一种二次判别函数分类器存储空间的压缩方法与流程
本发明涉及数据压缩技术领域,特别涉及一种二次判别函数分类器所存储的参数的压缩方法。
背景技术:
二次判别函数分类器被广泛地运用于数量较大,且类别较多的数据中,并对这些数据进行分类处理。特别是在对手写中文汉字单字图像的分类上有着非常重大的贡献。在所有距离分类器当中,二次判别函数分类器在对手写中文汉字单字图像的分类上分类效果最佳。但是,随着数据类别的增大,二次判别函数分类器需要存储大量的参数,即所占用的存储空间会随之增大。比如,在对手写中文汉字单字图像数据库CASIA-HWDB1.1的样本进行分类时,二次判别函数分类器需要占用大约140MB的存储空间。这样的分类器不适合广泛地应运于目前正在飞速发展和流行的移动设备当中,因为移动设备的存储空间仍然是非常有限的。
近年来,有学者对二次判别函数分类器的存储参数进行研究,提出了不同的压缩方法,比如向量量化技术或参数聚类方法等。虽然这些方法极大的降低了二次判别函数分类器的存储空间大小,但同时二次判别函数的分类效果也受到了比较严重的影响。
为此,许多学者仍然致力于研究在压缩数据的同时,尽可能的减少由于数据压缩而造成的原有精度的损失的方法。其中,稀疏编码在对大类别数据的分析上取得了非常好的效果,并被广泛应运于数据分类,压缩或去噪等方面。
技术实现要素:
本发明的目的是针对现有技术的不足而提供的一种二次判别函数分类器存储空间的压缩方法,该方法降低了二次判别函数分类器的存储空间大小,同时也能够保证二次判别函数分类器仍然保持有较高的分类精度。
本发明的目的是这样实现的:
一种二次判别函数分类器存储空间的压缩方法,该方法包括以下具体步骤:
步骤1:多字典学习
将二次判别函数分类器所存储的特征向量这一参数平均分成若干份,每一份特征向量学习一个字典,不同份的特征向量则学习不同的字典;
步骤2:稀疏编码
结合已学习得到的多个字典对二次判别函数分类器存储的特征向量进行稀疏编码,在存储稀疏编码时,只存储非零编码及指示下标;
其中,步骤1所述将二次判别函数分类器所存储的特征向量这一参数平均分成若干份是:将二次判别函数分类器所存储的特征向量这一参数平均分成K份,K等于二次判别函数分类器对每一类数据所存储的特征向量的数目,在不同类的数据中,相同序列的特征向量为一份,用于学习同一字典,不同序列的特征向量则用于学习不同的字典;
其中,步骤2所述只存储非零编码及指示下标是:除了存储非零编码,用于指示某个编码是否为零的下标也需要进行存储。用下标ι∈{0,1}来指示某个编码是否为非零,如果为非零,那么ι=1,否则ι=0。这里,每一个下标只用1-bit数据类型进行存储。
本发明的有益效果是:采用稀疏编码的方法,使压缩后的二次判别函数分类器具有更高的压缩比,减小了占用的存储空间,同时大大降低了由于数据压缩而造成的原有精度的损失。
附图说明
图1为本发明流程图;
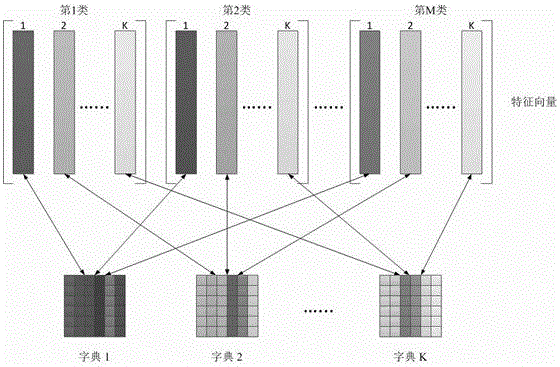
图2为多字典学习方式示意图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步的详细说明。实施本发明的过程、条件、实验方法等,除以下专门提及的内容之外,均为本领域的普遍知识和公知常识,本发明没有特别限制内容。
假设有M类数据,μi用于表示第i类数据的特征(即均值向量),其维度为D,Σi为第i类数据的协方差矩阵。无压缩的二次判别函数分类器需要存储三类参数:均值向量μ,∑的特征值λ及其对应的特征向量Φ。其中,二次判别函数对每一类数据需要存储K个特征值λ及K个特征向量Φ。假设为存储每个二次判别函数参数所用的字节数。那么这三类参数的存储大小分别为:以及从这三类参数的存储大小很明显可以看出,特征向量占据最多的存储空间,因此,针对二次判别函数中的特征向量Φ这一参数进行压缩。
如图1所示,为本发明实施例的流程图,该方法具体包括:
多字典学习,将二次判别函数分类器所存储的特征向量这一参数平均分成K份,K等于二次判别函数分类器对每一类数据所存储的特征向量的数目,在不同类的数据中,相同序列的特征向量为一份,用于学习同一字典,不同序列的特征向量则用于学习不同的字典。
首先需要学习一个超完备基的字典即这个字典包括d个基,且基的个数不能小于输入数据的维度D。这里,设置每个字典中的基的个数等于每一特征向量的维度,即d=D,因为压缩的二次判别函数分类器的存储空间大小会随着d的增加而大幅增加。通过这个字典Θ,使得特征向量Φ可以表示为Φ≈Θa的形式,其中为Φ的稀疏编码。字典学习是一个迭代的过程,每一次迭代主要包括两个步骤:(1)、编码阶段,即固定字典,然后对输入的数据计算它的稀疏编码a;(2)、字典更新阶段,即固定稀疏编码a,然后更新字典。在编码阶段,可以用任何追踪算法来计算稀疏编码a,比如匹配追踪算法,正交匹配追踪算法,基追踪算法等等。更新字典也有多种方法,比如最大似然估计方法,K-SVD方法,联合标准正交基方法等等。这里,采用正交匹配追踪算法进行编码,K-SVD方法进行字典更新,这两种方法计算简单而且精度高,它们的结合在稀疏编码中运用得非常的广泛。
但是,随着输入样本的增加,K-SVD方法对字典更新所需要的时间也会急速增长,且编码的精度也会不断下降。为克服这个困难,同时学习多个字典来提高字典更新的效率及编码的精度。具体的,把特征向量平均分成K份,即份数等同于二次判别函数所存储的每一类的特征向量Φ的个数。然后每一份特征向量用来学习一个字典,不同份的特征向量学习不同的字典。图2表示了多个字典学习方式的示意图。这里,每一类的特征向量是按其对应的特征值的降序排列而排列的。因此,在不同的类别中,相同序列的特征向量为一份,用来学习同一字典。那么不同序列的特征向量就学习不同的字典。
可以看出,一共需要学习K个字典。这里,每个字典的存储大小为则K个字典的存储大小为:
稀疏编码,结合已学习得到的多个字典对二次判别函数分类器存储的特征向量进行稀疏编码,在存储稀疏编码时,只存储非零编码及指示下标。
在学习完多个字典后,结合这多个字典对二次判别函数分类器的特征向量进行稀疏编码。具体来说,每一份特征向量,结合其对应的已学习得到的字典,采用正交匹配追踪算法对特征向量进行稀疏编码。在正交匹配追踪算法中,可以手动设置非零编码的个数,用T0表示,其中,T0<D。因此,只需要存储这些非零编码,以替代原来的特征向量,进而达到减小存储空间的目的。存储所有非零编码需要的存储空间大小为其中,表示稀疏编码中非零编码的百分比。
另外,在存储这些非零编码的同时,还需要存储与这些非零编码所对应的字典的基的位置,即需要存储用于指示某个编码是否为零的下标。因为在分类阶段,需要对特征向量进行重构,而特征向量的重构等于非零编码与所对应的字典的基的线性组合,即Φ≈Θa。这里,用一个下标ι∈{0,1}来表示某个字典的基所对应的编码是否为非零,如果为非零,那么ι=1,否则ι=0。每一个下标我们只需要用1-bit数据类型进行存储(1-bit=1/8-Byte),因此存储这些下标所用的存储空间非常小。存储所有下标的这一部分称为编码本,此编码本的存储大小为M×D×K/8/220(MB)。
综上所述,压缩的二次判别函数分类器需要存储的稀疏编码参数总大小为:
本发明的目的在于对二次判别函数分类器的存储空间进行压缩,因此,所存储的稀疏编码参数的存储空间应该小于用其替换的特征向量的参数,即满足以下式子:
此式子可以简化为如下形式:
即,当满足如上约束条件时,可以减小二次判别函数分类器的存储空间。
- 还没有人留言评论。精彩留言会获得点赞!