一种反作弊视频的方法及装置与流程
本发明涉及视频搜索引擎技术领域,尤其涉及一种反作弊视频的方法及装置。
背景技术:
如今,视频作为重要的在线流媒体产品,在人们的日常生活娱乐中占据了重要的位置。鼓励用户制作视频,上传视频,并得到露出也是视频网站的基本原则。各个视频网站都会在搜索结果或者推荐系统中展示视频结果。其背后的算法通常是利用了视频标题,描述,播放量,上传用户信息等数据。正常的视频通常具有合理的标题,描述,和播放量,以及与用户的交互行为。正常的用户也会包含正常的视频,并拥有一定量的粉丝。但是互联网视频网站存在大量的作弊视频和作弊用户。
作弊视频和作弊用户会对正常视频和用户产生不公平的影响。在工业界和学术界,人们并没有关于作弊视频和作弊用户的严格定义。常见的作弊视频和作弊用户有如下特点:视频标题有大量词语堆砌,例如“天天向上快乐大本营何炅谢娜视频”,“马云马化腾王健林李彦宏雷军陈安之创业秘籍”。视频内容与视频标题没有太大关联,或者夹带代理的推广信息。例如"天天向上快乐大本营何炅谢娜视频"的视频内容是关于创业的,
作弊视频有较大的播放量。然而,非热门节目和人物的视频不会有高达百万的播放量,作弊用户的粉丝很少,这种情况不符合网站正常的"播转粉"效率。
作弊视频和作弊用户对正常业务的开展是及其不利的。作弊视频和作弊用户由于虚假的播放量和标题,通常能在排序算法中占尽优势,使得自己可以排在视频结果的前面,便于在搜索和推荐中露出,从而使得真正的视频没有曝光机会。
技术实现要素:
本发明的主要目的在于提供一种反作弊视频的方法及装置,以解决现有技术中由于无法规避作弊视频而影响正常视频被展示的问题。
一种反作弊视频的方法,包括:
获取视频的日志数据;
使用预设的作弊视频识别规则对所述视频的日志数据进行筛选,确定出作弊视频;
降低所述作弊视频的搜索排序以及推荐排序。
优选的,所述作弊视频识别规则,包括:
判断视频标题包含的热门关键词的是否满足预设热门关键词个数,判断视频在预设时间段内的播放量是否满足预设播放次数,判断视频在所述预设时间段内获得的用户交互行为是否少于第二预设次数,判断视频的名称是否符合第一预设规律;
使用所述作弊视频识别规则对所述视频的日志数据进行筛选,确定出作弊视频,包括:
将所述视频的日志数据中至少满足所述作弊视频识别规则中一项的视频确定为作弊视频。
优选的,所述方法还包括:
在使用预设的作弊视频识别规则对所述视频的日志数据进行筛选,确定出作弊视频之后,获取用户的日志数据,使用预设的作弊用户识别规则对所述用户的日志数据进行筛选,确定出作弊用户;
降低所述作弊用户上传的视频的搜索排序以及被推荐的排序。
优选的,所述作弊用户识别规则包括:
判断所述用户的日志数据中的用户名称是否满足第二预设规律,判断所述用户的日志数据中视频的播放量是否满足预设播放次数,判断所述用户的日志数据中的用户的视频数目是否少于预设视频数目,判断所述用户的日志数据中的用户的视频的标题中包含的热门关键词的个数是否满足预设热门关键词个数,判断所述用户日志数据中用户的粉丝数是否小于预设粉丝数;
所述获取用户的日志数据,使用预设的作弊用户识别规则对所述用户的日志数据进行筛选,确定出作弊用户,包括:
将所述用户的日志数据中至少满足所述作弊用户识别规则中一项的用户确定为作弊用户。
优选的,所述方法还包括:
接收外部输入的作弊视频的名称和/或作弊用户的身份标识,将所述作弊视频的名称和/或作弊用户的身份标识发送给视频缓存区,以使作弊视频以及作弊用户在所述视频缓存区中被识别,所述作弊视频识别规则以及所述作弊用户识别规则预存在所述视频缓存区中。
一种反作弊视频的装置,包括:
第一获取模块,用于获取视频的日志数据;
第一筛选模块,用于使用预设的作弊视频识别规则对所述视频的日志数据进行筛选,确定出作弊视频;
第一降权模块,用于降低所述作弊视频的搜索排序以及推荐排序。
优选的,所述作弊视频识别规则,包括:
判断视频标题包含的热门关键词的是否满足预设热门关键词个数,判断视频在预设时间段内的播放量是否满足预设播放次数,判断视频在所述预设时间段内获得的用户交互行为是否少于第二预设次数,判断视频的名称是否符合第一预设规律;
所述第一筛选模块具体用于:
将所述视频的日志数据中至少满足所述作弊视频识别规则中一项的视频确定为作弊视频。
优选的,所述装置还包括:
第二筛选模块,用于在使用预设的作弊视频识别规则对所述视频的日志数据进行筛选,确定出作弊视频之后,获取用户的日志数据,使用预设的作弊用户识别规则对所述用户的日志数据进行筛选,确定出作弊用户;
第二降权模块,用于降低所述作弊用户上传的视频的搜索排序以及被推荐的排序。
优选的,所述作弊用户识别规则包括:
判断所述用户的日志数据中的用户名称是否满足第二预设规律,判断所述用户的日志数据中视频的播放量是否满足预设播放次数,判断所述用户的日志数据中的用户的视频数目是否少于预设视频数目,判断所述用户的日志数据中的用户的视频的标题中包含的热门关键词的个数是否满足预设热门关键词个数,判断所述用户日志数据中用户的粉丝数是否小于预设粉丝数;
所述第二筛选模块具体用于:
将所述用户的日志数据中至少满足所述作弊用户识别规则中一项的用户确定为作弊用户。
优选的,所述装置还包括:
接收模块,用于接收外部输入的作弊视频的名称和/或作弊用户的身份标识;
发送模块,用于将所述作弊视频的名称和/或作弊用户的身份标识发送给视频缓存区,以使作弊视频以及作弊用户在所述视频缓存区中被识别,所述作弊视频识别规则以及所述作弊用户识别规则预存在所述视频缓存区中。
本发明有益效果如下:
本发明实例提供的方案对识别出的作弊视频采用降权处理,改善视频搜索和推荐算法中的视频的排序结果,使得作弊用户和作弊视频在排序上处于极大劣势,规避了作弊视频对正常视频展示的影响,使得正常视频可以获得合理的展示机会。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1是本发明实施例1提供的反作弊视频的方法的流程图;
图2是本发明实施例2提供的反作弊视频的装置的结构框图;
图3是本发明实施例3提供的反作弊视频的装置的结构框图。
具体实施方式
为了解决现有技术中由于无法规避作弊视频而影响正常视频被展示的问题,本发明提供了一种反作弊视频的方法及装置,以下结合附图以及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不限定本发明。
实施例1
本实施例提供了一种反作弊视频的方法,图1是该方法的流程图,如图1所示,该方法包括如下处理:
步骤101:获取视频的日志数据;
步骤102:使用预设的作弊视频识别规则对视频的日志数据进行筛选,确定出作弊视频;
在本实施例中作弊视频识别规则具体可以包括对获取到的视频的日志数据中各项视频数据进行如下判断:
判断视频标题包含的热门关键词的是否满足预设热门关键词个数,判断视频在预设时间段内的播放量是否满足预设播放次数,判断视频在预设时间段内获得的用户交互行为是否少于第二预设次数,判断视频的名称是否符合第一预设规律;基于此,使用作弊视频识别规则对视频的日志数据进行筛选,确定出作弊视频的步骤具体可以包括:将视频的日志数据中至少满足作弊视频识别规则中一项的视频确定为作弊视频。
步骤103:降低作弊视频的搜索排序以及推荐排序。
进一步的,本实施例提供的方法还可以包括以下步骤:
在使用预设的作弊视频识别规则对视频的日志数据进行筛选,确定出作弊视频之后,获取用户的日志数据,使用预设的作弊用户识别规则对用户的日志数据进行筛选,确定出作弊用户;降低作弊用户上传的视频的搜索排序以及被推荐的排序。
其中,作弊用户识别规则具体可以包括:判断用户的日志数据中的用户名称是否满足第二预设规律,判断用户的日志数据中视频的播放量是否满足预设播放次数,判断用户的日志数据中的用户的视频数目是否少于预设视频数目,判断用户的日志数据中的用户的视频的标题中包含的热门关键词的个数是否满足预设热门关键词个数,判断用户日志数据中用户的粉丝数是否小于预设粉丝数;获取用户的日志数据,使用预设的作弊用户识别规则对用户的日志数据进行筛选,确定出作弊用户,包括:将用户的日志数据中至少满足作弊用户识别规则中一项的用户确定为作弊用户。
优选的,本实施例提供方法还可以包括:接收外部输入的作弊视频的名称和/或作弊用户的身份标识,将作弊视频的名称和/或作弊用户的身份标识发送给视频缓存区,以使作弊视频以及作弊用户在视频缓存区中被识别。优选的,在本实施例中,作弊视频识别规则以及作弊用户识别规则可以预存在视频缓存区中。
实施例2
本实施例提供了一种反作弊视频系统,本实施例针对SEO(Search Engine Optimization,搜索引擎优化)的技术来设计抑制作弊视频和作弊用户露出的线上架构,本实施例主要提出两种架构,即基本架构和人工干预架构,该两个架构同时生效,抑制作弊视频和作弊用户的露出。其中,基本架构用于实现自动的识别功能和抑制露出;人工干预架构负责手动添加的作弊视频和用户,并及时生效,以备紧急需求。
在本实施例中,针对视频网站反作弊视频的基础数据可以包含两部分:作弊视频和作弊用户。
以下分别对作弊视频以及作弊用户的识别进行说明:
作弊视频通常希望在视频网站的平台上获得更高的露出几率和关注度。例如,在搜索引擎中,作弊视频通常希望排在搜索结果页的首页,甚至是前几位;在视频推荐系统中,作弊视频也希望可以获得更多的推荐;作弊视频也通常希望有更多的用户收藏或转载自己,这样在第三方平台上,作弊视频也有机会让更多的人看到。
本实施例通过对SEO技术和视频的统计分析,发现作弊视频具有如下特点:
作弊视频的标题中通常包含多个热门词语,或者相关领域的热门词语,即热门关键词。例如,热播电视剧和综艺,财经领域的节目名和名人,创业或者直销领域的节目名和名人等,例如,最近网络中常见的有:欢乐喜剧人,太阳的后裔,郎眼财经,马云,陈安之,安利等。
由于作弊视频有专门的SEO工具来异常提高播放量,因此,作弊视频的播放量通常在较短时间内达到非正常的较高数值。通过统计可以发现,一个正常的普通用户在一天内的视频播放量通常不会超过10000,但是作弊视频的播放量可以在几个小时达到几十万甚至上百万。
作弊视频几乎没有顶踩,收藏等用户交互行为。而非作弊视频在如此高的播放量前提下,视频的顶踩,收藏等用户交互行为是可以达到一定水平的。但是作弊视频通常没有这些行为,即,虽然作弊视频的播放量被提高了,但是并没有真正的用户来交互。
作弊视频的用户名称具有一定的规律,由于SEO现在多采用软件自动化的方式进行命名,因此用户在上传视频前,不会手动设置用户名。只会简单的依靠软件按照一定的规律来生成用户名。常见的有:game_XXXXXX,QQYYYYYYYY,其中X代表字母或者数字,Y代表数字。
根据作弊视频的以上特点,对作弊视频进行识别可以通过人工整理,也可以通过机器对作弊视频的上述特点进行学习,从而得出识别作弊视频的规则。
作弊用户是作弊视频的承载平台,根据用户的当前属性,可以判断其是否为作弊用户。对于作弊用户的准确识别,可以更加有效的压制作弊视频,特别是对于即将推出的作弊视频,可以预先进行压制。对于用户的特征抽取,也需要建立在对所含视频的特征考量上。根据对作弊用户的SEO技术和视频的统计分析,发现作弊用户具有如下特点:
作弊用户的名称具有一定的规律,这一点和很多作弊视频的特征相似。由于SEO现在多采用软件自动化的方式,因此用户创建用户,不会手动设置用户名。只会简单的依靠软件按照一定的规律来生成用户名。常见的有:game_XXXXXX,其中X代表字母或者数字。
由于作弊用户有专门的SEO工具来提高视频播放量,故作弊用户的视频播放量通常都很高。基于统计可得,一个普通用户的视频播放量不会超过100000,但是作弊用户的播放量可达上百万甚至上千万。
作弊用户的视频数量都很少,由于SEO技术给用户创建提供了便利,因此为了提高视频露出机会,作弊者通常对于类似的视频内容重复创建用户。这样每一个用户下的视频个数都不多。目前,一般情况下,作弊用户的视频个数都不超过5个。
作弊用户的视频标题中通常含有大量的热词,由于作弊用户中作弊视频的可能性很高,因此作弊用户的视频标题也堆砌了大量的热词。
作弊用户的粉丝数都很低,作弊用户由于视频内容质量的原因,关注的人并不多,即便在如此大的播放量下,粉丝数依然达不到合理的水平。一般,视频网站的非作弊视频用户,每5000次播放可以转化出一个粉丝,而作弊用户则通常达不到这样的粉丝转化率。
在本实施例中,根据作弊用户的以上特点,对作弊用户进行识别可以通过人工整理,也可以通过机器对作弊用户的上述特点进行学习,从而得出识别作弊用户的规则。
本实施例基于上述作弊视频的特点以及作弊用户的特点,提出了用户识别作弊视频以及作弊用户的系统,本实施例提出的系统负责作弊用户和作弊视频的识别,并干预线上效果,进行生效。本系统的基本架构应该在不影响视频搜索系统或者视频推荐系统的前提下进行干预。
需要注意的是,本实施例的系统依赖于后台日志系统的搜索和推荐业务模块,会根据日志的更新周期定时进行识别运算。由于企业系统较为庞大,后台不可避免的存在日志不同步的情况。比如,用户的视频已经在线上生效,该视频也已经记录在视频日志中,但是并没有记录在用户日志中,这将对用户的判断不利。对于这种情况,可以优先进行作弊视频的识别。
另外,作弊视频的上传和作弊行为周期有可能比日志周期要短。比如日志周期是3天,但是作弊周期是1天。这种情况会导致无论识别算法如何判断,都会有新的作弊视频或者用户有机会露出。基于这种情况,可以在业务系统靠近前端(用户)的模块,例如,缓存中加入判断规则(即,上述作弊视频识别规则以及作弊用户识别规则),可以对作弊视频进行及时判断,缓存的特点是快速及时,但是不能承担巨大的任务量。因此该处加入的规则应该逻辑简单,易于处理。
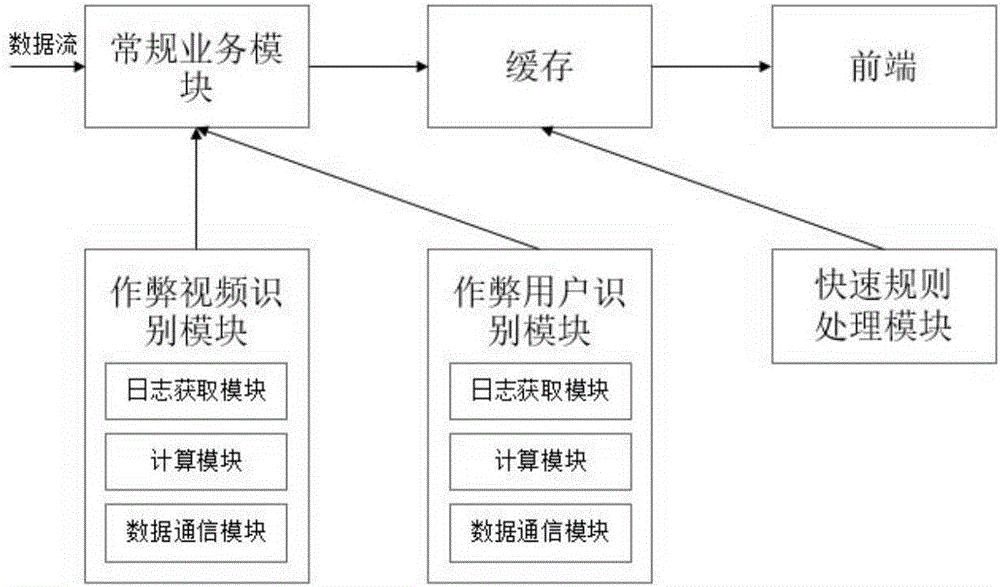
基于上述分析,如图2所示,本实施例提供的系统具体可以包括如下组成部分:作弊视频识别模块:包括日志获取模块,计算模块和数据通信模块。其中,日志获取模块用于获取视频的日志数据;计算模块用于自动识别视频是否为作弊视频,其内部算法为预先训练完成的机器学习算法;数据通信模块用于把作弊视频的id传输给常规业务模块,等待对作弊视频进行降权处理。
作弊用户识别模块:包括日志获取模块,计算模块和数据通信模块。日志获取模块用于获取用户的日志数据;计算模块用于自动识别用户是否为作弊用户,其内部算法为预先训练完成的机器学习算法;数据通信模块用于把作弊用户的id传输给常规业务模块,等待对作弊视频进行降权处理。
快速规则处理模块:通过实现逻辑简单,业务明了的判断逻辑,这些判断逻辑直接在缓存中实现,可以支持对最终搜索或者推荐结果的快速干预。
本实施例提供的系统实现了机器自动的反作弊压制的作用,但是对于紧急情况,仍需要输入作弊视频和作弊用户id,基于此,本实施例还提供了人工干预架构,
人工干预架构需要对作弊视频和用户进行快速及时的识别,可以放在业务系统靠近前端(用户)的模块,比如缓存中。人工干预架构通常需要有专门的模块负责接入用户输入,基于此,本实施例中人工干预模块的架构如下:
人工干预模块:包括输入接收模块和数据通信模块。输入接收模块,通常由一个用户友好的输入界面实现,它允许用户手动输入或接收其他模块发送过来的作弊视频和作弊用户的id,数据通信模块负责把接收到的数据传输给缓存,用于对最终的视频搜索或者视频推荐结果进行快速干预。
在本实施例中,基础系统架构和人工干预架构通常联合生效,才可以对作弊行为进行压制,即:在常规情况下使用基础系统架构,在应急情况下使用人工干预架构。
在本实施例中,对识别出的作弊视频以及作弊用户在搜索引擎在采用降权处理,改善搜索和推荐算法中的排序结果,使得这些用户和视频在排序上处于极大劣势,对于过高播放量和可疑标题的视频进行二次逻辑的处理,保证正常视频的露出,同时,监控可疑用户的视频上传行为,有针对性的对所含视频进行预警和干预,并对该用户进行提醒,帮助其改善视频质量;屏蔽作弊视频和作弊用户的无效播放行为,获取真实播放量,对于分成体系有着重要作用。
实施例3
本实施例提供了一种反作弊视频的装置,该装置可以是上述实施例2中提供的反作弊视频系统的一个组成部分,或该装置可以包括上述实施例2中提供的反作弊视频系统,图3是该装置的结构框图,如图3所示,该装置30包括如下组成部分:
第一获取模块31,用于获取视频的日志数据;
第一筛选模块32,用于使用预设的作弊视频识别规则对视频的日志数据进行筛选,确定出作弊视频;
第一降权模块33,用于降低作弊视频的搜索排序以及推荐排序。
其中,本实施例中的作弊视频识别规则具体可以包括:判断视频标题包含的热门关键词的是否满足预设热门关键词个数,判断视频在预设时间段内的播放量是否满足预设播放次数,判断视频在预设时间段内获得的用户交互行为是否少于第二预设次数,判断视频的名称是否符合第一预设规律;基于此,上述第一筛选模块31具体用于:将视频的日志数据中至少满足作弊视频识别规则中一项的视频确定为作弊视频。
进一步的,上述,装置30还可以包括:
第二筛选模块,用于在使用预设的作弊视频识别规则对视频的日志数据进行筛选,确定出作弊视频之后,获取用户的日志数据,使用预设的作弊用户识别规则对用户的日志数据进行筛选,确定出作弊用户;第二降权模块,用于降低作弊用户上传的视频的搜索排序以及被推荐的排序。
其中,作弊用户识别规则包括:判断用户的日志数据中的用户名称是否满足第二预设规律,判断用户的日志数据中视频的播放量是否满足预设播放次数,判断用户的日志数据中的用户的视频数目是否少于预设视频数目,判断用户的日志数据中的用户的视频的标题中包含的热门关键词的个数是否满足预设热门关键词个数,判断用户日志数据中用户的粉丝数是否小于预设粉丝数;基于此,上述第二筛选模块具体用于:将用户的日志数据中至少满足作弊用户识别规则中一项的用户确定为作弊用户。
可选的,本实施例中的装置30还可以包括:接收模块,用于接收外部输入的作弊视频的名称和/或作弊用户的身份标识;发送模块,用于将作弊视频的名称和/或作弊用户的身份标识发送给视频缓存区,以使作弊视频以及作弊用户在视频缓存区中被识别,作弊视频识别规则以及作弊用户识别规则预存在视频缓存区中。
以上所述仅为本发明的实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!