碳纤维原丝生产过程中牵伸环节性能指标的预测方法与流程
本发明属碳纤维智能生产预测技术领域,涉及一种碳纤维原丝生产过程中牵伸环节性能指标的预测方法,具体地说是基于幂律法则改进的PSO优化LS-SVM的碳纤维原丝生产过程中牵伸环节预测方法。
背景技术:
碳纤维是一种含碳量在95%以上的高强度、高模量纤维的新型纤维材料。因其密度低,比性能高,无蠕变,非氧化环境下耐超高温,耐疲劳性好,热膨胀系数小,耐腐蚀性好,导电导热性能好、电磁屏蔽性好,广泛应用于国防军工和民用方面。
碳纤维原丝生产过程主要包括聚合、脱泡、计量、喷丝、牵引、水洗、上油、烘干和收丝等工序,其中,牵伸是提高碳纤维物理与机械性能不可或缺的手段。初生纤维的牵伸可以一次完成,也可以分级完成,一般来说为使牵伸后的纤维物理分布均匀并具有较高牵伸倍数,牵伸过程多设为多级牵伸的模式,这里以六级牵伸过程为例。在牵伸过程,对碳纤维原丝产品质量影响最大的莫过于各级牵伸比,即使总牵伸比一样,各级牵伸比的设定稍有偏差,生产出的碳纤维原丝的性能指标也有很大的不同。
目前在碳纤维原丝生产的生产线上,各级牵伸比与产品性能指标之间的对应关系往往凭借生产经验,缺乏相关的理论指导,不足以满足智能生产的需求。因此迫切需要一种预测方法,勿需在线调试,即可根据设定的牵伸比预测出产品的性能指标,对其实际生产具有一定的指导作用。
技术实现要素:
本发明所要解决的技术问题是针对目前碳纤维原丝生产过程中,各级牵伸比与产品性能指标之间的对应关系往往凭借生产经验,缺乏相关的理论指导,在线调试需要生产线停产并进行多次生产模拟,会带来较大的经济损失等情况,提出一种碳纤维原丝生产过程中牵伸环节性能指标的预测方法,具体地说是基于幂律法则改进的PSO优化LS-SVM的碳纤维原丝生产过程中牵伸环节预测方法。
本发明的碳纤维原丝生产过程中牵伸环节性能指标的预测方法,为基于幂律法则改进的PSO优化的LS-SVM的碳纤维原丝生产过程中牵伸环节预测方法,包括以下步骤:
(1)将碳纤维原丝生产过程中牵伸环节的各级牵伸比作为特征信息,建立输入样本数据集,并对特征信息进行线性函数归一化处理,完成特征信息的预处理,并组成特征向量矩阵R’;
(2)建立影响碳纤维质量的主要性能指标的输出样本数据集,并对性能指标进行对数函数归一化处理,完成对性能指标的预处理,并建立输出样本数据集矩阵Y’;
(3)将所述特征向量和所述输出样本数据集矩阵使用基于幂律法则改进的PSO优化LS-SVM建立模型并实现预测功能;
所述基于幂律法则改进的PSO优化是指:根据LS-SVM建立输入特征向量和输出样本数据集矩阵之间的预测模型时,需要依据训练集采用PSO对LS-SVM的惩罚因子C和RBF核函数的参数σ进行优化,在PSO寻优过程中,将全部粒子按适应度值的大小进行排序,将适应度差的粒子直接淘汰,在适应度好的20%的粒子所围成的区域中随机生成粒子,作为淘汰粒子的替换粒子;从而可以加快PSO优化惩罚因子C和RBF核函数的参数σ的值的速度,进而建立预测模型。
作为优选的技术方案:
如上所述的碳纤维原丝生产过程中牵伸环节性能指标的预测方法,所述建立输入样本数据集矩阵具体为:
一组输入样本数据包括牵伸环节的各级牵伸比r,将其构成一组输入数据样本为[r1 r2 … rm],因此n组输入构成的输入样本数据集矩阵R为:
将输入样本数据集矩阵R进行线性函数归一化,所述线性函数归一化处理的转换公式为:
rij'=(rij-rjmin)/(rjmax-rjmin);
其中,i=1,2,…,n,j=1,2,…,m,n为输入样本组数量,m为牵伸级数;
rij为输入样本数据集的各级原始牵伸比;
rjmin和rjmax分别为r1j,r2j,…,rnj中的最小值和最大值;
rij’为归一化后的各级牵伸比;
对线性函数归一化后的输入样本数据集矩阵即为特征向量矩阵R':
如上所述的碳纤维原丝生产过程中牵伸环节性能指标的预测方法,其特征在于,建立与输入样本数据集一一对应的输出样本数据集,一一对应是指有一组输入,就要有对应这组输入的一组输出;所述建立输出样本数据集矩阵具体为:
一组输出样本数据包括与牵伸环节相关的碳纤维原丝的性能指标y;将其构成一组输出数据样本为[y1 y2 … yk],因此n组输入构成的输出样本数据集矩阵Y为:
将输出样本数据集矩阵Y进行对数函数归一化,所述对数函数归一化处理的转换公式为:
yij'=lg(yij);
其中,i=1,2,…,n,j=1,2,…,k,n为输出样本组数量;k为不同的性能指标数量;
yij’为归一化后的性能指标;yij为输出样本数据集的性能指标;
输出样本数据集矩阵Y’为:
如上所述的碳纤维原丝生产过程中牵伸环节性能指标的预测方法,所述步骤(3)使用LS-SVM建立模型的具体步骤为:
将所述特征向量矩阵R’作为LS-SVM的输入样本矩阵,将所述输出样本数据集矩阵Y’作为LS-SVM的输出样本矩阵,使用LS-SVM建立模型;
采用基于幂律法则改进的PSO计算惩罚因子C和RBF核函数的参数σ的值,建立模型;
基于幂律法则改进PSO具体为:
PSO中的粒子在指定的2维空间中搜索,第1维代表参数C,第2维代表参数σ,寻找最佳的C和σ参数组合;PSO每次寻优过程中,更新粒子的速度与位置,依据位置信息计算各粒子的适应度值并根据适应度的大小进行排序,在下一次寻优过程中,全部粒子向着适应度最好的粒子的位置移动;算法适应度函数代表预测值与真值间绝对误差的总和,粒子适应度值f的计算公式为:
其中,n为输出样本组数量,yi为第n组性能指标的真实值,为第n组性能指标的预测值;
适应度值越低表示粒子适应度越好;在单次搜索过程中,粒子适应度好并不能代表搜寻到的C和σ为全局最优解,但适应度差的粒子一定不是最优解;根据达尔文提出的优胜劣汰学说,可以将适应度差的粒子直接淘汰,并另外生成粒子作为淘汰粒子的替换粒子。因此,可以将全部粒子按适应度值从小到大进行排序,将适应度差的粒子直接淘汰,并另外生成粒子予以补全;
依据幂律法则,适应度最好的20%的粒子所围成的区域产生优秀粒子的可能性远远大于其他地方的粒子;所述基于幂律法则改进的PSO是指将全部粒子按适应度值的大小进行排序,将适应度差的粒子直接淘汰,在适应度好的20%的粒子所围成的区域中随机生成粒子,作为淘汰粒子的替换粒子。
如上所述的碳纤维原丝生产过程中牵伸环节性能指标的预测方法,其特征在于,所述输入样本组数量n为300~1000。
如上所述的碳纤维原丝生产过程中牵伸环节性能指标的预测方法,其特征在于,牵伸环节的牵伸级数m为1~8级。
如上所述的碳纤维原丝生产过程中牵伸环节性能指标的预测方法,其特征在于,牵伸环节为6级牵伸,分别为空气牵伸、凝固浴牵伸、热水牵伸、沸水牵伸、干热牵伸和蒸汽牵伸。
如上所述的碳纤维原丝生产过程中牵伸环节性能指标的预测方法,其特征在于,影响碳纤维质量的不同的性能指标数量k为1~5个。
如上所述的碳纤维原丝生产过程中牵伸环节性能指标的预测方法,其特征在于,影响碳纤维质量的性能指标为线密度、原丝强度和断裂伸长率。
如上所述的碳纤维原丝生产过程中牵伸环节性能指标的预测方法,其特征在于,为保证粒子多样化,不陷入局部最优解,将适应度差的粒子直接淘汰是指淘汰全部粒子总数的20~50%。
本发明以LS-SVM回归预测为手段,采用PSO对LS-SVM参数进行优化,在传统的PSO优化LS-SVM参数的回归预测方法中,引入优胜劣汰原理,将适应度差的粒子进行淘汰,并依据幂律法则对PSO的寻优过程进行改进,生成淘汰粒子的替换粒子。本发明明显优于众多用于智能预测的智能算法中,LS-SVM以风险最小化为原则,将损失函数直接定义为误差平方和,将优化中的不等式约束转化为等式约束,降低了计算复杂性,加快了求解速度。使用PSO并结合训练样本矩阵优化LS-SVM的参数,可以得出较好的参数C和σ。本发明将幂律法则思想运用在PSO优化LS-SVM进行预测的方法中,提出一种碳纤维原丝生产过程牵伸环节性能指标的预测方法。同时,本发明对PSO寻优过程中粒子的筛选与替换进行了一定的改进。
有益效果
本发明的上述技术方案相比现有技术具有以下优点:
本发明所述的基于幂律法则改进的PSO优化LS-SVM预测性能指标的方法,将幂律法则和PSO优化LS-SVM引入到性能指标的预测过程中,不仅实现了对性能指标的精确预测,还提高了预测精度,节省了时间。
附图说明
图1是预测方法结构框图
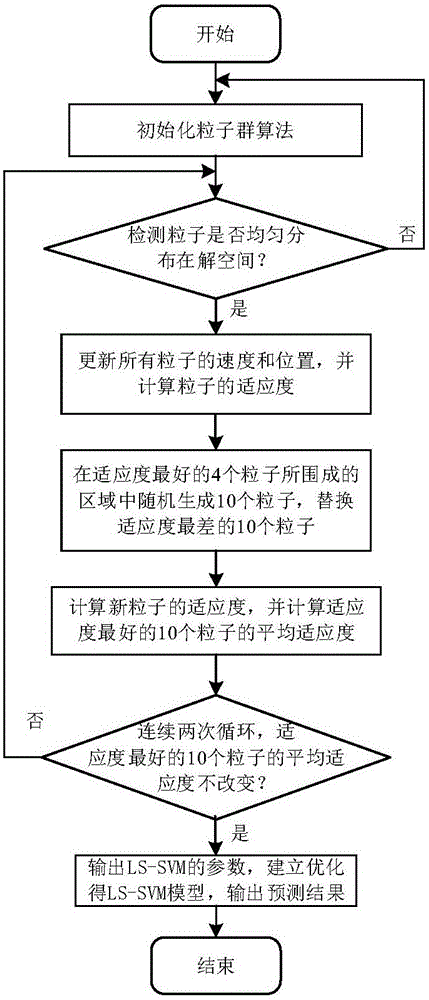
图2是预测方法流程图
图3是预测结果验证图
(a)线密度预测结果(b)原丝强度预测结果(c)断裂伸长率预测结果
图4是预测误差结果对比图
(a)线密度预测误差结果(b)原丝强度预测误差结果(c)断裂伸长率预测误差结果
图5是预测方法适应度函数值结果图
具体实施方式
下面结合具体实施方式,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
本发明的碳纤维原丝生产过程中牵伸环节性能指标的预测方法,为基于幂律法则改进的PSO优化LS-SVM的碳纤维原丝生产过程中牵伸环节预测方法,预测方法结构框图见图1,图2是预测方法流程图,包括以下步骤:
(1)将碳纤维原丝生产过程中牵伸环节的牵伸比作为特征信息,建立输入样本数据集,并对特征信息进行线性函数归一化处理,完成特征信息的预处理,并组成特征向量矩阵R’;
(2)建立影响碳纤维质量的主要性能指标的输出样本数据集,并对性能指标进行对数函数归一化处理,完成对性能指标的预处理,并建立输出样本数据集矩阵Y’;
(3)将所述特征向量和所述输出样本数据集矩阵使用基于幂律法则改进的PSO优化LS-SVM建立模型并实现预测功能;
所述基于幂律法则改进的PSO优化是指:将全部粒子按适应度值的大小进行排序,将适应度差的粒子直接淘汰,在适应度好的20%的粒子所围成的区域中随机生成粒子,作为淘汰粒子的替换粒子;从而可以加快PSO计算惩罚因子C和径向基核函数的参数σ的值的速度,进而建立预测模型。
所述建立输入样本数据集具体为:
一组输入样本数据包括牵伸环节的各级牵伸比r,将其构成一组输入数据样本为[r1 r2 … rm],因此n组输入构成的输入样本数据集矩阵R为:
将输入样本数据集矩阵R进行线性函数归一化,所述线性函数归一化处理的转换公式为:
rij'=(rij-rjmin)/(rjmax-rjmin);
其中,i=1,2,…,n,j=1,2,…,m,n为输入样本组数量,m为牵伸级数;
rij为输入样本数据集的各级原始牵伸比;
rjmin和rjmax分别为r1j,r2j,…,rnj中的最小值和最大值;
rij’为归一化后的各级牵伸比;
对线性函数归一化后的输入样本数据集矩阵即为特征向量矩阵R':
如上所述的碳纤维原丝生产过程中牵伸环节性能指标的预测方法,建立与输入样本数据集一一对应的输出样本数据集,一一对应是指有一组输入,就要有相应的一组输出;所述建立输出样本数据集矩阵具体为:
一组输出样本数据包括与牵伸环节相关的碳纤维原丝的性能指标y;将其构成一组输出数据样本为[y1 y2 … yk],因此n组输入构成的输出样本数据集矩阵Y为:
将输出样本数据集矩阵Y进行对数函数归一化,所述对数函数归一化处理的转换公式为:
yij'=lg(yij);
其中,i=1,2,…,n,j=1,2,…,k,n为输出样本组数量;k为不同的性能指标数量;
yij'为归一化后的性能指标;yij为输出样本数据集的性能指标;
输出样本数据集矩阵Y’为:
所述步骤(3)使用LS-SVM算法建立模型的具体步骤为:
将所述特征向量矩阵R’作为LS-SVM的输入样本矩阵输入,将所述输出样本数据集矩阵Y’作为LS-SVM的输出样本矩阵输入,使用LS-SVM算法建立模型;
采用基于幂律法则改进的PSO优化惩罚因子C和径向基核函数的参数σ的值,建立模型;
假设训练集T由n个样本点组成,T={(x1,y1),(x2,y2),…,(xn,yn)},其中,xi∈Rn是输入向量,yi∈R是相应于xi的输出。对样本数据进行非线性回归时,通过非线性映射Φ(x)将样本数据映射到高维特征空间,在高维特征空间进行线性回归,回归预测模型表达式为:
f(x)=ω·Φ(x)+b
其中,ω表示权值向量,b表示偏置量。LS-SVM以风险最小化为原则,在优化目标中选择了平方损失函数作为损失函数。因此,优化问题变为:
其中,ξi表示误差项,C表示惩罚因子,且C>0,表示对超出误差的样本的惩罚程度。引入拉格朗日函数求解该优化问题如下:
上式中,α表示拉格朗日乘子。根据KKT条件得:
根据Mercer条件,利用核函数,得到LS-SVM的回归预测模型表达式为:
其中,径向基核函数为:LS-SVM的预测精度与其惩罚因子C,径向基核函数参数σ的选取有很大关系。
σ精确定义了高维特征空间的结构,因而控制了最终解的复杂性。σ小意味着核更易局部化,有过训练的危险,σ大则容易造成欠训练。参数C控制机器复杂性和不可分离点数之间的平衡;通常被称为“正则化”参数的倒数。C取得过小,则对样本数据中超出样本的惩罚就小,使训练误差变大,机器学习的推广能力有所提高;C若取得过大,相应的惩罚就过大,学习机器的训练误差变小,推广能力变差。因此,需采取智能算法对LS-SVM各参数进行优化选取,以获得具有良好预测性能的LS-SVM。
所述步骤(3)采用PSO优化LS-SVM算法具体为:
按照如下PSO计算参数C和σ的值,设置初始粒子群数为20,目标搜索空间维数设置为2维,以预测值与真值间的最小绝对误差作为目标函数,在粒子找到个体极值和全局极值时,根据以下方程调整速度与位置:
vid(t+1)=ωvid(t)+η1rand()(pid-xid(t))+η2rand()(pgd-xid(t))
xid(t+1)=xid(t)+vid(t+1)
式中,vid(t+1)表示第i个粒子在t+1次迭代中第d维上的速度,xid(t+1)表示第i个粒子在t+1次迭代中第d维上的位置,vid(t)表示第i个粒子在t次迭代中第d维上的速度,xid(t) 表示第i个粒子在t次迭代中第d维上的位置,pid表示第i个粒子在第d维上搜索到的最优解,pgd表示第全部粒子在第d维上搜索到的最优解,ω为惯性权重,η1、η2为加速常数,设置η1=η2=2,rand()为0~1之间的随机数。此外,为使粒子速度不致过大,可设置速度上限vmax和速度下线vmin,即在速度调整公式中,vid(t+1)>vmax时,vid(t+1)=vmax;vid(t+1)<vmin,vid(t+1)=vmin;同样,为使粒子位置不超出指定范围,可设置位置边界xmax和xmin,即在粒子位置调整公式中,xid(t+1)>xmax时,xid(t+1)=xmax;xid(t+1)<xmin,xid(t+1)=xmin。
基于幂律法则改进PSO具体为:
PSO中的粒子在指定的2维空间内搜索,寻找最佳的C和σ;每一次寻优过程中,更新粒子的速度与位置,依据位置信息计算各粒子的适应度值并根据适应度的大小进行排序,在下一次寻优过程中,全部粒子向着适应度最好的粒子的位置移动;算法适应度函数代表预测值与真值间绝对误差的总和,粒子适应度值f的计算公式为:
其中,n为输出样本组数量,yi为第n组性能指标的真实值,为第n组性能指标的预测值;
适应度值越低表示粒子适应度越好;在单次搜索过程中,粒子适应度好并不能代表搜寻到的C和σ为全局最优解,但适应度差的粒子一定不是最优解;根据达尔文提出的优胜劣汰学说,可以将适应度差的粒子直接淘汰,并另外生成粒子作为淘汰粒子的替换粒子。因此,可以将全部粒子按适应度值从小到大进行排序,将适应度差的粒子直接淘汰,并另外生成粒子予以补全;
依据幂律法则,适应度最好的20%的粒子所围成的区域产生优秀粒子的可能性远远大于其他地方的粒子;所述基于幂律法则改进的PSO是指将全部粒子按适应度值的大小进行排序,将适应度差的粒子直接淘汰,在适应度好的20%的粒子所围成的区域中随机生成粒子,作为淘汰粒子的替换粒子。
所述输入样本组数量n为300~1000。
牵伸环节的牵伸级数m为1~8级。
牵伸环节为6级牵伸,分别为空气牵伸、凝固浴牵伸、热水牵伸、沸水牵伸、干热牵伸和蒸汽牵伸。
影响碳纤维质量的不同的性能指标数量k为1~5个。
影响碳纤维质量的性能指标为线密度、原丝强度和断裂伸长率。
将适应度差的粒子直接淘汰是指淘汰全部粒子总数的20~50%。
实施例1
为了验证改进的预测方法的有效性,根据500组输入输出样本数据,对预测方法进行检验。将样本数据按照8:2的比例分为训练样本和测试样本,即训练样本为400组数据,测试样本为100组数据。PSO中,选取粒子个数为20个,每个粒子2维,分别代表需要优化的惩罚因子C和核函数参数σ。本例基于幂律法则改进PSO寻优过程中,淘汰粒子的50%,在适应度最好的20%的粒子所围成的区域中随机生成10个粒子作为淘汰粒子的替换粒子。程序截止条件为:连续两次寻优得到的函数平均适应度值不变。并采用传统PSO优化LS-SVM和PSO优化LS-SVM算法中随机生成淘汰粒子的替换粒子算法进行对比。
实验预测结果对比图如图3所示,(a)线密度预测结果(b)原丝强度预测结果(c)断裂伸长率预测结果;实验预测误差结果对比图如图4所示,(a)线密度预测误差结果(b)原丝强度预测误差结果(c)断裂伸长率预测误差结果。从图中可以看出,预测方法可以较准确地预测出性能指标。预测方法适应度函数结果图如图5所示,且不淘汰粒子方法(以下简称传统算法)运行时间为933.4730s,方法适应度值为0.0128;随机生成替换粒子方法(以下简称对比算法)运行时间为916.6630s,方法适应度值为0.0115;本发明所提出的方法(以下简称改进算法)运行时间为678.9920s,方法适应度值为0.0113。实验结果表明,本发明所提方法不仅可以准确预测,而且可以节约时间,证明该方法有效。
- 还没有人留言评论。精彩留言会获得点赞!