智能视频分析方法与流程
本发明涉及视频分析技术领域,特别涉及一种智能视频分析方法。
背景技术:
随着我国信息化进程的推进,不可否认,大量的前端高清视频设备的建设使得整个视频监控质量有了很大提高,已形成了全覆盖的三级监控体系,实现了视频的大联网,满足了各级人员对前端视频的观看需要。大量的监管工作中常面临各类突发事件,在实际运行中,由于视频监控应用系统技术相对落后,且与业务系统相互独立,极大的制约了危机处理机制的实施效果。
当前视频监控系统主要存在以下一些问题:
1、实时监控画面众多,全靠人工识别。
2、海量视频录像,无法快速定位。
3、视频监控资源整合效率低,无法形成统一的资源池。
4、视频监控与业务系统相对独立,无法联动。
5、视频监控只用于时候取证,事前预警困难。
6、没有把图像资源转换为信息资料,起到的实战辅助作用不够。
中国专利公开号为CN 104581037A的发明专利,该发明专利提供一种智能视频分析方法服务器结构,它结构紧凑,操作方便,然而,该发明通实时监控画面众多,全靠人工识别。
技术实现要素:
本发明的目的旨在至少解决所述技术缺陷之一。
为此,本发明的目的在于提出一种不用考人工就可以识别的智能视频分析方法。
为了实现上述目的,本发明提供一种智能视频分析方法,包括以下步骤:
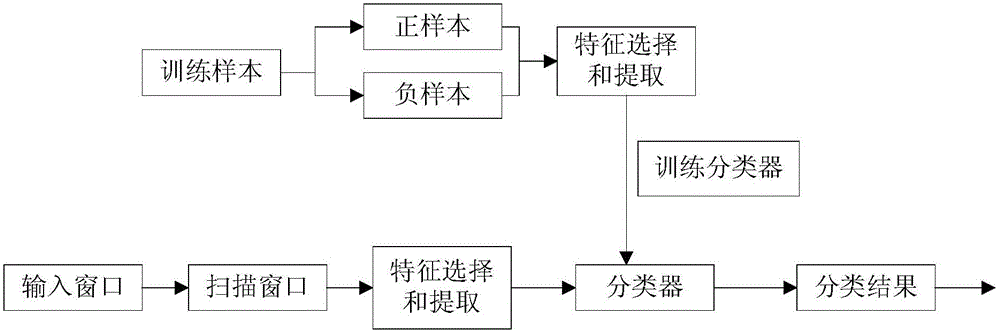
步骤S1,根据获取的视频图像,创建训练样本;
步骤S2,根据训练样本,提取特征;
步骤S3,根据所提取的特征,建立训练分类模型;
步骤S4,根据训练分类模型,检测目标。
进一步的,在步骤S1中,所述训练样本包括正样本和负样本,其中,所述正样本是指用于某类别检测的目标样本;所述负样本指不包含目标的视频图像或部分视频图像。
进一步的,在步骤S2中,所述特征至少包括目标姿态、形状、色彩、位置。
进一步的,在步骤S2中,在提取特征之前,根据不同的周围状况选择,对视频图像是否进行场景重建和恢复。
进一步的,在步骤S2中,提取特征前,将非结构化的视频图像数据进行结构化处理。
进一步的,在步骤S2中,视频图像数据结构化处理后,在镜头检测和聚类的基础上,进一步提取有意义的视频图像对象,建立多个维度的索引信息,并进行存储。
进一步的,在步骤S3中,建立训练分类模型包括以下步骤:
首先,对原始视频的进行背景建模,提取出背景和检测出运动物体;
然后,通过运动目标跟踪模块,提取出运动物体的轨迹;
接着,通过能量最小化来进行运动物体轨迹的平移和组合优化;
最后,通过图像拼接技术,将优化后的运动物体轨迹拼接在背景图像上,形成视频摘要的一帧。
进一步的,在步骤S3中,所述训练分类模型的算法为:
Y=f(X)
X是用于训练的已标记的样本数据,Y是类别集,f是参数,需要通过经验学习来确定。
进一步的,在步骤S4中,检测目标时,根据关键帧提取特征的方式检索,并输出检索结果。
进一步的,在步骤S4中,所述关键帧的特征至少包括纹理特征、形状特征、颜色特征。
本发明具有大规模多样化基础视频智能分析采集、存储、传递能力;图像大数据管理能力;与其他业务系统互联互通等集成能力。可将特征描述信息存储形成索引,通过有效利用并管理存储的视频文件资源,能从海量的视频文件中迅速定位、播放所关注事件的视频,提高视频录像倒查的效率,实现对视频数据的智能化管理。
本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1为本发明的工作流程图;
图2为本发明的结构流程图;
图3为本发明的应用领域架构图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
本发明提供一种智能视频分析方法,参考附图1-2,包括以下步骤:
步骤S1,根据获取的视频图像,创建训练样本。
训练样本包括正样本和负样本,其中,正样本是指用于某类别检测的目标样本(例如人脸识别中的人脸样本、行人检测中的行人样本、车辆检测中的汽车样本等)。负样本指不包含目标的视频图像或部分视频图像(如背景等)。为了方便处理,一般把所有的训练样本图片都归一化为统一大小的尺寸(例如,30x30)。
步骤S2,根据训练样本,提取特征;
特征至少包括目标姿态、形状、色彩、位置。
一幅图像的信息量是巨大的。例如,一个文字图像可以有几千个数据,有几万个像素灰度值。为了实现准确的分类和匹配,必须提取出原始图像数据中最能够反映图像本质的特征,即图像特征选择和提取。把用于分类识别的图像特征空间叫做特征空间,这些特征在同类物体之间相似度最大,不同类别之间差异最大。
常见的几种具有强大优势的特征有适合检测人脸的Haar特征、LBP特征、检测行人HOG特征及具有不变性的SIFT特征等。
Haar特征是基于"块"的特征。Haar特征值反映了图像的灰度变化情况。
LBP特征(Local Binary Pattern,局部二值模式)是一种用来描述图像局部纹理特征的算子;它的作用是进行特征提取,提取图像的局部纹理特征。
HOG特征为方向梯度直方图(Histogram of Oriented Gradient,HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子,它通过计算和统计图像局部区域的梯度方向直方图来构成特征。
SIFT的全称是Scale Invariant Feature Transform,尺度不变特征变换。SIFT特征对旋转、尺度缩放、亮度变化等保持不变性,是一种非常稳定的局部特征。
在提取特征之前,根据不同的周围状况选择,对视频图像是否进行场景重建和恢复。
视频监控所获得图像是否能真实反映现场情况呢?摄像机的位置、现场的光线、天气情况、场景中的目标运动等都可能会对监控中心获得的图像产生影响,从而使最终分析结果产生差异。因此,最大可能恢复和重建真实现场是智能识别的关键。在此过程中,需要根据不同的周围状况选择合适的算法对得到的视频图像进行处理,以获得最佳的期望效果。
下面对背景建模进行描述:
在视频摘要技术中,对象要重新嵌入背景图像中形成最终的摘要视频,所以背景建模的目的不仅仅是为了运动目标的检测,也要获得准确的背景图像。
背景模型适用于摄像头相对静止的场合,如监控场景。通过为背景建立模型、比较当前视频帧与背景模型的差异,变化不大的区域为背景区域,可得到背景图像,同时,变化较大的区域即为前景区域,该方法可用于对象检测。
常用的背景建模方法主要包括帧间差分模型、线性预测模型、时间中值、均值模型、单高斯模型等方法。为了有效克服噪声干扰、光线变化、阴影等外界因素的影响,同时考虑到安防监控视频中主要出现的是缓慢移动的物体,针对高斯混合背景建模的特性,我们实验中采用混合高斯背景建模的算法来进行背景建模。
提取特征前,将非结构化的视频图像数据进行结构化处理。
视频结构化技术包括两层含义:
1)视频内容语义化,即在标准化的视频内容描述规范组织下,把视频中各个感兴趣的目标和其特征及行为识别出来,以文本的方式来描述视频内容,这是一个视频信息情报化提取的过程。
2)视频资源关联化,建立单(跨)摄像头视频资源的语义互联,使得利用数据挖掘手段进行高效分析和语义检索成为可能,也使得视频资源同其它信息系统资源进行语义互联成为可能,这是一个视频信息组织、管理与挖掘,并辅助业务需求的过程。
视频图像数据结构化处理后,在镜头检测和聚类的基础上,进一步提取有意义的视频图像对象,建立多个维度的索引信息,并进行存储。
在视频结构化技术为基础,在镜头检测和聚类的基础上,进一步提取有意义的视频对象,使视频数据从非结构数据转化成容易进行高层处理的结构数据,对实现基于内容的视频检索十分重要。因此要利用高效的特征库索引技术,为用户提供快速的特征查询。其中,索引根据特定属性对数据库中数据进行排序,从而可提高对库中数据访问的效率。
与传统的字符型数据库系统相比,主题视频数据库索引要相对困难。首先,在传统的数据库管理系统中,通常选择多个或一个能够识别数据的关键字,但在主题视频数据库中,存在多个维度的索引信息,如注释、视频特征、业务数据索引等。此外在视频中还大量存在难以用字符和数字符号描述的内容线索,如视频中的图像的运动、帧图像中的颜色、纹理和形状等。当用户要利用这些线索对数据进行检索时,就必须首先将其人工转化为文本或关键词形式,但这种转换具有一定的主观性,而且相当耗时。现在,数据库和网络中的视频数据量非常庞大,人们在应用中不但要求数据库能对视频进行存储以及进行基于关键字的检索,而且要求对结构化的视频数据进行语义分析、表达和检索。然而,虽然视频数据包含丰富的语义内容,但在物理层次上,视频是二维象素阵列的时间序列,与语义内容有一定得区别。因此,要实现基于内容的检索,必须突破传统的基于多个或一个关键域建立索引的局限,直接对视频内容进行分析,抽取语义和内容特征,并利用这些内容特征建立索引。
步骤S3,根据所提取的特征,建立训练分类模型;
建立训练分类模型包括以下步骤:
首先,对原始视频的进行背景建模,提取出背景和检测出运动物体;
在视频处理领域,运动对象检测是一个重要的研究内容。运动对象检测是指在背景相对静止的视频中检测出与运动物体相关的像素点,滤除图像中与运动对象无关的信息。对运动对象的正确检测是后续运动物体跟踪和运动物体轨迹准确提取的重要保障。
然后,通过运动目标跟踪模块,提取出运动物体的轨迹;
运动目标跟踪模块的功能就是在连续的视频图像帧之间,建立被跟踪目标的对应匹配问题,把被跟踪的运动目标在图像视频序列中对应起来,获得被跟踪运动目标诸如位置、速度、运动轨迹、加速度等运动信息,从而进一步对这些运动信息进行分析和处理,实现对运动目标行为的理解。
最常用的运动目标跟踪的典型算法有:均值偏移(Meanshift)、粒子滤波和卡尔曼滤波,它们是运动目标跟踪中的三大主流算法。
接着,通过能量最小化来进行运动物体轨迹的平移和组合优化;
轨迹组合优化是基于对象的视频摘要中的核心步骤,其通过将不同时间段的运动轨迹平移到相同时间段中来,达到同时播放的目的。通过定义能量函数,综合考虑各目标体损失的像素值、不同目标体时间一致性以及不同目标间遮挡损失的像素值等因素,运用贪心算法进行能量最小化,确定各目标体在视频中的起始时间位置。在避免运动物体丢失的同时,避免了之间的碰撞,保证了视频播放的流畅性。
最后,通过图像拼接技术,将优化后的运动物体轨迹拼接在背景图像上,形成视频摘要的一帧。
即将提取的目标体嵌入到背景中,为了避免图像拼接时候出现不同物体之间的颜色融合,可采用诸如泊松编辑等图像拼接技术。
训练分类模型的算法为:
Y=f(X), (1)
X是用于训练的已标记的样本数据,Y是类别集,f是参数,需要通过经验学习来确定,达到最好的分类效果。
常用的分类模型有SVM(支持向量机)、AdaBoost算法、Randomforest(随机森林)、神经网络等。训练分类器就是寻找这些参数,使得达到最好的分类效果。
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
Randomforest(随机森林)指的是利用多棵树对样本进行训练并预测的一种分类器。
步骤S4,根据训练分类模型,检测目标。
检测目标时,根据关键帧提取特征的方式检索,并输出检索结果。
如何提取与人们视频相符合的视觉特征,如何使提取的视觉特征与实际人们的视觉感受相吻合,是基于内容的视频检索所必须解决的问题。另外,针对不同应用场合选择合适的视频特征和灵活的查询手段也是十分重要。在基于内容的视频检索系统中,主要是针对关键帧进行特征提取,关键帧的特征包括纹理特征、形状特征以及最常用的颜色特征等。
检测目标时,通过分类器对上述检测目标的区域特征进行筛选,判断该区域特征是否为目标的。
本发明通过智能视频分析方法可以建立资源池,通过资源池将视频中各类资源作为服务对外提供,通过集中管理和弹性资源调度,将原本静态分配的多媒体资源抽象为可管理、易于调度、按需分配的资源池,提供按需灵活使用各类视频资源的服务。对于各类后端应用系统,当其部署环境与地理位置无关时,则可以在资源池中进行部署,借助资源池提供的灵活的各类资源服务实现应用系统的灵活扩展。
由于各个应用系统品牌各异,对数据的存储方式也不尽相同,因此资源集成模块应能识别不同应用系统的存储内容,并可对其进行分类管理。各个应用系统与综合业务多媒体视频融合应用云平台间存在一定的逻辑关系,诸如资源命名、存储路径等,因此需构建一套专门的业务对象转换引擎,根据预定义规则对应用系统和综合业务多媒体视频融合应用云平台的业务对象数据进行翻译转换。业务对象访问引擎包括业务对象访问调度器、对象关系转换服务等主要功能模块。
本发明采用先进的Plug&Play(即插即用)技术,具备国内领先的网络穿透能力,适用于各种复杂性网络,无需对网关、防火墙进行设置调整,即可由前端设备主动发起连接,向后端云平台进行设备注册、按需转发。
本发明采用分布式文件系统、分布式数据库实现统一的存储架构,保证了系统的扩展性、可用性和性能。同时可结合用户实际业务应用需求,为视频应用定制一套适用于视频应用的存储系统。视频云存储的优势在于视频资源的有效管理和访问,同时支持海量小文件的高效存储。
本发明运行在视频云计算平台之上,实现了资源虚拟化技术、网格化计算技术、虚拟化存储技术、分布式媒体接入与转发技术在视频实战中的应用等。
本发明视频云检索为视频应用系统提供了多种检索方式,并将检索结果融合后输出检索结果。通过视频结构化处理分析和高效的检索引擎,实现多语义的查询检索,可根据用户具体业务数据检索相应视频录像,使视频切实符合业务应用需求,同时提供类似互联网的全文检索,实现所查即所得,支撑基于实战应用模型的数据挖掘。
本发明可对云中视频进行后台自动转换,将之统一转换为通用的视频格式,供网页端、客户端访问。云视频转码服务提供了云端的极速视频转码功能,支持输出视频的视频格式、视频宽高、视频码率、视频帧率等参数的自由设定。
本发明能够提供了多种观看和录影管理方式,可满足各级管理人员不同的应用需求,如远程实时并发观看、远程实时回放、移动用户访问、运营服务管理情况查询等。
本发明可将前端视频进行相应的分类、转储并建立标签,使视频能够成为结构化数据,为监管执法快速地提供有效依据。
本发明通过自动化和智能化手段对视频图像内容进行“行为识别”、“行为检测”、“行为分析”、“事件检测”,以满足视频综合应用的监测、预警、防控能力,减轻监控操作人员监视负担等业务需求。
本发明通过协议或SDK的方式接入各个厂家的视频设备,各厂家设备的功能、接口方式、流程、参数都会存在差异,通常使得设备接入部分的代码变得异常臃肿、难以维护、稳定性差。我们采用了虚拟化的访问技术,将各厂家的设备抽象成统一功能、统一接口的虚拟化设备,然后在云平台中采用相同的流程对其进行接入。
数据是综合业务视频智能化云处理平台的基础,与突发事件相关的基础数据及业务数据经过采集、处理、标准化、传输后存储到综合业务视频智能化云处理平台数据库,经过抽取、重新组合、加工、转换和汇总,形成多个面向主题的数据集合或面向决策的数据集合,这些数据集合将存储到综合业务视频智能化云处理平台数据库中。
参考图3所示,本发明结合业务应用系统,可以进行事前预警、事中处理、事后取证、决策支撑等功能;本发明结合应用目标系统,可以进行自动识别监管目标、自动分析异常行为、西东报警存储取证、自动业务标签关联等功能;本发明结合海关职能系统,可以进行监督进出境货物、行邮以及其它物品、监督进出境运输工具、查缉走私、参与国际防恐、通关口岸管理等功能。
本发明具有大规模多样化基础视频智能分析采集、存储、传递能力;图像大数据管理能力;与其他业务系统互联互通等集成能力。可将特征描述信息存储形成索引,通过有效利用并管理存储的视频文件资源,能从海量的视频文件中迅速定位、播放所关注事件的视频,提高视频录像倒查的效率,实现对视频数据的智能化管理。
本发明的智能视频分析方法具有以下有益效果:
1、本发明的智能视频分析方法对加强海关对监管场所的有效监管,提高海关实际监管效能和监控能力,完善海关管理手段,提升海关监管科技应用水平,实现数据流和物流监管的结合,科学优化配置人力,推动和促进海关监管场所业务的发展起到举足轻重的作用。着力加强监管基层基础建设、着力加强实际监管、着力提升监管效能、着力防范“三大风险”的思路,进一步提升综合监管合力,进一步夯实监管基层基础,进一步发挥综合监管作用,进一步健全完善监管工作机制和制度,形成综合监管大格局。
2、本发明的智能视频分析方法可以结合预警技术及时发现海面、路面异常运输工具,如船舶、车辆等,减少监管盲点,扩大监管范围,加强打击走私及逃跑等非法活动。可通过人脸识别,有效识别水客,使水客无所遁形,加大对重点口岸“水客”团伙走私的打击力度。
3、本发明的智能视频分析方法可整合海关内外信息资源,根据海关辑私任务形成丰富预案,可抓住要害、突出特点、看住底线,集中力量打击重点地区、重点渠道、重点商品的走私活动,构建新形势下的缉私执法辅助平台,提高反走私战斗力。
4、本发明的智能视频分析方法可通过“制度+科技”手段,提高风险防控能力。可加强视频分析,利用监控视频与业务情况进行比对,发挥监控系统在防控执法风险和廉政风险方面的重要作用;加强对特殊时段监控记录的调阅,加强对非通关时段口岸及各场所动态的关注,提高视频监控系统在执法监督和风险防控方面的应用实效。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。本发明的范围由所附权利要求极其等同限定。
- 还没有人留言评论。精彩留言会获得点赞!