一种数据检索方法及系统与流程
本发明涉及信息处理
技术领域:
,特别涉及一种数据检索方法及系统。
背景技术:
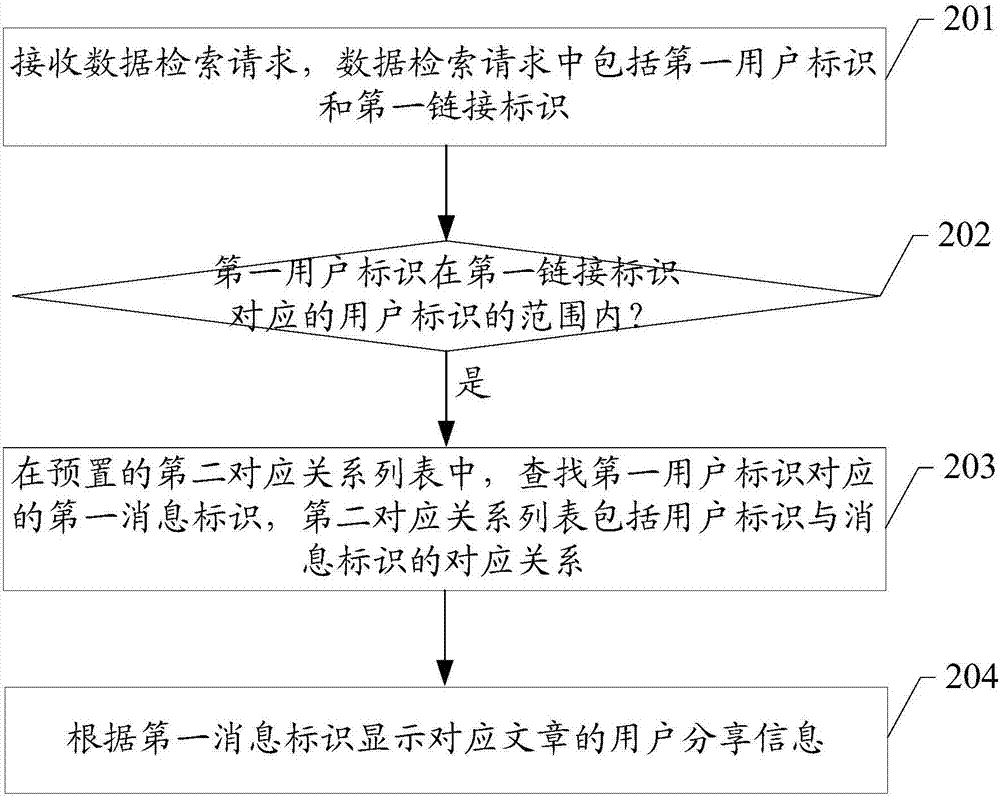
:现有的社交网络系统(比如微信系统,或即时通信系统)都具有关系链的检索功能,具体地,社交网络系统可以根据用户输入的关键字检索某一个链接的文章被该用户好友的分享情况,并将分享情况展示给用户。现有的社交网络系统一般采用优质网页数据对象(goodobject,简称gob)检索系统实现上述检索功能,具体地,社交网络系统以项(term)到消息标识的倒排数据结构储存用户与分享的文章之间的关系,这样社交网络系统在检索用户分享文章的信息时,会将用户标识和链接标识作为项,分别查找得到用户标识和链接标识对应的消息标识的第一列表和第二列表,然后对第一列表和第二列表进行求交操作得到链接标识,及用户标识和消息标识的对应关系。由于要对第一列表和第二列表进行求交操作,如果两个列表的项比较多,则数据检索的计算量就比较大。技术实现要素:本发明实施例提供一种数据检索方法及系统,实现了在数据检索系统储存的第一对应关系列表或第二对应关系列表中直接查找到消息标识。本发明实施例提供一种数据检索方法,包括:接收数据检索请求,所述数据检索请求中包括第一用户标识和第一链接标识;如果所述第一链接标识在所述第一用户标识对应的链接标识的范围内,在预置的第一对应关系列表中,查找所述第一链接标识对应的第一消息标识;其中,所述第一对应关系列表包括链接标识与消息标识的对应关系;根据所述第一消息标识显示对应文章的用户分享信息。本发明实施例提供一种数据检索系统,包括:第一请求接收单元,用于接收数据检索请求,所述数据检索请求中包括第一用户标识和第一链接标识;第一查找单元,用于如果所述第一链接标识在所述第一用户标识对应的链接标识的范围内,在预置的第一对应关系列表中,查找所述第一链接标识对应的第一消息标识;其中,所述第一对应关系列表包括链接标识与消息标识的对应关系;第一结果显示单元,用于根据所述第一消息标识显示对应的文章的用户分享信息。在本实施例的一个方面,数据检索系统中以第一对应关系列表储存链接标识与消息标识的对应关系,这样数据检索系统确定数据检索请求中的第一链接标识与第一用户标识相关联,则直接在第一对应关系列表中查找到第一链接标识对应的第一消息标识,从而得到用户分享文章的情况。本实施例中的方法可以不用执行求交操作,而是可以直接查找得到最终结果,相对于现有技术中的求交操作,数据检索的计算量较少。本发明实施例还提供一种数据检索方法,包括:接收数据检索请求,所述数据检索请求中包括第一用户标识和第一链接标识;如果所述第一用户标识在所述第一链接标识对应的用户标识的范围内,在预置的第二对应关系列表中,查找所述第一用户标识对应的第一消息标识;其中,所述第二对应关系列表包括用户标识与消息标识的对应关系;根据所述第一消息标识显示对应文章的用户分享信息。本发明实施例还提供一种数据检索系统,包括:第二请求接收单元,接收数据检索请求,所述数据检索请求中包括第一用户标识和第一链接标识;第二查找单元,用于如果所述第一用户标识在所述第一链接标识对应的用户标识的范围内,在预置的第二对应关系列表中,查找所述第一用户标识对应的第一消息标识;其中,所述第二对应关系列表包括用户标识与消息标识的对应关系;第二结果显示单元,用于根据所述第一消息标识显示对应文章的用户分享信息。在本实施例的另一方面,数据检索系统中以第二对应关系列表储存用户 标识与消息标识的对应关系,这样数据检索系统确定数据检索请求中的第一用户标识与第一链接标识相关联,则直接在第二对应关系列表中查找到第一用户标识对应的第一消息标识,从而得到用户分享文章的情况。本实施例中的方法可以不用执行求交操作,而是可以直接查找得到最终结果,相对于现有技术中的求交操作,数据检索的计算量较少。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。图1是本发明实施例一提供的一种数据检索方法的流程图;图2是本发明实施例二提供的一种数据检索方法的流程图;图3是本发明实施例一中数据检索系统储存数据的示意图;图4是本发明实施例二中数据检索系统储存数据的示意图;图5是本发明实施例三提供的数据检索方法应用于的社交网络系统的结构示意图;图6是本发明实施例三提供的一种数据检索方法的示意图;图7是本发明实施例四提供的一种数据检索系统的结构示意图;图8是本发明实施例四提供的另一种数据检索系统的结构示意图;图9是本发明实施例五提供的一种数据检索系统的结构示意图;图10是本发明实施例五提供的另一种数据检索系统的结构示意图;图11是本发明实施例六提供的一种数据检索系统的结构示意图。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺 序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例例如能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排它的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。本发明实施例一提供一种数据检索方法,主要是应用于社交网络系统中比如微信系统,微博系统或即时通信系统(比如qq系统等)等,在社交网络系统中可以包括客户端和服务器,在服务器中装载数据检索系统,本实施例的方法是服务器的数据检索系统所执行的方法,流程图如图1所示,包括:步骤101,接收数据检索请求,数据检索请求中包括第一用户标识和第一链接标识,这里第一用户标识是唯一标识某一个用户的信息,比如微信号,微博号或即时通信号等;第一链接标识是唯一标识某一个文章链接的信息。可以理解,用户可以通过社交网络系统中包括的客户端发起数据检索流程,具体地,用户可以在客户端显示的搜索界面选择至少一个文章链接,且可以选择该用户的用户标识,和/或,与该用户相关的至少一个用户标识,以发起本实施例的数据检索请求,并在数据检索请求中添加用户选择的信息;这样服务器的数据检索系统会接收到客户端发送的数据检索请求,并执行如下步骤102到104。其中,在数据检索请求中的第一用户标识和第一链接标识可以分别为一个,或分别为多个。步骤102,判断第一链接标识是否在第一用户标识对应的链接标识的范围内,如果是,则执行步骤103,说明该第一用户标识对应用户通过客户端分享了第一链接标识所标识链接的文章;如果不是,则结束流程。需要说明的是,当某一用户通过客户端分享某一链接的文章时,本实施例的数据检索系统会接收到该用户对某一链接的文章的分享请求,在分享请求中包括该某一链接的第一链接标识和该用户的第一用户标识,且还可以包括用户的评论信息;则数据检索系统会将该链接的文章的信息储存成第一用户标识对应的一条消息,且还可以将用户的评论信息储存到该条消息中,并 生成该条消息的第一消息标识来唯一标识该条消息,且将该第一链接标识和第一消息标识储存到第一对应关系列表中,并将该第一链接标识与第一用户标识关联。因此,在执行本步骤102时,数据检索系统可以查找数据检索系统中储存的与第一用户标识关联的链接标识中是否包括第一链接标识,如果有,则执行步骤103。因此,本实施例中,数据检索系统中不仅需要储存第一对应关系列表,还需要储存与用户标识关联的链接标识的信息。在具体实现过程中:(1)第一对应关系列表可以包括多个数据块,每个数据块包括头部和值两部分。其中头部的结构可以如下表1所示,包括数据长度(datalength)和下一数据块(next)在文件中的偏移(offset)数据,且还可以包括预留(reserve)数据,这里数据长度用于指示该数据块的长度,下一数据块在文件中的偏移数据用于指示该数据块的下一数据块的位置信息。表18bytesnextoffset8bytesdatalength16bytesreserve每个数据块的值的结构可以如下表2所示,包括链接标识及对应的消息标识,其中链接标识可以用文档标识(documentidentity,简称docid)来表示,消息标识用推特标识(tweetidentity,简称tid)来表示,该tid主要是指用户通过社交网络系统的客户端发表的一条消息的标识,比如微博消息的标识,微信消息的标识。表28bytestida8bytesdocida8bytestidb8bytesdocidb(2)本实施例中,数据检索系统可以通过用户标识索引查找到与用户标识关联的链接标识的信息。其中,用户标识索引的结构可以如下述表3所示,包括用户标识和关联信息在文件中的偏移数据,这里用户标识可以用用户识别号码(useridentificationnumber,简称uin)来表示,关联信息在文件中的偏移数据用于标识与该用户标识关联的链接标识的信息的位置信息。表38bytesuin8bytesoffset步骤103,在预置的第一对应关系列表中,查找上述第一链接标识对应的第一消息标识。其中,第一对应关系列表包括链接标识与消息标识的对应关系。步骤104,根据第一消息标识显示对应文章的用户分享信息,用户分享信息具体可以包括用户的评论信息,分享该文章的用户数等信息。在一个具体的实施例中,为了进一步地减少数据检索的工作量,如果上述数据检索请求中包括的第一用户标识有多个,则在执行步骤102之前,数据检索系统可以先使用过滤器过滤多个第一用户标识中的至少一个第二用户标识得到剩余的第三用户标识,第二用户标识为未对应任何链接标识的用户标识;则在执行步骤102时,数据检索系统会判断第一链接标识是否在第三用户标识对应的链接标识的范围内。具体地,数据检索系统中储存的过滤器的数据可以包括:过滤器索引和过滤器值,其中,过滤器索引的结构可以如下表4所示,包括链接标识和过滤器在文件中的偏移数据,其中过滤器在文件中的偏移数据用于指示过滤器的位置信息,且一个链接标识对应一个过滤器。表48bytesdocid8bytesoffset过滤器值的结构可以如下表5所示,包括多个数据块,每个数据块中包括数据长度和过滤策略数据,其中数据长度用于指示过滤策略数据的长度,过滤策略数据是指过滤用户标识的策略数据,可以由用户预置。这里过滤器可以是布隆过滤器(bloomfilter,简称bf)。表54byteslengthxbytesbfdataa4byteslengthxbytesbfdatab另外,需要说明的是,本实施例中数据检索系统在储存第一对应关系列表和与用户标识关联的链接标识的信息时,都是储存于该数据检索系统的永久性存储器(比如磁盘)中,而过滤器的数据可以储存在暂时性存储器(比 如内存)中。可见,在本实施例的方法中,数据检索系统中以第一对应关系列表储存链接标识与消息标识的对应关系,这样数据检索系统确定数据检索请求中的第一链接标识与第一用户标识相关联,则直接在第一对应关系列表中查找到第一链接标识对应的第一消息标识,从而得到用户分享某一链接的文章的情况。本实施例中的方法可以不用执行求交操作,而是可以直接查找得到最终结果,相对于现有技术中的求交操作,数据检索的计算量较少。本发明实施例二提供一种数据检索方法,主要是应用于社交网络系统中,在社交网络系统中可以包括客户端和服务器,在服务器中装载数据检索系统,本实施例的方法是服务器的数据检索系统所执行的方法,流程图如图2所示,包括:步骤201,接收数据检索请求,数据检索请求中包括第一用户标识和第一链接标识,这里第一用户标识是唯一标识某一个用户的信息,比如微信号,微博号或即时通信号等;第一链接标识是唯一标识某一个文章链接的信息。可以理解,用户可以通过社交网络系统中包括的客户端发起数据检索流程,具体地,用户可以在客户端显示的搜索界面选择至少一个文章链接,且可以选择该用户的用户标识,和/或,与该用户相关的至少一个用户标识,以发起本实施例的数据检索请求,并在数据检索请求中添加用户选择的信息;这样服务器的数据检索系统会接收到客户端发送的数据检索请求,并执行如下步骤202到204。其中,在数据检索请求中的第一用户标识和第一链接标识可以分别为一个,或分别为多个。步骤202,判断第一用户标识是否在第一链接标识对应的用户标识的范围内,如果是,则执行步骤203,说明该第一用户标识对应用户通过客户端分享了第一链接标识所标识链接的文章;如果不是,则结束流程。需要说明的是,当某一用户通过客户端分享某一链接的文章时,本实施例的数据检索系统会接收到该用户对某一链接的文章的分享请求,在分享请求中包括该某一链接的第一链接标识和该用户的第一用户标识,且还可以包括用户的评论信息;则数据检索系统会将该链接的文章的信息储存成第一用户标识对应的一条消息,且还可以将用户的评论信息储存到该条消息中,并 生成该条消息的第一消息标识来唯一标识该条消息,且将该第一用户标识和第一消息标识储存到第二对应关系列表中,并将该第一用户标识与第一链接标识关联。因此,在执行本步骤202时,数据检索系统可以查找数据检索系统中储存的与第一链接标识关联的用户标识中是否包括第一用户标识,如果有,则执行步骤203。因此,本实施例中,数据检索系统中不仅需要储存第二对应关系列表,还需要储存与链接标识关联的用户标识的信息。在具体实现过程中:(1)第二对应关系列表可以包括多个数据块,每个数据块包括头部和值两部分。其中头部的结构可以如上述表1所示,包括数据长度和下一数据块在文件中的偏移数据,且还可以包括预留数据;每个数据块的值的结构可以如下表6所示,包括用户标识及对应的消息标识,这里用户标识可以用uin来表示,消息标识可以用tid来表示。表68bytestida8bytesuina8bytestidb8bytesuinb(2)本实施例中,数据检索系统可以通过链接标识索引查找到与链接标识关联的用户标识的信息。其中,链接标识索引的结构可以如下述表7所示,包括链接标识和关联信息在文件中的偏移数据,这里链接标识可以用docid来表示,关联信息在文件中的偏移数据用于标识与该链接标识关联的用户标识的信息的位置信息。表78bytesdocid8bytesoffset步骤203,在预置的第二对应关系列表中,查找上述第一用户标识对应的第一消息标识。其中,第二对应关系列表包括用户标识与消息标识的对应关系。步骤204,根据第一消息标识显示对应文章的用户分享信息,用户分享信息具体可以包括用户评论信息,分享该文章的用户数等信息。在一个具体的实施例中,为了进一步地减少数据检索的工作量,如果上述数据检索请求中包括的第一用户标识有多个,则在执行步骤202之前,数据 检索系统可以先使用过滤器过滤多个第一用户标识中的至少一个第二用户标识得到剩余的第三用户标识,第二用户标识为未对应任何链接标识的用户标识;则在执行步骤202时,数据检索系统会判断第三用户标识是否在第一链接标识对应的用户标识的范围内。具体地,本实施例的过滤器的结构可以如上述表5中所述,在此不进行赘述。在这种情况下,数据检索系统中储存的标识索引的结构可以如下表8所示,包括链接标识、关联信息在文件中的偏移数据和过滤器在文件中的偏移数据,这里过滤器在文件中的偏移数据用于标识与该链接标识对应的过滤器的数据的位置信息,链接标识可以用docid来表示。表88bytesdocid8bytesoffset8bytesbfoffset另一种情况下,本实施例中的过滤器的结构也可以如上述实施例一中所述,包括过滤器索引和过滤器值,在此不进行赘述。在这种情况下,直接可以通过第一链接标识就可以定位到对应过滤器的位置,则数据检索系统中储存的标识索引的结构可以如上述表7所示,而不用包括过滤器在文件中的偏移数据。另外,需要说明的是,本实施例中数据检索系统在储存第二对应关系列表和与链接标识关联的用户标识的信息时,都是储存于该数据检索系统的永久性存储器(比如磁盘)中,而过滤器的数据可以储存在暂时性存储器(比如内存)中。可见,在本实施例的方法中,数据检索系统中以第二对应关系列表储存用户标识与消息标识的对应关系,这样数据检索系统确定数据检索请求中的第一用户标识与第一链接标识相关联,则直接在第二对应关系列表中查找到第一用户标识对应的第一消息标识,从而得到用户分享文章的情况。本实施例中的方法可以不用执行求交操作,而是可以直接查找得到最终结果,相对于现有技术中的求交操作,数据检索的计算量较少。需要说明的是,本实施例二与上述实施例一相比,数据检索系统所采用的检索方法类似,都是从对应关系列表中可以直接查找到最终结果,不同的是,上述实施例一中,数据检索系统储存的数据结构是用户标识到链接标识 与消息标识的对应关系的倒排数据结构,具体可以如图3所示,这样通过用户标识可以找到对应的消息标识。而在实施例二中,数据检索系统储存的数据结构是链接标识到用户标识与文章标识的对应关系的倒排数据结构,具体可以如图4所示,这样通过链接标识可以找到对应的消息标识。其中由于一个用户所分享的文章数量,相比一篇文章被分享的用户数量较小,则用户标识对应的链接标识与消息标识的数据,会比链接标识对应的用户标识与消息标识的数据少很多,一般情况下,几乎所有用户标识对应的链接标识与消息标识的数据只要一个4kb的数据块就可以存放,因此,采用实施例一中的方法,数据检索系统中储存的数据量要小。本发明实施例三以一个具体的实施例说明本实施例一中所述的数据检索方法,在本实施例的方法适用于社交网络系统,如图5所示,本实施例的社交网络系统包括社交网络客户端和社交网络服务器,在社交网络服务器中装载数据检索系统。(1)用户通过社交网络客户端发起本实施例的数据检索流程。具体地,用户可以在社交网络客户端显示的文章搜索界面中输入关键字并点击提交,则社交网络客户端会向文章服务器发送文章搜索请求,这样文章服务器会根据关键字搜索相关的文章信息,并将文章的链接信息发送给社交网络客户端进行显示。这样用户可以选择一个或多个链接,且可以选择该用户的用户标识,或与该用户相关的其它用户标识,并提交,这样社交网络客户端会向社交网络服务器发送上述实施例一中所述的数据检索请求,并由社交网络服务器中的数据检索系统执行上述实施例一中所述的方法。其中文章服务器是社交网络系统所支撑的一个服务器。(2)数据检索系统接收到数据检索请求,例如在数据检索请求中包括的第一用户标识为uin1,第一链接标识为docid1。参考图6所示,数据检索系统会查找到该uin1所属的哈希(hash)桶即哈希索引,并根据哈希索引中的哈希列表偏移确定哈希列表所在的位置;然后查找到哈希列表,并根据哈希列表中uin1的关联信息的偏移确定与uin1关联的链接标识的信息的位置;再查找到与该uin1关联的信息,具体可以包括最大 docid,最小docid,链接标识所在磁盘标识符(diskid),所在文件的标识(fileid)及对应关系偏移等。如果上述docid1在最大docid与最小docid的范围内,且在与uin关联的链接标识的信息中匹配到该docid1,则数据检索系统确定docid1在uin1对应的链接标识的范围内,并根据其中的对应关系偏移确定链接标识和消息标识的第一对应关系的值的位置,然后根据该位置查找到第一对应关系的值即tid+doc的值;从tid+doc的值中取出docid1对应的tid值。(3)数据检索系统可以将最终得到的tid值发送给文章服务器,由文章服务器根据该tid值得到对应文章的用户分享信息,并将用户分享信息发送给社交网络客户端进行显示。本发明实施例四提供一种数据检索系统,本实施例的系统是上述实施例一所述的数据检索系统,其结构示意图如图7所示,具体可以包括:第一请求接收单元10,用于接收数据检索请求,所述数据检索请求中包括第一用户标识和第一链接标识;在数据检索请求中的第一用户标识和第一链接标识可以分别为一个,或分别为多个。第一查找单元11,用于如果所述第一请求接收单元10接收的数据检索请求中包括的第一链接标识在所述第一用户标识对应的链接标识的范围内,在预置的第一对应关系列表中,查找所述第一链接标识对应的第一消息标识;其中,所述第一对应关系列表包括链接标识与消息标识的对应关系。第一结果显示单元12,用于根据所述第一查找单元11查找的第一消息标识显示对应文章的用户分享信息。可见,在本实施例的数据检索系统中以第一对应关系列表储存链接标识与消息标识的对应关系,这样当第一查找单元11确定数据检索请求中的第一链接标识与第一用户标识相关联,则直接在第一对应关系列表中查找到第一链接标识对应的第一消息标识,从而得到用户分享文章的情况。本实施例中的系统可以不用执行求交操作,而是可以直接查找得到最终结果,相对于现有技术中的求交操作,数据检索的计算量较少。参考图8所示,在一个具体的实施例中,数据检索系统除了可以包括如图 7所示的结构外,还可以包括第一过滤单元13和第一对应关系储存单元14,其中:当所述第一请求接收单元10接收的数据检索请求中包括的第一用户标识有多个,第一过滤单元13,用于使用过滤器过滤所述多个第一用户标识中的至少一个第二用户标识得到剩余的第三用户标识,所述第二用户标识为未对应任何链接标识的用户标识;这样所述第一查找单元11,具体用于如果所述第一链接标识在所述第一过滤单元13过滤得到的第三用户标识对应的链接标识的范围内,在预置的第一对应关系列表中,查找所述第一链接标识对应的第一消息标识,减少了数据检索的工作量。其中,过滤器的数据包括:过滤器索引和过滤器值,其中,所述过滤器索引中包括链接标识和所述过滤器在文件中的偏移数据,所述过滤器值中包括多个数据块,每个数据块中包括数据长度和过滤策略数据。第一对应关系储存单元14,用于接收到用户对某一链接的文章的分享请求,所述分享请求中包括所述某一链接的第一链接标识和所述用户的第一用户标识;将所述某一链接的文章的信息储存成所述第一用户标识对应的一条消息,并生成所述一条消息的第一消息标识,将所述第一链接标识和第一消息标识储存到所述第一对应关系列表中,将所述第一链接标识与所述第一用户标识关联;其中,所述第一对应关系列表中包括多个数据块,每个数据块包括头部和值,所述头部包括数据长度和下一数据块在文件中的偏移数据,每个数据块的值包括链接标识及对应的消息标识。这样第一查找单元11会在第一对应关系储存单元14储存的第一对应关系列表中查找到对应的第一消息标识。本实施例中的第一对应关系储存单元14在将所述第一链接标识与所述第一用户标识关联时,可以通过用户标识索引来关联,其中用户标识索引的结构可以如上述实施例一中所述,在此不进行赘述。本发明实施例五提供一种数据检索系统,本实施例的系统是上述实施例二所述的数据检索系统,其结构示意图如图9所示,具体可以包括:第二请求接收单元20,接收数据检索请求,所述数据检索请求中包括第 一用户标识和第一链接标识;;在数据检索请求中的第一用户标识和第一链接标识可以分别为一个,或分别为多个。第二查找单元21,用于如果所述第二请求接收单元20接收的数据检索请求中包括的第一用户标识在所述第一链接标识对应的用户标识的范围内,在预置的第二对应关系列表中,查找所述第一用户标识对应的第一消息标识;其中,所述第二对应关系列表包括用户标识与消息标识的对应关系。第二结果显示单元22,用于根据所述第二查找单元21查找的第一消息标识显示对应文章的用户分享信息。在本实施例的数据检索系统中以第二对应关系列表储存用户标识与消息标识的对应关系,这样数据检索系统的第二查找单元21确定数据检索请求中的第一用户标识与第一链接标识相关联,则直接在第二对应关系列表中查找到第一用户标识对应的第一消息标识,从而得到用户分享文章的情况。本实施例中的系统可以不用执行求交操作,而是可以直接查找得到最终结果,相对于现有技术中的求交操作,数据检索的计算量较少。参考图10所示,在一个具体的实施例中,数据检索系统除了可以包括如图9所示的结构外,还可以包括第二过滤单元23和第二对应关系储存单元24,其中:第二对应关系储存单元24,用于接收到某一用户对某一链接的文章的分享请求,所述分享请求中包括所述某一链接的第一链接标识和所述某一用户的第一用户标识;将所述某一链接的文章的信息储存成所述第一用户标识对应的一条消息,并生成所述一条消息的第一消息标识,将所述第一用户标识和第一消息标识储存到所述第二对应关系列表中,且将所述第一用户标识与第一链接标识关联;其中,所述第二对应关系列表中包括多个数据块,每个数据块包括头部和值,所述头部包括数据长度和下一数据块在文件中的偏移数据,每个数据块的值包括用户标识及对应的消息标识。本实施例中的第二对应关系储存单24在将所述第一用户标识与第一链接标识关联时,可以通过用户标识索引来关联,其中用户标识索引的结构可以如上述实施例二中所述,可以有如表7和表8中所示的两种结构,在此不进行赘述。当第二请求接收单元20接收的数据检索请求中包括的第一用户标识有多个;则第二过滤单元23,用于使用过滤器过滤所述多个第一用户标识中的至少一个第二用户标识得到剩余的第三用户标识,所述第二用户标识为未对应任何链接标识的用户标识;这样第二查找单元21,具体用于如果所述第二过滤单元23过滤得到的第三用户标识在所述第一链接标识对应的用户标识的范围内,在预置的第二对应关系列表中,查找所述第一用户标识对应的第一消息标识,减少了数据检索的工作量。其中,所述过滤器的数据包括:过滤器索引和过滤器值,其中,所述过滤器索引中包括链接标识和所述过滤器在文件中的偏移数据,所述过滤器值中包括多个数据块,每个数据块中包括数据长度和过滤策略数据。在这种情况下,第二对应关系储存单24关联信息时所使用的用户标识索引的结构可以如上述表7中所示的结构。另一种情况下,所述过滤器的数据包括过滤器值,所述过滤器值包括多个数据块,每个数据块中包括数据长度和过滤策略数据。在这种情况下,第二对应关系储存单24关联信息时所使用的用户标识索引的结构可以如上述表8中所示的结构。本发明实施例五本发明实施例还提供一种数据检索系统,其结构示意图如图11所示,该数据检索系统可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上中央处理器(centralprocessingunits,cpu)30(例如,一个或一个以上处理器)和存储器31,一个或一个以上存储应用程序321或数据322的存储介质32(例如一个或一个以上海量存储设备)。其中,存储器31和存储介质32可以是短暂存储或持久存储。存储在存储介质32的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对数据检索系统中的一系列指令操作。更进一步地,中央处理器30可以设置为与存储介质32通信,在数据检索系统上执行存储介质32中的一系列指令操作。数据检索系统还可以包括一个或一个以上电源33,一个或一个以上有线或无线网络接口34,一个或一个以上输入输出接口35,和/或,一个或一个以上操作系统323,例如windowsservertm,macosxtm,unixtm,linuxtm, freebsdtm等等。上述方法实施例中所述的由数据检索系统所执行的步骤可以基于该图11所示的数据检索系统的结构。本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(rom)、随机存取存储器ram)、磁盘或光盘等。以上对本发明实施例所提供的数据检索方法及系统进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1