结构化数据生成方法及装置与流程
本申请涉及数据处理技术领域,尤其涉及一种结构化数据生成方法及装置。
背景技术:
随着信息化的发展,电子文档的类型和数量越来越多,目前常用的电子文档的类型有doc、pdf、超文本标记语言(hypertextmark-uplanguage,html)等等,由于电子文档的类型非常丰富,用户可以根据各自的喜好选择电子文档的类型来生成电子文档,例如,在有大量服装加工厂的验厂报告中,不同的验厂机构会采用不同类型的电子文档来描述被验工厂的信息。
有时,用户需要将海量的电子文档进行对比,提取出符合设定匹配规则的结构化数据,例如,从大量服装加工厂的验厂报告中提取出符合设定匹配规则的结构化数据,以便从中快速筛选出符合条件的工厂,虽然海量的验厂报告均描述服装加工厂的情况,但由于验厂报告的类型不同,目前只能依靠人工来浏览每个验厂报告,从中获取符合设定匹配规则的数据,再录入表格中生成结构化数据。
上述通过人工生成结构化数据的方式,生成效率低下,且容易出现人为错误,准确性较差。
技术实现要素:
本申请实施例提供一种结构化数据生成方法及装置,用以解决相关结构化数据生成方式中存在的生成效率低下,且容易出现人为错误,准确性较差的问题。
根据本申请实施例,提供一种结构化数据生成方法,包括:
获取待解析电子文档的文本模式;
从所述待解析电子文档的文本模式中提取符合设定匹配规则的数据;
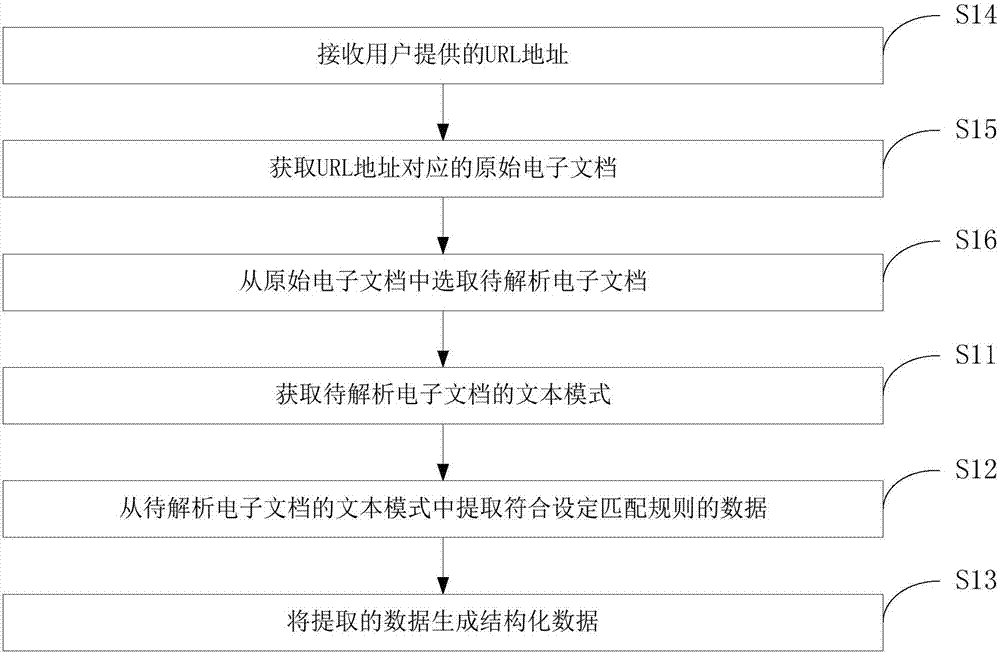
将提取的数据生成结构化数据。
可选的,还包括:
接收用户提供的统一资源定位符url地址;
获取所述url地址对应的原始电子文档;
从所述原始电子文档中选取待解析电子文档。
具体的,从所述原始电子文档中选取待解析电子文档,具体包括:
确定与所述原始电子文档的后缀文件名对应的验证工具,得到所述原始电子文档的验证工具;
使用所述原始电子文档的验证工具验证所述原始电子文档;
获取通过验证的原始电子文档,得到待解析电子文档。
可选的,还包括:
在所述待解析电子文档中添加第一设定标识。
具体的,获取待解析电子文档的文本模式,具体包括:
确定与所述待解析电子文档的后缀文件名对应的提取工具,得到所述待解析电子文档的提取工具;
使用所述待解析电子文档的提取工具提取所述待解析电子文档中的文字部分;
获取所述待解析电子文档中的文字部分,得到所述待解析电子文档的文本模式。
具体的,从所述待解析电子文档的文本模式中提取符合设定匹配规则的数据,具体包括:
将所述待解析电子文档的文本模式逐词匹配所述设定匹配规则;
获取所述待解析电子文档的文本模式中与所述设定匹配规则匹配的词,得到符合所述设定匹配规则的数据。
可选的,还包括:
在完成与所述设定匹配规则匹配的待解析电子文档中添加第二设定标识。
具体的,将提取的数据生成结构化数据,具体包括:
以表格的形式在页面中展示提取的数据。
根据本申请实施例,还提供一种结构化数据生成装置,包括:
第一获取模块,用于获取待解析电子文档的文本模式;
提取模块,用于从所述待解析电子文档的文本模式中提取符合设定匹配规则的数据;
生成模块,用于将提取的数据生成结构化数据。
可选的,还包括:
接收模块,用于接收用户提供的统一资源定位符url地址;
第二获取模块,用于获取所述url地址对应的原始电子文档;
选取模块,用于从所述原始电子文档中选取待解析电子文档。
具体的,所述选取模块,用于从所述原始电子文档中选取待解析电子文档,具体用于:
确定与所述原始电子文档的后缀文件名对应的验证工具,得到所述原始电子文档的验证工具;
使用所述原始电子文档的验证工具验证所述原始电子文档;
获取通过验证的原始电子文档,得到待解析电子文档。
可选的,还包括:
第一添加模块,用于在所述待解析电子文档中添加第一设定标识。
具体的,所述第一获取模块,用于获取待解析电子文档的文本模式,具体用于:
确定与所述待解析电子文档的后缀文件名对应的提取工具,得到所述待解析电子文档的提取工具;
使用所述待解析电子文档的提取工具提取所述待解析电子文档中的文字部分;
获取所述待解析电子文档中的文字部分,得到所述待解析电子文档的文本模式。
具体的,所述提取模块,用于从所述待解析电子文档的文本模式中提取符合设定匹配规则的数据,具体用于:
将所述待解析电子文档的文本模式逐词匹配所述设定匹配规则;
获取所述待解析电子文档的文本模式中与所述设定匹配规则匹配的词,得到符合所述设定匹配规则的数据。
可选的,还包括:
第二添加模块,用于在完成与所述设定匹配规则匹配的待解析电子文档中添加第二设定标识。
具体的,所述生成模块,用于将提取的数据生成结构化数据,具体用于:
以表格的形式在页面中展示提取的数据。
本申请实施例提供一种结构化数据生成方法及装置,获取待解析电子文档的文本模式;从所述待解析电子文档的文本模式中提取符合设定匹配规则的数据;将提取的数据生成结 构化数据。该方案中,通过获取待解析电子文档的文本模式,从待解析电子文档的文本模式中提取符合设定匹配规则的数据,然后将提取的数据生成结构化数据,从而实现自动生成结构化数据,相对于相关技术中采用人工生成结构化数据的方式,生成效率很高,能够有效避免人为错误,准确性较好,即使待解析电子文档是海量的不同格式的电子文档,也能快速、准确地生成结构化数据。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1为本申请实施例中一种结构化数据生成方法的流程图;
图2为本申请实施例中另一种结构化数据生成方法的流程图;
图3为本申请实施例中结构化数据的展示结果示意图;
图4为本申请实施例中一种结构化数据生成装置的结构示意图。
具体实施方式
为了使本申请所要解决的技术问题、技术方案及有益效果更加清楚、明白,以下结合附图和实施例,对本申请进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
为了解决相关结构化数据生成方式中存在的生成效率低下,且容易出现人为错误,准确性较差的问题,本申请实施例提供一种结构化数据生成方法,该方法可以但不限于应用在服务中,该方法的流程如图1所示,包括如下步骤:
s11:获取待解析电子文档的文本模式。
通常,一个待解析电子文档中会包括文字、图片、表格等等多种类型的数据,在生成结构化数据时,需要的是待解析电子文档的文字部分,因此,需要获取待解析电子文档的文本模式。待解析电子文档的数量可以是少量的,也可以是海量的。
s12:从待解析电子文档的文本模式中提取符合设定匹配规则的数据。
在生成结构化数据时,通常会预先设置设定匹配规则,相关技术中是采用人工方式从待解析电子文档中提取与设定匹配规则匹配的数据,而在本申请实施例中,可以自动实现从待解析电子文档的文本模式中提取符合设定匹配规则的数据。
s13:将提取的数据生成结构化数据。
s12中提取的数据是生成结构化数据所需要的数据,因此,直接将s12中提取的数据生成结构化数据即可。
一种可选的方式,s11-s13中的结构化数据生成方法可以采用java编程技术编写程序,利用跨平台的java虚拟机,通过在java虚拟机上运行该程序,批量获取不同格式、不同内容的海量待解析电子文档对应的结构化数据。
该方案中,通过获取待解析电子文档的文本模式,从待解析电子文档的文本模式中提取符合设定匹配规则的数据,然后将提取的数据生成结构化数据,从而实现自动生成结构化数据,相对于相关技术中采用人工生成结构化数据的方式,生成效率很高,能够有效避免人为错误,准确性较好,即使待解析电子文档是海量的不同格式的电子文档,也能快速、准确地生成结构化数据。
根据本申请实施例提供另一种结构化数据生成方法,该方法的流程如图2所示,在如图1所示的方法的基础上还包括:
s14:接收用户提供的统一资源定位符(universalresourcelocator,url)地址。
有时,用户会将电子文档保存在网上,这时用户只需要提供一个url地址即可,服务器可以通过该url地址获取到需要的电子文档,这样不仅可以简化用户的操作,并且可以反复提取电子文档。
s15:获取url地址对应的原始电子文档。
用户提供的url地址对应的电子文档并不一定都是合格的待解析电子文档,获取到的电子文档可以定义为原始电子文档。
s16:从原始电子文档中选取待解析电子文档。
原始电子文档中可能存在各种问题,例如,有的格式不正确,有的文件不完整,存在问题的原始电子文档是无法参与生成结构化数据的,因此需要提前过滤掉存在问题的电子文档,剩下的才是可以参与生成结构化数据的待解析电子文档。
具体的,上述s16中从原始电子文档中选取待解析电子文档的实现方式,具体包括:确定与原始电子文档的后缀文件名对应的验证工具,得到原始电子文档的验证工具;使用原始电子文档的验证工具验证原始电子文档;获取通过验证的原始电子文档,得到待解析电子文档。
不同类型的原始电子文档可以采用不同的验证工具,使用相应的验证工具验证原始电子文档的完整性和正确性,通过验证的原始电子文档,即为待解析电子文档。
一种优选的方式,为了避免重复对原始电子文档进行验证,可以在待解析电子文档中添加第一设定标识。第一设定标识可以根据实际需要进行设定。
具体的,上述s11中获取待解析电子文档的文本模式的实现过程,具体包括:确定与待解析电子文档的后缀文件名对应的提取工具,得到待解析电子文档的提取工具;使用待解析电子文档的提取工具提取待解析电子文档中的文字部分;获取待解析电子文档中的文字部分,得到待解析电子文档的文本模式。
不同类型的待解析电子文档可以采用不同的提取工具,待解析电子文档的不同类型可以通过其后缀文件名来区分,例如,后缀文件名为“.doc”的待解析电子文档,可以使用的提取工具为poi组件,后缀文件名为“.pdf”的待解析电子文档,可以使用的提取工具为itext组件。使用相应的提取工具提取待解析电子文档中的文字部分,从而得到待解析电子文档的文本模式。
具体的,上述s12中从待解析电子文档的文本模式中提取符合设定匹配规则的数据的实现过程,具体包括:将待解析电子文档的文本模式逐词匹配设定匹配规则;获取待解析电子文档的文本模式中与设定匹配规则匹配的词,得到符合设定匹配规则的数据。
通过提供待解析电子文档的设定匹配规则,用该设定匹配规则与待解析电子文档逐词进行匹配,若有匹配的词,则可以得到符合设定匹配规则的数据,直至完成所有待解析电子文档的解析。
一种可选的方式,为了避免重复将待解析电子文档与设定匹配规则进行匹配,可以在完成与设定匹配规则匹配的待解析电子文档中添加第二设定标识。第二设定标识可以根据实际需要进行设定。
具体的,上述s13中将提取的数据生成结构化数据的实现过程,具体包括:以表格的形式在页面中展示提取的数据。从而便于用户进行比对,筛选。
下面以一个具体实例说明上述结构化数据生成方法,该方法的应用场景是得到海量验厂报告的结构化数据。假设,在有大量服装加工厂的验厂报告电子文档中,由于不同的验厂机构会采用不同的电子文档格式,有doc文件、pdf文件、html文件等,并且还采用不同的描述方法来描述被验工厂的信息,这时就会迫切需要从各个验厂机构提供的验厂报告电子文档中提取出能对比的数据,以便快速的筛选出其中符合条件的工厂。
首先,用户将各自的验厂报告电子文档上传到互联网上,获取到该验厂报告电子文档的url地址,并将该url地址提供给服务器。
其次,服务器根据用户提供的url地址获取到原始验厂报告电子文档。
然后,服务器确定与原始验厂报告电子文档的后缀文件名对应的验证工具,得到原始 验厂报告电子文档的验证工具;使用原始验厂报告电子文档的验证工具验证原始验厂报告电子文档;获取通过验证的原始验厂报告电子文档,得到待解析验厂报告电子文档。
然后,服务器确定与待解析验厂报告电子文档的后缀文件名对应的提取工具,得到待解析验厂报告电子文档的提取工具;使用待解析验厂报告电子文档的提取工具提取待解析验厂报告电子文档中的文字部分;获取待解析验厂报告电子文档中的文字部分,得到待解析验厂报告电子文档的文本模式。
然后,服务器将待解析验厂报告电子文档的文本模式逐词匹配设定匹配规则;获取待解析验厂报告电子文档的文本模式中与设定匹配规则匹配的词,得到符合设定匹配规则的数据。
例如,其中的一条匹配规则为“(‘电脑’or’电脑控制式’)(‘缝纫’or‘平缝’)机{number}(‘台’or‘套’or‘个’)”,则在待解析验厂报告电子文档中若遇到“电脑平缝机5台”、“电脑控制式缝纫机5套”或“电脑缝纫机5个”等都会作为匹配成功。一旦匹配成功,则会获取其中的数字,并将其存储到数据库中“电脑平缝机”对应的字段中。具体匹配结果参见表1:
表1
最后,以表格的形式在页面中展示提取的数据。具体展示结果如图3所示。
至此,不同验厂报告获得的不同“电脑平缝机”数量等各种维度的参数,将会很容易的比较、排序,方便用户进行比较,从而筛选出符合条件的工厂。
基于同一发明构思,本申请实施例还提供一种结构化数据生成装置,该装置与如图1所示的结构化数据生成方法相对应,可以但不限于应用在服务器中,该装置的结构如4图所示,包括第一获取模块41、提取模块42和生成模块43,其中:
上述第一获取模块41,用于获取待解析电子文档的文本模式;
上述提取模块42,用于从待解析电子文档的文本模式中提取符合设定匹配规则的数据;
上述生成模块43,用于将提取的数据生成结构化数据。
该方案中,通过获取待解析电子文档的文本模式,从待解析电子文档的文本模式中提取符合设定匹配规则的数据,然后将提取的数据生成结构化数据,从而实现自动生成结构化数据,相对于相关技术中采用人工生成结构化数据的方式,生成效率很高,能够有效避免人为错误,准确性较好,即使待解析电子文档是海量的不同格式的电子文档,也能快速、准确地生成结构化数据。
可选的,上述结构化数据生成装置中还包括:
接收模块,用于接收用户提供的url地址;
第二获取模块,用于获取url地址对应的原始电子文档;
选取模块,用于从原始电子文档中选取待解析电子文档。
具体的,上述选取模块,用于从原始电子文档中选取待解析电子文档,具体用于:
确定与原始电子文档的后缀文件名对应的验证工具,得到原始电子文档的验证工具;
使用原始电子文档的验证工具验证原始电子文档;
获取通过验证的原始电子文档,得到待解析电子文档。
可选的,上述结构化数据生成装置中还包括:
第一添加模块,用于在待解析电子文档中添加第一设定标识。
具体的,上述第一获取模块41,用于获取待解析电子文档的文本模式,具体用于:
确定与待解析电子文档的后缀文件名对应的提取工具,得到待解析电子文档的提取工具;
使用待解析电子文档的提取工具提取待解析电子文档中的文字部分;
获取待解析电子文档中的文字部分,得到待解析电子文档的文本模式。
具体的,上述提取模块42,用于从待解析电子文档的文本模式中提取符合设定匹配规则的数据,具体用于:
将待解析电子文档的文本模式逐词匹配设定匹配规则;
获取待解析电子文档的文本模式中与设定匹配规则匹配的词,得到符合设定匹配规则的数据。
可选的,上述结构化数据生成装置中还包括:
第二添加模块,用于在完成与设定匹配规则匹配的待解析电子文档中添加第二设定标识。
具体的,上述生成模块43,用于将提取的数据生成结构化数据,具体用于:
以表格的形式在页面中展示提取的数据。
上述说明示出并描述了本申请的优选实施例,但如前所述,应当理解本申请并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述发明构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本申请的精神和范围,则都应在本申请所附权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!