一种基于层次深度语义的隐式篇章关系分析方法与流程
本发明涉及一种隐式篇章关系分析方法,特别涉及一种基于层次深度语义的隐式篇章关系分析方法,属于自然语言处理应用
技术领域:
。
背景技术:
:作为自然语言处理应用
技术领域:
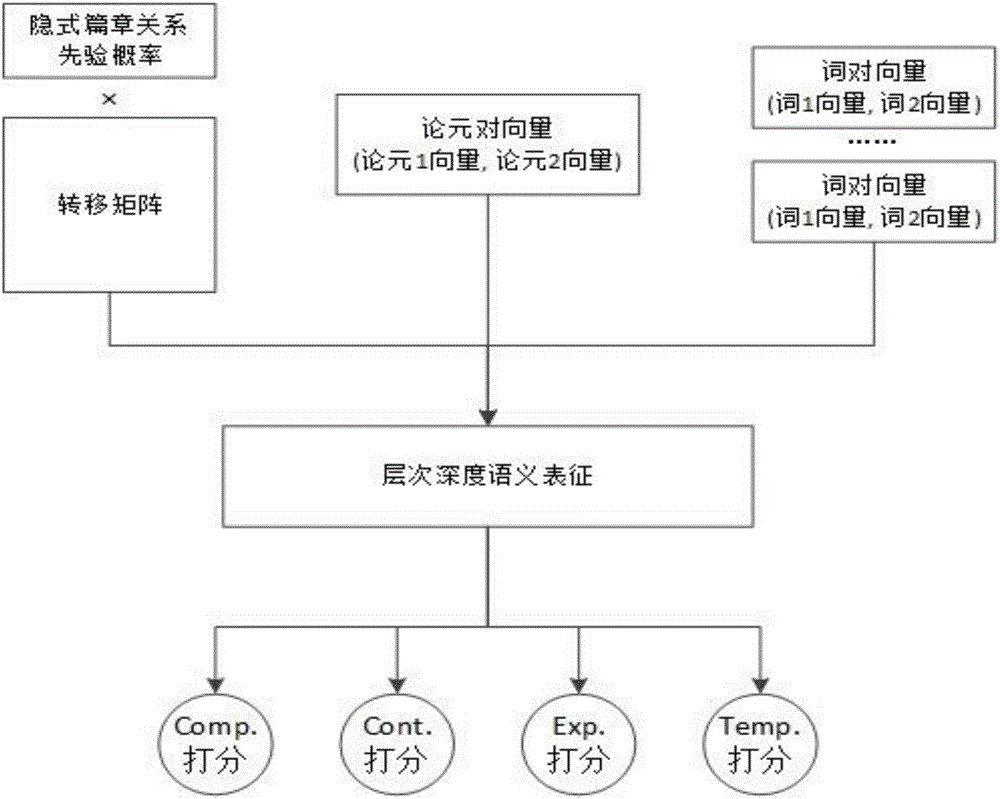
中的一项重要任务,篇章关系分析一直为学者们所不懈研究着,并广泛于统计机器翻译、信息抽取、情感分析等领域发挥重要作用。篇章关系建立在词法和句法分析之上,旨在篇章级别对没有篇章连接词连接的句际关系进行识别与归类,其中又尤以缺乏篇章连接词连接的隐式篇章关系分析为其重点与难点。随着自然语言的语义分析逐渐成为学术和应用的主流,针对一篇文章,如何高效正确地理解其结构与内容,引起了越来越多研究人员的重视。这种趋势从隐式篇章关系分析两次被国际会议CoNLL(ConferenceonComputationalNaturalLanguageLearning)选作共享任务中便可看出。如今又恰逢大数据时代,海量且无结构的信息层出不穷,将这些数据应用在隐式篇章关系分析上,能对现有的结果有较大的提升。因此,我们需要一种基于层次深度语义的方法,帮助我们结合已标注语料和未标注语料,训练出一个高效的隐式篇章关系分析模型,这是一项既有学术意义又有实用价值的研究课题。由于篇章连接词的缺失,整个隐式篇章关系的识别与分类过程,便从单个篇章连接词的语义分析转变为篇章论元结构的语义分析。目前,关于隐式篇章关系分析方面的研究并不充分,仍处于探索阶段,而没有篇章连接词这一特征的帮助,也使得隐式篇章关系分析的研究更加难以深入。主流的隐式篇章关系分析方法一方面着眼于使用离散的词对特征表示可能的关系类型,如Pitler等人在2009年ACL会议上发表的“Automaticsensepredictionforimplicitdiscourserelationsintext”一文中所采用的综合多种离散的语言学特征训练隐式篇章关系分类器的方法,其算法简单易行,但常受累于数据稀疏;另一方面,使用诸如词向量等浅层语义表征隐式篇章关系论元对,从而使用连续且维度较少的特征代替原有的离散特征,如Ji和Eisenstein在2016年NAACL会议上发表的“ALatentVariableRecurrentNeuralNetworkforDiscourseRelationLanguageModels”一文中所提出的,利用RNN向量化表征隐式篇章关系句际信息及上下文信息,其所包含的特征信息更为丰富,却也因现有的隐式篇章关系标注语料缺乏而无法拟合正确结果。上述已有的基于离散特征或深度学习的方法虽然一定程度上解决了隐式篇章关系分析这一问题,然而或因数据稀疏而表现欠佳,或受限于现有的标注数据规模,其性能的改进还存在很大空间。本发明的目的是致力于解决上述主流方法所存在的缺陷,结合两方面方法的优势,提出一种基于层次深度语义的隐式篇章关系分析方法。技术实现要素:本发明的目的是针对现有的隐式篇章关系分析方法由于数据规模和模型本身为主的原因所产生的过拟合和数据稀疏技术问题,即解决现有方法不能有效利用隐式篇章关系论元对所包含的深度语义信息的问题,提出一种基于层次深度语义的隐式篇章关系分析方法。为实现上述目的,本发明所采用的技术方案如下:本发明技术方案的思想是,首先结合已标注语料和未标注语料,扩充训练语料的规模,以避免训练语料规模过小所带来的欠学习问题;然后基于一定规则初始化训练语料的词向量及句向量,并通过信息增益值的大小筛选出有助于分类的词对,将其作为后续步骤的特征选取依据;最后设计一种打分函数,将待分类篇章关系论元对的有用词对向量、句向量及隐式篇章关系分布向量等多层次的深度语义信息相结合,利用神经网络训练模型参数并拟合隐式篇章关系类别标签,找到使性能达到最优的模型完成隐式篇章关系的分析。本发明的具体技术方案如下:一种基于层次深度语义的隐式篇章关系分析方法,包括以下步骤:步骤一、语料预处理,具体为:步骤1.1将已有的隐式篇章关系标注语料,分割为训练语料和测试语料,其中,分割的比例为:标注语料共有0-22Section,其中2-20Section作为训练语料,21-22Section作为测试语料;步骤1.2利用篇章连接词匹配的方法,从大规模未标注语料中匹配显式篇章连接词;步骤1.3基于步骤1.2的结果,以篇章连接词和标点为边界划分论元范围,提取出相应的显式篇章关系;步骤1.4将步骤1.3输出的篇章连接词去除,作为伪隐式篇章关系扩充步骤1.1所得的训练语料;步骤二、多层次语义向量初始化,具体为:步骤2.1利用ParagraphVector方法,采用词向量训练模型训练词向量,并将隐式篇章关系论元对所对应的句向量,添加到当前待训练词的上下文中,和词向量一同训练,其中,所述的词向量训练模型,可以采用word2vec;其中,所述的隐式篇章关系为步骤1.4所得训练语料中的隐式篇章关系;步骤2.2将步骤2.1所得结果,以及隐式篇章关系各类别的先验概率,作为步骤三及步骤四所使用的各个层次的隐式篇章关系深度语义向量的初始值;其中,各个层次即多层次;步骤三、生成有用词对表并扩充有用词对表,具体为:步骤3.1将步骤1.4所获取的训练语料作为提取对象,针对每一个隐式篇章关系,从上下两个论元中分别抽取一个词语构成词对,将词对作为研究对象,统计训练语料中所有词对在各篇章关系类别中的信息增益值大小,选取高于阈值的词对构建有用词对表;步骤3.2在步骤3.1基础上,利用词向量的相似度计量,扩充步骤3.1所得的有用词对表,其中,扩充有用词对表的规则为:每个有用词对表中的词对,选取至多六个COSINE相似度最高的词对;步骤四、隐式篇章关系模型训练和类别打分,具体为:步骤4.1针对步骤一所得的训练语料和测试语料中的隐式篇章关系,提取其中包含的有用词对,将词对转换为词向量的拼接形式,同隐式篇章关系论元对向量、隐式篇章关系分布向量相拼接,构成隐式篇章关系的层次深度语义的表征;步骤4.2把步骤4.1中拼接得到的训练语料隐式篇章关系层次深度语义向量,加入到神经网络训练模型中,训练模型参数;步骤4.3把步骤4.1中拼接得到的测试语料隐式篇章关系层次深度语义向量,加入到步骤4.2所得的神经网络训练模型中,拟合隐式篇章关系类别标签给出的相应分数,输出待分类隐式篇章关系的识别结果;至此,从步骤一到步骤四,完成了一种基于层次深度语义的隐式篇章关系分析方法。有益效果一种基于层次深度语义的隐式篇章关系分析方法,对比现有技术,具有如下有益效果:(a).通过采用离散特征选取与深度语义相结合的策略,一方面利用未标注语料扩充已有的训练语料,增加训练打分过程的准确率,另一方面将隐式篇章关系各个层次的语义信息相结合,在隐式篇章关系类别标签的指导下提升分析精度的同时,实现了各层次语义向量的互相优化;(b).弥补了基于离散特征选取的机器学习方法导致的错判;(c).能够有效地利用未标注语料及不同层次语义信息进行分析,使用户能够更快速而准确地获得隐式篇章关系的分析结果。附图说明图1为本发明一种基于层次深度语义的隐式篇章关系分析方法的流程图;图2为本发明一种基于层次深度语义的隐式篇章关系分析方法的隐式篇章关系分类系统架构图。具体实施方式下面结合附图和实施例,对本发明的具体实施方式作进一步详细说明。应该指出,所描述的实施例仅视为说明的目的,而不是对本发明的限制。实施例1本实施例具体叙述了本发明所提方法及本实施例中方法的流程图,如图1所示。从图1可以看出,本发明所提方法包括四个模块:预处理部分,对应步骤一中的语料预处理;向量初始化部分,对应步骤二中的多层次语义向量初始化;特征抽取部分,对应步骤三中的生成有用词对表并扩充有用词对表,以及步骤4.1中的隐式篇章关系的层次深度语义表征;分类部分,对应步骤4.2到4.3中的神经网络模型参数训练,以及隐式篇章关系类别打分;其中,宽箭头表示训练语料的数据流向,窄箭头表示测试语料的数据流向。从图中可以看出:在预处理部分,训练语料的一方面来源于标注语料的一部分,另一方面由未标注语料经模式识别的方法生成,而测试语料则全部来源于标注语料;在向量初始化部分,词向量训练模型,即word2vec,以预处理部分所获得的训练语料为输入,辅以ParagraphVector方法,初始化各个层次的隐式篇章关系深度语义向量的初始值;在特征抽取部分,所抽取的特征一方面是基于训练语料生成的有用词对表,另一方面是训练语料和测试语料层次深度语义的表征;最终在分类部分,训练语料的相关特征汇聚到神经网络模型,训练得到隐式篇章关系分类器,而由此为测试语料中的隐式篇章关系打分并标注类别。实施例2本实施例具体叙述了本发明所提方法的分类系统架构。图2为本发明所提方法的隐式篇章关系分类系统架构图。从图2可以看出,本发明所提方法的隐式篇章关系分类系统,对应步骤四中的隐式篇章关系的层次深度语义表征,神经网络模型参数训练,以及隐式篇章关系类别打分。输入从左到右分别为隐式篇章关系分布向量,即隐式篇章关系先验概率和转移矩阵的乘积,隐式篇章关系论元对向量,和隐式篇章关系有用词对向量;多层次的语义向量相拼接后,构成隐式篇章关系的层次深度语义表征,利用神经网络来训练模型参数,以及预测隐式篇章关系类别;输出即为对应的隐式篇章关系各类别的打分。实施例3本实施例具体叙述了基于本发明所提方法在一台PC机上运行基于层次深度语义的隐式篇章关系分析的流程,具体对应
发明内容中的步骤一到步骤四;本实施例依据英文标注语料库PennDiscourseTreebank(PDTB)及其标注类别,以及未标注语料库CentralNewsAgencyofTaiwan,EnglishService(CNA)和XinhuaNewsAgency,EnglishService(XIN),遵循
发明内容中的步骤顺序:逐一介绍语料预处理方法、多层次语义向量初始化方法、生成有用词对表并扩充有用词对表方法以及隐式篇章关系模型训练和类别打分方法。A)语料预处理,实现步骤如下:1.根据ThePennDiscourseTreebank2.0AnnotationManual一文中对篇章关系标注语料库PDTB所包含的篇章连接词的统计结果,选取出现频率最大的25个篇章连接词,作为判别句子是否包含显式篇章关系的特征依据,剩余的篇章连接词在PDTB中出现的频率均小于1%,故而舍弃;2.遍历未标注语料CNA及XIN,以下为其中的一段文字:所有文章段均以上述形式存储,使用TreeTagger标注工具对其进行词性标注(PartofSpeech,POS标注),其形式如下所示:继而采用显式篇章连接词匹配的方法,从中选取形如[Arg1,connectiveArg2]或[connectiveArg1,Arg2]的句子以篇章连接词和标点为边界划分论元范围,提取出相应的显式篇章关系论元对及其相应的显式篇章连接词,针对实施例第1,2句,有如下提取结果:篇章连接词also出现在实施例第2句中,故将其提取出作为隐式篇章关系连接词,剩余部分分别作为隐式篇章关系的上下论元;3.根据ThePennDiscourseTreebank2.0AnnotationManual一文中对于各显式篇章连接词对应的篇章关系类型,为(2)中所获得的显式篇章关系论元对进行自动标注,若某一篇章连接词可对应多种篇章关系类型,则选取出现频率较大者为标注结果,按照文中统计结果,篇章连接词also对应的篇章关系类型如下所示:由此可知,also更为可能引导Conjunction类别的篇章关系,而Conjunction又是Expansion类别的子类别,故而将实施例标注为Expansion类别;4.去除标注后的显式篇章关系所包含的篇章连接词,将其作为伪隐式篇章关系添加到PDTB语料中,同其中的真实隐式篇章关系一同作为后续步骤的训练语料T;B)多层次语义向量初始化,实现步骤如下:1)训练语料T为步骤一中所提取伪隐式篇章关系,及原有的真实隐式篇章关系集合,其中不包含实施例中所显示的隐式篇章关系连接词及标签;2)首先使用word2vec工具训练词向量,将训练语料集合中所有词汇转换为维度为d的词向量形式,鉴于整体语料规模大约在3G左右,使用连续词袋模型(ContinuousBagofWords,CBOW)训练可以直观地提升效率并保证词汇间的语义相似性,上下文窗口大小设置为3~5之间,迭代次数超过15次即可;3)使用ParagraphVector方法,在word2vec原有的上下文结构中添加各隐式篇章关系论元对向量,使其和词向量一同训练,迭代优化,对于实施例而言,令论元一向量为argument1,论元二向量为argument2,如下所示:设上下文窗口大小为3,则论元一中的词decision/NN的上下文分别为to/TO、the/DT、House/NP、,/,、Wall-Street/NP、share/NN以及论元一向量argument1,将argument1同上述六个词所组成的上下文一同训练,argument2的训练过程同理;4)多次迭代后可得相应的词向量集合以及句向量集合其中|V|和|S|均是集合的规模,而d表示向量的维度;C)生成有用词对表并扩充有用词对表,实现步骤如下:■设置训练语料集合T的隐式篇章关系数为N,某个类别的数量用ni表示,其中i∈{1,2,3,4},代表PDTB语料库标注规范中,隐式篇章关系的四种主要类别,分别为Comparison,Contingency,Expansion和Temporal;■遍历训练语料集合T,对每一个隐式篇章关系,抽取其中所包含的词对,如实施例所示,论元一包含27个词语,论元二包含11个词语,则该篇章关系共包含27×11=297个词对,针对每一词对term,分别统计其总共出现的次数t,以及出现在对应类别class的隐式篇章关系的频数ti,i∈{1,2,3,4};■计算所有词对的信息增益值,计算公式如下:IG(term)=H(class)-H(class|term)=-Σi=14niN·logniN+tN·Σi=14tit·logtit+(N-tN)·Σi=14ni-tiN-t·logni-tiN-t]]>针对每一词对,均可计算出该词对对隐式篇章关系分类的贡献程度,将所有词对按照信息增益值大小排序,选取IG(t)值不小于1e-5的词对构成有用词对集合T';■在T'基础上,针对其中所包含的所有词,计算每个词最相似的三个词用于扩展有用词对集合T',词和词之间的COSINE相似度计算公式如下所示,其中ai和bi分别表示词a和词b对应词向量的第i位:cos(a,b)=Σi=1dai·bi(Σi=1dai·ai)·(Σi=1dbi·bi)]]>利用步骤二中所获得的词向量及COSINE相似度公式,将有用词对的每个词对应的COSINE相似值最高的三个词两两交叉,构成新的词对并添加到有用词对集合中,视为T”,就实施例而言,词对(share/NN,market/NN)在有用词对集合T'中,share/NN最相似的三个词分别为contribution/NN,dividend/NN和division/NN,market/NN最相似的三个词分别为advertise/VV,display/VV和retail/NN,则将(contribution/NN,market/NN)、(dividend/NN,market/NN)、(division/NN,market/NN)、(share/NN,advertise/VV)、(share/NN,display/VV)和(share/NN,retail/NN)均加入有用词对集合中;D)隐式篇章关系模型训练和类别打分,实现步骤如下:(1)设置词向量集合句向量集合其中|V|和|S|均是集合的规模,而d表示向量的维度,再者,隐式篇章关系各类别的先验概率为使隐式篇章关系分布向量同V和A保持维度上的一致,故再设置转移矩阵故而隐式篇章关系分布向量三者作为隐式篇章关系所蕴含的层次深度语义,由表示,隐式篇章关系分析的打分函数如下所示:P=f(WTC)=f(WT·v1,v2a1,a2pT)]]>其中f为sigmoid非线性函数,v1,v2∈V以及a1,a2∈A为待分类的隐式篇章关系所包含的有用词对向量及论元对向量,而矩阵则是需要训练的参数,矩阵P是最终得到的打分结果;(2)对于每个类别的最大似然估计li的公式如下所示:li=log(f(WiTC)label(1-f(WiTC))1-label)=label·logf(WiTC)+(1-label)·log(1-f(WiTC))]]>若打分结果之中i项的得分最高,则预测类别为i,若真实类别r同i相等,则label=1,反之,label=0,由此可知,对于r类别的最大似然估计值,采用的是梯度上升的方法进行优化,而对于非r类别的最大似然估计值,则是采用梯度下降的方法进行优化,这样可以令r类别的打分结果和非r类别间的margin尽可能增大;就实施例而言,其属于Expansion类别,对应的类别项r=3,则当i=3时,label=1,对li进行梯度上升优化,当i!=3时,label=0,对li进行梯度下降优化;(3)由(2)中所示的最大似然估计值,可得到相应的层次深度语义C以及对应参数W的梯度,公式如下所示:∂li/∂C=[label-f(WiTC)]·WiT]]>∂li/∂WiT=[label-f(WiTC)]·C]]>其中可知,C和W在最大似然估计公式中相互对称,故二者的梯度计算公式亦相互对称,除此之外,需要优化的还有隐式篇章关系分布的转移矩阵T,公式如下所示:∂li/∂T=∂li/∂D·pT=[label-f(WiTC)]·WiT·pT]]>(4)根据(2)中关于label的设置,对相应的隐式篇章关系的各层次深度语义向量及其参数矩阵进行梯度上升或下降优化,迭代多次后即可获得隐式篇章关系分类模型。以上所述为本发明的较佳实施例而已,本发明不应该局限于该实施例和附图所公开的内容。凡是不脱离本发明所公开的精神下完成的等效或修改,都落入本发明保护的范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1