利用多字节编码的文献检索方法及文献索引方法与流程
本发明涉及利用多字节编码而检索与用户输入的关键词匹配的文献的方法及装置。更具体地,涉及如下的方法及装置:对于构成检索对象的文献,分别利用多字节编码而构建数据库化的索引之后,在用户输入了关键词的情况下,抽取上述关键词的单位音节及单位音节的位置,通过将抽取的单位音节及单位音节的位置与之前数据库化的索引进行比较来检索文献。
背景技术:
一般,作为分析多语种的语素的方式,具有基于统计的方法和基于词典的方法。
基于统计的方法作为根据通过分析大量的多语种文档集而计算的概率而分析的方式,通过机器学习而自动分析,因此与基于词典的方法相比,难以去除错误。
另外,基于词典的方法作为分析出现在多语种的单词而标记词性并数据库化成词典而分析的方式,能够提高错误的控制及准确度,但需要由人来进行分别将单词数据库化为词典的作业,并且在每次变更词典时,均再次执行整个索引作业及数据库化作业。
本发明是在这样的技术背景下完成的,本发明的目的在于不仅充分满足以上的技术要求,并且还提供本领域技术人员无法容易地发明的追加性的技术要素。
现有技术文献
专利文献
(专利文献0001)韩国公开专利公报2001-0000673(2001.01.05.)
技术实现要素:
发明要解决的课题
本发明的目的在于,利用多字节编码而从构成检索对象的多个文献抽取索引而生成索引信息即进行数据库化,特别是,在生成索引信息时将文献标记化,对于所获得 的语节,以二音节为基准进行拆分而抽取一个以上的单位音节,另外进一步掌握该单位音节在各个语节内的位置,对于一个索引,使单位音节和单位音节的位置匹配起来的方式进行存储。
另外,本发明的目的在于以如下方式进行文献检索:对于用户输入的关键词,利用多字节编码,以二音节的单位音节及各个单位音节的位置进行匹配而分析各个关键词,并对上述分析的单位音节及各个单位音节的位置与之前生成的索引信息进行比较而判断该文献中是否包括关键词。
本发明的目的在于,特别是,以单位音节及单位音节的位置匹配的信息为基础而判断文献内是否包括关键词,从而提高准确度及速度。
解决课题的手段
为了解决上述的问题,本发明的文献检索方法包括:(a)由用户输入关键词的步骤;(b)将上述关键词以语节单位进行分离的步骤;(c)将上述关键词以n-音节(n为1以上的自然数)为基准进行拆分而获得一个以上的单位音节,并获得各个上述单位音节在上述关键词内的位置,从而生成包括上述单位音节及单位音节在上述关键词内的位置的检索信息的步骤;(d)将上述检索信息与关于一个以上的文献的索引信息进行比较,从而检索与上述单位音节及该单位音节的位置相应的文献的步骤。
另外,在上述文献检索方法中,在上述(c)步骤中,将上述分离后的关键词以二音节为基准进行拆分而获得一个以上的单位音节,并获得各个上述单位音节在上述关键词内的位置。
另外,在上述文献检索方法中,在上述(c)步骤中,在上述分离后的关键词为一音节的情况下,在上述一音节后端追加分隔符后定义为单位音节,并获得上述单位音节在关键词内的位置,从而生成包括上述单位音节及单位音节在关键词内的位置的检索信息。
另外,在上述文献检索方法中,在上述(d)步骤中,对包括上述单位音节、该单位音节的位置的检索信息与上述索引信息进行比较。
另外,在上述文献检索方法中,在上述(d)步骤中,对包括上述单位音节和该单位音节的位置的检索信息与上述索引信息进行比较而计算与上述索引信息之间的类似度,并以所计算的类似度为基准检索文献,通过比较在上述检索信息内包括的关键词的单位音节及单位音节的位置与在上述索引信息内包括的索引词的单位音节及单 位音节的位置来算出上述类似度。
另外,本发明的另一方面的文献索引方法包括:(a)下载文献,将上述文献标记化而获得一个以上的语节的步骤;(b)将上述语节以n-音节(n为1以上的自然数)为基准进行拆分而获得一个以上的单位音节,并获得各个上述单位音节在上述语节内的位置的步骤;(c)生成匹配有各个上述单位音节和该单位音节在语节内的位置的索引信息的步骤。
另外,在上述文献索引方法中,在上述(b)步骤中,在上述语节为一音节的情况下,获得上述一音节,并获得上述一音节在上述语节内的位置,并生成匹配有上述一音节和该一音节在语节内的位置的索引信息。
发明效果
根据本发明,能够准确快速地检索包括用户所希望的关键词的文献。
特别是,本发明不仅将单位音节与数据库化的索引信息进行比较,而且还将单位音节的位置与数据库化的索引信息进行比较,从而在比较关键词时能够提高准确度,进而能够比较各个单位音节的位置,由此对于无需的单位音节组合,无需进行计算,因此能够进行更加快速的检索。
附图说明
图1表示从文献将索引信息数据库化的过程。
图2表示在由用户输入关键词的情况下,检索包括上述关键词的文献的过程。
图3表示将索引信息数据库化的过程的实施例。
图4表示基于用户输入的关键词检索匹配的文献的实施例。
图5是表示本发明的索引装置的具体结构的框图。
图6是表示本发明的检索装置的具体结构的框图。
(符号说明)
[索引装置]
510文献下载部
520语节分析部
530索引信息生成部
540存储部
550索引装置控制部
[检索装置]
610关键词接收部
620检索信息生成部
630检索执行部
650检索装置控制部
具体实施方式
通过以下的参照附图而进行的详细说明,能够更加清楚地理解本发明的目的和技术结构及由此产生的作用效果的具体事项。下面,参照附图,对本发明的实施例进行详细说明。
关于本说明书所公开的实施例,不应解释或利用为对本发明的范围的限定。对于本领域技术人员来说,可对包括本说明书的实施例的说明进行各种应用。因此,本发明的实施方式中所记载的任一实施例均是为了更好地说明本发明的例示,本发明的范围不限于这些实施例。
附图中所示的以下说明中的功能块均为可行的实施方式。在其他实施方式中,在不超出具体实施方式的思想及范围的范围内可使用其他功能块。另外,虽然将本发明的一个以上的功能块表示为独立块,但本发明的功能块中的一个以上的功能块可以是执行相同功能的各种硬件或软件结构的组合。
另外,包括某一构成要件的表述作为开放型的表述,单纯地指代该构成要件的存在,不应理解为排除追加性的构成要件。
进而,提到某一构成要件与其他构成要件连结或连接时,应理解为既可与其他构成要件直接连结或连接,也可在中间具备其他构成要件。
另外,‘第一、第二'这样的表述仅用于区分多个结构,对于结构之间的顺序或其他特征没有限定作用。
在提到某一部分与其他部分“连结”时,其不仅包括“直接连结”的情况,而且还包括中间隔着其他部件而“间接连结”的情况。另外,在提到某一部分“包括”某一构成要件时,在没有特别相反的记载的情况下,并不是排除其他构成要件,而是表示还可具备其他构成要件。
图1按照顺序而表示在正式地提供检索服务之前将构成检索对象的文献索引化的过程。即,在为了执行检索而由用户输入了特定关键词时,需要在判断是否包括上述关键词时要参照的数据,图1表示将这样的参照数据进行数据库化的过程。另外,在本具体实施方式中,将上述参照数据称为索引信息,关于索引信息,将在下面进行详细说明。
参照图1,文献索引方法最先从下载由索引装置要索引化的文献的步骤开始。此时,文献表示包括正文的所有种类的数据,例如包括文件形态的论文、文件形态的专利文献(公开文献,公报文献)、除此之外的包括正文的数据。另外,上述文献无需一定要存储在本发明的索引装置或检索装置所具备的内部存储库,也可以是通过网络而获得的存储在外部服务器的数据。
在下载要索引化的文献的情况下,索引装置以语节单位拆分上述文献内的正文而获得多个语节。此时,语节是指构成文章的最小成分,表示包括多个名词、代名词、动词、形容词、关系词、助词等各种词性的单词的单位。索引装置作为抽取文献内的语节的基准,可应用标点符号或由单词之间的空格产生的间隔的存在与否。即,在正文内存在由空格产生的间隔的情况下,本发明的索引装置能够以该间隔为基准划分前后语节,或在正文内具有句号的情况下,能够以该句号为基准划分前后语节。
例如,在存在“大韩民国在发展”这样的文章的情况下,索引装置以空格间隔为基准抽取‘大韩民国'、‘在’、‘发展’这样的三个语节。
在抽取语节之后,索引装置按照各个语节而获得单位音节及各个单位音节的位置(步骤c)。单位音节是指在语节内将音节捆绑为特定个数的情况,例如在将‘大韩民国’这样的一个语节分解为两个单位的单位音节的情况下,包括‘大韩
另外,在图1中的(步骤c)中,除了单位音节之外,还获得各个单位音节的位置。各个单位音节的位置是指,表示特定单位音节在一个语节内位于第几个顺序的信息。在上述的例示中,‘大韩’在‘大韩民国’的语节内位于第一个顺序,‘韩民’位于第 二个顺序,‘民国’位于第三个顺序,‘国在’位于第四个顺序。本发明的索引装置以匹配了各个单位音节及单位音节的位置的方式获得。
另外,在图1中的(步骤c)中,除了‘单位音节及各个单位音节的位置’之外,还获得‘尾音节及尾音节的位置’。例如,在‘大韩民国在’这样的语节内尾音节为‘在’,该尾音节在语节内位于第五个位置,索引装置如上述地将尾音节及该尾音节的位置匹配起来获得。
另外,上述单位音节及各个单位音节的位置、尾音节及尾音节位置如{大韩,#1}、{韩民,#2}、{民国,#3}、{国在,#4}、{在,#5}这样匹配各个单位音节或尾音节与位置信息的方式存储。
如上述,单位音节及各个单位音节的位置、尾音节及尾音节的位置分别按照各个语节而分别生成并存储在索引装置内的存储库(步骤d),而将这样存储的信息称为索引信息。即,索引信息表示从文献内的正文,按照各个语节,将单位音节、尾音节及它们的位置信息匹配起来存储的信息。另外,索引装置在索引化过程中对于重复的语节,对多个语节中的仅一个语节如上述地将单位音节、尾音节及位置信息匹配起来进行存储。
以上,参照图1而对本发明的索引装置从文献生成索引信息的过程,即将索引信息数据库化的过程进行了说明。
图2按照顺序而表示本发明的检索装置基于用户的输入的关键词而检索相关的文献的过程。
检索过程首先从由要检索的用户输入特定关键词的步骤(步骤a)开始。从通过网络而与检索装置连接的客户装置(用户的台式计算机、笔记本电脑、智能手机等)接收由用户输入的关键词,或者也可以接收由用户直接输入到设于上述检索装置的输入单元(键盘,鼠标等)的关键词。
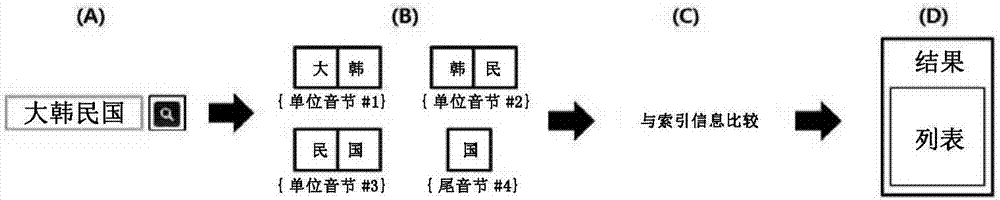
在接收关键词之后,检索装置将上述关键词拆分为特定个数的音节束而获得单位音节(步骤b)。即,上述检索装置以与索引装置从文献内的语节获得单位音节的方式相同的方式反而由用户关键词获得单位音节。例如,在用户输入的关键词为“大韩民国”时,在以两个音节为基准获得单位音节的情况下,检索装置获得‘大韩’、‘韩民’、‘民国’这三个单位音节。
另外,检索装置还获得各个上述单位音节的位置。即,对于‘大韩’获得#1,对 于‘韩民’获得#2,对于‘民国’获得#3,并与各个单位音节匹配起来进行存储。
进而,检索装置以与上述的索引装置的方式相同的方式来获得上述关键词的尾音节及尾音节的位置。即,检索装置获得作为关键词的尾音节的‘国’及该尾音节的位置#4,并将此匹配起来进行存储。
另外,在如上述地将单位音节、尾音节及各个位置匹配起来进行识别之后,检索装置将此与索引装置所存储的索引信息进行比较,从而判断该关键词是否包括在特定文献。以单位音节及单位音节的位置、尾音节及尾音节的位置准确地一致的程度的大小为基准进行与索引信息之间的比较。
即,对关键词的单位音节、尾音节及各个位置与索引信息内的各个语节的单位音节、尾音节及各个位置进行比较而计算一致率。
最后,检索装置将包括较多数量的与关键词的一致率高的语节的文献掌握为用户最终要检索的文献,并将此提供给用户。此时,上述文献以一致率为基准,以一致率高到低的顺序排列而提供多个。
下面,参照图3,对本发明的文献索引方法进行更加详细的说明。
图3表示索引装置对于构成检索对象的文献分别索引的方法的顺序图,具体表示其中的还考虑到从文献内的正文抽取的语节仅具备一个音节的情况的索引方法的顺序图。即,图4表示考虑到语节仅包括一个音节的情况即基于二元语法无法索引的情况的索引方法。本发明的索引装置按照图4的逻辑而索引文献。
图3的文献索引方法首先从下载文献,从各个文献内的正文获得语节的步骤(s310)开始。如在上述的图1中所说明,文献包括论文、专利文献等,将包括在该文献内的正文以空格间隔、标点符号等为基准进行拆分而抽取多个语节。特别是,在韩语、英语文献的情况下,以空格间隔为基准抽取语节。
接着,索引装置确认所抽取的语节是否由一个音节构成。(s320)在语节仅由一个音节构成的情况下,无法生成以两个以上的音节为基准形成的单位音节,在该情况下,需要以一个音节为基准生成索引信息。即,索引装置通过s320步骤而判断语节是否由一个音节构成,在由两个以上的音节构成的情况下,进入s330步骤,而在由一个音节构成的情况下,进入s340步骤。
首先,在语节由两个以上的音节构成的情况下所进行的s330步骤是如下的步骤:以与在图1所说明的方式相同的方式而获得以两个以上的音节为基准的单位音节,并 获得各个单位音节的位置。即,在从文献内的正文抽取“大韩民国”这一语节的情况下,获得{大韩,#1}、{韩民,#2}、{民国,#3}、{国在,#4}这样的在该语节内以两个音节为基准的单位音节及各个单位音节的位置。在s330步骤之后,索引装置获得该语节的尾音节及尾音节的位置。(s340)在上述实施例的情况下,获得{在,#5}。
另外,在语节仅由一个音节构成的情况下,直接进入s340步骤,此时该语节仅为一个音节,因此在s340步骤中获得既是始音节又是尾音节的一个音节及该音节的位置。例如,在从正文抽取的语节由“力”这样的一个音节的单词构成的情况下,索引装置从s320步骤直接进入s340步骤而获得{力,#1}这样的一个音节及该音节的位置。
这样,在经过s310步骤至s340步骤之后,索引装置将按照各个语节而获得的音节及音节的位置索引化而存储。(s350)即,在上述实施例中,对于“大韩民国”,将{大韩,#1}、{韩民,#2}、{民国,#3}、{国在,#4}、{在,#5}匹配起来进行存储,对于“力”,将{力,#1}匹配起来进行存储。另外,这样的索引信息按照各个文献而分别形成,之后在由用户输入或接收关键词的情况下,比较该关键词是否包括在该文献中
下面,参照图4,对检索装置的文献检索方法进行说明。
图4表示在由用户输入或接收关键词之后,检索装置将该关键词拆分而获得单位音节及尾音节,并获得关于各个音节的位置的过程及以所获得的单位音节、尾音节及位置为基础而与索引信息进行比较来检索想要查找的文献的过程。特别是,图4的文献检索方法在如图3的索引方法的理路上还考虑了关键词仅为一个音节的情况。
图4的文献检索方法首先从由用户输入或接收特定关键词的步骤开始。(s410)如上述的图2所说明,当用户通过客户装置而在网络上输入关键词时,检索装置接收该关键词而作为文献检索的基础,或者在用户通过与检索装置直接连接的输入单元输入了关键词的情况下,检索装置接收上述输入而作为文献检索的基础。
接着,检索装置判断上述关键词是否由一个音节构成。(s420)在关键词仅由一个音节构成的情况下,无法抽取以两个以上的音节为基准生成的单位音节,因此,在该情况下,需要单独执行仅以一个音节为基准的检索。即,检索装置通过s420步骤而判断关键词是否由一个音节构成,然后在关键词由两个以上的音节构成的情况下,进入s430步骤,在由一个音节构成的情况下,进入s440步骤。
首先,在关键词由两个以上的音节构成的情况下进行的s430步骤中,以与在图2中说明的方式相同的方式,获得以两个以上的音节为基准的单位音节,并获得各个单位音节的位置。即,在从用户接收的关键词为“大韩民国”的情况下,获得{大韩,#1}、{韩民,#2}、{民国,#3}这样的在该关键词内以两个音节为基准的单位音节及各个单位音节的位置。另外,在s430步骤之后,检索装置获得该关键词的尾音节及尾音节的位置。(s440)在上述实施例的情况下,获得{国,#4}。另外,将这样的对每个关键词生成的单位音节、尾音节及该音节的位置信息统称为检索信息。即,关于“大韩民国”这一关键词,检索装置生成{大韩,#1}、{韩民,#2}、{民国,#3}、{国,#4}这样的检索信息。(s450)
另外,在关键词仅由一个音节构成的情况下,直接进入s445步骤。在由一个音节构成的关键词的情况下,代替单位音节基准的检索信息而生成在上述音节的右侧追加分隔符而形成的检索信息。例如,在关键词为“力”的情况下,检索装置如‘力*’这样,将分隔符(*)追加到该关键词而生成检索信息。这样,在一音节关键词追加分隔符而生成检索信息的情况下,与仅能够抽取二音节以上的单位音节的以往方式不同地,还能够检索到仅由一音节构成的关键词,从而具备提高用户方便度的效果。
另外,检索装置在从关键词获得音节及位置而生成检索信息之后,将该检索信息与索引装置内的索引信息比较,从而判断上述用户输入的关键词是否包括在特定文献内。
此时,以关键词的检索信息即关键词的各个单位音节及各个单位音节的位置、尾音节及尾音节的位置与和上述文献匹配的索引信息一致的程度的大小为基准判断上述关键词是否包括在该文献。例如,关于用户输入的“大韩民国”的关键词,判断为与之前说明的“大韩民国在”这一语节的索引信息的类似度高,从而认为在该文献中包括关键词。另外,此时,表示该关键词是否在特定文献内包括的基准由逻辑的研发者来任意设定。在根据这种方式的本发明的情况下,能够同时参照单位音节和单位音节的位置而确认关键词是否包括在文献内,从而能够提高检索的准确度,另外,无需将文献内的整个正文与上述检索信息进行比较,而是仅与所存储的索引信息进行比较即可,因此还可提高检索的速度。
另外,由用户输入的“力”这一关键词以追加了分隔符的“力*”为基础与索引信息比较类似度,判断为与在首音节中包括“力”的所有语节具有类似性。这样,本 发明的检索装置对于一音节关键词也能够提供检索结果。
另外,在s450步骤中进行检索信息与索引信息之间的比较之后,检索装置根据所计算的类似度的大小而向用户提供特定的一个以上的文献。例如,按照类似性从高到低的顺序排列文献而提供给用户。(s460)
以上,参照图1至图4而对本发明的文献索引方法及文献检索方法进行了说明。
图5及图6分别是表示索引装置及检索装置的具体结构的框图。
首先,图5表示索引装置的具体结构,如图所示,索引装置包括:文献下载部(510)、语节分析部(520)、索引信息生成部(530)、存储部(540)及索引装置控制部(550)。
文献下载部(510)是加载存储于外部服务器的文献或已存储在索引装置的存储部(540)内的文献的功能部。
语节分析部(520)是从上述加载的文献内的正文抽取一个以上的语节的功能部。此时,语节分析部(520)以包括在正文内的空格间隔或标点符号为基准抽取语节。
索引信息生成部(530)是从上述抽取的语节分别掌握单位音节、各个单位音节的位置、尾音节、尾音节的位置,并按照各个语节而将它们匹配起来的功能部。在上述的图1及图3中详细说明了通过该过程而生成索引信息的情况,因此可进行参照。
接着,存储部(540)是存储文献或存储由索引装置生成的索引信息的结构。存储部(540)包括以电子方式实现数据的记录的所有单元。
接着,索引装置控制部(550)是对上述说明的文献下载部(510)、语节分析部(520)、索引信息生成部(530)、存储部(540)进行整体控制的结构。
图6表示检索装置的具体结构。如图所示,检索装置包括:关键词接收部(610),检索信息生成部(620),检索执行部(630)及检索装置控制部(650)。
关键词接收部(610)接收根据用户输入的关键词。此时,关键词可以是从在网络上连接的外部客户装置接收的关键词,或可以是通过直接设于该检索装置的输入单元(键盘,鼠标)输入的关键词。
检索信息生成部(620)是对于上述接收的关键词掌握单位音节、各个单位音节的位置、尾音节、尾音节的位置而生成检索信息的功能部。在上述的图2及图4中详细说明了生成检索信息的过程,因此可进行参照。
接着,检索执行部(630)是参照上述索引装置所生成的索引信息而检索包括上述 关键词的文献的功能部。此时,如上所述,通过判断检索信息与索引信息的类似度来进行检索。
检索装置控制部(650)是对上述说明的关键词接收部(610)、检索信息生成部(620)及检索执行部(630)进行整体控制的结构。
以上,参照附图,对本发明的基于多字节编码的文献检索方法进行了说明。
本领域技术人员应该理解本发明在不变更其技术思想或必要特征的情况下,可以其他具体形态实施,以上说明的实施例在所有方面上均为例示,本发明不限于此。另外,本发明的范围相比于上述具体实施方式,更根据后述的权利要求书来定义,并且从权利要求书的意思及范围以及其等价概念导出的所有变更或变形的形态均包括在本发明的范围内。
- 还没有人留言评论。精彩留言会获得点赞!