一种ARN数据库平台及其分析构建科学假说的方法与流程
本发明属于数据库管理技术领域,涉及一种在线的构建科学假说的方法,尤其涉及一种与调控脂肪生成相关的ARN数据库平台及其分析构建科学假说的方法。
背景技术:
如今的大多数科学研究都用到了数据库,例如NCBI,miRBase,TRRUST,PAZAR,BioGRID,miRGate等等,这些数据库包含某一领域的丰富的信息,为科研人员提供检索功能。但是这些数据库提供的检索功能很多是针对文档的,而非针对内容的检索,因此检索结果间彼此互不相关,很难让科研人员对某一主题进行深入分析,并很快的形成科学假说。
一个研究者要想通过传统的方式提取到需要的信息,就必须面临如下挑战:在阅读大量文献和通过数据库查询信息的过程中,花费大量时间,并且错失掉大量有用信息,以2013年为例,平均每天大概需要阅读3篇新文章。其次,不同研究者提取信息过程中,也出现了大量的重复性劳动。
传统的构建科学假说的方法认为,在两个独立的研究领域存在互补但脱节的(CBD)研究成果,如果我们能发现他们,就可能形成有价值的新的假说。在生物医学的文献中,存在着许多未被发掘的重要联系。CBD的应用策略是基于共同出现就可能具有相关性,使用者需要在系统提供的多种选择中选择相关的,从而发现新的联系。但由于科研人员掌握的文献数量非常有限,大大限制了此方法的运用。
综上所述,现有的专业数据库有下述缺陷:
1、检索结果碎片化,导致科研人员提取信息的过程耗时耗力,且有大量的重复性劳动。
2、个人能够掌握的文献的数量,大大限制了构建科学假说的方法的使用。
因此,如何利用专业的数据库平台,使得科研人员能够轻松检索到结构清晰、互相关联的专业信息,并易于实现对数据的更新,并且能够用于对科研数据的分析、构建和初步评价科学假说一直是申请人研究的课题之一。
技术实现要素:
针对上述现有技术存在的缺陷或不足,本发明的目的在于,提供一种ARN数据库平台及其分析构建科学假说的方法。
为了实现上述任务,本发明采取如下的技术解决方案:
一种ARN数据库平台,其特征在于,包括ARN数据库展现单元以及互相连接的ARN数据库修改单元和数据定义语句DDS转换单元;ARN数据库展现单元与后台数据库和前台ARN显示界面相连接,ARN数据库修改单元与前台ARN显示界面相连接,DDS转换单元与后台数据库相连接;其中:
所述ARN数据库展现单元,用于从后台数据库中读取数据库的库表结构,并将所读取的数据库的库表结构发送到前台ARN显示界面显示;该ARN数据库展现单元提供基本的检索功能和通过分析构建科学假说的功能;
所述ARN数据库修改单元,用于通过ARN显示界面提供一个易于操作的可视化数据库修改页面,并将从ARN显示界面接收到的数据库修改信息发送到所述DDS转换单元;
所述DDS转换单元根据预先设定的转换关系表将接收自所述ARN数据库修改单元的数据库修改信息转换成能够在后台数据库中执行的数据库操作语句,并将转换得到的数据库操作语句发送到后台数据库中执行;
所述ARN数据库存储的信息来自对脂肪生成相关科学文献的文本挖掘、人工检查和整理以及对外部数据库数据的整合。
上述ARN数据库平台分析构建科学假说的方法,其特征在于,该方法以ARN数据库平台为基础,将调控因子的相关信息存储于数据库中,以调控因子的各项特征为筛选条件,首先根据用户的条件设置,筛选出满足特定条件的结果集;再依据“基于文献的科学假说构建方法”,按照“开放的”和“闭合的”两种假说构建过程,构建出符合特定条件的科学假说;
所述的“基于文献的科学假说构建方法”是,如果文献1提到A影响B,文献2提到B影响C,研究人员可以构建假说:A影响C;文献1和文献2的内容间存在交叉和脱节两个特征;
所述的“开放的”假说构建过程为:
如果第一步从ARN数据库平台中筛选到B1,B2,B3,B4,……,Bn一系列影响脂肪生成A的调控因子,第二步从数据库中筛选到C1,C2,C3,C4,……,Cn一系列影响B的调控因子,第三步就可以构建科学假说C1,C2,C3,C4,……,Cn影响脂肪生成A。
所述的“闭合的”假说构建过程为:
如果第一步从ARN数据库平台中筛选到B1,B2,B3一系列影响脂肪生成A的调控因子,第二步从数据库中筛选到B3,B4,B5一系列调控因子受调控因子C调控,第三步就可以构建科学假说调控因子C通过B3影响脂肪生成A。
在进行调控因子的筛选时,根据使用者不同的分析需求,设计三种筛选方式:即节点筛选、表达特征筛选和自定义节点集筛选。
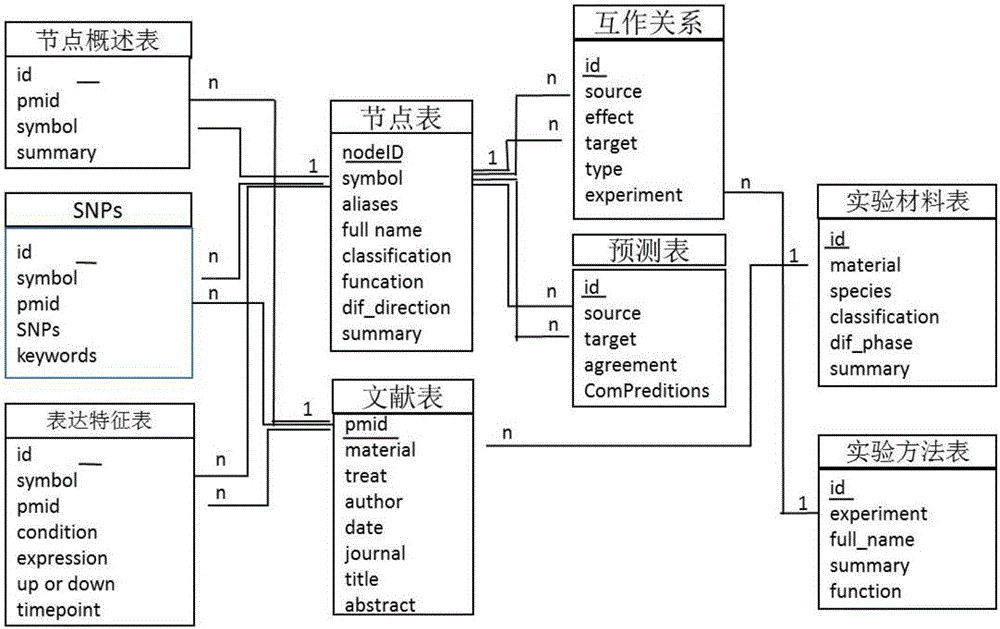
所述的ARN数据库平台包含了通过对脂肪生成相关文献的文本挖掘获得的3万多条相关数据,这些相关数据由9个数据库表组成,它们是:节点表、文献表、概述表、SNPs表、表达特征表、实验材料表、实验方法表、关系表和预测表。
进一步的,所述的节点筛选方式是根据节点的名称、Gene ID、类别、功能、对脂肪生成的影响对数据库中的调控分子进行初步筛选,并根据节点间的作用方向对数据库中的调控分子进行二次筛选。
所述的表达特征筛选方式是根据相关文献的PMID号、在脂肪生成相关过程中的表达变化、观察时间点等对数据库中的调控分子进行初步筛选,并根据节点间的作用方向对数据库中的调控分子进行二次筛选。
所述的自定义筛选方式是允许用户根据自身的分析需求,录入一个节点集,并据节点间的作用方向,对数据库中的调控分子进行筛选。
所述的二次筛选是用户根据分析需求,有以下五项选择:不进行二次筛选、筛选目标节点的源节点、筛选目标节点的靶节点、筛选目标节点的预测源节点和筛选目标节点的预测靶节点;其中,源节点代表该节点参与调控目标节点;靶节点代表该节点被目标节点调控;预测源节点代表该节点可能参与调控目标节点;预测靶节点代表该节点可能被目标节点调控。
本发明的ARN数据库平台,将数据库技术与基于文献的科学假说建立方法相结合,充分发挥了数据库对于数据的强大储存和整合功能,通过将来自文本挖掘的文献信息进行重组和可视化显示,有效的避免了检索结果的碎片化,为科研人员提供了一种脂肪生成分子调控信息的综合检索平台;ARN数据库平台弥补了传统的基于文献构建科学假说的方法在文献数量上的缺陷,为科研人员提供了一种快速分析数据和形成科学假说的工具。赋予了基于文献的科学假说建立方法充分的灵活性,为脂肪生成相关基因和通路的发现提供帮助。同时,也可为其他专业数据库的开发利用提供参考依据。
附图说明
图1是本发明的ARN数据库的构建过程示意图;
图2是ARN数据库的表结构;
图3是基于ARN数据库的科学假说构建方法原理示意图;
图4是ARN数据库的分析工具。
下面结合附图和实施例,对本发明作进一步详细描述。
具体实施方式
本实施例给出一种ARN数据库平台(URL:http://210.27.80.93/arn/),该ARN数据库平台包括:ARN数据库展现单元以及互相连接的ARN数据库修改单元和数据定义语句DDS转换单元;ARN数据库展现单元与后台数据库和前台ARN显示界面相连接;ARN数据库修改单元与前台ARN显示界面相连接;DDS转换单元与后台数据库相连接;其中:
ARN数据库展现单元,用于从后台数据库中读取数据库的库表结构,并将所读取的数据库的库表结构发送到前台ARN显示界面显示;该ARN数据库展现单元提供基本的检索功能和通过分析构建科学假说的功能。
ARN数据库修改单元,用于通过ARN显示界面提供一个易于操作的可视化数据库修改页面,并将从ARN显示界面接收到的数据库修改信息发送到所述DDS转换单元;
DDS转换单元根据预先设定的转换关系表将接收自ARN数据库修改单元的数据库修改信息转换成能够在后台数据库中执行的数据库操作语句,并将转换得到的数据库操作语句发送到后台数据库中执行;
ARN数据库存储的信息来自对脂肪生成相关科学文献的文本挖掘、人工检查和整理以及对外部数据库数据的整合。
基于数据库的科学假说构建方法包括信息数据库的构建和分析工具设计,它的性能取决于信息数据库的数据的数量和质量。本实施例使用的文本挖掘方法保障了数据的数量,人工的检查和数据清洗保障了数据的质量。信息收集过程中对脂肪生成相关科学文献的文本挖掘是借助Cytoscape(3.2.1)软件平台的Agilent Literature Search文献检索插件,首先将检索得到的文献拆分成单个的句子,再根据基因数据库(Entrez Gene)的基因名称或别名(概念名词),或者特定的关系词(通常是动词)如“binding”或“activate”进行分析,如果在一个句子中同时存在至少两个概念名词和一个关系动词,那么它就会被转换成一条互作记录,并加入到Cytoscape(3.2.1)软件平台的互作网络当中。
信息收集过程中人工检查和整理是对文本挖掘结果进行逐一检查,剔除错误结果。并通过阅读相关文献整理网络中节点的其他信息。
信息收集过程中对外部数据库数据的整合是利用ARN数据库收集到的脂肪生成相关节点集,筛选TRRUST,PAZAR,BioGRID和miRGate等外部数据库中的节点互作数据。
ARN数据库平台构建中,从数据采集到加工处理的流程主要包括以下四步(图1):
第一步,文献信息的采集与挖掘
共有9908篇PubMed数据库的文章摘要被作为初始语料库用于进一步分析。
借助Cytoscape数据分析平台的Agilent Literature Search文献检索插件,输入一些与成脂分化调控相关的47个关键基因并同时输入“adipo*differen*”,将检索条件提交到PubMed,检索得到的文献将被拆分成单个句子,再根据基因数据库(Entrez Gene)的基因名称或别名(概念名词),将检索条件提交到PubMed,检索得到的文献将被拆分成单个的句子,再根据基因数据库(Entrez Gene)的基因名称或别名(概念名词),或者特定的关系词(通常是动词)如“binding”或“activate”进行软件分析,如果在一句话中提取到至少两个概念名词和一个关系动词,那么它就会被转换成一条互作记录,并加入到Cytoscape数据分析平台的互作调控网络中。
第二步,人工筛选,注释和分析
专业人员根据文献摘要对特定基因,microRNAs和它们之间的关系进行检查和筛选,并标记节点的分类,节点的功能以及节点对脂肪生成的影响,我们还对ARN数据库中包含的每篇文献的试验设计的相关信息如试验方法、试验材料、细胞系名称等进行了分类整理。
ARN数据库平台包含了通过对脂肪生成相关文献的文本挖掘获得的3万多条相关数据,这些相关数据由9个数据库表组成,它们是:节点表、文献表、概述表、SNPs表、表达特征表、实验材料表、实验方法表、关系表和预测表(图2)。
第三步,整合外部数据库中与主题相关的数据
以ARN数据库为例,利用ARN数据库中与脂肪生成相关的3054个节点为筛选条件,可以快速将miRGate,PAZAR,TRRUST,BioGRID等4个外部数据库中,与这些节点相关的数据筛选出来,并添加到ARN数据库中的预测表中。
第四步,设计构建和评价科学假说的分析工具
ARN数据库平台分析构建科学假说的方法,以ARN数据库平台为基础,将调控因子的相关信息存储于数据库中,以调控因子的各项特征为筛选条件,依据“基于文献的科学假说构建方法”,分为“开放的”和“闭合的”两种假说构建过程,根据用户的条件设置,构建出符合特定条件的科学假说(图3);
所述的“基于文献的科学假说构建方法”是,如果文献1提到A影响B,文献2提到B影响C,研究人员可以构建假说:A影响C;文献1和文献2的内容间存在交叉和脱节两个特征。
所述的“开放的”假说构建过程为:
如果第一步从ARN数据库平台中筛选到B1,B2,B3,B4,……,Bn一系列影响脂肪生成A的调控因子,第二步从数据库中筛选到C1,C2,C3,C4,……,Cn一系列影响B的调控因子,第三步就可以构建科学假说C1,C2,C3,C4,……,Cn影响脂肪生成A。
所述的“闭合的”假说构建过程为:
如果第一步从ARN数据库平台中筛选到B1,B2,B3一系列影响脂肪生成A的调控因子,第二步从数据库中筛选到B3,B4,B5一系列调控因子受调控因子C调控,第三步就可以构建科学假说调控因子C通过B3影响脂肪生成A。
为了对ARN数据库平台所构建的假说进行初步的评价,我们基于该平台3万多条数据,根据公式:IFi=1/3[Ei/Emax+Ri/Rmax+Pi/Pmax]为每个调控因子节点计算出它的影响值,以量化它对脂肪生成的影响力,从而用于评价ARN数据库平台所构建的假说的重要性。
在具体设计ARN数据库平台构建和评价科学假说的分析工具界面时,根据使用者不同的分析需求,设计了三种调控因子的筛选方式:即节点筛选、表达特征筛选和自定义节点集筛选。
进一步的,节点筛选方式是根据节点的名称、Gene ID、类别、功能、对脂肪生成的影响对数据库中的调控分子进行初步筛选,并根据节点间的作用方向对数据库中的调控分子进行二次筛选。
表达特征筛选方式是根据相关文献的PMID号、在脂肪生成相关过程中的表达变化、观察时间点等对数据库中的调控分子进行初步筛选,并根据节点间的作用方向对数据库中的调控分子进行二次筛选。
自定义筛选方式是允许用户根据自身的分析需求,录入一个节点集,并据节点间的作用方向,对数据库中的调控分子进行筛选。
在ARN-Analysis中,研究者可以根据图2数据库表结构中,数据库所包含的各类信息,筛选出满足特定条件的数据和信息,按照开放的和闭合的发现过程,建立科学假说。
二次筛选是用户根据分析需求,有以下五项选择:不进行二次筛选、筛选目标节点的源节点、筛选目标节点的靶节点、筛选目标节点的预测源节点和筛选目标节点的预测靶节点;其中,源节点代表该节点参与调控目标节点;靶节点代表该节点被目标节点调控;预测源节点代表该节点可能参与调控目标节点;预测靶节点代表该节点可能被目标节点调控。
下面以调控因子“mirn335”为例,说明ARN数据库平台的科学假说构建方法。
首先我们在ARN数据库的节点页面检索mirn335的基本信息。概述部分显示,它促进骨骼生成;表达部分显示,它在骨骼和脂肪生成过程中的早期高表达,后期显著降低;随后,利用ARN数据库的分析工具,我们可以依次筛选到mirn335的靶标节点集(85个)、抑制骨骼生成的基因节点集(117个)和抑制脂肪生成的基因节点集(173个),点击“分析”按钮,求出它们的交集,就能构建出有关mirn335与骨骼生成和脂肪生成相关的科学假说:
(1)mirn335可能通过抑制brca1、kdm4c、klf7、nfat5、rora、shh等6个抑制成脂的基因,达到促进脂肪生成的效果。
(2)mirn335可能通过抑制fndc3b、mecom、wif1、znf711等4个抑制成骨的基因,达到促进骨骼生成的效果。
接下来,通过在ARN数据库中检索这10个假说中的靶基因,查询出它们的IF值,根据IF值的大小(brca1,29.4;kdm4c,0.4;klf7,1.5;nfat5,2.6;rora,4.9;shh,3;fndc3b,4;mecom,1.2;wif1,0.9;znf711,3.2),我们可以对这些假说的重要性做出初步的判定。
在这个案例中,第一步筛选节点集的过程,依据的是“开放的”科学假说构建原理。第二步,对节点集的分析,依据的是“闭合”科学假说构建原理。
图3是ARN数据库平台的科学假说构建方法原理示意图。本实施例中,所述基于数据库的科学假说构建分为两种:
(1)开放的构建过程:该过程可形成假设。如图3左图所示,研究者从生理现象A出发,通过条件设置,从ARN数据库中筛选到与A相关的多个调控因子B1、B2、B3、B4、...、Bn,随后,通过条件设置,从ARN数据库中筛选到调控B的一系列调控因子C1、C2、C3、C4、C5、C6、...、Cn,从而建立假设:Cn可以通过作用Bn,影响生理过程A。
(2)闭合的发现过程:闭合的发现过程用于检验假设。如果研究者已经形成一个假设,也许是通过前面描述的开放的发现过程形成的假设,他可以通过闭合的发现过程验证该假设。图3右图描述了该方法:从生理过程A和药影响因子C开始,研究者可以通过条件设置,从ARN数据库中筛选到与A相关的节点集1(B1、B2、B3)和与C相关的节点集2(B3、B4、B5),二者的交集B3可用于形成假设:C通过B3影响生理过程A。
本实施例中,ARN数据库是基于Microsoft SQL Server关系型数据库平台开发的,ARN数据库平台Web界面是基于.NET和HTML5开发的。脂肪生成分子调控网络的可视化是通过D3(d3js.org)实现的。
图4展示了ARN数据库平台的在线分析工具截图。该分析工具支持按节点筛选、按表达特征筛选和用户自定义节点集三种分析模式。
综上所述,本实施例详细描述了ARN数据库平台及其分析构建科学假说的方法,通过将所述ARN数据库平台与后台数据库和前台ARN显示界面相连接,利用文本挖掘得到的大量信息,根据开放的和闭合的科学假说构建方法,使得研究人员能够基于海量的数据,快速理清科研思路,构建科研假说,并且能够基于数据库的统计数据,对所构建的科学假说进行初步评价。基于数据库的科学假说构建模型必定能够减轻科研人们面对海量信息的压力,同时加速科学假说的形成和验证。
以上实施方式仅用于本领域技术人员理解本发明,本发明不限于以上实施例,本领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型,因此所有等同的技术方案也应属于本发明的范畴。
- 还没有人留言评论。精彩留言会获得点赞!