基于CPU和GPU的数据库防火墙系统和其的控制方法与流程
本发明涉及互联网技术领域,尤其涉及一种基于cpu和gpu的数据库防火墙系统和基于cpu和gpu的数据库防火墙系统的控制方法。
背景技术:
随着互联网技术和信息技术的迅速发展,以数据库为基础的信息系统在经济、金融、军工、医疗等领域的信息基础设施建设中得到了广泛的应用,越来越多的数据信息被不同组织和机构搜集、存储以及发布,其中大量信息被用于行业合作和数据共享,因此数据库防火墙的应用越来越广泛,越来越重要,同时,随着千兆、万兆的网络在国内的大规模应用,那么用户对数据库防火墙的吞吐量的要求越来越高。
技术实现要素:
本发明的目的旨在至少解决上述技术缺陷之一,提供一种基于cpu和gpu的数据库防火墙系统和基于cpu和gpu的数据库防火墙系统的控制方法。
本发明提供一种基于cpu和gpu的数据库防火墙系统,所述系统包括:至少一个多核cpu包括cpu调度核组,cpu计算核组和cpu常规任务核组;
至少一个gpu包括gpu会话组、gpu运算组和gpu集群通信接口;
网卡与所述gpu连接,包括网卡缓存区;
系统内存分别与所述多核cpu和gpu连接,包括gpu专享内存池、cpu内存池、网卡内存池、gpu与cpu的共享内存池以及通过所述网卡内存池和gpu专享内存池进行虚拟映射形成的nic与gpu的共享内存池,其中,所述网卡内存池和网卡缓存区具有相同的物理地址;
其中,所述cpu调度核组用于根据cpu调度核组中的核数量进行网卡缓存区的对应划分。
从上述数据库防火墙系统的方案可以看出,通过gpu去并行处理数据库防火墙中所有的运算任务,从而满足大数据环境以及云计算环境中对高吞吐量安全的需求。而且采用嵌入式gpu防火墙硬件设计架构,实现大数据环境以及云计算环境中高性能、低能耗、低成本。
本发明还提供一种基于cpu和gpu的数据库防火墙系统的控制方法,所述控制方法包括以下步骤:
系统初始化;
根据cpu数量以及核数量将至少一个多核cpu划分为cpu调度核组、cpu计算核组和cpu常规任务核组;
根据gpu数量将至少一个gpu划分为gpu会话组和gpu运算组;
将系统内存划分为gpu专享内存池、cpu内存池、网卡内存池和gpu与cpu的共享内存池,其中,所述网卡内存池和网卡缓存区具有相同的物理地址;
将所述网卡内存池和gpu专享内存池进行虚拟映射,形成nic与gpu的共享内存池;
根据cpu调度核组中的核数量进行网卡缓存区的对应划分;以及
对gpu集群通信接口进行初始化。
从上述控制方法的方案可以看出,通过gpu去并行处理数据库防火墙中所有的运算任务,从而满足大数据环境以及云计算环境中对高吞吐量安全的需求。而且采用嵌入式gpu防火墙硬件设计架构,实现大数据环境以及云计算环境中高性能、低能耗、低成本。
附图说明
图1为本发明的基于cpu和gpu的数据库防火墙系统一种实施例的结构示意图;
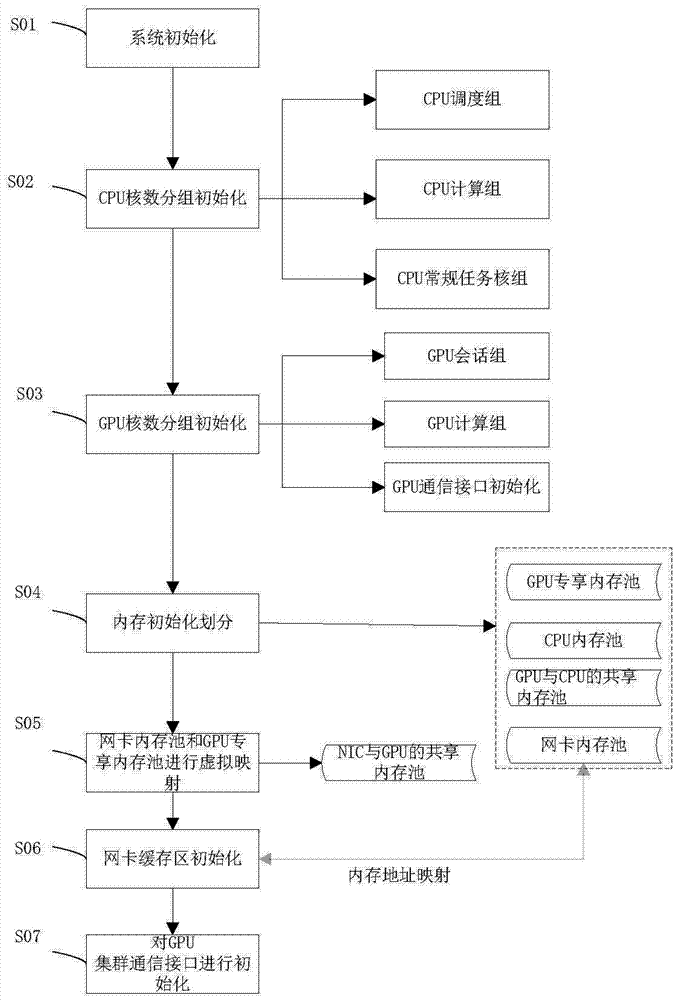
图2为本发明的基于cpu和gpu的数据库防火墙系统的控制方法中初始方法的一种实施例的流程图;
图3为本发明的基于cpu和gpu的数据库防火墙系统的控制方法中对网络数据包的处理方法的一种实施例的流程图;
图4为本发明的基于cpu和gpu的数据库防火墙系统的控制方法中对网络数据包的处理方法的另一种实施例的流程图;
图5为本发明的基于cpu和gpu的数据库防火墙系统的控制方法中的动态任务调度算法一种实施例的流程图。
具体实施方式
为了使本发明所解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明提供一种实施例的基于cpu和gpu的数据库防火墙系统,如图1所示,所述系统包括:
至少一个多核cpu1包括cpu调度核组,cpu计算核组和cpu常规任务核组;
至少一个gpu2包括gpu会话组、gpu运算组和gpu集群通信接口;
网卡3即nic与所述gpu2连接,包括网卡缓存区;
系统内存4分别与所述多核cpu1和gpu2连接,包括gpu专享内存池、cpu内存池、网卡内存池、gpu与cpu的共享内存池以及通过所述网卡内存池和gpu专享内存池进行虚拟映射形成的nic与gpu的共享内存池,其中,所述网卡内存池和网卡缓存区即nic缓冲区具有相同的物理地址;
其中,所述cpu调度核组用于根据cpu调度核组中的核数量进行网卡缓存区的对应划分。也就是说,多核多cpu、多gpu、高速网卡、以及系统内存构成一种高吞吐量的基于cpu和gpu的数据库防火墙系统,另外将传统cpu集群上的大型防火墙并行应用移植到gpu集群上,显著减少空间、能耗等硬件资源需求,而且通过过cpu、gpu的混合调度充分利用cpu和gpu,在gpu计算复杂任务的同时让cpu做一些较为简单的调度和计算,充分发挥多cpu的调度优势与多gpu的计算优势减少网络延迟。
在具体实施中,所述cpu常规任务核组可以包括如下功能:设备配置,集中管理,审计管理以及安全策略配置等。
在具体实施中,如图1所示,网卡3与gpu2之间实现高速内存交换机制,即实现gpu与nic之间的内存(专属内存)交换以及gpu与系统内存(专属内存)的交换,把处于等待状态(或在cpu调度原则下被剥夺运行权利)的gpu的映射内存空间腾出来,同时赋予忙碌状态的gpu或nic采用内存管理,优化算法所消耗的内存空间,内存大小是有限的,而数据流是不断产生,充分利用有限的内存一次性处理更多的数据,以达到数据流的实时处理。
在具体实施中,当网络数据包进入网卡缓存区时,所述cpu调度核组还用于:调度gpu会话组,以及根据动态任务调度算法将所述gpu会话组分别与网卡缓存区中的网络数据包和任务处理进行匹配;
所述gpu会话组,用于进行全局初始化,并对与其对应匹配的网络数据包进行对应的任务处理,以及得到会话流和将会话流标志位存入所述系统内存中。
也就是说,cpu调度核组采用动态任务调度算法,将调度的gpu会话组与nic缓冲区进行一一对应匹配计算,可以减小系统负载不均,提高硬件资源并行计算能力,使得所有计算资源尽可能在同一时间完成执行。
在具体实施中,gpu会话组进行的任务处理包括:
对网络数据包进行会话管理;
对网络数据包进行l2层解析;
对网络数据包进行tcp/ip协议的解析;
对网络数据包进行时域会话的hash计算对时域会话的数据包进行tcp流重组;以及对时域会话的数据包进行数据库类型识别。
也就是说,gpu会话组采用基于gpu的数据流通用处理模型,该通用模型适合于各个应用领域的多条高维时间序列数据流,它涵盖了数据流的预处理、减负、概要抽取和挖掘处理等多项功能,能完成数据流处理时的多项任务,如查询处理、聚类、分类、频繁项集挖掘等。任务包括但不限于:gpu会话组针对单一数据包进行checksumandcrc;gpu会话组针对单一数据包进行l2解析;gpu会话组针对单一数据包进行tcp协议的解析;gpu会话组针对单一数据包进行session会话的hash计算;gpu会话组针对session会话的数据包进行tcp流的重组;gpu会话组针对session会话进行数据库类型的识别。即将gpu会话组划分为多个会话小组,比如,第一会话小组的任务处理为:对网络数据包进行会话管理,第二会话小组的任务处理为:对网络数据包进行l2层解析,那么第一会话小组从匹配的网卡缓存区中得到对应的网络数据,并对所述对应的网络数据进行会话管理,而第二会话小组从匹配的网卡缓存区中得到对应的网络数据,并对所述对应的网络数据进行l2层解析。
在具体实施中,当网络数据包进入网卡缓存区时,所述cpu调度核组还用于:调度gpu计算组,以及根据动态任务调度算法将所述gpu运算组分别与网卡缓存区中的网络数据包和任务处理进行匹配;
所述gpu运算组,用于进行全局初始化,对所述网络数据包进行优化处理,并对匹配且优化后的网络数据包进行任务处理。
在具体实施中,cpu调度核组采用联合专用线程调度策略,调度gpu运算组进行不同会话的相关运算。
在具体实施中,gpu会话组进行的任务处理包括:
对会话管理组进行数据迭代运算;
对会话管理组进行数据库协议解析
对会话管理组进行sql语法分析;
对会话管理组进行安全策略分析;
对网络数据包进行安全策略自学习;
对网络数据包进行安全策略关联分析;以及对网络数据包进行阻断与放行。
也就是说,gpu运算组基于多层归约的mapreduce实现方案,主要从线程的执行方式,共享内存缓存策略和输入数据读取3个方面进行优化,采用多层归约机制在map计算结束后直接进行归约计算,以减少中间数据的存储开销。多层归约机制使块内部的并发线程可以同时分别在共享内存和全局内存上高效的执行归约计算,避免了由于频繁的共享内存数据换出带来的线程同步开销,提高了线程并发执行的效率,包括但不限于以下的运算:gpu运算组针对会话管理组的数据进行数据迭代运算;gpu运算组针对会话管理组进行数据库协议解析;gpu运算组针对会话管理组进行sql语法分析;gpu运算组针对会话管理组进行安全策略分析;gpu运算组进行安全策略自学习;gpu运算组进行安全策略关联分析;gpu运算组进行数据包的阻断与放行。即将gpu运算组划分为多个运算小组,比如,第一运算小组的任务处理为:对会话管理组进行数据迭代运算,第二运算小组的任务处理为:对会话管理组进行数据库协议解析,那么第一会话小组从匹配的网卡缓存区中得到对应的网络数据,并对会话管理组进行数据迭代运算,而第二会话小组从匹配的网卡缓存区中得到对应的网络数据,并对会话管理组进行数据库协议解析。
从上述数据库防火墙系统的方案可以看出,通过gpu去并行处理数据库防火墙中所有的运算任务,从而满足大数据环境以及云计算环境中对高吞吐量安全的需求。而且采用嵌入式gpu防火墙硬件设计架构,实现大数据环境以及云计算环境中高性能、低能耗、低成本。进一步通过提供板间数据传输重叠化机制、片上内存虚拟地址管理、以及软硬件任务并执行调度算法等优化策略,能够对大数据应用取得可观的性能功耗优势。基于gpu的异构计算系统及并行计算模式使得大量传统串行算法转移到并行计算平台上的并行化实现成为可能,无论是从高性能计算的成本控制、精度要求还是并行计算在硬件设备和应用服务之间的关键作用来说,基于gpu的高性能并行优化算法具有应用价值。另外,云安全是大数据时代信息安全的体现,它融合了并行处理、网格计算、未知病毒行为判断等新兴技术和概念,高吞吐量的数据库防火墙能够有效地提高数据库系统环境的安全,为云机算环境的推广与普及提供安全保障和技术支撑。
在具体实施中,本发明还提供一种实施例的基于cpu和gpu的数据库防火墙系统的控制方法,如图2所示,所述控制方法包括以下步骤:
步骤s01,系统初始化;
步骤s02,根据cpu数量以及核数量将至少一个多核cpu划分为cpu调度核组、cpu计算核组和cpu常规任务核组;
步骤s03,根据gpu数量将至少一个gpu划分为gpu会话组和gpu运算组;
步骤s04,将系统内存划分为gpu专享内存池、cpu内存池、网卡内存池和gpu与cpu的共享内存池,其中,所述网卡内存池和网卡缓存区具有相同的物理地址;
步骤s05,将所述网卡内存池和gpu专享内存池进行虚拟映射,形成nic与gpu的共享内存池;
步骤s06,根据cpu调度核组中的核数量进行网卡缓存区的对应划分,以及网卡缓存区与网卡内存池进行虚拟映射使得所述网卡内存池和网卡缓存区具有相同的物理地址即进行网卡缓存区初始化;
步骤s07,对gpu集群通信接口进行初始化。
也就是说,将传统cpu集群上的大型防火墙并行应用移植到gpu集群上,显著减少空间、能耗等硬件资源需求,而且通过过cpu、gpu的混合调度充分利用cpu和gpu,在gpu计算复杂任务的同时让cpu做一些较为简单的调度和计算,充分发挥多cpu的调度优势与多gpu的计算优势减少网络延迟。
在具体实施中,如图3所示,对网络数据包的处理方法,在步骤s07之后还包括以下步骤:
步骤s31,当网络数据包进入网卡缓存区时,cpu调度核组调度gpu会话组;
步骤s32,gpu会话组从系统内存映射中获取数据包的物理地址;
步骤s33,gpu会话组进行全局初始化;
步骤s34,cpu调度核组根据动态任务调度算法将所述gpu会话组分别与网卡缓存区中的网络数据包和任务处理进行匹配;
步骤s35,gpu会话组与其对应匹配的网络数据包进行对应的任务处理,得到会话流并将会话流标志位存入所述系统内存中。
也就是说,cpu调度核组采用动态任务调度算法,将调度的gpu会话组与nic缓冲区进行一一对应匹配计算,可以减小系统负载不均,提高硬件资源并行计算能力,使得所有计算资源尽可能在同一时间完成执行。
在具体实施中,gpu会话组进行的任务处理包括:
对网络数据包进行会话管理;
对网络数据包进行l2层解析;
对网络数据包进行tcp/ip协议的解析;
对网络数据包进行时域会话的hash计算
对时域会话的数据包进行tcp流重组;以及对时域会话的数据包进行数据库类型识别。
也就是说,gpu会话组采用基于gpu的数据流通用处理模型,该通用模型适合于各个应用领域的多条高维时间序列数据流,它涵盖了数据流的预处理、减负、概要抽取和挖掘处理等多项功能,能完成数据流处理时的多项任务,如查询处理、聚类、分类、频繁项集挖掘等。任务包括但不限于:gpu会话组针对单一数据包进行checksumandcrc;gpu会话组针对单一数据包进行l2解析;gpu会话组针对单一数据包进行tcp协议的解析;gpu会话组针对单一数据包进行session会话的hash计算;gpu会话组针对session会话的数据包进行tcp流的重组;gpu会话组针对session会话进行数据库类型的识别。即将gpu会话组划分为多个会话小组,比如,第一会话小组的任务处理为:对网络数据包进行会话管理,第二会话小组的任务处理为:对网络数据包进行l2层解析,那么第一会话小组从匹配的网卡缓存区中得到对应的网络数据,并对所述对应的网络数据进行会话管理,而第二会话小组从匹配的网卡缓存区中得到对应的网络数据,并对所述对应的网络数据进行l2层解析。
在具体实施中,如图4所示,对网络数据包的处理方法,在步骤s07或步骤s35之后还包括以下步骤:
s41,当网络数据包进入网卡缓存区时,cpu调度核组调度gpu运算组;
s42,gpu运算组从系统内存映射中获取数据包的物理地址;
s43,gpu运算组进行全局初始化;
s44,gpu运算组对所述网络数据包进行优化处理;
s45,cpu调度核组根据动态任务调度算法将所述gpu运算组分别与网卡缓存区中的网络数据包和任务处理进行匹配;
s46,gpu运算组与其对应匹配的网络数据包进行对应的任务处理。
在具体实施中,cpu调度核组采用联合专用线程调度策略,调度gpu运算组进行不同会话的相关运算。
在具体实施中,gpu会话组进行的任务处理包括:
对会话管理组进行数据迭代运算;
对会话管理组进行数据库协议解析
对会话管理组进行sql语法分析;
对会话管理组进行安全策略分析;
对网络数据包进行安全策略自学习;
对网络数据包进行安全策略关联分析;以及对网络数据包进行阻断与放行。
在具体实施中,所述gpu运算组对所述网络数据包进行优化处理的步骤,具体包括:
数据加载;
数据分割;以及统计中间键值对应的归约频率也就是说,gpu运算组基于多层归约的mapreduce实现方案,主要从线程的执行方式,共享内存缓存策略和输入数据读取3个方面进行优化,采用多层归约机制在map计算结束后直接进行归约计算,以减少中间数据的存储开销。多层归约机制使块内部的并发线程可以同时分别在共享内存和全局内存上高效的执行归约计算,避免了由于频繁的共享内存数据换出带来的线程同步开销,提高了线程并发执行的效率,包括但不限于以下的运算:gpu运算组针对会话管理组的数据进行数据迭代运算;gpu运算组针对会话管理组进行数据库协议解析;gpu运算组针对会话管理组进行sql语法分析;gpu运算组针对会话管理组进行安全策略分析;gpu运算组进行安全策略自学习;gpu运算组进行安全策略关联分析;gpu运算组进行数据包的阻断与放行。即将gpu运算组划分为多个运算小组,比如,第一运算小组的任务处理为:对会话管理组进行数据迭代运算,第二运算小组的任务处理为:对会话管理组进行数据库协议解析,那么第一会话小组从匹配的网卡缓存区中得到对应的网络数据,并对会话管理组进行数据迭代运算,而第二会话小组从匹配的网卡缓存区中得到对应的网络数据,并对会话管理组进行数据库协议解析。
在具体实施中,如图5所示,所述动态任务调度算法具体包括以下步骤:
步骤s51,判断是否第一次运行,如果是,进入步骤s52,如果否,进入步骤s55;
步骤s52,任务随机分配;
步骤s53,计算每个gpu的负载量;
步骤s54,计算每个gpu的计算速率,返回步骤s51;
步骤s55,预处理;
步骤s56,更新每个gpu的负载量;
步骤s57,更新每个gpu的计算速率;
步骤s58,减负;
步骤s59,概要抽取;
步骤s510,对两次负载和两次计算速率的差值进行加权;
步骤s511,判断加权的差值是否达到稳定速率或负载量的20%,如果是,进入步骤s512,如果否,返回步骤s55;
步骤s512,任务执行。
在步骤s512中,对于gpu会话组则执行与gpu会话组对应的任务,对于gpu运算组则执行与gpu运算组对应的任务。
在具体实施中,实现单次扫描算法,不允许任何可以暂时阻塞数据流的操作,所有的数据只能扫描一次。
从上述控制方法的方案可以看出,通过gpu去并行处理数据库防火墙中所有的运算任务,从而满足大数据环境以及云计算环境中对高吞吐量安全的需求。而且采用嵌入式gpu防火墙硬件设计架构,实现大数据环境以及云计算环境中高性能、低能耗、低成本。进一步通过提供板间数据传输重叠化机制、片上内存虚拟地址管理、以及软硬件任务并执行调度算法等优化策略,能够对大数据应用取得可观的性能功耗优势。基于gpu的异构计算系统及并行计算模式使得大量传统串行算法转移到并行计算平台上的并行化实现成为可能,无论是从高性能计算的成本控制、精度要求还是并行计算在硬件设备和应用服务之间的关键作用来说,基于gpu的高性能并行优化算法具有应用价值。另外,云安全是大数据时代信息安全的体现,它融合了并行处理、网格计算、未知病毒行为判断等新兴技术和概念,高吞吐量的数据库防火墙能够有效地提高数据库系统环境的安全,为云机算环境的推广与普及提供安全保障和技术支撑。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!