高速取回。示例2将通过参照图31至38说明第二示例。这一示例是第一示例的变化。因此,说明将聚焦于与第一实施例的差异。在这一示例中,克隆源文件也是在存档装置20侧用于重复处理和存根化处理的目标。在这一示例中,适当评估克隆源文件的上次访问日期/时间,并且防止将引用的克隆源文件转换成存根化的文件。图31示出使用这一示例的重复过程来传送数据。图31(a)示出克隆源文件和正常文件的情况。在存档装置20中创建克隆源文件和正常文件(非克隆文件)的重复件的情况下,从文件存储装置10向存档装置20传送所有文件数据。备选地,在克隆文件的情况下,如图31(b)中所示,从文件存储装置10向存档装置20仅传送克隆文件特有的数据(与克隆源文件的差异数据)。在存档装置20中,重复的克隆文件引用与在文件存储装置10中相同的重复的克隆源文件中的数据的部分或者全部。在第一示例中,在存储所有数据的状态中向存档装置20传送克隆文件。因此,不仅传送重复数据,并且通信网络拥塞,浪费地使用存档装置20的存储区域。备选地,在这一示例中,如图31中所示从文件存储装置10向存档装置20仅传送克隆文件的差异数据。这使得有可能阻止传送重复数据并且高效地使用存档装置20的存储区域。然而在这一示例中,由于克隆源文件也视为重复处理目标,所以有在克隆文件之前将克隆源文件转换成存根化的文件的可能性。如上文描述的那样,克隆源文件是用作引用的文件并且使用特殊目录来管理以防止它由于错误而被损坏或者去除。因此,即使在引用克隆源文件的克隆文件被频繁使用时,这仍然未影响克隆源文件的利用频率,该克隆源文件存储引用的数据。作为这一点的结果,引用的克隆源文件在进行引用的克隆文件之前被转换成存根化的文件。由于必须在引用存根化的克隆源文件时执行召回过程,所以克隆文件的响应性能减少并且用户可用性变差。因而在这一示例中,基于克隆文件的上次访问日期/时间计算克隆源文件的上次访问日期/时间。以下方法例如将视为用于基于克隆文件的上次访问日期/时间计算克隆源文件的上次访问日期/时间的方法。第一方法是其中引用相同克隆源文件的多个克隆文件的相应上次访问日期/时间中的最新近上次访问日期/时间用作克隆源文件的上次访问日期/时间的方法。第二方法是用于计算引用相同克隆源文件的多个克隆文件的相应上次访问日期/时间的加权或者未加权平均值的方法。将考虑上文描述的两种方法的相对优点。在第一方法的情况下,可能有多个克隆文件中的包括最新近上次访问日期/时间的克隆文件仅引用克隆源文件作为形式而未实际拥有与克隆源文件共享的数据的情况。根据与克隆源文件基本上无关的克隆文件的上次访问日期/时间确定克隆源文件的上次访问日期/时间被认为不适当和不期望的。此外,例如在第一方法的情况下,在仅一个克隆文件的上次访问日期/时间是新的,并且尽管事实为多个克隆文件中的大多数克隆文件的上次访问日期/时间是旧的、仍然仅使用这一个新的上次访问日期/时间时,有这一上次访问日期/时间与实际情形相距甚远的可能性。尽管事实为使用多数克隆文件难以被使用而仍然使用仅一个克隆文件这样的事实从多数判决观点来看应当视为克隆源文件的作用结束。因此,在这一示例中,使用第二方法,计算多个克隆文件的上次访问日期/时间的平均值,并且配置这一平均值作为克隆源文件的上次访问日期/时间。除非从权利要求中省略,则也在本发明的范围中包括第一方法。图32是示出用于计算克隆源文件的上次访问日期/时间的方法(第二方法)的图示。图32示出引用克隆源文件的三个克隆文件CF1、CF2、CF3。克隆文件CF1的数据与克隆源文件的数据完全匹配。克隆文件CF2的数据与克隆源文件的数据多数匹配、但是部分不同。克隆文件CF3的数据与克隆源文件的数据完全不匹配。根据这一点,基于克隆文件CF的上次访问日期/时间LT1和克隆文件CF2的上次访问日期/时间LT2计算克隆文件的上次访问日期/时间的平均值ALT(ALT=(LT1+LT2)/2)。在克隆源文件的上次访问日期/时间C104中配置这一平均值ALT。在计算平均值ALT时排除与克隆源文件的数据全然不同的克隆文件CF3的上次访问日期/时间LT3以便通过消除与克隆源文件无关的克隆文件来计算与实际情形最接近地近似的上次访问日期/时间。换而言之,消除具有完全不兼容数据的克隆文件是指根据兼容数据的程度对克隆文件加权并且计算上次访问日期/时间的平均值。也就是说,通过将数据兼容克隆文件CF1和CF2的上次访问日期/时间LT1和LT2乘以系数W1(例如1)来使用这些上次访问日期/时间LT1和LT2,并且通过将数据不兼容克隆文件CF3的上次访问日期/时间LT3乘以系数W2(例如0)来使用这一上次访问日期/时间LT3。这使得有可能使用ALT=((LT1xW1+LT2xW2+LT3xW3)/3)来发现上次访问日期/时间的平均值ALT。加权的系数W1可以在值等于或者大于0时被配置为除了1之外的值。加权的系数W2可以在值小于W1时被配置为至少为0的值。可以根据引用克隆源文件数据的比率配置加权的系数W的值。然而必须最终调整平均值ALT以免与相应克隆文件的上次访问日期/时间LT相距甚远。图33是示出用于获取上次访问日期/时间的程序的操作的流程图。上次访问日期/时间获取程序(下文为LT获取程序)由接收程序P104调用。在执行需要上次访问日期/时间的过程的情况下启动LT获取程序。首先,LT获取程序确定目标文件是否为克隆源文件(S300)。在目标文件是克隆源文件(S300:是)的情况下,上次访问日期/时间从引用克隆源文件的克隆文件获取上次访问日期/时间,并且如使用图32描述的那样来计算其平均值(S30)。LT获取程序向作为请求源的接收程序P104返回计算的平均值作为克隆源文件的上次访问日期/时间(S302)并且结束处理。在目标文件不是克隆源文件(S300:否)的情况下,LT获取程序从索引节点管理表T10的上次访问日期/时间列C104获取值(S303)。LT获取程序向接收程序P104返回获取的上次访问日期/时间(S302)并且结束处理。图34是示出接收程序P104执行的读请求过程和写请求过程的流程图。接收程序P104在从主机12接收处理请求时确定ON是否在目标文件的存根化标志中被配置(S310)。在存根化标志被配置为OFF(S310:否)的情况下,接收程序P104移向在图21中描述的处理。在存根化标志被配置为ON(S310:是)的情况下,接收程序P104确定目标文件是否为克隆文件(S311)。在目标文件是克隆文件(S311:是)的情况下,接收程序P104移向图35的处理。在目标文件不是克隆文件(S311:否)的情况下,接收程序104移向图36的处理。图35是在目标文件是克隆文件的情况下的处理。图35中所示处理包括图20中所示处理的步骤S101、S102、S103、S105、S107、S108和S109、但是未包括图20的步骤S104和S106。在这一示例中,由于也可以将克隆源文件转换成存根化的文件,所以在图35中所示处理中,执行新步骤S312和S313取代步骤S104,并且执行新步骤S314和S315取代步骤S106。在读请求(S101:读)的情况下,接收程序P104确定目标文件的块地址是否有效(S102)。在块地址无效(S102:否)的情况下,接收程序P104关于被作为目标文件的克隆文件引用的克隆源文件的数据请求召回(S312)。接收程序P104也关于作为目标文件的克隆文件的数据请求召回、合并克隆源文件数据与克隆文件数据并且向请求源返回结果(S313)。备选地,在写请求(S101:写)的情况下,接收程序P104关于作为目标文件的克隆文件引用的克隆源文件的数据请求召回(S314)。接收程序P104也关于作为目标文件的克隆文件的数据请求召回(S315)。随后,接收程序P104用写数据改写作为目标文件的克隆文件的数据(S107)。图36是示出在图34的处理中的目标文件不是克隆文件的情况下的处理的流程图。由于这一处理仅包括使用图20描述的步骤S101至S109,所以将省略说明。图37是示出用于从文件存储装置10读取数据用于向存档装置20传送用于重复过程或者文件同步过程的处理的流程图。首先,接收程序P104确定目标文件是否为克隆文件(S320)。在目标文件不是克隆文件(S320:否)的情况下,接收程序P104根据索引节点管理表T10的块地址获取数据并且向请求源返回这一数据(S321)。接收程序P104更新目标文件的上次访问日期/时间C104(S322)并且结束处理。在目标文件是克隆文件(S320:是)的情况下,接收程序P104根据索引节点管理表T10的块地址获取克隆文件特有的数据(差异数据)并且向请求源返回这一数据(S323)。图38是示出接收程序P104执行的文件复制过程的流程图。与使用图22描述的处理比较,这一处理包括新步骤S330取代步骤S133。在复制目标文件的块地址无效(S131:否)的情况下,接收程序P104关于克隆源文件和克隆文件请求召回并且获取文件数据和元数据(S330)。这样配置这一示例实现与第一实施例相同的效果。此外,在这一示例中,克隆源文件也是重复处理的目标,并且也在存档装置20这一侧上维持单实例关系。因此,在这一示例中,仅需向存档装置20传送克隆文件的特有数据从而使得有可能减少从文件存储装置10向存档装置20的传送大小。也有可能高效使用存档装置20的存储区域。在这一示例中,基于克隆文件的上次访问日期/时间计算克隆源文件的上次访问日期/时间(例如发现平均值)。因此有可能阻止被克隆文件引用的克隆源文件在克隆文件之前被转换成存根化的文件。这防止克隆文件响应性能降低。示例3图39是示出在第三示例的数据移动器程序P101的操作期间的存根化过程的操作的流程图。数据移动器程序P101校验文件系统的空闲容量RS(S340)并且确定这一空闲容量RS是否小于指定阈值ThRS(S341)。在空闲容量RS等于或者大于阈值ThRS(S341:否)的情况下,数据移动器程序P101结束这一处理。在空闲容量RS小于阈值ThRS(S341:是)的情况下,数据移动器程序P101向接收程序P104发布读请求,并且获取每个文件的上次访问日期/时间(S342)。数据移动器程序P101从尚未经历单实例化的文件(非克隆文件)之中选择上次访问日期/时间比指定阈值更旧的文件(S342)。数据移动器程序P101删除在步骤S342中选择的文件的数据、配置这一文件的存根化标志C106C为ON并且此外还配置这一文件的重复标志C106B为OFF(S343)。数据移动器程序P101重新校验文件系统的空闲容量RS,并且确定空闲容量RS是否变成等于或者大于阈值ThRS(S344)。在空闲容量RS已经变成等于或者大于阈值ThRS(S344:是)的情况下,数据移动器程序P101结束这一处理。在即使非克隆文件已经被转换成存根化的文件时空闲容量RS仍然未变成等于或者大于阈值ThRS(S344:否)的情况下,数据移动器程序P101选择单实例化的文件(克隆文件),并且将这一克隆文件转换成存根化的文件(S345)。数据移动器程序P101从克隆文件之中选择单实例化时段SIT比指定阈值ThSIT更短的克隆文件直至空闲容量RS变成等于或者大于阈值ThRS(S345)。数据移动器程序P101删除选择的文件的数据并且配置这一文件的存根化标志为ON(S345)。数据移动器程序P101也将克隆源文件的引用计数C106E的值递减1(S345)。这样配置这一示例使得有可能组合这一示例与第一示例和第二示例二者,并且这一示例实现与第一示例或者第二示例相同的效果。在这一示例中,在执行存根化过程时,首先将非克隆文件转换成存根化的文件(S342、S343),并且在这不够时,将克隆文件转换成存根化的文件(S345)。此外,在这一示例中,还从作为克隆文件的时段(单实例化时段)在克隆文件中为最短的克隆文件开始执行存根化过程。存根化文件候选包括以下两个类型的文件。第一类型是在文件创建时间点经历单实例化的文件。也就是如下文件,该文件在文件创建时间的用户的显式指令上被转换成克隆文件。第二类型是新近已经根据单示例处理的循环实施而转换成克隆文件的文件。第一类型的克隆文件从文件创建时间起是克隆文件并且这样已经有助于将存储的容量减少相对长的时间。备选地,第二类型的克隆文件被新近地转换成克隆文件并且很少有助于减少存储的容量。因而在这一示例中,通过在文件存储装置10中尽可能多地留下第一类型的克隆文件。出于这一原因,在将非克隆文件转换成存根化的文件之后将第二类型的克隆文件转换成存根化的文件。本发明不限于上文描述的相应示例。本领域普通技术人员将能够进行各种添加和改变而未脱离本发明的范围。例如以上描述的本发明的计数特征可以通过按照需要组合这些特征而付诸实践。也可以例如表达本发明为用于控制管理装置的计算机程序的发明如下。表达1.一种用于使管理分级存储系统的计算机作为管理装置的计算机程序,该分级存储系统用于分级地管理在第一文件管理装置和第二文件管理装置中的文件,该计算机程序分别在上述计算机上实现:重复处理部分,该重复处理部分用于在上述第二文件管理装置中创建在上述第一文件管理装置中的指定文件的重复件;重复去除处理部分,该重复去除处理部分用于通过根据预先配置的第一指定条件选择在上述第一文件管理装置中的另一指定文件作为重复数据去除目标,并且将选择的上述另一指定文件转换成引用源文件来去除重复数据,该引用源文件引用指定引用文件的数据;以及存根化处理部分,该存根化处理部分根据预先配置的第二指定条件选择存根化候选文件,该存根化候选文件构成用于删除在上述第一文件管理装置中的上述指定文件的数据的存根化过程的目标,并且此外仅留下在上述指定文件的在上述第二文件管理装置中创建的重复件中的数据,并且此外根据预先配置的第三指定条件关于上述存根化候选文件执行上述存根化过程。表达2.根据表达1的计算机程序,还包括文件访问接收部分,该文件访问接收部分在上述第一文件管理装置中的复制源文件的重复件已经被请求的情况下创建上述复制源文件重复件作为上述引用源文件。表达3.根据表达1或者2的计算机程序,其中上述第一文件管理装置被配置为用户终端可以直接访问的文件管理装置,并且上述第二文件管理装置被配置为所述用户终端不能直接访问的文件管理装置。表达4.根据表达1至3中的任一表达的计算机程序,其中上述第一指定条件是从在上述第一文件管理装置中的文件之中选择上次访问日期/时间比预先配置的指定时间阈值更旧的文件作为上述另一指定文件。表达5.根据表达1至4中的任一表达的计算机程序,其中上述第二指定条件是在上述第一文件管理装置以内的空闲容量降至指定自由空间阈值以下的情况下选择上述存根化候选。表达6.根据表达1至5中的任一表达的计算机程序,其中上述第三指定条件是按照从具有最旧上次访问日期/时间的文件起的顺序从上述存根化候选文件之中选择文件直至上述空闲容量变成等于或者大于上述指定空闲容量阈值。表达7.根据表达1至6中的任一表达的计算机程序,其中上述引用源文件存储上述指定引用文件的索引节点编号,并且上述指定引用文件作为引用目的地与上述引用源文件关联。表达8.根据表达1至7中的任一表达的计算机程序,其中上述指定引用文件存储表示以上述指定引用文件作为引用目的地的上述引用源文件的数目的引用数目,并且每当选择上述引用源文件时或者每当为上述引用源文件实施上述存根化过程时,递减上述引用数目,并且上述文件访问接收部分能够在上述引用数目达到0时删除上述指定引用文件。表达9.根据表达1至8中的任一表达的计算机程序,其中上述指定引用文件未被选择作为上述指定文件,引用上述指定引用文件的上述引用源文件被选择作为上述指定文件,并且上述指定引用文件变成上述重复处理部分和上述存根化处理部分的处理目标。表达10.根据表达9的计算机程序,其中上述被选择作为上述指定文件的上述引用源文件在必须从上述指定引用文件的数据之中引用的所有数据被存储的状态中被发送到上述第二文件管理装置。表达11.根据表达1至10中的任一表达的计算机程序,其中上述指定引用文件根据来自在上述第一文件管理装置中设置的指定目录之下存在的并且通过文件大小排序而预先预备的多个子目录之中的与上述指定引用文件的大小对应的子目录来管理。编号列表1边缘侧2核心侧文件管理装置3管理装置10文件存储装置12主机计算机13RAID系统20存档装置21RAID系统
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1