一种基于眼动数据的流程图笔划成组的方法和装置与流程
本发明涉及笔划识别,特别涉及眼动数据分析在笔划识别中的应用。
背景技术:
草图识别是对手绘图形的识别,利用计算机识别手绘的图表,如流程图、UML图、电路图等。基于草图识别的人机交互允许用户以视觉化的形式形象的表达和传递信息,自然直观,易于理解和便于操作。草图识别中,笔划成组是一项重要内容。所谓笔划成组是指在多个实体的草图中如何将笔划分组成若干个能组成实体单元的笔划组。笔划分组后,才能对笔划组中的笔划进行进一步识别。比如,在手绘电路图中,通过笔划成组,将手绘草图的笔划分组成单独的二极管、三极管、电阻、电容等语义符号,然后对分组后的笔划进行进一步识别区分出该语义符号是二极管,还是三极管、电阻、电容。对于手绘流程图而言,需要将笔划分组成步骤方框、节点菱形等语义符号,然后进一步识别该语义符号是步骤方框还是节点菱形。由此可见,笔划成组是草图识别的基础。
现有技术的笔划成组方法主要有两种。第一种方法是通过约束用户行为进行分组。比如,Druin软件要求在画完一个语义符号后停顿一定时间,再比如Gennari软件在其电路图识别系统中要求组成同一个语义符号的笔划是连续的。这种通过约束用户行为的处理方式实用性较低,且因会明显扰乱用户本身的绘制流而不可取,用户体验差。第二种方法是利用草图本身的几何特征等信息来实现,或尝试通过启发式原则来帮助成组。如Peterson软件先将笔划分为点、边和文字,然后计算出一系列笔划的可量化属性特征,如长度、角度、纵横比和时空上下文等,并采用了AdaBoost分类器进行笔划成组。这种方法使用的信息形式相对单一,也因此难以突破笔划成组方法在性能表现上的瓶颈。
技术实现要素:
本发明所要解决的问题是提高手绘流程图识别的速度和准确性,增强用户体验。
为解决上述问题,本发明采用的方案如下:
根据本发明的一种基于眼动数据的流程图笔划成组的方法,包括以下步骤:
S1:当用户绘制流程草图时从眼动仪获取眼动数据;
S2:根据对眼动数据的分析得到注视点集;所述注视点集为注视点的集合;
S3:根据注视点集计算屏幕上各点的热值;
S4:对屏幕上各点的热值用阈值进行过滤得到热点集;所述热点集为坐标点的集合;
S5:对热点集进行聚类分析得到热区集;所述热区集为热区的集合;所述热区包括热区中心和热区中心所对应的热点集;
S7:以热区中心为中心点向外逐步扩展查询中心点扩展区域内构成封闭区域的笔划,将构成封闭区域的笔划设为热区所对应的笔划组。
进一步,根据本发明的基于眼动数据的流程图笔划成组的方法,所述步骤S3包括以下步骤:
S31:为每个注视点在屏幕上构建注视区;
S32:计算注视区内各点的热值,注视区内各点的热值反比于该点与注视点的距离;
S33:将每个注视点所对应的注视区中各点的热值累加到屏幕上相应的坐标点上。
进一步,根据本发明的基于眼动数据的流程图笔划成组的方法,所述步骤S31中所述注视区是以注视点为中心,边长为L的正方形区域。
进一步,根据本发明的基于眼动数据的流程图笔划成组的方法,所述注视点包含该注视点的绝对注视时长T;所述步骤S31中的注视区是以注视点为中心,半径为R的圆形区域;所述步骤S32中注视区内各点的热值正比于该注视点的绝对注视时长T。
进一步,根据本发明的基于眼动数据的流程图笔划成组的方法,所述步骤S5之后,步骤S7之前还包括步骤S6,对热区集进行过滤,剔除合并覆盖面积小的热区;所述步骤S5中的聚类分析采用DBSCAN算法。
根据本发明的一种基于眼动数据的流程图笔划成组的装置,包括以下模块:
M1,用于:当用户绘制流程草图时从眼动仪获取眼动数据;
M2,用于:根据对眼动数据的分析得到注视点集;所述注视点集为注视点的集合;
M3,用于:根据注视点集计算屏幕上各点的热值;
M4,用于:对屏幕上各点的热值用阈值进行过滤得到热点集;所述热点集为坐标点的集合;
M5,用于:对热点集进行聚类分析得到热区集;所述热区集为热区的集合;所述热区包括热区中心和热区中心所对应的热点集;
M7,用于:以热区中心为中心点向外逐步扩展查询中心点扩展区域内构成封闭区域的笔划,将构成封闭区域的笔划设为热区所对应的笔划组。
进一步,根据本发明的基于眼动数据的流程图笔划成组的装置,所述模块M3包括以下模块:
M31,用于:为每个注视点在屏幕上构建注视区;
M32,用于:计算注视区内各点的热值,注视区内各点的热值反比于该点与注视点的距离;
M33,用于:将每个注视点所对应的注视区中各点的热值累加到屏幕上相应的坐标点上。
进一步,根据本发明的基于眼动数据的流程图笔划成组的装置,所述模块M31中所述注视区是以注视点为中心,边长为L的正方形区域。
进一步,根据本发明的基于眼动数据的流程图笔划成组的装置,所述注视点包含该注视点的绝对注视时长T;所述模块M31中的注视区是以注视点为中心,半径为R的圆形区域;所述模块M32中注视区内各点的热值正比于该注视点的绝对注视时长T。
进一步,根据本发明的基于眼动数据的流程图笔划成组的装置,还包括模块M6,对热区集进行过滤,剔除合并覆盖面积小的热区;所述模块M5中的聚类分析采用DBSCAN算法。
本发明的技术效果如下:本发明的方法可以与流程草图绘制同步进行,笔划分组速度快,准确性高,为后续的识别打下了坚实的基础。绘制流程过程中无对笔划顺序、绘制时长等因素的要求或附加以符号间停顿等约束,从而大大提高了用户体验。
附图说明
图1是注视点热值累加计算的示意图。
图2是注视点屏幕热值化后和聚类分析后的效果图。
图3是由热区对流程草图进行笔划分组的示例图。
具体实施方式
下面结合附图对本发明做进一步详细说明。
本实施例涉及一种流程图草图输入的设备。该设备由主机、显示屏、输入设备以及眼动仪。显示屏、输入设备和眼动仪连接主机。输入设备可以是鼠标,也可以是手写笔,甚至可以是触摸显示屏。主机内设有CPU、RAM和持续化存储器。持续化存储器内存储有流程草图输入识别的程序,当该程序通过CPU执行时,用户可以通过输入设备在显示屏上画出流程草图,并且该程序执行时能够对用户所画的流程草图进行识别生成规范化的流程图。当用户通过输入设备在显示屏上画流程草图时,眼动仪采集用户的眼动数据。主机通过执行程序获取眼动仪所采集的眼动数据。这个过程,也即前述的步骤S1,当用户绘制流程草图时从眼动仪获取眼动数据。当用户画完流程草图时,主机根据眼动数据对流程草图进行笔划成组分析,然后对分组后的笔划组进行进一步识别。本发明所涉及的一种基于眼动数据的流程图笔划成组的方法和装置,即为前述的根据眼动数据对流程草图进行笔划成组分析。而后续对分组后的笔划组进行识别的过程不是本发明所讨论的范畴,无需赘述。本实施例,根据眼动数据对流程草图进行笔划成组分析的具体步骤如下:
S2:根据对眼动数据的分析得到注视点集;
S3:根据注视点集计算屏幕上各点的热值;
S4:对屏幕上各点的热值用阈值进行过滤得到热点集;
S5:对热点集进行聚类分析得到热区集;
S6,对热区集进行过滤,剔除合并覆盖面积小的热区;
S7:以热区中心为中心点向外逐步扩展查询中心点扩展区域内构成封闭区域的笔划,将构成封闭区域的笔划设为热区所对应的笔划组。
下面对上述步骤做进一步详细描述。
步骤S2的输出是注视点集。注视点集是注视点的集合。注视点是用户在屏幕上长时间凝视的点。注视点的分析依赖于眼动仪所能采集的数据和眼动仪API。倘若调用眼动仪API不能直接获得注视点,注视点可以采用以下方法获取:在步骤S1中通过眼动仪采集眼动数据时,按一定的时间间隔,比如10毫秒或15毫秒,获取眼球注视的坐标点。由此得到的眼动数据时按一定时间间隔获得的坐标点序列。然后对每个坐标点的前后进行比较,假如有N(N>1)个连续的坐标点相同,可视为用户在该坐标点凝视了一段时间,而作为注视点。采用这种方法,还可以获得注视点的绝对注视时长:找到注视点后,从眼动数据中统计与该注视点坐标相同点的数目即为绝对注视时长。本实施例中步骤S2中所输出的注视点集的各个注视点包含了该注视点的绝对注视时长。也就是注视点定义为:{P,T}。其中,P为注视点的坐标,T为注视点的绝对注视时长。需要说明的是,这里注视点的坐标P是经过屏幕坐标映射转化的,对应了显示屏上的坐标点。注视点坐标的屏幕坐标映射为本领域技术人员所熟悉,本说明书不再赘述。
步骤S2得到的注视点仅仅是一个坐标点,但实际上,这样一个坐标点反应了用户视觉的范围。此时,用户的视觉范围可以视为是以这个坐标点中心的一块区域。这样一块区域才是真实反应用户视觉所关注的范围。为真实体现这样一个视觉关注的范围,本实施例通过对屏幕上每个坐标点赋值于一定的数值。这个数值就是热值,体现了用户对该点的关注度。屏幕上不同的热值的点组成热区。步骤S3就是通过步骤得到注视点对屏幕上点进行热值化的步骤。这种热值化的方法有很多种,本实施例采用如下步骤实现:
S31:为每个注视点在屏幕上构建注视区;
S32:计算注视区内各点的热值,注视区内各点的热值反比于该点与注视点的距离;
S33:将每个注视点所对应的注视区中各点的热值累加到屏幕上相应的坐标点上。
步骤S31中的注视区是以注视点为中心的区域。最好的方式是这样一个注视区是以注视点为中心、半径为R的圆形区域,或者是以注视点为中心、长轴半径为a、短轴半径为b的椭圆形区域。为便于处理,该区域也可以设定为以注视点为中心、边长为L的方形区域,或者可以设定为以注视点为中心、宽为W、高为H的长方形区域。这里,R、a、b可以预先设定为20~50;W、H可以预先设定为40~80。考虑到注视点还包含了绝对注视时长的数据,也可以将该注视区范围的大小设定为与绝对注视时长相关,绝对注视时长越大,注视区范围也越大。比如,假设注视区是以注视点为中心、半径为R的圆形区域,半径R的取值为:当T<20时,R=5+T×1.5,否则R=35。这里,根据步骤S2所描述,绝对注视时长T必然大于0。
步骤S32中注视区内各点热值的计算可以采用以下公式:
其中,C、α、β均为预先设定的常量,D为注视区内的点与注视点之间的距离,T为注视点绝对注视时长,H(x,y)表示注视区内坐标为x,y点的热值。简单的情形下,C、β可设为1,α可设为0。由此上述公式可以简化为:通常情况下,注视区内的点与注视点之间的距离D可以采用普通的欧拉公式进行计算:考虑到眼球水平关注和竖直关注的不同,D可以用以下公式进行替换:
其中h为水平系数,可取值为1.0~1.2;v为竖直系数,可取值为0.85~1.0。
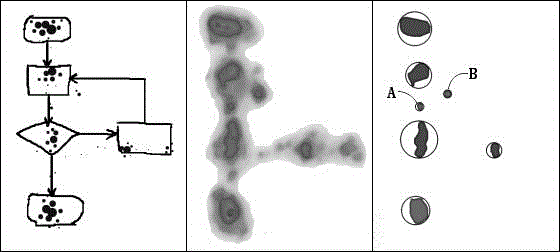
步骤S33是热值累加计算的步骤,将每个注视点所对应的注视区中各点的热值累加到屏幕上相应的坐标点上。如图1所示,1,2,3,4是四个圆圈表示四个注视区,注视区的圆心即为注视点。四个圆圈大小不一,注视区范围考虑的绝对注视时长,圆圈大的绝对注视时长长,圆圈小的绝对注视时长短。斜线部分是两个注视区重叠的部分,其相应的热值由两个注视区内的热值相加得到。阴影部分是三个注视区重叠的部分,,其相应的热值由三个注视区内的热值相加得到。实际过程中,注视点有很多,相应的重叠也会有很多。图2是本实施例注视点屏幕热值化后和聚类分析后的效果图,其中,左侧部分是用户所绘制的流程草图,中间部分是上述步骤S31、S32、S33处理后注视点屏幕热值化后的效果。其中,灰度表示热值,颜色越深表示热值越高,颜色越浅表示热值越低。
步骤S4,对屏幕上各点的热值用阈值进行过滤得到热点集。热点集是坐标点的集合。具体可以通过以下步骤:首先将屏幕上各点的热值进行归一化处理,将热值映射至0~1的区间,然后选取大于阈值0.5的点组成热点集。对于图2的以0~255灰度表示的热值中,可以直接选取灰度值大于127的点组成热点集。
步骤S5:对热点集进行聚类分析得到热区集。聚类分析的算法有很多种,比如k-means算法、DBSCAN算法。考虑到k-means算法需要确定k值,本实施例优选采用DBSCAN算法。DBSCAN算法为本领域技术人员所熟悉,其具体的算法本说明书不再赘述。图2右侧部分是根据中间部分的热值化的注视点进行聚类分析后的效果图。其中阴影部分是步骤S4经过阈值过滤后得到的热点集的范围,圆圈中心为经聚类算法分析后得到的聚类中心。圆圈所围区域为热区,圆圈的大小为热区半径。由图2可见,经步骤S5聚类分析得到了7个聚类中心,由此产生7个热区组成热区集。这里,热区集为热区的集合。热区包括热区中心和热区中心所对应的热点集。热区中心也就是聚类中心。
步骤S6,对热区集进行过滤,剔除合并覆盖面积小的热区。如图2所示,经步骤S5聚类分析得到了7个聚类中心,其中两个聚类中心A和B的范围很小,需要剔除合并。剔除合并的过程具体可以采用如下步骤实现:
S61:计算热区的热点集中各个热点与热区中心的平均距离d;
S62:当平均距离d小于阈值T1时,通过计算各热区与该热区之间的中心距离,找出与该热区最近的热区P;
S63:当热区P与该热区的中心距离小于阈值T2时,合并热区P和该热区,否则删除该热区。
上述步骤中,阈值T1和T2均为预先设定的常数,中心距离是两个热区的热区中心的距离。需要指出的是,步骤S6是步骤S5聚类分析的延伸,可以视为聚类分析的一部分。倘若步骤S5中聚类分析的算法足够好,那么步骤S6可以省略。本实施例步骤S6是基于步骤S5中的聚类算法采用DBSCAN算法下的步骤,是DBSCAN算法后续补充。如图2所示,通过上述步骤S6的处理,可以剔除掉热区A和B。
步骤S7:以热区中心为中心点向外逐步扩展查询中心点扩展区域内构成封闭区域的笔划,将构成封闭区域的笔划和封闭区域内的笔划设为热区所对应的笔划组。该步骤的具体过程如下:以图3中的其中一个热区为例,首先以前述热区中心为中心点、以热区半径为半径构建圆形范围S0,判断该圆形范围内是否存在构成封闭区域的笔划;如果没有,则增加圆形范围的半径形成圆形范围S1,然后判断圆形范围S1内是否存在构成封闭区域的笔划;如果没有,则继续增加圆形范围的半径,直到当圆形范围的半径增加至圆形范围S2时,流程草图中节点菱形的语义符号落入了圆形范围S2内,然后将组成该节点菱形的笔划组成相对应的笔划组,从而完成笔划成组。
- 还没有人留言评论。精彩留言会获得点赞!