基于内存计算框架和长短周期兴趣迁移及融合模型的音乐推荐方法与流程
本发明涉及计算机领域,尤其涉及一种基于内存计算框架和长短周期兴趣迁移及融合模型的音乐推荐方法。
背景技术:
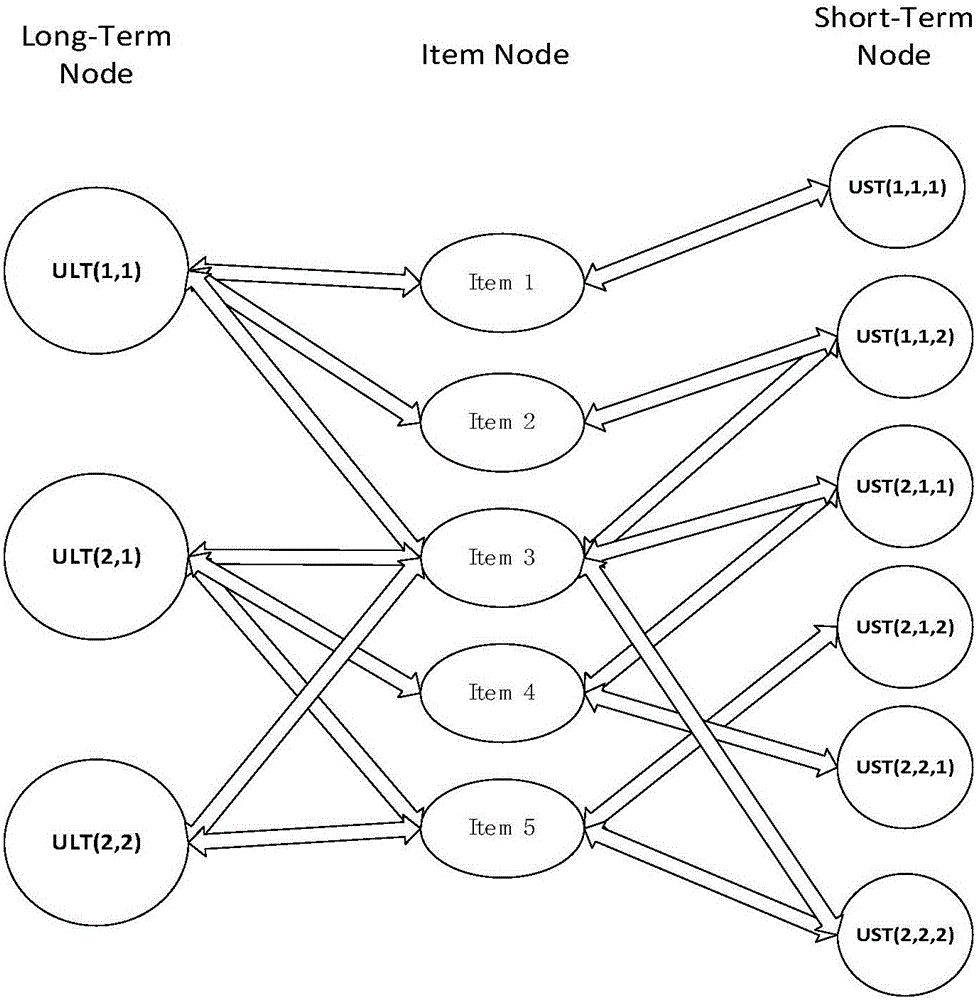
:近年来,随着互联网信息的爆发式增长,人工智能和大数据处理成为计算机领域一股新的风潮,而对于不同领域的信息的精确性挖掘显得更加迫切。个性化推荐技术应运而生,不同于搜索引擎,推荐系统需要更少的精确描述来寻找用户感兴趣信息。传统的推荐算法主要有基于协同过滤的推荐方法、基于内容的推荐方法和混合类型的推荐算法。这些方法都存在各自的局限性。其中,基于协同过滤的推荐方法通过计算用户或者商品之间相似度,寻找目标用户或商品的最近邻,最后根据最近邻的评分结果进行预测推荐。基于内容的推荐方法获取更多的有效信息比较用户商品主题匹配程度形成推荐列表。虽然这些传统的推荐方法使用广泛,但是它们没有将用户的兴趣迁移的情况考虑进去。用户的兴趣不会一成不变,随着时间的递进,用户的兴趣会存在不同程度的变化。传统的静态推系统难以处理变化频繁的数据,只有充分考虑时间变化对个性化推荐的影响,推荐系统才能得到更加准确的结果。ApacheSpark是个开源和兼容Hadoop的集群计算平台,由加州大学伯克利分校的AMPLabs开发。Spark使用内存缓存来提升性能,因此进行交互式分析足够快速。缓存同时提升了迭代算法的性能,这使得Spark非常适合数据理论任务,特别是机器学习。因此,通过结合Spark的内存计算框架缩短算法的计算时间的方法适用于大数据环境下的推荐算法模型的训练。虽然推荐系统中考虑了时间因素的影响,但是不同时间跨度上的数据反映的用户兴趣存在差异,它们之间具有较大的倾向区分度,因此现在的推荐系统亟需一种兼顾长短周期兴趣的个性化推荐方法。技术实现要素:本发明旨在至少解决现有技术中存在的技术问题,特别创新地提出了一种基于内存计算框架和长短周期兴趣迁移及融合模型的音乐推荐方法。为了实现本发明解决传统的推荐算法中忽略用户兴趣迁移的问题,考虑不同时间跨度下的用户兴趣的不同影响,提高推荐算法在高频度更新数据中的准确率和召回率的目的,本发明提供了一种基于内存计算框架和长短周期兴趣迁移及融合模型的音乐推荐方法,包括:S1:搭建ApacheSpark框架,实现算法整体的分布式运行;利用SparkMLlib模块实现算法,加快算法运行速度;S2:获取数据中所有用户对不同音乐的收听次数,对获取的数据进行预处理,利用收听记录计算所有用户的音乐评分;S3:将时序数据整理成周期数据集合;S4:构建长短周期兴趣迁移模型;S5:构建长短周期图模型;S6:结合S3生成的长短周期兴趣和S4中的长短周期图模型进行音乐推荐。所述的基于内存计算框架和长短周期兴趣迁移及融合模型的音乐推荐方法,优选的,步骤S2中所述的数据进行预处理的步骤:S2-1、S1中利用Spark搭建形成包含master和若干slave的集群;然后本发明将数据导入master主机中,由master进行分割,将数据的预处理任务分派给slave机器,同时追踪slave机器上的分布式计算,收集slave机器的反馈信息进行汇总统计;S2-2、将整个数据分割为用户个人记录信息,对个人数据中用户收听记录进行统计,将收听记录过少的用户删除,留存包含足够信息的用户;S2-3、同时,统计每位音乐被收听记录,如果音乐被收听次数过少,不能充分反映用户的兴趣,将相关记录删除;S2-4、依据S2-1和S2-2步骤的清理结果,以当前时间为准,统计该时间之前的数据,获取用户对于音乐的收听记录;S2-5、用户对于音乐的评价受到访问次数和访问最近时间的影响,所有用户的音乐的评分需要综合考虑这些因素,用户自身对于不同用户的收听次数存在上限和下限,根据用户收听习惯,设置分段函数赋予频次评分;构造一个线性函数对于用户的频次评分和收听时间距离进行加权平均化,获得最终的所有用户的音乐评分;S2-6、利用S2-4获取的所有用户的音乐评分矩阵,将用户对不同音乐的评价作为音乐特征进行聚类,生成相似音乐簇集,分别为各簇集赋予新的标签作为音乐类别标记。所述的基于内存计算框架和长短周期兴趣迁移及融合模型的音乐推荐方法,优选的,步骤S3中所述的时序数据整理成周期数据集合的步骤包括:S3-1、获取S2中清洗完毕后的数据,获取当前时间之前的用户历史收听记录;S3-2、根据不同周期类型,设置周期窗口;S3-3、沿着时间反向回溯行进,短周期窗口范围内的收听记录作为一个短周期数据块,然后行进一个短周期窗口长度时间能获取一个新的短周期数据块,依次类推;同理,获取长周期数据块,实际运行中由于长周期窗口长度是短周期窗口长度的整数倍。所述的基于内存计算框架和长短周期兴趣迁移及融合模型的音乐推荐方法,优选的,步骤S4中所述的构建长短周期兴趣迁移模型的步骤包括:S4-1、根据S3步骤中获取的周期数据集合,提取用户周期数据中的观察量和隐藏量;观察量为用户在周期数据中最喜爱的音乐,隐藏量为用户在该周期范围内喜爱音乐的所属类别;S4-2、周期数据集中的用户的喜爱音乐组成观察量序列O={o1,o2,...,oT},oi表示用户在i时刻下的喜欢的音乐;对应的个人兴趣组成隐变量序列Q={q1,q2,...,qT},qi表示用户在i时刻喜欢的音乐所属的类别,其中下标T为正整数;S4-3、依照改进的隐马尔科夫模型,对整理后的数据进行训练获取优化参数;将用户的观察量序列和隐变量序列输入模型中,设定初始化隐变量概率分布参数,利用EM算法进行参数优化训练;利用现有的期望最大化算法进行参数优化训练S4-4、利用S4-3步骤可以获取HMM的优化参数:隐变量的迁移矩阵A和隐变量条件下的观察变量概率分布B;计算用户兴趣偏向和喜爱音乐的概率:P(ST+1=qi)和P(OT+1=oi),其中,ST+1指的是T+1时刻用户的状态,即用户感兴趣音乐类别,而OT+1表示T+1时刻的用户观察值,即用户感兴趣的音乐;计算当前时间窗口范围内,用户对相关音乐的评分:Score=B*An*P(ST+1=qi)nScore=Score/Σoi∈OScorc(oi)]]>S4-5、依照S4-4步骤已经获取了用户对于相关音乐的评分,根据S3的划分周期数据集合分为长周期数据集合和短周期数据集合;利用该区别分别计算当前时间所属长短周期的不同音乐评分,形成长周期推荐列表和短周期推荐列表。所述的基于内存计算框架和长短周期兴趣迁移及融合模型的音乐推荐方法,优选的,步骤S5中所述的构建长短周期图模型工的步骤包括:S5-1、长短周期图模型(LSTG)由三种节点构成:长周期节点、短周期节点和商品节点;长周期节点表示用户在长周期阶段的兴趣,相应的短周期节点表示的用户在短周期阶段的兴趣,而商品节点表示的用户对于该商品的喜爱程度;LSTG是一种三部图,三种节点只与相邻类型的节点连接,不与相同类型的节点连接;长周期节点只与商品节点连接,商品节点处于中间,商品节点与长短周期节点连接,而短周期节点只与商品节点连接;周期节点与商品节点的连接表示用户在该周期范围内对商品节点表示的商品感兴趣;S5-2、图模型之间通过传递用户兴趣连接;而不同类别节点之间兴趣传递效率不同,这些由节点连接边的权重确定;其中长周期节点集合Long-TermNodes简写为LT,短周期节点集合Short-TermNodes简写为ST,商品节点集合ItemNodes简写为I;节点连接权重如下所示:其中下标i,j为序号,ηLT表示由商品节点指向长周期节点的边权重,而ηST表示由商品节点指向短周期节点的边权重;S5-3、初始化工作通过为初始长短周期节点赋值,初始长短周期节点的值表示长短周期在整体兴趣形成中占据的比例;长周期节点初始值为a,短周期节点初始值为b,其中a+b=1。所述的基于内存计算框架和长短周期兴趣迁移及融合模型的音乐推荐方法,优选的,步骤S6中所述的音乐推荐的步骤包括:S6-1、由S5步骤可以获取在当前时间段中的长周期推荐列表和短周期推荐列表;将当前时间段的结果制作成新的长短周期节点添加进入长短周期图模型中,同时将这两个节点作为初始化节点进行初始化赋值;S6-2、兴趣在节点之间游走会产生一条兴趣传播路径,如果初始节点为v0,终点节点为vn,那么其中路径为{v0,v1,v2......vn};结合S5中连接边权重,路径评分公式表示为n≥1,为正整数S6-3、商品节点的最终兴趣值由所有指向商品节点的路径决定;因此,获取得到商品节点的兴趣值评分公式其中path(u,i)为用户兴趣传播路径S6-4、根据S6-3公式获取用户u对于音乐i的个性化评分PR(u,i);按照音乐曲目评分次序选出top-n首音乐曲目组成推荐列表作为最终推荐结果。综上所述,由于采用了上述技术方案,本发明的有益效果是:通过本发明推荐算法中根据用户兴趣迁移兴趣类型,考虑不同时间跨度下的用户兴趣的不同影响,提高推荐算法在高频度更新数据中的准确率和召回率,更加准确的提升音乐的匹配程度,让用户获得更好的音乐推荐满意度。同时,本推荐算法结合内存计算框架,有效缩短了模型的训练时间,提高了针对个性化用户的实时推荐的能力。本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。附图说明本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:图1是长短周期兴趣迁移模型的基本示意图;图2是长周期图模型的基本构造示意图;图3是本发明具体实施的流程示意图。具体实施方式下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。在本发明的描述中,需要理解的是,术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。在本发明的描述中,除非另有规定和限定,需要说明的是,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是机械连接或电连接,也可以是两个元件内部的连通,可以是直接相连,也可以通过中间媒介间接相连,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。图1是长短周期兴趣迁移模型的基本示意图;图2是长周期图模型的基本构造示意图;如图3所示,一种基于内存计算框架和长短周期兴趣迁移及融合模型的音乐推荐方法,算法按以下步骤进行:S1:搭建ApacheSpark框架,实现算法整体的分布式运行。利用SparkMLlib模块实现算法,加快算法运行速度。S2:获取数据中所有用户对不同音乐的收听次数,利用收听记录计算用户对音乐评分。S3:将时序数据整理成周期数据集合S4:构建长短周期兴趣迁移模型S5:构建长短周期图模型S6:结合S3生成的长短周期兴趣和S4中的长短周期图模型进行音乐推荐步骤S2中所述的数据预处理工作按照以下步骤进行:A1、S1中本发明利用Spark搭建形成包含master和若干slave的集群。然后本发明将数据导入master主机中,由master进行分割,将数据的预处理任务分派给slave机器,同时追踪slave机器上的分布式计算,收集slave机器的反馈信息进行汇总统计。A2、将整个数据分割为用户个人记录信息,对个人数据中用户收听记录进行统计,将收听记录过少的用户删除,留存包含足够信息的用户。A3、同时,统计音乐被收听记录,如果音乐被收听次数过少,不能充分反映用户的兴趣,将相关记录删除。A4、依据A1和A2步骤的清理结果,以算法中当前时间为准,统计该时间之前的数据,获取用户对于音乐的收听记录。A5、用户对于音乐的评价受到访问次数和访问最近时间的影响。用户-音乐的评分需要综合考虑这些因素,用户自身对于不同用户的收听次数存在上限和下限(下限一般为1或2,上限不定),根据用户收听习惯,设置分段函数赋予频次评分。用户的频次评分只考虑用户的全部的历史记录,忽略了时间对当前真实评分的影响。构造一个线性函数对于用户的频次评分和收听时间距离进行加权平均化,获得最终的用户-音乐评分。A6、利用A4获取的用户-音乐评分矩阵,将用户对不同音乐的评价作为音乐特征进行聚类,生成相似音乐簇集,分别为各簇集赋予新的标签作为音乐类别标记。步骤S3中所述的时序数据整理成周期数据集合工作按照以下步骤进行:B1、获取S2中清洗完毕后的数据,获取当前时间之前的用户历史收听记录。B2、根据不同周期类型,设置周期窗口。其中,长周期窗口长度设置为7天,短周期窗口长度设置为1天。B3、沿着时间反向回溯行进,短周期窗口范围内的收听记录作为一个短周期数据块,然后行进一个短周期窗口长度时间可以获取一个新的短周期数据块,依次类推。同理,可以获取长周期数据块,实际运行中由于长周期窗口长度是短周期窗口长度的整数倍,所以7个短周期窗口数据块可以组成一个长周期数据块。步骤S4中所述的构建长短周期兴趣迁移模型工作按照以下步骤进行:C1、根据S3步骤中获取的周期数据集合,提取用户周期数据中的观察量和隐藏量。观察量为用户在周期数据中最喜爱的音乐,隐藏量为用户在该周期范围内喜爱音乐的所属类别,即用户兴趣(按照投票机制,获得票数最高的作为用户兴趣)。C2、周期数据集中的用户的喜爱音乐组成观察量序列O={o1,o2,...,oT},oi表示用户在i时刻下的喜欢的音乐;对应的个人兴趣组成隐变量序列Q={q1,q2,...,qT},qi表示用户在i时刻喜欢的音乐所属的类别,其中下标T为正整数;C3、依照改进的隐马尔科夫模型(HMM),对整理后的数据进行训练获取优化参数。将用户的观察量序列和隐变量序列输入模型中,设定初始化隐变量概率分布参数,利用EM(ExpectationMaximization)算法进行参数优化训练。C4、利用C3步骤可以获取HMM的优化参数:隐变量的迁移矩阵A和隐变量条件下的观察变量概率分布B。计算用户兴趣偏向和喜爱音乐的概率:P(ST+1=qi)和P(OT+1=oi)。计算当前时间窗口范围内,用户对相关音乐的评分:Score=B*An*P(ST+1=qi)nScore=Score/Σoi∈OScorc(oi)]]>C5、依照C4步骤已经获取了用户对于相关音乐的评分,根据S3的划分周期数据集合分为长周期数据集合和短周期数据集合。利用该区别分别计算当前时间所属长短周期的不同音乐评分,形成长周期推荐列表和短周期推荐列表。步骤S5中所述的构建长短周期图模型工作按照以下步骤进行:D1、长短周期图模型(LSTG)由三种节点构成:长周期节点、短周期节点和商品节点。LSTG是一种三部图,三种节点只与相邻类型的节点连接,不与相同类型的节点连接。长周期节点只与商品节点连接,商品节点处于中间,可以与长短周期节点连接,而短周期节点只与商品节点连接。周期节点与商品节点的连接表示用户在该周期范围内对商品节点表示的商品感兴趣。D2、图模型之间通过传递用户兴趣连接。而不同类别节点之间兴趣传递效率不同,这些由节点连接边的权重确定。其中L表示长周期节点集合,S表示短周期节点集合,I表示商品节点集合。节点连接权重如下所示:w(vi,vj)=1vi∈L∪S,vj∈Iηlvi∈I,vj∈Lηsvi∈I,vj∈S]]>D3、初始化工作通过为初始长短周期节点赋值,初始长短周期节点的值表示长短周期在整体兴趣形成中占据的比例。长周期节点初始值为a,短周期节点初始值为b,其中a+b=1。步骤S6中所述的音乐推荐工作按照以下步骤进行:E1、由S5步骤可以获取在当前时间段中的长周期推荐列表和短周期推荐列表。将当前时间段的结果制作成新的长短周期节点添加进入LSTG中,同时将这两个节点作为初始化节点进行初始化赋值。E2、兴趣在节点之间游走会产生一条兴趣传播路径,如果初始节点为v0,终点节点为vn,那么其中路径为{v0,v1,v2,...,vn}。结合S5中连接边权重,路径评分公式可以表示为Ratc(P)=Πvk∈P,0≤k≤nψ(vk,vk+1)α(v0)]]>E3、商品节点的最终兴趣值由所有指向商品节点的路径决定。因此,可以获取得到商品节点的兴趣值评分公式PR(u,i)=ΣP∈path(u,i)Rate(P)]]>E4、根据E3公式可以获取用户u对于音乐i的个性化评分PR(u,i)。按照音乐评分次序选出top-n首音乐组成推荐列表作为最终推荐结果。在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1