一种语音数据处理方法、装置、用具和系统与流程
本发明属于语音数据处理技术领域,具体涉及一种语音数据处理方法、装置、用具和系统。
背景技术:
现今,由于公共场所内的人流量较大,很多顾客为了使同行的人清楚的听到自己所说的内容,只能将说话的音量增大,但这无疑会导致公共场所中的噪音增加,这种情况给其他顾客带来的体验和心理感受非常不好,甚至还会导致该公共场所因此而失掉大量顾客,同时,还存在因顾客之间的吵闹而对周边居民的正常生活造成困扰的问题。
技术实现要素:
本发明旨在至少解决现有技术中存在的技术问题之一,提出了一种能够减小公共场所内的噪音分贝的语音数据处理方法、装置、用具和系统。
解决本发明技术问题所采用的技术方案是一种语音数据处理方法,包括:
对餐厅的全部用户进行音量采集,生成全部用户的采集数据;
从全部用户的采集数据中提取出使用用具的使用者的音量;
根据使用者的音量生成语音数据;
将所述语音数据发送至服务器,以供所述服务器根据所述语音数据生成打折比例并根据所述打折比例对所述使用者进行结算。
其中,在所述对餐厅的全部用户进行音量采集,生成全部用户的采集数据之前,还包括:
向点餐装置提供第一标识,形成所述用具与餐桌之间的第二关联关系,所述第二关联关系包括所述用具和所述餐桌之间的对应关系;
所述服务器根据所述语音数据生成打折比例并根据所述打折比例对所述使用者进行结算包括:
所述服务器根据所述第二关联关系查询出与餐桌对应的全部用具,统计出所述全部用具对应的使用者的语音数据;
所述服务器根据所述餐桌上的全部用具对应的使用者的语音数据生成打折比例;
所述服务器根据所述打折比例对所述使用者进行结算。
其中,在对餐厅的全部用户进行音量采集,生成全部用户的采集数据之前,还包括:
每隔预设时间对餐厅内的全部用户进行声纹采集,生成每个用户的声纹数据;
根据所述声纹数据形成所述用具与所述使用者之间的第一关联关系,所述第一关联关系包括第二标识和使用者标识之间的对应关系,第二标识用于标识所述用具,使用者标识用于标识所述使用者;
根据所述第一关联关系确定出与用具对应的使用者。
其中,所述声纹数据包括:时间值和归属声纹特征;
所述根据所述声纹数据形成第二标识与使用者标识之间的第一关联关系包括:
将每个所述声纹数据中时间值进行比较,筛选出包含最小时间值的声纹数据;
确认出所述包含最小时间值的声纹数据对应的用户为使用者;
将所述第二标识和所述使用者对应的声纹数据中的归属声纹特征进行绑定,以形成第一关联关系。
其中,所述语音数据为所述使用者的最大音量值或音量平均值。
其中,在所述每隔预设时间对餐厅内的全部用户进行声纹采集,生成每个用户的声纹数据之前,还包括:
检测环境温度,以根据所述环境温度设置预设时间。
其中,所述预设时间小于等于0.1毫秒。
作为另一技术方案,本发明还提供一种语音数据处理装置,包括:
第一采集模块,用于对餐厅的全部用户进行音量采集,生成全部用户的采集数据;
提取模块,用于从全部用户的采集数据中提取出使用用具的使用者的音量;
生成模块,用于根据使用者的音量生成语音数据;
发送模块,用于将所述语音数据发送至服务器,以供所述服务器根据所述语音数据生成打折比例并根据所述打折比例对所述使用者进行结算。
其中,所述语音数据处理装置还包括:
第一关联模块,用于向点餐装置提供第一标识,形成所述用具与餐桌之间的第二关联关系,以供所述服务器根据所述第二关联关系查询出与餐桌对应的全部用具,统计出所述全部用具对应的使用者的语音数据,并根据所述餐桌上的全部用具对应的使用者的语音数据生成打折比例,根据所述打折比例对所述使用者进行结算;所述第二关联关系包括所述用具和所述餐桌之间的对应关系。
其中,所述语音数据处理装置还包括:
第二采集模块,用于每隔预设时间对餐厅内的全部用户进行声纹采集,生成每个用户的声纹数据;
第二关联模块,用于根据所述声纹数据形成所述用具与所述使用者之间的第一关联关系,所述第一关联关系包括第二标识和使用者标识之间的对应关系,第二标识用于标识所述用具,使用者标识用于标识所述使用者;
确定模块,用于根据所述第一关联关系确定出与用具对应的使用者。
其中,所述声纹数据包括:时间值和归属声纹特征;
第二关联模块包括:
筛选模块,用于将每个所述声纹数据中时间值进行比较,筛选出包含最小时间值的声纹数据;
确认模块,用于确认出所述包含最小时间值的声纹数据对应的用户为使用者;
绑定模块,用于将所述第二标识和所述使用者对应的声纹数据中的归属声纹特征进行绑定,以形成第一关联关系。
其中,所述语音数据为所述使用者的最大音量值或音量平均值。
其中,所述语音数据处理装置还包括:
检测模块,用于检测环境温度,以根据所述环境温度设置预设时间。
其中,所述预设时间小于等于0.1毫秒。
作为另一技术方案,本发明还提供一种用具,包括用具本体和上述任意一项所述的语音数据处理装置,所述语音数据处理装置位于所述用具本体上。
其中,所述用具为筷子。
作为另一技术方案,本发明还提供一种语音数据处理系统,包括:服务器和上述的用具;
所述服务器,用于接收所述用具发送的语音数据,根据所述语音数据生成打折比例并根据所述打折比例对使用者进行结算。
本发明的语音数据处理方法、装置、用具和系统中,该处理方法包括:对餐厅的全部用户进行音量采集,生成全部用户的采集数据,从全部用户的采集数据中提取出使用用具的使用者的音量,根据使用者的音量生成语音数据;将语音数据发送至服务器,以供服务器根据语音数据生成打折比例并根据打折比例对使用者进行结算,通过这一方法,可以根据用户的语音数据,让餐厅的经营者能够根据服务器对顾客的交谈声音做出客观的评价,从而辅助以餐费打折等手段,促使顾客主动降低交谈时的音量,以达到降低整体环境噪音和改善用餐环境的目的。
本发明的语音数据处理方法、装置、用具和系统适用于降低餐厅等人流量较大的公共场所的噪声。
附图说明
图1为本发明的实施例1的语音数据处理方法的流程示意图;
图2为本发明的实施例1的语音数据处理方法的具体实施方案的示意图;
图3为本发明的实施例2的语音数据处理装置的结构示意图;
图4为本发明的实施例3的用具的结构示意图;
图5为本发明的实施例4的语音数据处理系统的结构示意图;
其中,附图标记为:1、第一采集模块;2、提取模块;3、生成模块;4、发送模块;5、第一关联模块;6、第二采集模块;7、第二关联模块;71、筛选模块;72、确认模块;73、绑定模块;8、确定模块;9、检测模块;100、语音数据处理装置;101、用具本体;200、用具;300、服务器。
具体实施方式
为使本领域技术人员更好地理解本发明的技术方案,下面结合附图和具体实施方式对本发明作进一步详细描述。
实施例1:
请参照图1,本实施例提供一种语音数据处理方法,包括:
步骤100,用具向点餐装置提供第一标识,形成用具与餐桌之间的第二关联关系,第二关联关系包括用具和餐桌之间的对应关系。
需要说明的是,第一标识为用具的身份标识,也就是说,每个用具都有与其匹配的唯一的第一标识,第一标识可以是RFID芯片、二维码或其他类型的标识,点餐装置只要设置有与第一标识类型匹配且可以读取第一标识的读取模块(如摄像头等)即可,当点餐装置读取了用具的第一标识后,餐厅服务员可在点餐装置上手动填入餐桌号码,从而可以在该用具所在的餐桌与该用具之间建立第二关联关系。
当然,一个用具只能对应于一个与其建立第二关联关系的餐桌,但一个餐桌可以同时与多个餐具建立第二关联关系。
步骤101,用具每隔预设时间对餐厅内的全部用户进行声纹采集,生成每个用户的声纹数据。
也就是说,每隔预设时间,每个用具就会对餐厅内的全部用户同时进行声纹采集,而后生成每个用户的声纹数据。
步骤102,用具根据声纹数据形成用具与使用者之间的第一关联关系,第一关联关系包括第二标识和使用者标识之间的对应关系,第二标识用于标识用具,使用者标识用于标识使用者。其中,声纹数据包括:时间值和归属声纹特征,具体地,使用者标识为归属声纹特征。
步骤102具体包括:
步骤1021,用具将每个声纹数据中时间值进行比较,筛选出包含最小时间值的声纹数据。
需要说明的是,时间值是指接收到某一声音时距离预设时间初始时的时间差。例如,某一用户发出声音,餐厅内所有用具都采集到了该声音,但由于每个用具与该用户之间的距离不同,因此,每个用具采集到该声音的时间点不同,有的用具可能经过0.02毫秒采集到,有的用具可能经过0.03毫秒采集到,因此,在所有声纹数据中必然存在一个包括最小时间值的声纹数据,在所有用具中也必然存在一个采集到该声音的时间点最短的用具。
步骤1022,用具确认出包含最小时间值的声纹数据对应的用户为使用者。
具体地,对于一个用具来说,其从多个声纹数据中筛选出的包含最小时间值的声纹数据必然是离该用具最近的一个用户的声纹数据,因此,用具确认该出包含最小时间值的声纹数据对应的用户为其使用者。
步骤1023,用具将第二标识和使用者对应的声纹数据中的归属声纹特征进行绑定,以形成第一关联关系。
第二标识设置在用具上或用具中,第二标识作为用具的身份特征,且每个用具都具有唯一的第二标识。当用具确认出其使用者时,会将其第二标识与该使用者的声纹数据中的归属声纹特征进行绑定,以形成第一关联关系。
步骤103,用具根据第一关联关系确定出与用具对应的使用者。
也就是说,通过将第二标识与归属声纹特征绑定的方式将该包括该第二标识的用具与包括该归属声纹特征的声纹数据所对应的使用者进行绑定。
步骤104,用具对餐厅的全部用户进行音量采集,生成全部用户的采集数据。
由于餐厅是一个开放式的环境,因此,各种声音汇集,为了减少用具的采集量,可以预先在用具中存储服务员等餐厅工作人员的声纹特征,当用具采集到工作人员的采集数据后可直接忽略。需要说明的是,采集数据并不是某一用的使用者一个人的,而是餐厅内所有用户的。
步骤105,用具从全部用户的采集数据中提取出使用用具的使用者的音量。
具体地,用具根据其使用者的归属声纹特征,在采集数据中进行查询,从而在全部用户的采集数据中提取出该用具使用者的音量。
步骤106,用具根据使用者的音量生成语音数据。
其中,语音数据为使用者的最大音量值或音量平均值。
需要说明的是,用具只要在采集数据中提取到其使用者的音量,就会对该音量进行存储并按照语音数据的类型生成语音数据。例如,若语音数据为音量平均值,则用具会对其使用者的全部音量进行存储,并在使用者结束用餐时,按照平均值公式计算出其音量平均值;若语音数据为最大音量值,则用具会对其使用者的全部音量进行存储,并在使用者结束用餐时,从所有音量中筛选出最大音量值。当然,语音数据的类型并不局限于此,还可以是使用者的最小音量值或音量累计值等,只要是能够用于统计使用者的音量信息的数据即可,在此不再赘述。
步骤107,用具将语音数据发送至服务器,以供服务器根据语音数据生成打折比例并根据打折比例对使用者进行结算。
步骤107具体包括:
步骤1071,用具将语音数据发送至服务器。
具体地,用具将生成的使用者的语音数据发送至服务器。
步骤1072,服务器根据第二关联关系查询出与餐桌对应的全部用具,统计出全部用具对应的使用者的语音数据。
具体地,服务器接收到用具发送的语音数据后,根据第二关联关系查询出与该用具对应的餐桌,并查询该餐桌是否还对应有其他用具,当查询出该餐桌对应的全部用具后,对全部用具对应的使用者的语音数据进行统计。
步骤1073,服务器根据餐桌上的全部用具对应的使用者的语音数据生成打折比例。
可以理解的是,服务器是按照预先设定的打折公式生成打折比例的。
步骤1074,服务器根据打折比例对使用者进行结算。
优选地,在步骤101之前还可以包括步骤100a。
步骤100a,检测环境温度,以根据环境温度设置预设时间。
之所以通过检测环境对预设时间进行设置,是由于当环境温度不同时,声音在环境中的传播速度会发生改变,虽然变化幅度不大,但也会影响声音传播的每米时间差,从而影响预设时间的大小,根据环境温度设置预设时间,能够增加用具确定其使用者的精准度。
需要说明的是,步骤100a可以在步骤101之前执行,也可以在步骤100之前执行,对本实施例的语音数据处理方法并无影响,可根据实际情况进行设置,在此不再赘述。
优选地,预设时间小于等于0.1毫秒。
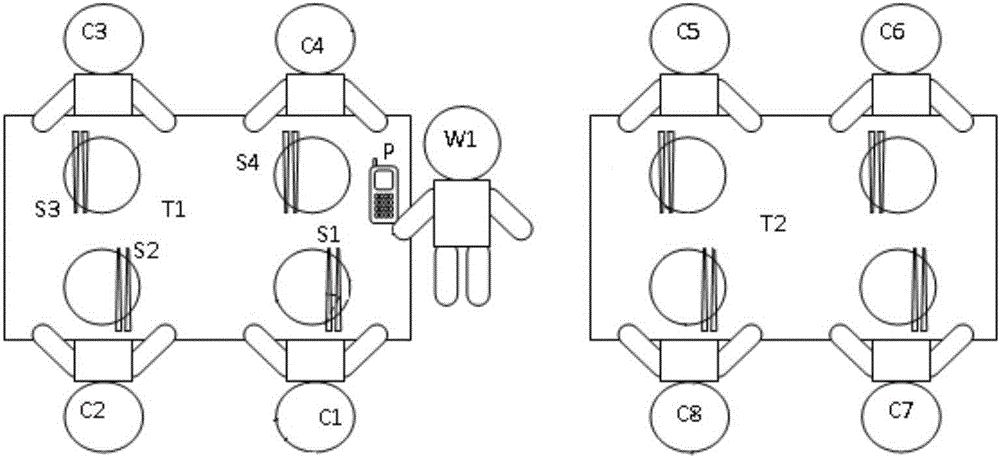
请参照图2,下面以用具为筷子提供一具体例子对本实施例的语音数据处理方法进行说明,其中,C1~C8为餐厅内用餐的用户,W1为服务员,P为点餐装置,T1和T2分别为餐桌,S1~S8为筷子,以筷子S1进行详细说明。本实施例的具体方案为:
S1,当用户C1~C4落座后,服务员W1用点餐装置P识别餐桌T1上筷子S1~S4的第一标识,从而将筷子S1~S4与餐桌T1绑定,形成第二关联关系;S2,筷子S1每隔0.1毫秒对餐厅内的全部用户进行声纹采集,生成每个用户的声纹数据;S3,筷子S1将每个声纹数据中时间值进行比较,筛选出包含最小时间值的声纹数据,从图2中可以看出,由于用户C1~C8距离筷子S1的距离不同,因此,声音在传播时,用户C6的声纹数据中的时间值必然是最大的,用户C1的声纹数据中的时间值必然是最小的,因此,筷子S1将其第二标识与用户C1的归属声纹特征进行绑定,形成第一关联关系,从而将筷子S1与用户C1进行绑定,进而确认出用户C1为筷子S1的使用者;S4,筷子S1对对餐厅的全部用户进行音量采集,生成全部用户的采集数据,并根据C1的归属声纹特征从采集数据中提取出用户C1的音量;S5,筷子S1根据用户C1的音量生成语音数据,并将用户C1的语音数据发送至服务器;S6,服务器根据第二关联关系查询出与筷子S1对应的餐桌T1,并查询餐桌T1还对应的其他筷子S2~S4,对与餐桌T1对应的全部筷子S1~S4对应的使用者的语音数据进行统计;S7,服务器根据统计后的餐桌T1的全部语音数据按照预先设定的打折公式生成打折比例,对使用者进行结算,例如打7折等。
需要说明的是,当使用者发出敲击盘子或其他声音时,也会根据时间值归属到对应的使用者的音量值中。服务器实际上是餐厅的收银服务器,当收银服务器生成打折比例后,其能够直接显示打折后的优化价格,以供餐厅管理者对用户进行收费。因此,通过上述方法,餐厅管理者在用户用餐前预先告知用户可以通过降低说话音量的方式获取打折优惠,从而使用户在用餐时主动降低说话音量,进而降低餐厅内的整体噪声,为所有用户提供更加舒适的就餐环境。
本实施例的语音数据处理方法,包括:对餐厅的全部用户进行音量采集,生成全部用户的采集数据,从全部用户的采集数据中提取出使用用具的使用者的音量,根据使用者的音量生成语音数据;将语音数据发送至服务器,以供服务器根据语音数据生成打折比例并根据打折比例对使用者进行结算,通过这一方法,可以根据用户的语音数据,让餐厅的经营者能够根据服务器对顾客的交谈声音做出客观的评价,从而辅助以餐费打折等手段,促使顾客主动降低交谈时的音量,以达到降低整体环境噪音和改善用餐环境的目的。
实施例2:
请参照图3,本实施例提供一种语音数据处理装置,包括:第一采集模块1、提取模块2、生成模块3、发送模块4、第一关联模块5、第二采集模块6、第二关联模块7、确定模块8和检测模块9。
第一采集模块1用于对餐厅的全部用户进行音量采集,生成全部用户的采集数据。
由于餐厅是一个开放式的环境,因此,各种声音汇集,为了减少用具的采集量,可以预先在用具中存储服务员等餐厅工作人员的声纹特征,当用具采集到工作人员的采集数据后可直接忽略。需要说明的是,采集数据并不是某一用的使用者一个人的,而是餐厅内所有用户的。
提取模块2用于从全部用户的采集数据中提取出使用用具的使用者的音量。
具体地,用具的提取模块2根据其使用者的归属声纹特征,在采集数据中进行查询,从而在全部用户的采集数据中提取出该用具使用者的音量。
生成模块3用于根据使用者的音量生成语音数据。
其中,语音数据为使用者的最大音量值或音量平均值。
需要说明的是,用具的提取模块2只要在采集数据中提取到其使用者的音量,用具就会对该音量进行存储并按照语音数据的类型生成语音数据。例如,若语音数据为音量平均值,则用具会对其使用者的全部音量进行存储,并在使用者结束用餐时,按照平均值公式计算出其音量平均值;若语音数据为最大音量值,则用具会对其使用者的全部音量进行存储,并在使用者结束用餐时,从所有音量中筛选出最大音量值。当然,语音数据的类型并不局限于此,还可以是使用者的最小音量值或音量累计值等,只要是能够用于统计使用者的音量信息的数据即可,在此不再赘述。
发送模块4用于将语音数据发送至服务器,以供服务器根据语音数据生成打折比例并根据打折比例对使用者进行结算。
具体地,用具的发送模块4将生成的使用者的语音数据发送至服务器;然后,服务器接收到用具的发送模块4发送的语音数据后,根据第二关联关系查询出与该用具对应的餐桌,并查询该餐桌是否还对应有其他用具,当查询出该餐桌对应的全部用具后,对全部用具对应的使用者的语音数据进行统计;而后,服务器按照预先设定的打折公式生成打折比例;最后,服务器根据打折比例对使用者进行结算。
第一关联模块5用于向点餐装置提供第一标识,形成用具与餐桌之间的第二关联关系,以供服务器根据第二关联关系查询出与餐桌对应的全部用具,统计出全部用具对应的使用者的语音数据,并根据餐桌上的全部用具对应的使用者的语音数据生成打折比例,根据打折比例对使用者进行结算;第二关联关系包括用具和餐桌之间的对应关系。
需要说明的是,第一标识为用具的身份标识,也就是说,每个用具都有与其匹配的唯一的第一标识,第一标识可以是RFID芯片、二维码或其他类型的标识,点餐装置只要设置有与第一标识类型匹配且可以读取第一标识的读取模块(如摄像头等)即可,当点餐装置读取了用具的第一标识后,餐厅服务员可在点餐装置上手动填入餐桌号码,从而可以在该用具所在的餐桌与该用具之间建立第二关联关系。
当然,一个用具只能有一个与其建立第二关联关系的餐桌,但一个餐桌可以同时与多个餐具建立第二关联关系。
第二采集模块6用于每隔预设时间对餐厅内的全部用户进行声纹采集,生成每个用户的声纹数据。
也就是说,每隔预设时间,每个用具的第二采集模块6就会对餐厅内的全部用户同时进行声纹采集,而后生成每个用户的声纹数据。
第二关联模块7用于根据声纹数据形成用具与使用者之间的第一关联关系,第一关联关系包括第二标识和使用者标识之间的对应关系,第二标识用于标识用具,使用者标识用于标识使用者。
其中,声纹数据包括:时间值和归属声纹特征,具体地,使用者标识为归属声纹特征。
第二关联模块7包括:筛选模块71、确认模块72和绑定模块73。
筛选模块71用于将每个声纹数据中时间值进行比较,筛选出包含最小时间值的声纹数据。
需要说明的是,时间值是指接收到某一声音时距离预设时间初始时的时间差。例如,某一用户发出声音,餐厅内所有用具都采集到了该声音,但由于每个用具与该用户之间的距离不同,因此,每个用具采集到该声音的时间点不同,有的用具可能经过0.02毫秒采集到,有的用具可能经过0.03毫秒采集到,因此,在所有声纹数据中必然存在一个包括最小时间值的声纹数据,在所有用具中也必然存在一个采集到该声音的时间点最短的用具。
确认模块72用于确认出包含最小时间值的声纹数据对应的用户为使用者。
具体地,对于一个用具来说,其从多个声纹数据中筛选出的包含最小时间值的声纹数据必然是离该用具最近的一个用户的声纹数据,因此,用具的确认模块72能够确认该出包含最小时间值的声纹数据对应的用户为其使用者。
绑定模块73用于将第二标识和使用者对应的声纹数据中的归属声纹特征进行绑定,以形成第一关联关系。
第二标识设置在用具中或用具上,第二标识作为用具的身份特征,且每个用具都具有唯一的第二标识。当用具的确认模块72确认出其使用者时,会将其第二标识与该使用者的声纹数据中的归属声纹特征进行绑定,以形成第一关联关系。
确定模块8用于根据第一关联关系确定出与用具对应的使用者。
也就是说,确定模块8通过将第二标识与归属声纹特征绑定的方式将该包括该第二标识的用具与包括该归属声纹特征的声纹数据所对应的使用者进行绑定。
检测模块9用于检测环境温度,以根据环境温度设置预设时间。
之所以设置检测模块9通过检测环境对预设时间进行设置,是由于当环境温度不同时,声音在环境中的传播速度会发生改变,虽然变化幅度不大,但也会影响声音传播的每米时间差,从而影响预设时间的大小,根据环境温度设置预设时间,能够增加用具确定其使用者的精准度。
优选地,预设时间小于等于0.1毫秒。
本实施例的语音数据处理装置用于实现实施例1的语音数据处理方法,详细描述可参照实施例1的语音数据处理方法,在此不再赘述。
本实施例的语音数据处理装置,用于实现实施例1的语音数据处理方法,其可以根据用户的语音数据,让餐厅的经营者能够根据服务器对顾客的交谈声音做出客观的评价,从而辅助以餐费打折等手段,促使顾客主动降低交谈时的音量,以达到降低整体环境噪音和改善用餐环境的目的。
实施例3:
请参照图4,本实施例提供一种用具,包括用具本体101和实施例2的语音数据处理装置100,语音数据处理装置100位于用具本体101上。
可以理解的是,语音数据处理装置100与用具本体101的位置关系并不局限于此,语音数据处理装置100可以设置在用具本体101内部,也可以设置在用具本体101的外部,还可以通过其他方式连接在一起,在此不再赘述。
优选地,用具为筷子。
当然,该用具并不局限于筷子,还可以为用户用餐时使用的其他餐具,在此不再赘述。
本实施例的用具包括实施例2的语音数据处理装置,详细描述可参照实施例2的语音数据处理装置,在此不再赘述。
本实施例的用具,包括实施例2的语音数据处理装置,其可以根据用户的语音数据,让餐厅的经营者能够根据服务器对顾客的交谈声音做出客观的评价,从而辅助以餐费打折等手段,促使顾客主动降低交谈时的音量,以达到降低整体环境噪音和改善用餐环境的目的。
实施例4:
请参照图5,本实施例提供一种语音数据处理系统,包括:用具200和服务器300。
服务器300用于接收用具200发送的语音数据,根据语音数据生成打折比例并根据打折比例对使用者进行结算。
本实施例的语音数据处理系统包括实施例3的用具,详细描述可参照实施例3的用具,在此不再赘述。
本实施例的语音数据处理系统,包括实施例3的用具,其可以根据用户的语音数据,让餐厅的经营者能够根据服务器对顾客的交谈声音做出客观的评价,从而辅助以餐费打折等手段,促使顾客主动降低交谈时的音量,以达到降低整体环境噪音和改善用餐环境的目的。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!