一种基于动态帧时隙的二进制树RFID防碰撞方法与流程
本发明属于无线射频识别
技术领域:
中的多标签读取技术,涉及到解决RFID系统中多标签碰撞问题的方法。
背景技术:
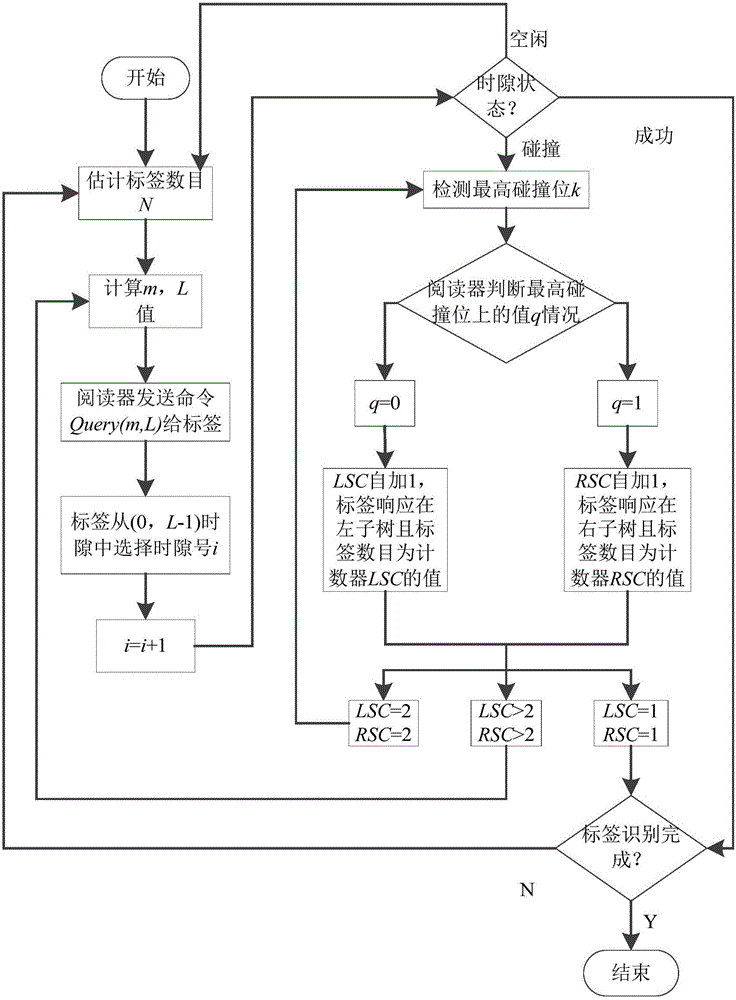
:无线射频识别(RadioFrequencyIdentification,RFID)技术作为物联网的核心技术之一,正随着物联网的快速发展被广泛的应用到各个领域。无线射频识别技术是一种以空间电磁波为传输媒介的非接触式数据自动采集技术,其基本原理是利用电磁传播和射频信号来实现对待识别物体的自动识别。与传统的识别技术相比,它可在非接触、非光学可视、非人工干预情况下完成信息输入和处理,具有操作方便、存储量大,保密性好、反应时间短、对环境适应性强等优点,现已广泛应用于门禁、交通、食品安全及物流等领域。典型的RFID系统一般由电子标签(Tag)、阅读器(Reader)和后端数据库(Database)三大部分组成,在多个阅读器与多个标签的射频识别系统中,存在着阅读器碰撞和标签碰撞,由于读写器发生碰撞的概率相对较小,而读写器本身又有较强的信息处理能力,所以当今的研究较集中在标签碰撞,即当有两个或两个以上的标签同时向阅读器发送数据时,阅读器就会出现接收数据冲突,导致阅读器无法正确识别标签信息。为了解决多标签碰撞问题,目前已经提出了很多标签防碰撞算法,主要有两大类:基于ALOHA算法的不确定性算法和基于二进制树的确定性算法。ALOHA算法通过标签随机响应和阅读器检测标签状态来实现信息交换,主要包括纯ALOHA(PureALOHA,PA)算法、时隙ALOHA(SlottedALOHA,SA)算法、帧时隙ALOHA(Frame-slottedALOHA,FSA)算法和动态帧时隙ALOHA(DynamicFrame-slottedALOHA,DFSA)算法等。这些算法的优点是设计简单,标签和阅读器都不需要执行复杂的运算,但当标签数目增大时,标签发生碰撞的概率极大,算法性能降低,并且由于时隙选择存在一定的可能性,某些标签可能会出现长时间不被识别。二进制树搜索算法多用于超高频段,EPCGlobal的Class0标准采用的就是基于位操作的二进制搜索树算法,通过逐位比较,依次识别出唯一的标签ID,现有动态二进制树搜索算法(DynamicBinarySearchTree,DBST)、后退式二进制树搜索算法(Regressive-styleBinarySearchTree,RBST)、跳跃式动态树算法(JumpingandDynamicSearchingTree,JDST)和查询树算法(QueryTree,QT)等。虽然此类算法能实现100%的标签读取率,但当标签位数较大时,即标签数目庞大时,碰撞的频率会大大增加,而且每次碰撞只能产生两个分支,识别时间会急剧增加,搜索效率会降低。技术实现要素:本发明的目的是克服现有技术的不足,提出一种基于动态帧时隙的二进制树RFID防碰撞方法。本发明融合了ALOHA算法和二进制树搜索算法提出了动态帧时隙的二进制树(DynamicFramedBinaryTree,DFBT)防碰撞算法,实验仿真表明本发明比现有的RFID标签防碰撞算法具有较高的吞吐率和识别效率。本发明是通过以下技术方案实现的。1、Vogt算法估计标签数目。标签数量估计对算法的性能起着至关重要的作用,在识别标签前先估计标签数量是为了更好更准确的动态调整帧长,使得算法性能达到最大。目前已有的标签数量估计算法主要有:Vogt算法、Schoute算法和LowBound算法等。当标签数目庞大时,Vogt算法来估计标签数量能有效地减少误差。对于帧长为L,待识别标签数目为N,利用切比雪夫不等式可以得到:ϵ(L,c0,c1,ck)=min|a0a1ak-c0c1ck|---(1)]]><c0,c1,ck>是前一个阅读周期的结果,是将空闲时隙、识别时隙和碰撞时隙分别量化后得到的空闲时隙数、成功时隙数和碰撞时隙数。<a0,a1,ak>分别是空闲时隙、成功时隙和碰撞时隙的期望值。某个标签占用帧内任意时隙的概率为:P=1L---(2)]]>同一时隙有M个标签的概率为:P(L,N,M)=CNM(1L)M(1-1L)N-M---(3)]]>一个时隙中无请求识别标签的概率为:Pi=P(L,N,0)=(1-1L)N---(4)]]>一个时隙中只有一个请求标签的概率为:Ps=P(L,N,1)=NL(1-1L)N-1---(5)]]>一个时隙中有两个或两个以上请求识别标签的概率为:Pc=1-Ps-Pi(6)则在一帧的识别周期之后,没有标签时隙数的期望值a0,仅有一个标签时隙数的期望值a1,产生碰撞时隙数的期望值ak分别为:a0=L×Pi=L(1-1L)N---(7)]]>a1=L×Ps=N(1-1L)N-1---(8)]]>ak=L×Pc=L-a0-a1(9)2、本发明方法描述。2.1帧长优化分析。由帧时隙ALOHA算法分配时隙的规则可知,帧长L必须为2的整数幂,即L=2m,本发明方法中m代表的是决定时隙的位数,这样标签就可以根据自身ID中的m位来决定一帧中选择的时隙号。某n个标签的某一位相同的概率为:P(n)=C21(12)n=12n-1---(10)]]>一个时隙中有n个标签同时发送的概率为:P(n,m)=[C21(12)n]m---(11)]]>当标签总数为N时,某个时隙中有n个标签同时发送的概率为:P(N,m,n)=CNn[C21(12)n]m[1-(12)m]N-n---(12)]]>某一时隙为成功时隙的概率为:P(N,m,1)=N[1-(12)m]N-1---(13)]]>一帧中成功时隙个数的期望值S1为:S1=E(N,m,1)=N·2m[1-(12)m]N-1---(14)]]>对S1求导,令其导函数为0,得到期望值的最小值即为m值:dE(N,m,1)dm=ln2·N[1-(12)m]N-2(2m-N)=0---(15)]]>即:则本发明方法帧长为:其中表示向下取整运算,从而得到了帧长L与待识别标签数目N的关系式,为了说明本发明方法帧长得到了优化,将与DFSA算法作对比,如表1所示:表1DFSA算法和本发明算法帧长的对比标签数目501002003004005006007008009001000DFSA帧长501002003004005006007008009001000本发明帧长32641282562562565125125125125122.2分配时隙规则。为了减少标签反复碰撞,标签选择时隙规则作了规定:首先阅读器发送查询命令,待识别标签收到命令后检查自己ID,符合要求的标签响应,然后阅读器检测响应标签的最高碰撞位k,则响应标签选择时隙号由ID的最高碰撞k位起的m位决定,标签分配时隙示意图如图1所示。例如假设系统中有4个标签,其ID分别为1000、1101、0100和0011,根据式(16)得出m=2,阅读器检测最高碰撞位k=3,则标签选择时隙号由ID码中的第3位和第2位决定,即(10)2=2,(11)2=3,(01)2=1,(00)2=0,因此它们分别响应在时隙2、时隙3、时隙1和时隙0中。2.3具体执行步骤。一般来说,在RFID系统中,每个标签中都含有两个计数器LSC和RSC,LSC定义为碰撞位为“0”标签计数器,RSC定义为碰撞位为“1”标签计数器,图2为本发明提出DFBT算法流程图,具体执行步骤如下:(S01):在进行数据读取之前,首先用Vogt算法估计待识别标签的数目N。(S02):分别计算出决定标签选择时隙号位数m的值和帧长L的值。(S03):进行时隙扫描,阅读器发送Query(m,L)命令给每个标签,标签收到命令后,根据分配时隙规则在(0,L-1)时隙中选择各自所需时隙号i。(S04):阅读器判断第i个时隙的状态。然后执行以下三种情况在之一:1)若该时隙为成功时隙,则标签总数N=N-1,该轮识别结束后跳转至步骤(S09);2)若该时隙为空时隙,则跳转至步骤(S01),进行下一轮识别。3)若该时隙为碰撞时隙,则所有碰撞标签跳转至步骤(S05)。(S05):阅读器检测上一阶段的碰撞标签ID码的最高碰撞位k值,并检测和记录下最高碰撞位k上的数值q的大小。(S06):阅读器将标签ID最高碰撞位及前缀发送给每个碰撞标签,与碰撞标签ID本身对比,如果检测到发送的标签最高碰撞位及前缀与碰撞标签ID相同且最高碰撞位为“0”,则计数器LSC自加1,如果碰撞位为“1”,则计数器RSC自加1。(S07):阅读器作出判决:所有q=1的标签响应在二进制树的右子树,所有q=0的标签响应在二进制树的左子树,得到计数器LSC和计数器RSC的值,即分别响应在二进制树的左子树和右子树上标签数目。(S08):对计数器LSC和计数器RSC的值作出判断:若LSC>2且RSC>2,跳转到步骤(S02);若LSC=2且RSC=2,则跳转到步骤(S05);若LSC=1且RSC=1,则表明此轮识别结束,则标签总数N=N-2。(S09):判断上一轮识别结束后标签是否全部被识别:若标签总数N>1,说明标签未全部识别,则跳转到步骤(S01),进行下一轮的识别,直至全部标签识别完成;若标签总数N=0时,说明标签已全部识别完成,则搜索识别结束。本发明为了改善阅读器在识别多个标签过程中产生多标签碰撞存在的问题,结合已有的不确定性和确定性两类多标签防碰撞算法,融合了ALOHA算法和二进制树搜索算法,提出了一种基于动态帧时隙的二进制树(DynamicFramedBinaryTree,DFBT)防碰撞方法。利用Vogt算法预先估计待识别标签数目,动态调整帧长,再结合二进制树搜索算法实现对标签的识别。其仿真分析结果表明该方法不仅提高了系统的识别效率,还缩短了标签的识别时间,当标签数目达到1000左右,系统识别效率仍可以保持在64%左右,比动态帧时隙ALOHA算法和后退式二进制搜索树算法分别提高了210%和30%。通过对该方法的理论性能分析得出,识别效率的理论值与实验值的误差小于2%,在误差允许的范围之内,理论值与实验值基本保持一致,同时该方法能提高系统稳定性,在当今物联网领域具有良好的应用前景。本发明所述的基于动态帧时隙的二进制RFID防碰撞方法,其特征是结合了动态帧时隙ALOHA防碰撞算法和二进制搜索树防碰撞算法,并对帧长进行优化和标签选择时隙号规则进行调整,在识别全部标签的过程中,既可以减少所需要的总时隙数和识别时间,又可以提高系统识别效率和增加系统稳定性。附图说明图1为本发明提出DFBT算法分配时隙规则示意图。图2为本发明提出DFBT算法流程图。图3为本发明提出DFBT算法数例示意图。图4为本发明总时隙数理论分析与仿真分析对比。图5为本发明识别效率理论分析与仿真分析对比。图6为本发明与其他算法总时隙数对比。图7为本发明与其他算法识别效率对比。图8为本发明与其他算法碰撞时隙数对比。图9为本发明与其他算法识别时间对比。图10为本发明提出DFBT算法不同标签长度K的识别效率对比。具体实施方式本发明包括帧时隙处理阶段和碰撞时隙处理阶段两个阶段,为了进一步验证和说明本发明方法的理论分析的正确性,进行数例分析,操作流程参见图3。假设系统有10个标签A~J,标签的ID为8位,其ID码分别为TagA:110101111、TagB:10100111、TagC:01011111、TagD:10111010、TagE:01111101、TagF:10001011、TagH:10101110、TagI:01110000、TagJ:11100110,则具体实现过程如下:(1)第一轮搜索中,待识别标签数目N1=10,m1=3,阅读器发送查询命令Query(m1,L1),此时所有待识别标签都会响应,响应标签根据分配时隙规则选择响应的时隙号,成功识别标签A、C、F、G和J,其他标签均为碰撞标签。(2)阅读器检测碰撞标签的最高碰撞位k,可以得出k=7,即最高碰撞位为第7位,并记下k上的值q的大小,可得qE=qI=0,qB=qD=qH=1,进行第二轮搜索,标签E和I响应在二进制树的左子树,标签B、D和H响应在二进制树的右子树。(3)第三轮搜索中,待识别标签只有标签E和I,阅读器检测最高碰撞位k,可得k=3,并且最高碰撞位上的值分别为qE=1,qI=0,则标签E响应在右子树,标签I响应在左子树,成功识别标签E和I。(4)第四轮搜索中,待识别标签数目N2=3,m2=1,阅读器发送查询命令Query(m2,L2),此时标签B、D和H响应,阅读器检测最高碰撞位k,可得k=4,标签根据分配时隙规则选择时隙号,成功识别标签D。(5)第五轮搜索中,阅读器检测标签B和H的最高碰撞位并且记录下其最高碰撞位上的数值,可得qB=0,qH=1,则标签B响应在左子树,标签H响应在右子树,成功识别标签B和H。(6)所有标签全部识别成功,搜索结束。本发明方法识别系统中10个待识别标签,只需要进行5次搜索识别,产生的碰撞时隙有5个,空闲时隙有1个,其他均为成功时隙,需要的总时隙数为16个,相对于DFSA算法和RBST算法,减少了搜索次数和识别过程中所需要的总时隙数。本发明的性能分析:本发明结合了动态帧时隙ALOHA算法和二进制树搜索算法提出的一种新型防碰撞算法,该算法与DFSA算法、RBST算法和AHT算法相比较,在减少总时隙数、提高识别效率和缩短识别时间方面有明显的优势,并且该算法设计较简单,算法的识别效率不受标签ID长度的影响,增加了系统识别效率的稳定性,标签内部不需要设计复杂的电路,可以降低标签硬件的成本,因此该研究方案在当今物联网技术方面具有良好的应用前景。本发明实验结果和实验数据在IntelCore、CPUT6500@2.1GHZ、2GB的内存以及Windows7的环境下,采用MATLAB软件平台进行仿真,分别进行了7组对比仿真实验。(1)总时隙数理论结果与仿真结果分析阅读器识别标签过程所需要的总时隙数表示为动态帧时隙ALOHA算法所需要的总时隙数和二进制树搜索算法所需要的总时隙数之和。最后得出的平均总时隙数理论值为如图4所示表示总时隙数理论结果与仿真结果的对比,得出两者基本保持一致,误差小于2%。(2)识别效率理论结果与仿真结果分析系统的识别效率表示只用于识别标签的可读时隙与识别这些标签所需要的总时隙数的比率,分析得出平均识别效率的理论值为如图5所示表示识别效率的理论结果与仿真结果对比,得出两者的误差值小于2%,在误差允许的范围之内,两者基本保持一致,进一步验证了本发明方法的正确性、可靠性优越性。(3)总时隙数分析总时隙数是决定系统性能的一个重要指标,总时隙数越少,系统性能越好。相关的总时隙数分析采用以下步骤:①当RFID系统中待识别标签总数为N时,根据式(16)、(17)可以得出决定标签选择时隙号位数m的值和帧长L的值,此时帧长L的值即为该轮识别所需时隙数,在该轮识别中待识别标签会根据时隙分配规则选择相应的时隙号i,会产生成功时隙、碰撞时隙和空闲时隙;②再对响应在碰撞时隙中的碰撞标签进行最高碰撞位的检测,将最高碰撞位q=0的碰撞标签响应在二进制的左子树,将最高碰撞位q=1的碰撞标签响应在二进制树的右子树,该轮分裂碰撞标签所需时隙数为2个;③依次循环,直到所有待识别标签被识别为止,因此DFBT算法识别所有待识别标签所需总时隙数是帧时隙处理阶段所需时隙数和分裂碰撞标签所需时隙数之和。对FSA算法、DFSA算法、RBST算法、DFBT算法和自调整混合树防碰撞算法(AHT)的总时隙数进行仿真,仿真结果如图6所示。标签数目从0到1000变化,DFBT算法所耗总时隙数增加比较缓慢,而FSA算法和DFSA算法却增加的比较迅速,尤其是当标签数目比较大时,DFBT算法和RBST算法所耗总时隙数是呈线性增加的,而FSA算法和DFSA算法是呈指数增加的,当标签总数接近1000时,DFBT算法只需要约1554个时隙,比AHT算法减少约300,比FSA算法减少约4011,比DFSA算法减少了约3573,比RBST算法减少了约265。(4)识别效率分析系统识别效率也是衡量系统性能的一个重要指标。由于识别效率S定义为成功时隙数(标签总数)N与识别所有待识别标签所需总时隙数之比,因此DFBT算法的识别效率只与标签总数和总时隙数有关。为验证DFBT算法在识别效率上得到提高,对比算法为FSA算法、DFSA算法、RBST算法和AHT算法,仿真结果如图7所示。DFBT算法的识别效率可以保持在0.61以上,最大可以达到0.64,当标签总数相同相同时,DFBT算法的识别效率比对比的三种算法都要高,当标签总数达到1000时,DFBT算法的识别效率比FSA算法提高了约215%,比DFSA算法提高了约210%,比RBST算法提高了约30%。特别是当标签数目较大时,DFBT算法的识别效率仍可以保持在0.6以上,而FSA算法和DFSA算法的识别效率却急剧下降。(5)碰撞时隙数分析从DFBT算法流程图中可以看出,在帧时隙处理阶段,待识别标签响应在相应的时隙号i中,当两个及两个以上的标签同时响应在同一时隙上,则该时隙就为碰撞时隙,当所有碰撞时隙中的碰撞标签数目大于2时,在碰撞标签处理阶段分裂碰撞标签又会产生2个碰撞时隙,因此DFBT算法在识别标签过程所产生的碰撞时隙数是帧时隙处理阶段产生的碰撞时隙数与碰撞标签处理阶段分裂碰撞标签产生的碰撞时隙数之和。由于算法的识别效率表示为标签总数与识别这些标签所需的总时隙数之比,而碰撞时隙数量直接决定总时隙数量,所以识别过程中产生的碰撞时隙数间接影响算法的识别效率。对比算法为RBST算法和DFSA算法,仿真结果如图8所示,当标签总数相同时,DFBT算法产生的碰撞时隙数最少,尤其当标签总数增加到1000左右时,DFBT算法产生的碰撞时隙比FSA算法减少了约3623个,比DFSA算法减少了约3370个,比RBST算法减少了约396个。(6)识别时间分析为验证DFBT算法在识别时间上的优势,对比算法为RBST算法和DFSA算法,仿真结果如图9所示,标签总数从0增加到1000,标签识别时间也相应的增加,但是DFBT算法的识别时间较RBST算法和DFSA算法增加的较缓慢。在标签总数相同的情况下,DFBT算法的识别时间比RBST算法和DFSA算法都要短,当标签总数达到1000时,DFBT算法的识别时间是1.3秒左右,而RBST算法和DFSA算法的识别时间分别为5秒和3秒左右,DFBT算法大大的缩短了标签识别时间,表明该算法的识别速度较RBST算法和DFSA算法要快。(7)不同标签ID长度K的识别效率分析为验证DFBT算法识别效率的稳定性,分别对标签ID长度K取16bit、32bit和64bit进行实验对比,当标签总数一定时,识别效率主要受总时隙数的影响,而根据式(17)可知总时隙数与决定标签选择时隙号位数m有关,即与标签ID最高碰撞位后的二进制数的位数有关,与标签ID长度无直接关系。仿真结果如图10所示,在不同标签ID长度下,DFBT算法的识别效率基本保持稳定。从而验证了本发明提出的新算法可以增加系统识别效率的稳定性。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1