基于随机森林算法的网络潜力用户挖掘方法及系统与流程
本发明涉及基于随机森林算法网络数据挖掘领域,具体涉及一种基于随机森林算法的网络潜力用户挖掘方法及系统。
背景技术:
随着在网络直播行业的飞速发展,直播网站的用户呈爆炸式增长。在此基础上,直播网站的运营商需要快速有效的将具有潜力的用户从全站用户中筛选出来,以方便运营人员针对潜力用户做进一步的精细化营销方案,进而提高用户的付费转化率。
目前,传统的潜力用户挖掘方法一般为以下2种:1、通过人工提取,即根据个人经验组合用户的有效行为特征,以此来人工筛选潜力用户;2、通过常用的决策树、knn(k-NearestNeighbor,分类算法)或朴素贝叶斯等算法进行二次分类来挖掘潜力用户。
但是,上述2种方法分别存在以下缺陷:
(1)人工筛选的方法一般会带有较大程度的主观性,在海量数据的场景下,数据往往维度多、数据量大,靠人工是很难将用户兴趣度相关指标统计全面的,进而使得人工筛选出的潜力用户的精准度较低。
(2)二次分类挖掘潜力用户的方法容易过拟合,面对不均衡的样本数据时,二次分类的误差较大,而且对数值缺失敏感,进而降低挖掘到的潜力用户的精准度。
技术实现要素:
针对现有技术中存在的缺陷,本发明解决的技术问题为:在保证精准度的基础上自动挖掘网络潜力。本发明不仅能够使得网络潜力用户的挖掘过程更加智能化,挖掘网络潜力用户的用户特征比较全面,而且计算速度较快,工作效率较高。
为达到以上目的,本发明提供的基于随机森林算法的网络潜力用户挖掘方法,包括以下步骤:
S1:在需要挖掘网络潜力用户的网络平台中,定义抽样用户类别为付费用户和从未付费用户,对每个抽样用户类别抽样选取指定数量的用户作为样本;
S2:确定每个样本的用户特征;
S3:计算每个样本的用户特征的归一化特征值Y,计算公式为:Y=(X-MinX)/(MaxX-MinX);其中X代表当前样本的用户特征参数,MinX代表所有样本中当前用户特征的最小参数,MaxX代表所有样本中当前用户特征的最大参数;
S4:对所有的用户特征进行多次抽样,根据每次抽样的用户特征的归一化特征值形成随机森林算法的决策树;
S5:在所有样本中,为每棵决策树选取指定数量的样本;
S6:基于随机森林算法,根据每棵决策树的样本和用户特征的归一化特征值,将每棵决策树的数据分为2个类别,其中1类代表潜力用户,另1类代表非潜力用户;
S7:根据每棵决策树中的2个类别对待分类用户进行分类,统计所有决策树中相同类别的数量,将相同数量多的类别确定为待分类用户的类别。
本发明提供的实现上述方法的基于随机森林算法的网络潜力用户挖掘系统,包括抽样用户类别定义模块、用户特征选取模块、归一化特征值计算模块、决策树构建模块、决策树样本选取模块、决策树训练模块和网络潜力用户定义模块;
抽样用户类别定义模块用于:在需要挖掘网络潜力用户的网络平台中,定义抽样用户类别为付费用户和从未付费用户,对每个抽样用户类别抽样选取指定数量的用户作为样本;
用户特征选取模块用于:确定每个样本的用户特征;
归一化特征值计算模块用于:计算每个样本的用户特征的归一化特征值Y,计算公式为:Y=(X-MinX)/(MaxX-MinX);其中X代表当前样本的用户特征参数,MinX代表所有样本中当前用户特征的最小参数,MaxX代表所有样本中当前用户特征的最大参数;
决策树构建模块用于:对所有的用户特征进行多次抽样,根据每次抽样的用户特征的归一化特征值形成随机森林算法的决策树;
决策树样本选取模块用于:在所有样本中,为每棵决策树选取指定数量的样本;
决策树训练模块用于:基于随机森林算法,根据每棵决策树的样本和用户特征的归一化特征值,将每棵决策树的数据分为2个类别,其中1类代表潜力用户,另1类代表非潜力用户;
网络潜力用户定义模块用于:根据每棵决策树中的2个类别对待分类用户进行分类,统计所有决策树中相同类别的数量,将相同数量多的类别确定为待分类用户的类别。
与现有技术相比,本发明的优点在于:
(1)本发明采用基于随机森林算法的方法,自动计算和挖掘网络潜力用户,不需要人工主观性判断,基于随机森林的挖掘算法能够很好地找到网络潜力用户,且算法模型更鲁棒,受异常数据影响较小,不会产生过拟合。因此,本发明不仅能够使得网络潜力用户的挖掘过程更加智能化,而且挖掘网络潜力用户的用户特征比较全面,挖掘到的潜力用户的精准度较高。
(2)本发明实际使用时,能够基于Spark的内存计算和挖掘网络潜力用户,其计算速度较快,能够显著缩短计算周期,进而提高工作效率。
附图说明
图1为本发明实施例中基于随机森林算法的网络潜力用户挖掘方法的流程图;
图2为在Spark MLlib上实现基于随机森林算法的网络潜力用户挖掘方法的流程图。
具体实施方式
以下结合附图及实施例对本发明作进一步详细说明。
参见图1所示,本发明实施例中的基于随机森林算法的网络潜力用户挖掘方法,其核心算法是随机森林:随机森林算法是机器学习、计算机视觉等领域内应用极为广泛的一个算法,它不仅可以用来做分类,也可用来做回归即预测,随机森林机由多个决策树构成,相比于单个决策树算法,它分类、预测效果更好,不容易出现过度拟合的情况。
在此基础上,本发明实施例中的基于随机森林算法的网络潜力用户挖掘方法,包括以下步骤:
S1:选择样本数据:在需要挖掘网络潜力用户的网络平台中,定义抽样用户类别为付费用户(正样本)和从未付费用户(负样本),对每个抽样用户类别抽样选取指定数量的用户作为样本,转到S2。
S2:确定每个样本(正样本和负样本)的用户特征,转到S3。
S2中的用户特征之前已经预定义,本实施例中的用户特征为:观看时长、观看次数、发送弹幕数量、赠送礼物数量(例如斗鱼直播平台的鱼丸)、在线领取礼物数量、发送鱼翅金额、关注房间数量、关注分区数量、指定分区观看时长(本实施例中分区为直播平台中最火热的10个分区)、指定分区观看次数、指定分区发弹幕数量、指定分区赠送礼物数量、指定分区在线领取礼物数量、指定分区发送鱼翅金额和指定分区关注房间数量。由于每一个top特征可看成10个细分特征,因此本实施例中总计78个用户特征。
S3:归一化特征值:为了避免因不同用户特征的差异较大,而导致对分类结果造成影响,在此需要计算每个样本的用户特征的归一化特征值Y,Y的计算公式为:Y=(X-MinX)/(MaxX-MinX),其中X代表当前样本的用户特征参数,MinX代表所有样本中当前用户特征的最小参数,MaxX代表所有样本中当前用户特征的最大参数。根据上述计算公式得出的Y的值均集中在(0,1]之间,特征量纲差异较小,转到S4。
S3举例如下:例如计算第3个样本的用户特征(观看时长),第3个样本的观看时长的参数为50,所有样本中最小的观看时长参数为30,最大的观看时长参数为70,则Y=(50-30)/(70-90)。
S4:对所有的用户特征进行多次抽样,根据每次抽样的用户特征的归一化特征值形成随机森林算法的决策树(随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的总数而定):本实施例中对所有的用户特征进行多次抽样的方式为不放回抽样,每次抽样均选取3个用户特征的归一化特征值(实际应用中每次抽样选取的用户特征可不同,但是至少3个以上),78/3=26,即一共有26棵决策树,转到S5。
S5:随机选取样本数据:在所有样本(所有正负样本)中,为每棵决策树抽样选取样本。本实施例中为每棵决策树采用有放回抽样的方式,抽样选取所有样本总量(所有正负样本数量之和)的60%~80%的样本,转到S6。
S6:基于随机森林算法,根据每棵决策树的样本和用户特征的归一化特征值,对每棵决策树进行训练:将每棵决策树的数据分为2个类别,其中1类代表潜力用户,另1类代表非潜力用户,转到S7。
S7:所有决策树训练完毕后,随机森林也就够构造完毕了。根据每棵决策树中的2个类别对待分类用户进行分类,统计所有决策树中相同类别的数量,将相同数量多的类别确定为待分类用户的类别;即少数服从多数投票原则,例如26棵决策树中有16个分类结果为潜力用户,10个分类结果为非潜力用户,16>10,因此当前用户为潜力用户。
S6的具体流程为:
S601:将每棵决策树的所有样本作为训练数据集D,计算数据集D的信息熵info(D),计算公式为:
上述公式中m代表类别数量,本实施例中为2个类别,即m=2,Pi代表第i个类别在数据集D中出现的概率。
S602:将每棵决策树的用户特征的归一化特征值作为属性集A,根据每棵决策树的info(D),计算属性集A中每个属性的信息增益gain(A),计算公式为:
gain(A)=info(D)-infoA(D),
上述公式中Di代表第i个类别在数据集D中的数量。
S603:将gain(A)最大的属性作为最强属性,计算最强属性的信息增益率gainratio(A),计算公式为:
gainratio(A)=gain(A)/IntrinsicInfo(A);
根据最强属性的信息增益率gainratio(A)选择最佳分裂位置,将数据集D分为2类数据,1类代表潜力用户,另1类代表非潜力用户。
S604:判断数据集D的2类数据是否同时符合要求(即每类数据中的所有数据类别相同,或者分类数据量达到一个下限阈值,或者决策树达到指定深度),若是,转到S7,否则将当前最强属性对应的用户特征剔除后,重新执行S601。
本发明实施例中的基于随机森林算法的网络潜力用户挖掘方法,在Spark MLlib上实现,Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用并行框架,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
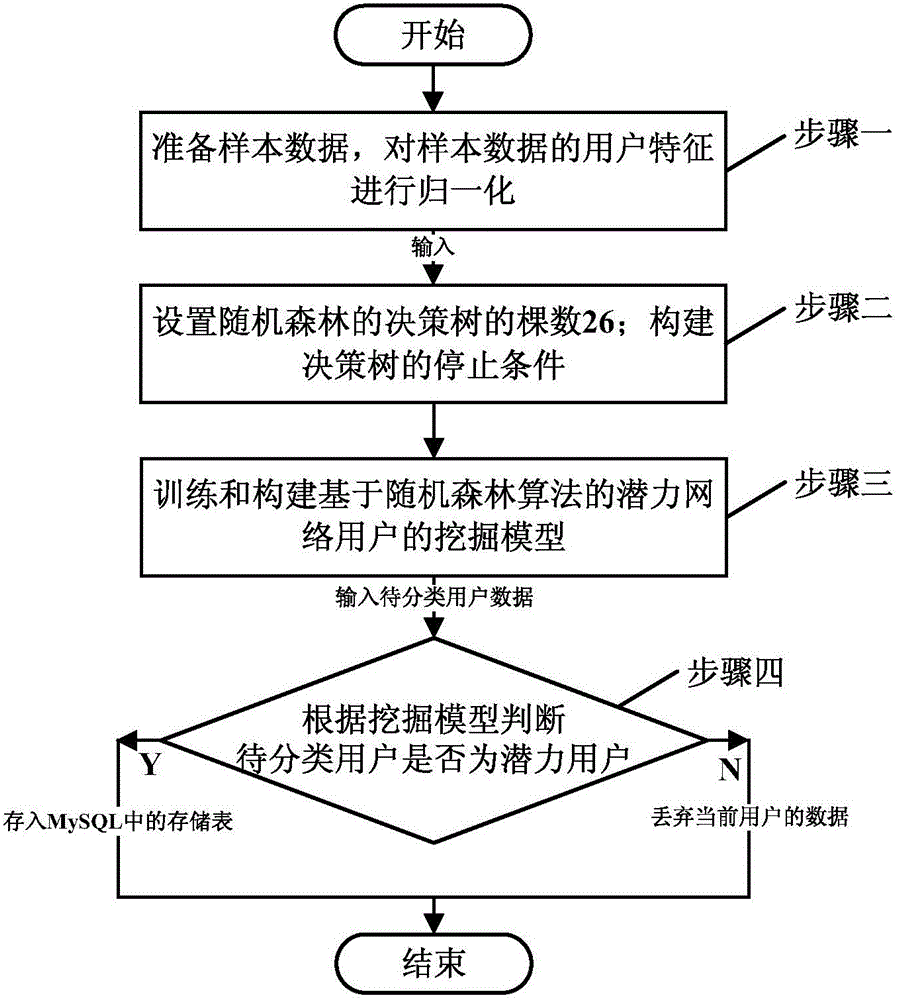
参见图2所示,在Spark MLlib上实现基于随机森林算法的网络潜力用户挖掘方法时,包括以下流程:
步骤一、准备好S1中的样本数据,采用S2和S3的步骤对样本数据的用户特征进行归一化;
步骤二、将样本数据和用户特征的归一化特征值输入至parkMLlib的算法接口;设置随机森林的决策树的棵数26;构建决策树的停止条件,这里指定树的深度来作为决策树停止条件;设置类的个数,这里是两个:潜力用户1、非潜力用户0;
步骤三、调用Spark MLlib中RandomForestModel.trainClassifier方法,训练和构建基于随机森林算法的潜力网络用户的挖掘模型;鉴于Spark MLlib提供的是算法接口,且S4至S6中中详细介绍了决策树的训练方法,此处不再赘述;
步骤四、将待分类用户的数据按样本数据的格式输入训练好的决策数模型,即可得到待分类用户的类别,若待分类用户为潜力用户,则存入MySQL中的存储表,若待分类用户为非潜力用户,则丢弃当前用户的数据。
本发明实施例中的实现上述方法的基于随机森林算法的网络潜力用户挖掘系统,包括抽样用户类别定义模块、用户特征选取模块、归一化特征值计算模块、决策树构建模块、决策树样本选取模块、决策树训练模块和网络潜力用户定义模块。
抽样用户类别定义模块用于:在需要挖掘网络潜力用户的网络平台中,定义抽样用户类别为付费用户和从未付费用户,对每个抽样用户类别抽样选取指定数量的用户作为样本;
用户特征选取模块用于:确定每个样本的用户特征;
归一化特征值计算模块用于:计算每个样本的用户特征的归一化特征值Y,计算公式为:Y=(X-MinX)/(MaxX-MinX);其中X代表当前样本的用户特征参数,MinX代表所有样本中当前用户特征的最小参数,MaxX代表所有样本中当前用户特征的最大参数;
决策树构建模块用于:对所有的用户特征进行多次抽样,根据每次抽样的用户特征的归一化特征值形成随机森林算法的决策树;具体工作流程为:对所有的用户特征进行多次不放回抽样,每次抽样选取至少3个用户特征的归一化特征值形成随机森林算法的决策树。
决策树样本选取模块用于:在所有样本中,为每棵决策树选取指定数量的样本;具体工作流程为:为每棵决策树采用有放回抽样的方式,抽样选取所有样本总量的60%~80%的样本。
决策树训练模块用于:基于随机森林算法,根据每棵决策树的样本和用户特征的归一化特征值,将每棵决策树的数据分为2个类别,其中1类代表潜力用户,另1类代表非潜力用户;具体工作流程为:
将每棵决策树的所有样本作为训练数据集D,计算数据集D的信息熵info(D),计算公式为:
上述公式中m代表类别数量,Pi代表第i个类别在数据集D中出现的概率;
将每棵决策树的用户特征的归一化特征值作为属性集A,根据每棵决策树的info(D),计算属性集A中每个属性的信息增益gain(A),计算公式为:
gain(A)=info(D)-infoA(D),
上述公式中Di代表第i个类别在数据集D中的数量;
将gain(A)最大的属性作为最强属性,计算最强属性的信息增益率gainratio(A),计算公式为:
gainratio(A)=gain(A)/IntrinsicInfo(A);
根据最强属性的信息增益率gainratio(A)选择最佳分裂位置,将数据集D分为2类数据,1类代表潜力用户,另1类代表非潜力用户;
判断数据集D的2类数据是否同时符合要求(每类数据中的所有数据类别相同、或者分类数据量达到下限阈值、或者决策树达到指定深度),若是,工作完成,否则将当前最强属性对应的用户特征剔除后,重新将决策树的剩余所有样本作为训练数据集D、并进行后续工作流程。
网络潜力用户定义模块用于:根据每棵决策树中的2个类别对待分类用户进行分类,统计所有决策树中相同类别的数量,将相同数量多的类别确定为待分类用户的类别。
本发明不局限于上述实施方式,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围之内。本说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
- 还没有人留言评论。精彩留言会获得点赞!