一种基于数据源划分矩阵的加权关联规则挖掘方法与流程
本发明是利用数据挖掘方法,对海量行业文本数据中挖掘隐含的有价值的专家知识进行关联规则挖掘,获得以关联规则表示的专家知识;属于人工智能、机器学习、数据挖掘领域。
背景技术:
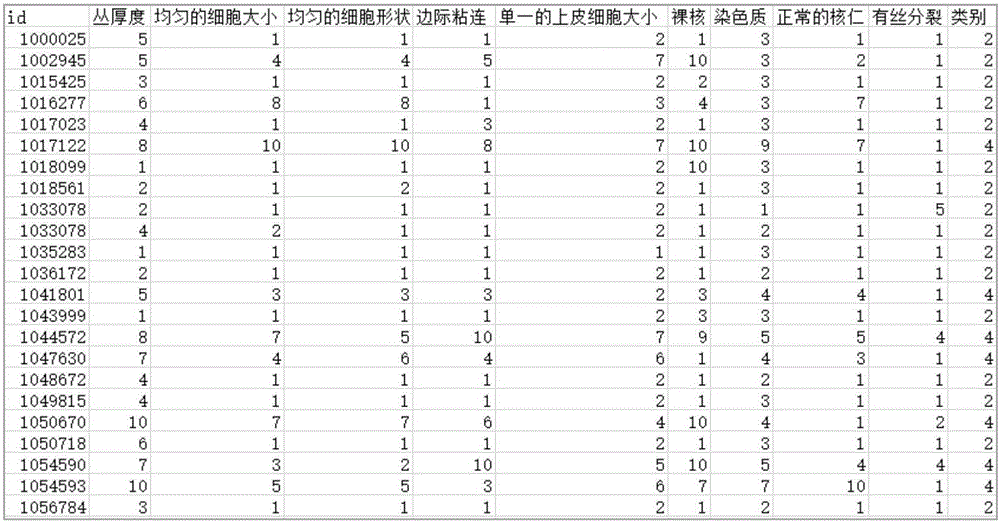
:关联规则用来描述一个事物与其他事物之间存在的某种关系,其主要表现为事物之间的相互影响的关系。在多数情况下大量事物之间相互影响的关系无法被人工所发现,通过计算机人工智能技术对数据进行整理与分析,将这些关系以规则的形式表示出来,即为关联规则挖掘。例如,在数据集中,假设某两个事物之间存在关联,那么意味着可以通过一个事物的信息来推断与其相关联的另一个事物。在商业中可以根据客户的购买记录来发现商品与商品之间的关联关系,如购买某样商品将可能影响其他商品的购买可能性。在医学上可以根据患者的就医记录或疾病症状描述来发现症状与疾病之间的关系,那么就可以通过获取患者症状来推测其可能患有的疾病。首先介绍一些关联规则挖掘中基本的概念。定义1项目集:简称为项集,项目集定义为包涵所有项目的集合,设在数据库中存在事务集D={d1,d2,d3,...,dk},其中di={I1,I2,I3,...,Ij},则项目集I=d1∪d2∪d3∪d4...∪dk。定义2规则:设X、Y是项集,蕴含式X→Y称为规则,其中X、Y是某项目集的子集且X、定义3项目集的支持度:在事务数据库中支持项目X的事务数目定义为项目集X的支持数,即为Count(X),设事物数据库中的总事务数为D,那么项目集X的支持度为sup(X)=Count(X)/D。定义4关联规则X→Y的支持度:X和Y是两个事物集合,A表示规则的成立条件,B表示规则的结果。定义规则的支持度为在事物集中X与Y同时发生的概率。即sup(X→Y)=P(XY)。定义5关联规则X→Y的置信度:X和Y是两个事物集合,A表示规则的成立条件,B表示规则的结果。定义规则的置信度为在事务集中在X的条件下Y的概率。即conf(X→Y)=P(Y|X)=P(YX)/P(X)。假设规则X→Y的置信度是40%,这意味着在X的条件下发生Y的可能性是40%,若Y单独发生的概率是50%,那么在发生了X的条件下会制约发生Y的概率,这时可以认为X与Y之间表现的是一种互斥的关系。因此出现了提升度的概念。定义6关联规则X→Y的提升度:X和Y是两个事物集合,A表示规则的成立条件,B表示规则的结果。关联规则X→Y的提升度计算公式为:如果一个规则的提升度的值等于1,说明前件和后件没有任何关联;如果规则的提升度小于1,说明规则前件对规则后件具有抑制作用;如果规则的提升度大于1,说明规则前件对规则后件具有促进作用。Agrawal等人于1993年提出了Apriori算法,这个算法在关联规则挖掘领域成为了最基本和最具影响力的算法之一。Apriori算法利用到以下两条重要性质:性质1:频繁项集的非空子集也一定是频繁项集。如果一个项集是频繁项集,那么代表在数据库中包含此项集的事务条目数一定大于最小支持度阈值,那么对于该项集的任意一个非空子集,数据库中包含该项集的事务也一定包含它的非空子集,那么该项集的非空子集也一定是频繁项集。性质2:假设项目集X是Y的非空子集,如果X不是频繁项集,那么Y也一定不是频繁项集。显然性质2是性质1的逆否命题,因此显然成立。这两条性质被称为Apriori性质。Apriori算法就是利用Apriori性质,使用了逐层迭代的思路进行频繁项集的挖掘。首先需要扫描数据库找出所有的频繁1-项集,根据频繁1-项集来迭代找出频繁2-项集,逐步向上寻找,直到找到频繁k-项集且无法向上迭代找到频繁(k+1)-项集为止。在Apriori算法中主要有以下两个步骤:●连接步:假设现在已经获取到了频繁n-项集,那么将获取到的频繁n-项集进行与自身的连接,进而得到候选(n+1)-项集。连接方法是如果在频繁n-项集中的两个元素的前(n-1)项相同,而最后一项不同,那么将两个元素的最后一项添加到前(n-1)项上成为一条候选(n+1)-项集的一条元素。●剪枝步:利用性质2,在候选(n+1)-项集中,如果某个元素的子集不属于频繁n-项集,那么这个元素一定不是频繁的。将不满足最小支持度的元素进行剪枝删除。通过以上两个关键步骤进行频繁项集的迭代搜索,最终找到频繁k-项集,然后进行关联规则的生成。Apriori算法原理简单,根据Apriori的两个基本性质,应用频繁项集的先验知识,逐层的将频繁项集找寻出来。但通过研究Apriori算法流程,能够发现该方法存在以下几点问题:(1)在使用Apriori算法时,为了判断出候选集中条目的支持度是否满足最小支持度而对数据库进行了多次扫描。而通常数据库内数据的数据量都是比较大的,这会花费大量的时间用于信息的读取操作,导致了算法的时间成本过高。(2)由于数据量大,在算法计算过程中进行连接操作时,将会产生大量的候选频繁项集,这也会影响计算的效率。(3)传统的Apriori算法将事务数据库中的数据项同等对待,认为每一个数据项在关联规则挖掘中起到的作用是相同的,不能体现出数据项对关联规则结论的侧重程度,这样会导致挖掘的结果可能出现一些“平凡”的规则,具有一定的局限性。针对上述方法缺陷,本发明提出改进方法。技术实现要素:本发明提出了一种关联规则挖掘方法,能够从海量、复杂的行业文本数据中获取出隐含的有价值的知识,为专家系统提供专家知识。本发明包括两部分:数据预处理和关联规则挖掘。数据预处理部分通过对文本特征向量提取和表示,剔除原始文本数据中与领域专业知识无关的信息,提取有用信息、构建文本特征向量。关联规则挖掘部分,提出一种基于数据源划分矩阵的加权关联规则挖掘方法,在传统方法的基础上加以改进,通过对领域数据进行分析挖掘,获得能够表达领域专家知识的关联规则。本发明的目的是通过下述技术方案实现的。1.数据预处理本发明专利针对的是包含领域专家知识的文本数据信息,例如,对于医疗行业中的疾病诊断专家系统,疾病诊断的专家知识可以从医生的诊断病历文本中获取。这些领域文本数据可以以多种方式获得:一是利用爬虫工具,从较为权威、准确程度较高的网站、论坛等获取内容,依据正则表达式从网页源码中进行分离有效的信息。二是由专业从业人员根据自身知识和经验人工输入文本内容,或者是利用现有的电子信息系统提取相关内容。然而,这些文本信息通常呈现口语化严重、使用俗语方言的情况,而且有可能存在与所需数据无关的文字表达以及描述不清等问题,这样的信息难以被计算机理解、不能直接进行数据挖掘,因此需要对海量文本数据进行分词等数据预处理,使之成为结构化的数据。数据预处理主要分为三步:建立领域专有词汇的词典、中文文本分词和文本的特征表示。步骤如下:(1)建立领域词汇词典根据现有的知识建立行业词汇词典,可根据不同的行业建立多个词典。例如,针对医疗行业的疾病诊断专家系统,可建立疾病词典、症状词典及偏义词典分别用于存储疾病名称、症状,以及疾病或症状名称的偏义词语。(2)利用领域词汇进行中文文本分词这一步骤,可以采用分词工具进行中文分词,例如开源的Ansj。利用领域词汇词典对文本数据分别进行分词处理,提取文本中各个不同部分的内容。为提高文本预处理的准确率,同时使用偏义词典处理口语或别名词汇,匹配之后提取对应的专业术语以供后续数据挖掘使用。(3)建立文本特征向量经过分词后,利用得到的词语对该文本进行文本特征表示后,文本转化为由特征项构成的多维空间特征向量。例如,对于医疗行业,为方便后面进行关联规则挖掘,可以将每个文本形成的文本向量分成症状和疾病结论两部分组成文本特征向量。包含领域知识的文本数据经过上述三个步骤处理后,可以将文本信息中有价值的信息抽取出来,进行后续的关联规则挖掘。2.基于数据源划分矩阵的加权关联规则挖掘方法通过对经典关联规则挖掘的Apriori算法的分析,本发明提出了基于数据源划分矩阵的加权关联规则挖掘方法,从两个方面进行改进:首先,采用基于数据源划分矩阵的方法快速计算支持度;其次,采用基于概率的权重标定方法对关联规则挖掘过程中的数据项目集进行加权。具体内容如下:(1)采用基于数据源划分矩阵的方法快速计算支持度首先给出以下定义和性质的证明。性质3:包含有某个项集的全部事务的集合为包含该项集中元素的所有事务的交集。证明:交集的定义为在A、B两个集合中既属于A又属于B的元素的集合。假设某项集为{I1,I2,I3...In},根据交集的定义,包含该项集中元素的所有事务的交集为既包含项目I1,又包含项目I2,又包含项目I3...,又包含项目In的事务的集合,即所有包含该项目的全部事务的集合。性质4:存在频繁(K+1)-项集,那么在频繁K-项集中的项集个数至少为K。证明:如果存在频繁(K+1)-项集,那么频繁(K+1)-项集可以得到K个频繁K-项子集。如果频繁K-项集中项集的个数小于K,产生矛盾,因此性质2正确。定义7事务矩阵:设有项目集合I={I1,I2,I3...In},在事务数据集D中的一条事务表示为ti,ti为项目集合上的非空子集,定义数据集D的事务矩阵A为:如果矩阵A为数据集D的事务矩阵,则矩阵A中的每一行代表数据集D中的一条事务数据。对于矩阵A的一条事务,如果在某一列上元素为1,代表这条事务中含有该项目。在第一次扫描数据集D时,首先建立数据集D的事务矩阵,同时计算出每一个项目的支持度,然后计算出面向该数据的频繁1-项集。根据频繁1-项集对得到的数据集的事务矩阵进行裁剪操作。这里将利用Apriori性质2:如果一个项目集的非空子集不是频繁集,那么该项目集也一定不是频繁集。构造数据库事务矩阵A的映射矩阵H的具体步骤为:(a)扫描数据库,构造数据集D的事务矩阵A,同时求得频繁1-项集。(b)将数据库的事务矩阵按照行向量的二进制大小进行排序,同时在矩阵A最后添一列作为重复系数,并赋予初始值1。(c)删除非频繁的项目对应的列,合并相同的向量,并累加求得重复系数。在得到的事务矩阵A的映射矩阵H中,行向量称为事务向量,除重复系数对应的列向量外的其它列向量称为对应项目的分布向量。下面,在映射矩阵H基础上,根据性质1给出一种新的求解项目集支持数的方法。(a)假设有项目集I′={I1,I2,I,3},该项目集的支持数为包含该项目集的全部事务集合中的元素个数,根据性质3可以转化为求包含该项目集中元素的所有事务的交集中元素的个数。设Hij为项目Ij对应的分布向量的第i维,其意义为事务di是否属于包含项目Ij的事务集合,属于为1否则为0。那么Hi1*Hi2*Hi3表示事务di是否属于包含项目集{I1,I2,I,3}元素的事务的交集中,属于为1否则为0。(b)对所有事务向量进行上述(a)相同计算,再乘以对应重复系数后累加求和就可以得到包含该项目集中元素的所有事务的交集中元素的个数,即为项目集的支持数。这种求解项目集支持数的算法只需要扫描一次数据库,就可以求得映射矩阵。所有的计算都是对映射矩阵的计算,从而省去了多次扫描数据库的过程,能够有效的提升算法效率。此外,考虑到由于数据集D规模过大,生成的事务矩阵可能无法直接放入内存。针对这样的问题,给出如下性质5。性质5将数据全集划分为若干数据子集,数据全集的频繁项集一定是数据子集对应局部频繁项集交集的子集。数据全集的频繁项集一定在某个或某些数据子集中是频繁的,因此数据子集的频繁项集的交集一定包含数据全集的频繁项集。因此根据性质5于划分的思想可以将数据集D中的数据进行划分,划分的大小需要保证每一个数据子集生成的事务矩阵可以放入内存中,对每一个子数据集进行计算,求得每一个数据子集的对应的局部频繁项目集。最后将所有子数据集对应的局部频繁项集求并,扫描数据全集根据最小支持度筛选出数据全集的频繁项集。可以采用贪心的原则对数据集D进行划分,在满足内存的情况下获得尽量大的数据子集。由于生成的事务矩阵是布尔型的,因此事务矩阵所占的空间相对数据集来讲是非常小的。(2)基于概率的权重标定进行关联规则挖掘项目集的权重定义为在这个项目集中所有项目的权重的乘积,项目的权重定义为事务数据库中此项目出现的频率。在扫描数据集时可以同时建立关于数据项的权重向量。项目(集)Ii的权重W(Ii)向量的计算方法为:项目(集)Ii在数据集中出现的次数与数据集中事务数量的比值,如公式(3)所示:其中Ni为数据集D中包含项目Ii的事务数。将上一步得到的项目集的支持度与该项目集的权重进行乘积,就可以求得加权的项目支持度。如果加权支持数不满足最小支持度,就将该项目集从候选项目集中删除,然后将得到的频繁项集的项集个数进行统计,再利用性质2判断是否可以进一步进行迭代,最终求出所有的频繁项集。下面给出基于数据源划分矩阵的加权关联规则挖掘方法的步骤。步骤一:根据内存的大小对数据集进行划分,扫描数据库建立数据库划分后数据子集的事务矩阵A,并求得局部频繁1-项集。步骤二:根据事务矩阵A生成映射矩阵H。步骤三:将得到的局部频繁K-项集(K≥1)进行连接得到局部候选(K+1)-项集,根据映射矩阵H求得各个局部项集的支持度,将得到的支持度与该项目集的权重进行乘积求得加权的局部项目集支持度。步骤四:根据步骤三的结果对局部候选(K+1)-项集进行筛选得到局部频繁(K+1)-项集。步骤五:对局部频繁(K+1)-项集内的项集数进行统计:(a)如果局部频繁(K+1)-项集中的项集数小于(K+2)则跳转步骤六;(b)返回步骤三。步骤六:合并所有频繁项集,根据取得的频繁k-项集,取出其中的一条元素并求得其所有的子集,扫描数据集计算每一个子集的置信度,获取满足预先设定的最小置信度阈值的关联规则集合。基于数据源划分矩阵的加权关联规则挖掘方法的流程图如图1所示。至此基于数据源划分矩阵的加权关联规则挖掘方法完成,可以根据设定的最小置信度阈值,挖掘出符合置信度要求的关联规则。最后将这些得到的关联规则集合加入数据库中,每条关联规则可以作为数据库中的一条记录,完成专家知识库的构建。对于已经构建完成的专家知识库,也可利用挖掘结果来补充和完善。3.实验结果分析为了验证本发明所提方法的正确性以及优化性能,我们选取UCI公共数据集中的BreastCancerWisconsin(Original)数据集进行测试。在数据集中共包含699条事务,共94个项目。图2为数据集数据样例。图3是最小支持度阈值设置分别为10%、15%、20%、25%、30%下,运用本发明所提方法与Apriori算法在运行时间方面的对比图。实验结果验证了本发明提出的方法与传统的Apriori算法相比,在时间复杂度方面有了很大改善,相同数据集规模下本发明提出的方法运行时间仅为传统的Apriori算法的65%。进一步,选取最小支持度为15%对恶性肿瘤数据进行了关联规则挖掘的结果展示,如图4所示,验证了基于数据源划分矩阵的加权关联规则挖掘方法的正确性。4.有益效果在算法的时间复杂度方面,与传统的Apriori算法相比较,基于数据源划分矩阵的加权关联规则挖掘方法只需要扫描两次数据库:在第一次扫描数据库的同时建立起数据库的事务矩阵,在数据库事务矩阵的基础上将数据库的事务矩阵转化为映射矩阵,之后关联规则挖掘都是基于映射矩阵来计算,不需要重复扫描数据库,大大减少了在运算过程中的I/O时间,降低了时间复杂度;最后在合并局部频繁项集时第二次扫描数据库完成对整体数据集的频繁项集的筛选,最终可以获得满足给定的最小置信度的关联规则集。在空间复杂度方面,基于数据源划分矩阵的加权关联规则挖掘方法是基于映射矩阵来进行计算,而映射矩阵的每一行的向量表示都是数字来代表数据集中的每一个特征项,所需存储空间比原始数据要小很多,因此在一定程度上也减少了关联规则挖掘算法的空间复杂度。附图说明图1为根据本发明的基于数据源划分矩阵的加权关联规则挖掘方法的流程图;图2为BreastCancerWisconsin(Original)数据集数据样例;图3为不同支持度下算法时间对比图;图4为在最小支持度15%条件下关联规则挖掘的结果。为了能明确实现本发明的实施例的结构,在图中标注了特定的尺寸、结构和器件,但这仅为示意需要,并非意图将本发明限定在该特定尺寸、结构、器件和环境中,根据具体需要,本领域的普通技术人员可以将这些器件和环境进行调整或者修改,所进行的调整或者修改仍然包括在后附的权利要求的范围中。具体实施方式为了更好地说明本发明的目的和优点,以下结合实施例和附图对本发明做进一步说明。下面的具体应用中,举例说明对医疗领域中的疾病诊断专家知识库进行建设的方法,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。1.数据预处理首先进行数据获取。方式一,利用互联网资源。打开网页,分析网页源码中各个标签的属性,利用正则表达式进行匹配查找,找到分别包含患者咨询的问题与医生的回答情况的标签。分别将这两部分内容提取出来,保存到两个文档中,例如问题“嗓子有痰但咳不出,嗓子痒一咳就憋的不能出气”,回答“您这种情况多久了?有没有诱因。根据你的情况是考虑上呼吸道感染的情况”。使用广度优先搜索的方式重复上述步骤,根据网址的不同过滤掉不合理的网页,重复多次直到获取足够的数据。方式二,由人工手动录入数据或者读取已有电子病历文件,获取病历文本中的主诉症状和诊断结果。例如,病历档案如表1:表1病历档案示例提取其主诉和诊断结果作为有效数据之后,对获得的数据进行进一步的分词处理,分词处理前需要先构建行业词典,包括症状词典、疾病词典和偏义词典。(a)建立症状词典。将每个症状词汇按照[名称属性词频]的格式存储为一条记录,如[发热症状1000],然后保存在后缀为dic的文件中,作为症状词典。(b)建立疾病词典。将每个疾病词汇按照[名称属性词频]的格式存储为一条记录,如[普通感冒疾病1000],然后保存在后缀为dic的文件中,作为疾病词典。(c)建立偏义词典。将每个症状、疾病词汇的近义词、俗语等按照[名称对应词词频]的格式存储为一条记录,如[头痛头疼1000],然后保存在后缀为dic的文件中,作为偏义词典。然后,采用开源Ansj中文分词方法,利用症状词典对之前获得的疾病诊断文本中症状相关内容进行分词处理,同时利用疾病词典对之前获得的诊断结果相关内容进行分词处理,保证症状和结果一一对应的顺序不变。对于未在以上两个词典中出现的词语,可以再利用偏义词典进行处理,提高数据获取的准确率,匹配之后提取对应的专业术语进行使用。例如:对症状文本“嗓子有痰但咳不出,嗓子痒一咳就憋的不能出气”分词,得到症状词语“有痰”、“咳”;对诊断结果文本“根据你的情况是考虑上呼吸道感染的情况”分词,得到词语“上呼吸道感染”。组合后可以得到空间特征向量(有痰,咳,上呼吸道感染),供接下来的关联规则挖掘使用。2.关联规则挖掘设有项集I={感冒,发热,咳嗽,流涕,头晕,乏力,口干,嗜睡},设定的加权最小支持度为0.13。数据集D示例数据如表2所示:表2数据集D示例数据事务号事务项集1感冒,发热,咳嗽,流涕,头晕2发热,咳嗽,流涕3感冒,发热,流涕4感冒,头晕,乏力,口干5感冒,发热,头晕,乏力6感冒,发热,咳嗽,流涕,头晕7感冒,咳嗽,流涕8发热,咳嗽,流涕,头晕,乏力,嗜睡9咳嗽,嗜睡接下来利用基于数据源划分矩阵的加权关联规则挖掘方法进行关联规则挖掘。步骤一:根据内存的大小对数据集进行划分,扫描数据库建立数据库划分后数据子集的事务矩阵A,并求得局部频繁1-项集。假设选用数据集划分数目为1的情况进行分析,当数据集划分数目大于1时可依据相同的方式进行分析。扫描数据库建立事务矩阵A为:计算各个项目的支持度,计算结果如表3所示:表3各个项目支持度感冒发热咳嗽流涕头晕乏力口干嗜睡0.6670.6670.6670.6670.5560.3330.1110.222因为加权最小支持度为0.13,因此加权最小支持数为1.17,因此可以得到频繁1-项集L1={感冒,发热,咳嗽,流涕,头晕,乏力,嗜睡}。步骤二:根据事务矩阵A生成映射矩阵H。将事务矩阵A按照行向量二进制值排序后求得的映射矩阵H为:步骤三:将得到的局部频繁K-项集(K≥1)进行连接得到局部候选(K+1)-项集,根据映射矩阵H求得各个局部项集的支持度,将得到的支持度与该项目集的权重进行乘积求得加权的局部项目集支持度。将频繁1-项集进行连接操作得到候选2-项集,C2={感冒发热,感冒咳嗽,感冒流涕,感冒头晕,感冒乏力,感冒嗜睡,发热咳嗽,发热流涕,发热头晕,发热乏力,发热嗜睡,咳嗽流涕,咳嗽头晕,咳嗽乏力,咳嗽嗜睡,流涕头晕,流涕乏力,流涕嗜睡,头晕乏力,头晕嗜睡,乏力嗜睡}。根据新的支持数求解方法求项集“感冒发热”的支持度为第一列、第二列以及重复系数列按位乘积在求和,得到的值为:1*1*2+1*1*1+1*1*1+1*0*1+1*0*1+0*1*1+0*1*1+0*0*1=4进而可以求得其加权支持数为4*0.667*0.667=1.780,满足最小支持数。同理求得的其它项集的加权支持数如表4所示:表4候选2-项集的加权支持数编号项集名称候选2-项集支持数1感冒发热1.7802感冒咳嗽0.8983感冒流涕1.3354感冒头晕1.1135感冒乏力0.2226感冒嗜睡07发热咳嗽1.3358发热流涕1.7809发热头晕1.11310发热乏力0.44411发热嗜睡0.14812咳嗽流涕1.78013咳嗽头晕0.74214咳嗽乏力0.22215咳嗽嗜睡0.14816流涕头晕0.74217流涕乏力0.22218流涕嗜睡0.14819头晕乏力0.37020头晕嗜睡0.12321乏力嗜睡0.074步骤四:根据步骤三的结果对局部候选(K+1)-项集进行筛选得到局部频繁(K+1)-项集。将不满足最小支持数的项集剔除后得到频繁2-项集为L2={感冒发热,感冒流涕,发热咳嗽,发热流涕,咳嗽流涕}。步骤五:对局部频繁(K+1)-项集内的项集数进行统计:(a)如果局部频繁(K+1)-项集中的项集数小于(K+2)则算法结束(b)返回步骤三。此时频繁2-项集中的项集数为5,大于3,因此返回步骤三继续计算。接下来根据频繁2-项集生成的候选3-项集并求得加权支持数如表5:表5候选3-项集加权支持数此时候选3-项集中的项集都不满足最小支持数,得到的频繁3-项集为空集,项集个数为0小于4,因此计算结束。步骤六:合并所有频繁项集,根据取得的频繁k-项集,取出其中的一条元素并求得其所有的子集,扫描数据集计算每一个子集的置信度,获取满足预先设定的最小置信度阈值的关联规则集合。合并所有频繁项集得到:L={感冒,发热,咳嗽,流涕,头晕,感冒发热,感冒流涕,发热咳嗽,发热流涕,咳嗽流涕}。接下来根据“症状->疾病”的方式分别计算规则的置信度,得到表6结果。表6规则及规则的置信度编号项集名称置信度1发热->感冒0.6672流涕->感冒0.667假设,预先给定的最小置信度为0.6,那么“发热->感冒”“流涕->感冒”两条规则都属于满足阈值的关联规则,可将这两条规则作为关联规则挖掘的结果,加入至专家知识库中。至此,本次关联规则挖掘过程完成。汇总疾病诊断的关联规则挖掘方法的工作过程以及挖掘结果使用的完整示例如表7所示。依据上述方法挖掘出的满足预先指定的最小置信度阈值的关联规则集合就可以以产生式规则的形式保存至疾病诊断专家系统中的知识库中,可以在专家系统推理中提供辅助决策支持。表7疾病诊断的关联规则挖掘工作过程示例当然,本发明还有多种其他实施例,在不背离本发明精神和实质的情况下,熟悉本领域的技术人员可根据本发明做出各种相应的改变,但这种改变都应属于本发明所附的权利要求的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1