一种大数据风险分析方法与流程
本发明具体涉及一种大数据风险分析方法,属于大数据风险分析
技术领域:
。
背景技术:
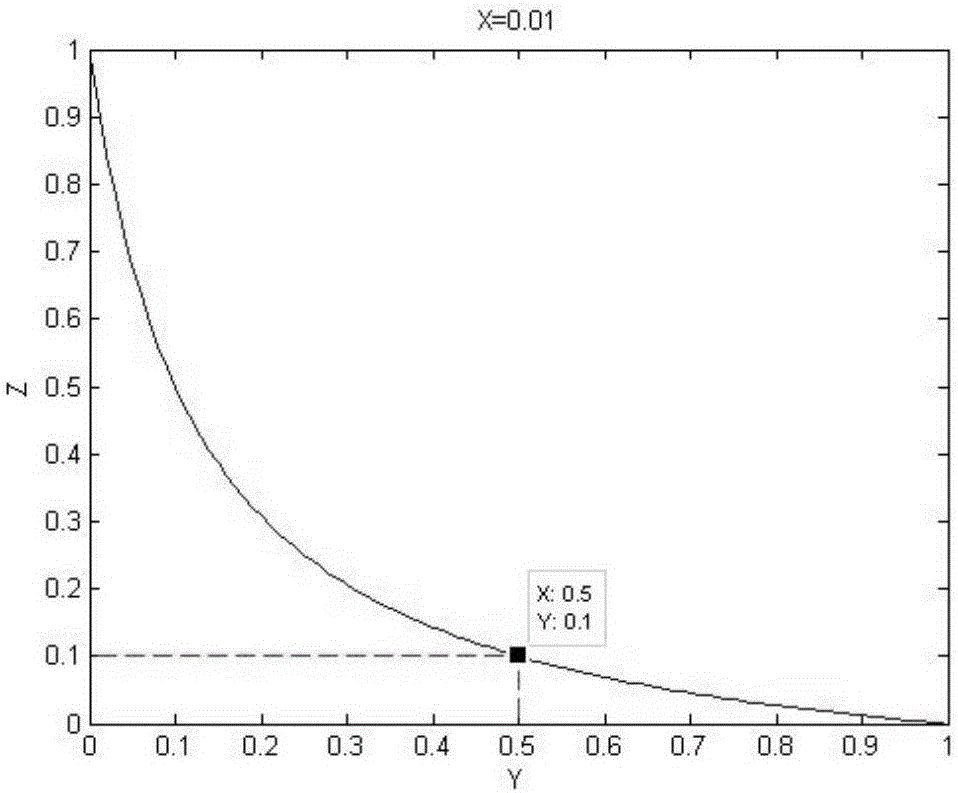
:埃博拉疫情、马航MH370客机失事、天津仓库爆炸案、法国巴黎恐怖袭击事件……人类社会进入二十一世纪后不断出现的种种灾害和意外无一例外地警示我们:风险无处不在,一个以风险为特征的新型社会形态正在逐步来临。传统的风险评估方法已经不能够满足我们对风险评估的需求,传统的风险评估在分析随访资料时存在着很大的困难,不能确定所有的随访资料都具有真实性和可靠性,并且会出现大量失访的情况(失去联系、无法观察到结局、某项研究截止等等),显然,我们可以看出将失访数据无论是算作死亡还是存活似乎都不太合理。这样就对我们进行风险评估和风险管理造成了很大的障碍。保险公司会根据传统的精算模型制定相应的投保方案,但是,传统的信息搜集方式无法全面地获得一个人的生活日常规律,例如一个人的作息时间、出行时间、社交频率等,而恰恰是这些微不足道的细节信息,往往是问题的关键所在。比如,一个经常酗酒泡吧且出行驾驶的人,酒后驾驶的可能性会非常之高,导致交通事故的可能性也会相对很高;另外经常作息不规律、长期熬夜的人患病的几率也比常人高很多。在大数据时代,由于各类传感器日益普及,通讯技术的飞跃以及网络基础设施的高速发展,越来越多的领域如金融、电商、广告、医疗、生物、物流等开始有意识地收集和积累大量数据,并从中挖掘以前不曾也不可能触及的价值。过去两年所产生的数据量为有史以来所有数据量的90%,其中2013年中国产生的数据总量超过0.8ZB(相当于8亿TB),是2012年所产生的数据量的2倍。精准而又庞大的数据对于我们进行分析风险评估给予了很大的帮助,我们不用再考虑是否会有失访数据的存在,从而使我们对风险的管理更加精确化、系统化。众所周知,以往支撑保险公司保险体系的是对于投保人的社会关系的充分调查,包括投保人的年龄、性别、行业、家族遗传史等,但是由外界的发病率统计资料不完整,所以,如不考虑年龄差别,保险费率计算所使用的发病率统计资料主要来自保险公司对被保险人的记录,这些统计资料有一定的局限性。当然保险业的一些出版物也是最可靠的统计资料来源。例如:美国保险委员会的精算师编写和出版的《丧失工作能力者收入、住院、外壳费用和大额医疗费用保险的个人保险单经验数据的年度报告》或者《保险监督官丧失工作能力表》。美国保险公司只要对这些已经统计好的数据进行简单的调整,就可以用做计算净保险费和准备金。保险精算的最基本方法是切比雪夫大数定律,如下所示:设X1,X2,…,Xi是由相互独立的随机变量所构成的序列,每一随机变量都有有限的方差,并且它们有公共上界,即:Var(X1)≤C,Var(Xi)≤C,...,Var(Xn)≤C,则对于任意的Ξ>O,都有:limn→0P{|1nΣi=1nXi-1nΣi=1nE(Xi)|<Ξ}=1]]>切比雪夫大数定律阐述的是大量随机因素的平均效果与其数学期望有较大偏差的可能性越来越小的规律。从风险的角度看,它表明,如果以Xi表示第i个风险单位的未来损失,则当n很大时,n个风险单位未来损失和以概率1接近它们的期望值。这就是保险人把未来损失的期望值作为纯保险费的主要根据。当保险人承保了n个相互独立的保险标的后,尽管每个风险单位的实际损失Xi不会等于其期望值E(Xi),但当保险标的数n足够大时,保险标的的平均损失与其损失的平均期望值几乎相等。换言之,如果保险人按照每个风险单位的未来损失期望值作为纯保险费来收取,则当其聚集风险单位足够多时,这些纯保险费将足够支付保险人未来作出的损失赔偿。投保人可能会刻意隐瞒不利于自己的信息(疾病史、遗传史、工作性质等),造成数据的真实性和可靠性无法保证。因此,依据传统数据得出的风险模型显然存在很大的漏洞。技术实现要素:本发明的目的是提供一种大数据风险分析方法。本发明针对现有精算模型存在的弊端,结合大数据的背景,建立了更为精确的预测个人风险的模型系统,并且确定预测准确率和保险公司赔偿率之间的关系,继而确定预测准备率对于保险公司盈利的影响,一方面新型保险模型提高了保险公司的盈利,另一方面还产生了一定的社会价值。具体的,本发明提供了一种大数据风险分析方法,所述方法包括以下步骤:步骤(1):在现有精算模型的基础上,结合大数据建立预测用户风险的新模型;步骤(2):验证新模型可行性;步骤(3):确定预测准确率和保险公司赔偿率之间的关系,继而确定新模型的盈利空间。本发明结合大数据的时代背景,利用机器学习算法模型分析被保人的日常行为习惯,预测出被保人罹患疾病或发生意外的可能性,从而更为人性化地制定相应的保费标准。进一步对新模型的可行性进行了研究,首先是建立了新模型赔偿率和预测准确率的关系式,发现了预测准确率和赔偿率的负相关关系,并且当预测准确率大于50%时,新模型赔偿率将低于原模型赔偿率。并用MATLAB对模型进行可视化分析。然后进行了新模型盈利分析,建立了低风险客户的折扣、预测准确率以及盈利的三维关系,更为直观地得到新模型下增加的盈利空间。附图说明图1为本发明大数据风险分析方法的流程图。图2为MATLAB对新模型进行可视化分析时赔偿率为0.01时,预测的准确率和新模式下赔偿率之间的关系曲线图。图3为MATLAB对新模型进行可视化分析时赔偿率为0.05时,预测的准确率和新模式下赔偿率之间的关系曲线图。图4为MATLAB对新模型进行可视化分析时赔偿率为0.1时,预测的准确率和新模式下赔偿率之间的关系曲线图。图5为MATLAB对新模型进行可视化分析时赔偿率为0.2时,预测的准确率和新模式下赔偿率之间的关系曲线图。图6为MATLAB对新模型进行可视化分析时赔偿率为0.5时,预测的准确率和新模式下赔偿率之间的关系曲线图。图7为MATLAB对新模型进行可视化分析时赔偿率为0.8时,预测的准确率和新模式下赔偿率之间的关系曲线图。图8为盈利与折扣以及预测准确率之间的关系曲线图。图9为当折扣取0.5时,盈利和准确率之间的关系曲线图。图10为当折扣取0.7时,盈利和准确率之间的关系曲线图。图11为当折扣取0.8时,盈利和准确率之间的关系曲线图。图12为当折扣取0.9时,盈利和准确率之间的关系曲线图。图13为本发明中结合大数据建立预测用户风险的新模型的方法流程图。具体实施方式下面结合附图和实施例对本发明进行详细的描述。如图1所示,本发明流程如下:步骤(1):在现有精算模型的基础上,结合大数据建立预测用户风险的新模型;步骤(2):验证新模型可行性;步骤(3):确定预测准确率和保险公司赔偿率之间的关系,继而确定新模型的盈利空间。所述结合大数据的方法,如图13所示,首先运用Hadoop平台完成对原始数据的预处理以及特征工程的训练,然后利用逻辑回归等二分类算法训练机器学习模型,最后采用AUC方法对模型进行评价。其中风险模型预测方法分为两类,疾病风险预测模型和意外风险预测模型,疾病风险预测模型采用logistic回归算法、决策树以及LS-SVM算法模型;意外风险预测模型使用逻辑回归模型以及贝叶斯网络算法模型。所述步骤(1)中的现有精算模型为经典离散时间风险模型:Un=Un-1+Xn-Yn,U0=u>0Un表示保险公司第n阶段结束时的盈余,Xn表示第n阶段的保费收入,Yn表示第n阶段的赔偿额;假设从第n阶段开始结合大数据进行改进,则所述新模型为:U'n=Un-1+X'n-Yn',U'0=u>0将Un和U'n对比,看改进后保险公司盈余的变化。结合前面的离散风险模型,则有Un=Un-1+pU′n=Un-1+P即Un-U'n=p-P。本发明将通过以上预测方法,准确地判断出发生疾病和意外事故的高危人群。疾病预测系统由疾病风险预测模型来支撑,意外预测系统由意外风险预测模型支持。对于保险公司而言,能够准确地预测出高风险人群是至关重要的,大大降低了保险公司的赔偿率,从而有效地控制风险。本发明将预测结果分为四种情况,如下表1显示。表1在新模型下,预测出来的高风险客户将被提高保费,同时低风险客户将在原来的个给予投保优惠,显然该情况下,投保结果将出现调整。设预测的准确率为Y,赔偿率为X,采用新的模式后赔偿率为Z,则有下式成立,x1+x3x1+x2+x3+x4=Y;x1x1+x2=Yx3x3+x4=Y;x1+x2=Xx1+x2+x3+x4=1Z=x2x2+x3]]>解得,其中当Y=1时,X=0。由于X∈(0,1),下面分别取X=0.01、X=0.05、X=0.1、X=0.2、X=0.5以及X=0.8,采用MATLAB对上述模型进行可视化分析,结果如图2-7所示。通过MATLAB作图得出,赔偿率Z随着准确率Y的变化而变化。如图2-7所示,图像为递减的,即随着预测准确率Y的增大,赔偿率Z不断降低,并且可以看出X越小,Z下降的趋势越明显。结果显示,当预测准确率Y=0.5时,Z=X,当Y>0.5时,Z>X,即准确率最低保证为50%,在新模型下的赔偿率才低于传统模型的赔偿率。下面本发明将进一步讨论预测准确率对于保险公司盈利的影响,结合传统的投保模式,将新的模型和传统模型进行对比。传统模型:设有x人投保,单位保费为a,赔偿率为X,单位赔偿额为b,则盈利p=a·x-x·X·b新模型:设有x人投保,单位保费为ca(0<c<1),赔偿率为Z,单位赔偿额为b,则盈利P=x·ca-x·Z·b=x·ca-x·11+Y1-Y·1-XX·b(Y≠1)]]>P是关于折扣c和准确率Y的函数,利用MATLAB进行分析得到盈利与折扣以及预测准确率之间的关系,如图8所示。图中设x=1000;a=1000;b=10000;X=0.08,横截面表示的是原模型下的盈利,曲面表示的是新模型下的盈利,其中箭头指示的即为新模型较传统模型增加的盈利区间。当折扣取不同定值时,通过二维图像更为直观地显示盈利和准确率之间的关系,如图9-12所示。如图所示,当折扣c取值为0.5时,准确率大于75%时,新模型的盈利将超过传统模型;当折扣c取值为0.9时,准确率大于55%时,新模型的盈利将超过传统模型。因此,当折扣较高时,对于准确率的要求越高。通过本发明研究,新模型既满足盈利可行性,又利于督促投保人养成良好的行为习惯,同时还能带来一定的环境效益,相信新型保险模式将会是大势所趋。显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若对本发明的这些修改和变型属于本发明权利要求及其同等技术的范围之内,则本发明也意图包含这些改动和变型在内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1