基于K-means的妥投地址数据处理方法和系统与流程
本发明涉及地理空间信息数据的处理技术领域,具体地说,涉及一种基于k-means的妥投地址数据处理方法和系统。
背景技术:
随着空间信息技术和移动互联网的发展和应用,地理信息技术已广泛应用于互联网的各个领域,尤其是智能位置服务,其已成为互联网发展的关键支撑技术之一。
在电商的物流投递系统中,电商的快递员根据商品的运单地址,将物品投递给用户,并记录投递时的地理坐标,也就是妥投地址的地理坐标。在电商的系统中,通常在同一个地址下会有多个历史累积的订单,如同一用户有过多次购买行为,因而会下过多次订单。由于每一次订单的快递员可能不同,用户接收商品的地点可能不同,因而,针对同一个地址,妥投地址的地理坐标可能会不同,所以,这就产生了在同一个地址下,电商系统中对应有多个妥投地址的地理坐标的问题。这些妥投地址的地理坐标并不是智能位置服务需要的最终数据,而且,这些地理坐标总是会在一定范围变化,如果波动范围较大,则会影响正/逆向获取地址的准确性。即根据地址得到地理坐标,或根据地理坐标得到地址的准确性。
在大型电商的投递系统中,记录了大量的地址地理坐标数据,而这些数据正是目前大多数gis(geographicinformationsystem,地理信息系统)系统所需要的数据源。多数的gis系统通过地理坐标采集或购买来获得数据源。对于采集的地理坐标数据,数据单薄,而且数据准确度受信号、采集人员等多方面因素的影响,采集数据误差在所难免,且不易控制。
技术实现要素:
本发明要解决的技术问题在于,针对目前同一地址对应多个妥投地址地理坐标的问题,提供了一种基于k-means的妥投地址数据处理方法和系统,用于通过所述多个妥投地址的地理坐标确定一个与所述地址对应的准确地理坐标。
为解决上述技术问题,根据本发明的一个方面,本发明提供了一种基于k-means的妥投地址数据处理方法,其中,包括如下步骤:
获取给定地址的多个妥投地址的地理坐标,并将所述多个妥投地址的地理坐标作为源数据,形成坐标点群;
根据k-means聚类算法,以聚类个数值为1,对所述坐标点群进行第一次聚合,获取第一次聚合坐标点p1(x1,y1);
以所述第一次聚合坐标点p1(x1,y1)为圆心作圆,得到圆内坐标点的数量大于或等于预设的聚合数量阈值n1的最终圆;
根据k-means聚类算法,以聚类个数值为1,对最终圆内多个坐标点进行聚合,获取最终聚合坐标点pf(xf,yf),并将所述最终聚合坐标点pf(xf,yf)作为所述给定地址的地理坐标。
优选地,在以所述第一次聚合坐标点p1(x1,y1)为圆心作圆时,包括以下步骤:
以所述第一次聚合坐标点p1(x1,y1)为圆心,以所有坐标点到所述圆心p1的平均距离r1为半径作圆;
统计半径为r1的圆内坐标点的数量;
如果半径为r1的圆内坐标点的数量大于或等于预设的聚合数量阈值n1,则所述半径为r1的圆为最终圆;
如果半径为r1的圆内坐标点的数量小于预设的聚合数量阈值n1,则根据公式1-1得到的校正半径重新做圆,直到得到最终圆;
ri+1=ri+(dmax-ddev)/β1-1
其中,ri为当前圆的半径,i=1,2,3……k,k为自然数,dmax、ddev分别是当前圆内所有坐标点到圆心p1的最大值和平均值;β为权值。
优选地,如果所述地址为索引地址,则β=2;如果所述源数据为末级地址,则β=4。
优选地,所述聚合数量阈值n1=n*λ,其中,n为源数据的数量,如果所述地址为索引地址,则λ为95%-97%区间的任何一个点值,如果所述地址为末级地址,则λ为70%-80%区间的任何一个点值。
优选地,对所述坐标点群进行第一次聚合之前,判断所述源数据的数量是否大于或等于预定的数量阈值,如果所述源数据的数量大于或等于预定的数量阈值,对所述坐标点群进行第一次聚合。
优选地,在根据公式1-1得到的半径重新做圆时,包括判断所述地址为索引地址或末级地址的步骤:
读取所述给定地址的标识位,根据所述标识位的标识,判断所述地址为索引地址或末级地址。
优选地,还包括对用户地址进行分类处理的步骤:
将用户地址根据地理区域从大到小进行分段处理,形成从首地址分段到末端地址分段的多个地址分段;
按照地理区域从大到小的地址分段,依次统计各个地址分段对应的地理坐标点的数量;
将所述各个地址分段对应的地理坐标点的数量分别与预定阈值进行比较,如果当前地址分段对应的地理坐标点的数量小于所述预定阈值时,同时当前地址分段的前一个地址分段对应的地理坐标点的数量大于或等于所述预定阈值时,则从所述当前地址分段开始到末端地址分段为末级地址,从首地址分段到当前地址分段的前一个地址分段为索引地址;
为所述索引地址和末级地址分别设置相应的标识位。
优选地,在依次统计各个地址分段对应的地理坐标点的数量之前,将所述各个地址分段与预设的索引地址匹配表进行匹配,确定属于索引地址的地址分段和非索引地址的地址分段;
统计各个地址分段对应的地理坐标点的数量时,统计非索引地址的地址分段对应的地理坐标点的数量;
将所述各个地址分段对应的地理坐标点的数量分别与预定阈值进行比较时,将所述非索引地址的地址分段对应的地理坐标点的数量分别 与预定阈值进行比较。
为解决上述技术问题,根据本发明的另一个方面,本发明提供了一种基于k-means的妥投地址数据处理系统,其中,包括:
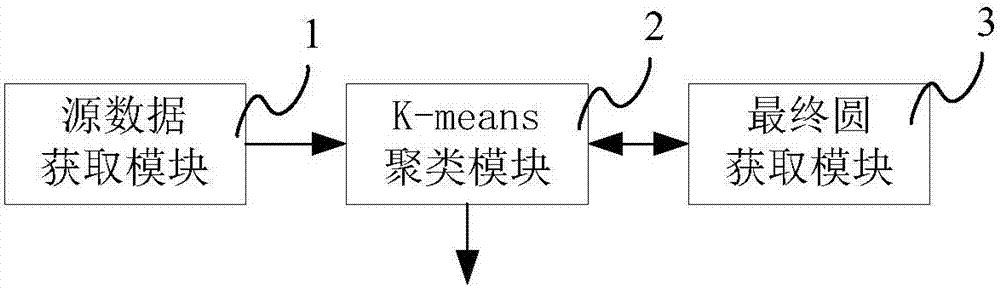
源数据获取模块,用于根据提供的地址,获取与所述地址对应的多个妥投地址的地理坐标,在地理信息系统中形成坐标点群;
k-means聚类模块,用于根据设定的聚类个数值,对设定的坐标点群进行聚合,得到设定聚类个数的聚合坐标点;和
最终圆获取模块,用于根据k-means聚类模块得到的第一次聚合坐标点p1(x1,y1),得到圆内坐标点的数量大于或等于预设的聚合数量阈值n1的最终圆。
优选地,上述系统还包括地址类别判断模块,用于判断所述地址为索引地址或末级地址。
优选地,所述最终圆获取模块包括首次圆获取单元、校正圆获取单元、统计单元和比较单元;
其中,所述首次圆获取单元与所述k-means聚类模块和所述源数据获取模块相连接,用于根据所述k-means聚类模块得到的第一次聚合坐标点p1(x1,y1),以所述坐标点p1(x1,y1)为圆心,以从所述源数据获取模块得到的所有坐标点到所述圆心p1(x1,y1)的平均距离r1为半径,得到首次圆;
所述校正圆获取单元,分别与所述首次圆获取单元、所述地址类别判断模块和比较单元相连接,根据所述比较单元输出的重新计算通知,以公式1-1得到的校正半径ri+1,以所述坐标点p1(x1,y1)为圆心,得到校正圆,或者根据所述比较单元输出的合格通知,将半径为r1的圆确定为最终圆;
ri+1=ri+(dmax-ddev)/β1-1
其中,ri为当前圆的半径,i=1,2,3……k,k为自然数,dmax、ddev分别是当前圆内所有坐标点到点p1(x1,y1)的最大值和平均值,β为权值;
所述统计单元与所述首次圆获取单元和校正圆获取单元相连接,用于统计首次圆和校正圆内的坐标点数量;
所述比较单元与所述统计单元相连接,用于对首次圆和校正圆内的 坐标点数量分别与聚合数量阈值n1相比较,如果圆内坐标点的数量小于预设的聚合数量阈值n1,向所述校正圆获取单元发送重新计算通知,如果圆内坐标点的数量大于或等于预设的聚合数量阈值n1,则向所述校正圆获取单元发送合格通知。
优选地,本发明所述系统还包括地址处理模块,所述地址处理模块包括:
地址分段单元,用于将所述地址按地理区域从大到小进行分段,形成多个地址分段;
数量统计单元,与所述地址分段单元相连接,用于统计各个地址分段对应的地理坐标点的数量;
比较单元,与所述数量统计单元相连接,用于比较各个地址分段对应的地理坐标点的数量与预定阈值;和
地址类别标记单元,与所述比较单元相连接,根据比较单元的比较结果,标记所述地址的类别。
所述地址处理模块还包括:
索引地址匹配单元,与所述地址分段单元和数量统计单元相连接,用于将所述多个地址分段与预设的索引地址匹配表进行比较,确定属于索引地址的地址分段和非索引地址的地址分段;
所述数量统计单元用于统计属于非索引地址的地址分段对应的地理坐标点的数量。
本发明利用k-means聚类算法,准确地确定与地址对应的地理坐标,在保证结果准确度的前提下,通过简洁的处理过程提高了数据处理效率。本发明利用快递员提供的丰富的妥投地址的地理坐标,由多个数据求均值,相对于采集地址的单一数据,减少了数据误差,提高了定位准确度。由于本发明中的妥投地址不仅是城镇地址,还包括很多乡村地址,经过本发明确定了某一地址的坐标后,为后期地图数据的细化提供了丰富而准确的数据。
附图说明
通过以下参照附图对本发明实施例的描述,本发明的上述以及其他 目的、特征和优点将更为清楚,在附图中:
图1为本发明所述基于k-means的妥投地址数据处理方法的流程示意图;
图2为本发明所述基于k-means的妥投地址数据处理系统的结构原理示意图;
图3为本发明所述基于k-means的妥投地址数据处理系统的另一结构原理示意图;
图4为本发明所述地址处理模块的结构原理示意图;
图5为本发明所述最终圆获取模块的结构原理示意图;
图6为本发明所述基于k-means的妥投地址数据处理方法一实施例的流程示意图;
图7为发明所述基于图6所示方法得到的原始数据分布图;
图8为发明所述基于图6所示方法多次聚合后得到的圆及数据分布图;
图9为发明所述基于图6所示方法最终圆及聚合后得到的最终地理坐标分布图;和
图10为发明所述基于图6所示方法得到的最终地理坐标在地图上显示的示意图。
具体实施方式
以下基于实施例对本发明进行描述,但是本发明并不仅仅限于这些实施例。在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。为了避免混淆本发明的实质,公知的方法、过程、流程没有详细叙述。另外附图不一定是按比例绘制的。
附图中的流程图、框图图示了本发明实施例的系统、方法、装置的可能的体系框架、功能和操作,流程图和框图上的方框可以代表一个模块、程序段或仅仅是一段代码,所述模块、程序段和代码都是用来实现规定逻辑功能的可执行指令。也应当注意,所述实现规定逻辑功能的可执行指令可以重新组合,从而生成新的模块和程序段。因此附图的方框 以及方框顺序只是用来更好的图示实施例的过程和步骤,而不应以此作为对发明本身的限制。
如图1所示,为本发明所述基于k-means的妥投地址数据处理方法的流程示意图。如图2所示,为本发明所述基于k-means的妥投地址数据处理系统的结构原理示意图;结合图1和图2对本发明进行说明如下:
本发明提供的基于k-means的妥投地址数据处理系统包括源数据获取模块1,k-means聚类模块2和最终圆获取模块3。其中,所述源数据获取模块1根据提供的地址,获取与所述地址对应的多个妥投地址的地理坐标,形成坐标点群;所述k-means聚类模块2用于根据设定的聚类个数值1,对设定的坐标点群进行聚合,得到一个聚合坐标点,第一次聚合后得到坐标点p1(x1,y1),而后再根据最终圆获取模块3得到的圆的半径内的坐标点进行聚合,得到最终的聚合坐标点,该坐标点即为与所述地址相对应的地理坐标;所述最终圆获取模块3用于根据k-means聚类模块2得到的第一次聚合坐标点p1(x1,y1),得到圆内坐标点的数量大于或等于预设的聚合数量阈值n1的最终圆。
基于图2所示的系统,本发明提供的基于k-means的妥投地址数据处理方法,包括如下步骤:
步骤s1,源数据获取模块获取1给定地址的多个妥投地址的地理坐标,并将所述多个妥投地址的地理坐标作为源数据输入到处理系统中形成坐标点群;
步骤s2,k-means聚类模块2根据k-means聚类算法,设定聚类个数k为1,对所述坐标点群进行第一次聚合,获取第一次聚合坐标点p1(x1,y1);
步骤s3,最终圆获取模块以所述第一次聚合坐标点步骤s1,为圆心作圆,得到圆内坐标点的数量大于或等于预设的聚合数量阈值n1的最终圆;
步骤s4,k-means聚类模块根据k-means聚类算法,设定聚类个数k为1,对最终圆内多个坐标点进行聚合,获取最终聚合坐标点pf(xf,yf)。
本发明利用聚类算法的思想:同一个类簇中的实体是相似的,不同类簇中的实体是不相似的;同一类簇中的任意两点间的距离小于不同类 簇的任意两个点间的距离,对给定地址的多个妥投地址的地理坐标进行聚类。在聚类算法的基础上,分析源数据坐标点,先对数据坐标进行分类去除较远偏离点,再对剩下较精准的坐标点进行聚合,从而提高了最后聚合得到的地理坐标的准确度。
本发明所述的给定地址分为索引地址和末级地址,根据地址类别的不同,在计算时采用不同的参数,以期得到更高准确度的聚合坐标。其中,所述索引地址是指地理区域较大的地址,例如一个只包括省、市、地区的地址,涉及地域范围广。在发明中,具体指如上所述的大地址,且包含的地理坐标的数量大于预定阈值的地址,这样的地址称为索引地址。而涉及用户详细地址,如某小区的某楼、某号房间,涉及的地域范围较窄,对应的地理坐标的数量小于预定阈值,这样的地址称为末级地址。因而,对应于索引地址,会有较多数量的地理坐标与之相对应,而对应于末级地址,对应的妥投地理坐标的数量会比较少。根据概率论中的概率正态分布,对应于索引地址的地理坐标,概率小于等于3%-5%的为小概率事件,出现频率很低,一般不会发生,可以忽略。而对应于末级地址的地理坐标,分布相对集中,一般70%-80%集中分布的坐标点即可代表该地址的坐标。因而,对应于索引地理坐标,取源数据量的95%-97%作为聚合数量的参考阈值,对应于末级地理坐标,取源数据量的70%-80%作为聚合数量的参考阈值。
因而,本发明所述的系统还包括地址类别判断模块4。如果在本系统之前对用户地址已进行处理,即已将用户地址区分为索引地址和末级地址,则会在所述地址中设置有标识位,如0表示索引地址,1表示末级地址,通过读取该标识位,可以判断所述地址是索引地址,还是末级地址。
如果在进行本发明所述方法之前,没有对所述地址进行处理,则本发明还包括地址处理模块5具体,如图3所示,用于将用户地址拆分为索引地址和末级地址,并增加上相应的标识以供所述地址类别判断模块4进行识别。
具体地,所述地址处理模块5如图4所示,包括:地址分段单元51、数量统计单元52、比较单元53和地址类别标记单元54。
其中,所述地址分段单元51用于将所述地址按地理区域从大到小进行分段处理,形成多个地址分段。如省地址分段、市地址分段、区地越分段、街道地址分段、街道号地址分段、小区地址分段、楼号地址分段、房间号地址分段等,在进行分段处理时,还包括地址的除杂处理,例如,去掉地址中的括号、空格等符号。
所述数量统计单元52与所述地址分段单元51相连接,用于统计各个地址分段对应的地理坐标点的数量。
所述比较单元53与所述数量统计单元52相连接,用于比较各个地址分段对应的地理坐标点的数量与预定阈值。关于本发明中设定的参考阈值,可根据实际情况,通过多次试验获得。例如,为确定一个阈值的具体数值,经过多次反复的设置、运行,然后对比、分析运行结果,从而确定出合适的数值。通常来说,在源数据的数据量较小时,设定较小的阈值,当源数据的数据量积累到足够大时,则需要增大所述阈值。例如,在地址处理模块5处理的一批地址中,对于大部分地址,(例如总量的70%以上),每一个地址对应着的妥投地址的数据量为50-100时,可将阈值设为50。
当地址分段对应的地理坐标点的数量大于该参考阈值,则认为该地址是索引地址,如果某个地址分段对应的地理坐标点的数量小于该参考阈值,同时当前地址分段的上一个地址分段对应的地理坐标点的数量大于或等于所述预定阈值时,则从所述当前地址分段开始到末端地址分段为末级地址,从首地址分段到当前地址分段的上一个地址分段为索引地址。因而,当将所述比较的结果发送给所述地址类别标记单元54后,所述地址类别标记单元54根据比较单元53的比较结果,对确定出的末级地址和索引地址进行标记,如0表示索引地址,1表示末级地址。
更好地,为了加快处理进度,对于一些明显的地址分段,系统内设置有索引地址匹配表,在将地址分段后、统计各个地址分段对应的地理坐标点的数量之前,先进行索引地址匹配,从而得到属于索引地址的地址分段和非索引地址的地址分段,对于非索引地址的地址分段,统计各处地址分段对应的地理坐标点的数量,然后与参数阈值进行比较,从而确定当前的非索引地址的地址分段中是否有可以划分到索引地址的地址 分段。通过地址处理模块5,将用户地址分为索引地址和末级地址,并对其做出标记,以供地址类别判断模块4进行识别,在后续计算中采用不同的计算参数。
如图5所示,为本发明中所述最终圆获取模块3的结构原理示意图。所述最终圆获取模块3包括首次圆获取单元31、校正圆获取单元32、统计单元33和比较单元34。
其中,所述首次圆获取单元31与所述k-means聚类模块2和所述源数据获取模块1相连接,用于根据所述k-means聚类模块2得到的第一次聚合坐标点p1,以所述坐标点p1(x1,y1)为圆心,以从所述源数据获取模块1得到的所有坐标点到所述圆心p1(x1,y1)的平均距离r1为半径,得到首次圆;
所述校正圆获取单元32分别与所述首次圆获取单元31、所述地址类别判断模块1和比较单元34相连接,根据所述比较单元34输出的重新计算通知,以公式1-1得到的校正半径,以所述坐标点p1(x1,y1)为圆心得到校正圆,或者根据所述比较单元4输出的合格通知,将半径为r1的圆确定为最终圆;
ri+1=ri+(dmax-ddev)/β1-1
其中,ri为当前圆的半径,i=1,2,3……k,k为自然数,dmax、ddev分别是当前圆内所有坐标点到圆心p1(x1,y1)的最大值和平均值,β为权值,按二分法或四分法增大圆半径。索引地址下坐标数据量一般较多,而且涉及地域范围广,以二分法扩大圆半径,末级地址涉及用户的详细地址,地域范围涉及较窄,坐标数据较少,则以四分法扩大圆半径。根据所述地址类别判断模块,在所述地址为索引地址时,β=2;在所述地址为末级地址时,β=4。这是因为索引坐标涉及区域范围大,数据点分布较远,因此将分母设置较小,圆半径每次变化间距变大;对于末级地址,则相反,末级地址范围小,数据点分布较密,所以可以将分母设置大些。当然,所述β的值也可以取其他值,在本实施例中,从工程角度出发,通常以二分法或四分法进行计算。
所述统计单元33与所述首次圆获取单元31和校正圆获取单元32相连接,用于统计首次圆和校正圆内的坐标点数量,并将统计的结果发 送给所述比较单元34。
所述比较单元34与所述统计单元33相连接,用于对首次圆和校正圆内的坐标点数量分别与聚合数量阈值n1相比较,如果圆内坐标点的数量小于预设的聚合数量阈值n1,向所述校正圆获取单元发送重新计算通知,如果圆内坐标点的数量大于或等于预设的聚合数量阈值n1,则向所述校正圆获取单元发送合格通知。
另外,在对所述坐标点群进行第一次聚合之前,需要判断所述源数据的数量是否大于或等于预定的数量阈值,即判断是否具有足够多的坐标用于聚合。如果所述源数据的数量大于或等于预定的数量阈值,例如40-50,对所述坐标点群进行第一次聚合,如果小于所述的预定的数量阈值,则不做任何处理。其中,所述的数量阈值视情况可以设置不同的具体数值。
以下通过具体实施例对本发明进行详细地说明。
例如,对于一条详细地址:上海浦东新区城区世纪大道1589号(索引地址)+长泰国际金融大厦2009室(末级地址)。根据本发明所述方法得到精确地理坐标的过程如图6所示,具体如下:
步骤s1a,获取给定地址“长泰国际金融大厦2009室”的多个妥投地址的地理坐标,如图7所示,共有200个,并将所述多个妥投地址的地理坐标作为源数据输入到数据处理系统中形成坐标点群。
步骤s2a,判断所述坐标点群中坐标点的数量是否大于或等于设定的数量阈值(如50),如果小于,则不做处理,如果坐标点的数量是否大于或等于设定的数量阈值,则进行下一步。
步骤s3a,调用k-means聚类算法,将聚类个数设置为1。
步骤s4a,对所述坐标点群进行第一次聚合,获取第一次聚合坐标点p1(x1,y1)。
步骤s5a,计算所有坐标点到所述圆心p1(x1,y1)的距离,并求得平均距离ddev和最大距离dmax。
步骤s6a,以第一次聚合坐标点p1(x1,y1)为圆心,以平均距离ddev作为半径作圆;并统计圆内坐标点的数量n当前。
步骤s7a,判断所述地址是索引地址还是末级地址,如果是索引地 址,在步骤s8a,取n1=n*λ=n*95%,β=2;如果是末级地址,在步骤s9a,取n1=n*λ=n*70%,β=4;在本实施例中,由于所述地址为末级地址,则取n1=n*λ=n*70%,β=4。
步骤s10a,判断圆内坐标点的数量n当前是否大于或等于n1,如果n当前大于或等于n1,则认为当前圆合格,在步骤s11a,对圆内多个坐标点进行聚合,获取最终聚合坐标点pf(xf,yf),并作为所述地址的地理坐标输出,如图10所示。
如果n当前小于n1,则认为当前圆不合格,则在步骤s12a,根据公式ri+1=ri+(dmax-ddev)/β重新计算圆的半径,并返回步骤s6a重新做圆,如图8所示。重新判断所述当前圆内的坐标点数量是否符合要求,直到得到合格的最终圆,即圆内坐标点的数量n当前是否大于或等于n1,如图9所示。
从上述流程及附图可见,本发明利用k-means聚类算法,准确地确定出一个给定地址的地理坐标,在保证结果准确度的前提下,通过简洁的处理过程提高了数据处理效率。本发明利用快递员提供的丰富的妥投地理坐标,由多个数据求均值,相对于采集地址的单一数据,减少了因为信号差、人为等因素造成的位置误差,提高了地理位置定位的准确度。并且,由于本发明中的妥投地址不只是城镇地址,还可以是很多乡村地址,经过本发明确定某一给定地址的地理坐标后,为后期地图数据的细化提供了丰富而准确的数据。
依照本发明的实施例如上文所述,这些实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施例。显然,根据以上描述,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地利用本发明以及在本发明基础上的修改使用。本发明的保护范围应当以本发明权利要求所界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!