数据管理方法及装置与流程
本发明涉及车联网技术领域,尤其涉及一种数据管理方法及装置。
背景技术:
随着全球定位系统(Global Positioning System,简称GPS)、智能手机等的广泛使用,以位置数据为核心的时空数据大量产生。车联网作为物联网的重要应用,近几年也取得了突飞猛进的发展。车联网等应用通过实时采集、存储、分析汽车的时空大数据,可以获得良好的经济、社会收益。目前,车联网接入的车辆规模越来越大,存储的轨迹数据越来越多,查询也越来越复杂,系统在实时存储、查询轨迹数据面临着严峻挑战。
在存储方面,轨迹数据具有数据量大、轨迹重复的特点。轨迹数据一般以轨迹点元组PT表示,PT表示为:<longitude,latitude,t>,其中longitude表示经度,latitude表示纬度,t为时间戳。经过同条道路、路径的轨迹会存在着大量的重复轨迹点。特别是在道路网络中,一辆车的行驶轨迹本身会存在着重复(与历史轨迹对比),大量汽车轨迹间就存在着更多的重复,系统一般以PT的形式存轨迹储数据,行驶过相同道路、路线的车辆,会存储大量相同的轨迹点,从而在存储上有大量冗余。
因此,如何利用道路网络、历史轨迹信息,减少轨迹数据的存储容量和加快轨迹的查询速度是车联网等时空数据系统中亟需解决的技术问题。
技术实现要素:
本发明提供一种数据管理方法及装置,以克服现有技术中轨迹存储冗余、查询速度慢的问题。
第一方面,本发明提供一种数据管理方法,包括:
通过地图匹配方法将原始轨迹点匹配到道路网络中,获取地图匹配后的轨迹集合;
根据训练数据确定不同的道路类型对应的最小支持度和最小路段数量;
根据所述轨迹集合建立轨迹树,并建立以所述轨迹树中的各个节点为起点的轨迹子树;所述轨迹树和所述轨迹子树包括:至少一个节点;所述各个节点为所述道路网络中的交叉路口;
根据所述轨迹子树,确定经过所述各个节点满足所述最小支持度和最小路段数量的轨迹模式;
将各个节点的轨迹模式进行去冗余处理,生成新的轨迹模式,并存储。
第二方面,本发明提供一种数据管理装置,包括:
获取模块,用于通过地图匹配方法将原始轨迹点匹配到道路网络中,获取地图匹配后的轨迹集合;
确定模块,用于根据训练数据确定不同的道路类型对应的最小支持度和最小路段数量;
建立模块,用于根据所述轨迹集合建立轨迹树,并建立以所述轨迹树中的各个节点为起点的轨迹子树;所述轨迹树和所述轨迹子树包括:至少一个节点;所述各个节点为所述道路网络中的交叉路口;
所述确定模块,还用于根据所述轨迹子树,确定经过所述各个节点满足所述最小支持度和最小路段数量的轨迹模式;
处理模块,用于将各个节点的轨迹模式进行去冗余处理,生成新的轨迹模式;
存储模块,用于存储所述新的轨迹模式。
本发明数据管理方法及装置,通过地图匹配方法将原始轨迹点匹配到道路网络中,获取地图匹配后的轨迹集合;根据训练数据确定不同的道路类型对应的最小支持度和最小路段数量;根据所述轨迹集合建立轨迹树,并建立以所述轨迹树中的各个节点为起点的轨迹子树;所述轨迹树和所述轨迹子树包括:至少一个节点;所述各个节点为所述道路网络中的交叉路口;进一步的,根据所述轨迹子树,确定经过所述各个节点满足所述最小支持度和最小路段数量的轨迹模式;将各个节点的轨迹模式进行去冗余处理,生成新的轨迹模式,并存储,上述方法使用道路网络和历史轨迹,抽取出以道路网络为基础的轨迹模式然后,通过对轨迹模式的组合优化,实现以轨迹模式为基础的存储。最终,达到减少轨迹数据存储冗余,同时也能够实现加快轨迹查询速度的目的。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为道路网络中轨迹示意图;
图2为本发明实施例的系统组件示意图;
图3为本发明数据管理方法一实施例的流程示意图;
图4为本发明数据管理方法一实施例的地图匹配示意图;
图5为空间线-线关系示意图;
图6为轨迹模式示意图;
图7为道路类型分布示意图;
图8为轨迹长度分布示意图;
图9为本发明实施例中轨迹模式挖掘过程示意图;
图10为本发明实施例中轨迹模式组合优化示意图;
图11为本发明基于轨迹模式关系的自适应算法和一般频繁算法挖掘的轨迹模式道路覆盖率随最小支持度和最小路段数量变化的示意图;
图12为本发明基于轨迹模式关系的自适应算法和一般频繁算法挖掘的轨迹模式邻接关系比率随最小支持度和最小路段数量变化的示意图;
图13为本发明基于轨迹模式关系的自适应算法和一般频繁算法挖掘的轨迹模式包含关系比率随最小支持度和最小路段数量变化的示意图;
图14为本发明基于轨迹模式关系的自适应算法和一般频繁算法挖掘的去冗余率随最小支持度和最小路段数量变化的示意图;
图15为路径查询的查询时间比率示意图;
图16为本发明数据管理装置一实施例的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
车联网作为物联网的重要应用,近几年取得了突飞猛进的发展。计算技术的发展使得位置数据的采集频率不断提高,采集的数据量成爆发式增长。众多车载终端对位置数据的采集和上传时间已由分钟级提升至秒级,一个由上万辆车组成的车联网系统,每天面临着上亿个轨迹点的存储压力。车联网作为典型的时空大数据应用,轨迹查询也主要集中在道路网络中,面临着大量实时位置、轨迹路径等多样化查询的挑战。随着车辆规模的持续增长,轨迹存储和查询面临越来越大的压力。
一般情况下,轨迹数据管理系统对轨迹点采用轨迹点元组PT的形式进行存储。例如PT表示为:<longitude,latitude,t>,其中longitude表示经度,latitude表示纬度,t为时间戳。所有的存储、查询也都围绕着PT进行。轨迹点元组可以灵活、方便地表示轨迹,但也存在着GPS采样误差带来的数据不准确、大量数据的空间复杂性等问题。同时,在车联网系统中,更存在着存储冗余、查询效率低的问题。
轨迹T=<PT1,PT2…PTn>,n是轨迹中PT的数目。一条车辆轨迹T是一个PT的时间有序序列。
而且道路网络也被用来表示轨迹,一个轨迹点经过地图匹配(将车辆轨迹T与地图中道路网络RN匹配的过程),转化为地图匹配点。即MMP=<rid,dis,t>,表示一个PT点经地图匹配算法匹配到道路网络RN中的一个道路段RS,其中,rid表示匹配的道路段RS的标识id,dis表示道路段中对应的匹配点到道路段起点的距离,t表示时间戳。行驶过相同道路的轨迹就包括重复的道路,以MMP的形式表示,系统在存储上存在冗余。
其中,道路网络RN=G(V,E),道路网络是一个有向图,其中,V表示顶点GP的集合,E表示道路R的集合。
GP=<longitude,latitude>,longitude表示经度,latitude表示纬度,GP表示一个GPS位置。道路段RS=<rid,GPstart,GPend,attributes>,其中,rid是道路段的id,GPstart是道路段的起点,GPend是道路段的终点,attributes是道路段的属性,如长度、方向等。一个道路段是道路中一个起点到终点的路段。道路R=<Rid,(RS1,RS2…RSm),attributes>,Rid表示道路的id,RSi表示道路中的某个路段,m是该道路包含的路段数量,attributes是道路的属性,包括道路的名称、长度、方向等。一条道路是一个RS序列。
图1为道路网络中轨迹示意图。对于车辆轨迹这种明显在道路网络中存在空间约束的数据,查询主要集中在道路网络上。如果以PT的形式表示轨迹,无论何种精度的查询都需要对原始轨迹点计算。如图1所示,图1中包含道路R1、R2、R3、R4、R5、R6,轨迹T由轨迹点P1,P2…P9等组成,查询P5的精确位置时,根据P5的经纬度将其匹配到路段V1V4上,之后得到其在V1V4上的精确位置。查询轨迹T的路径时,我们需要对9个轨迹点全部计算才能得到。实际上,我们只需要得到T经过的路段V7V4、V4V1、V1V2、V2V3即可,不需要知道每个轨迹点的精确位置。同时道路V7V4存在多个轨迹点,更需要对P1、P2、P3、P4重复计算。如果使用PT的形式表示轨迹,每次查询时,系统都会进行匹配和重复计算,产生查询效率低的问题。
当我们使用轨迹点元组PT表示轨迹点时,无论是地理数据库,例如PostGIS;还是分布式数据库,例如HBase,仍然存在着存储冗余和查询效率低的问题。PostGIS等地理数据库通过增加地理类型、索引、地理查询函数等来实现地理查询,其重点主要集中在地理数据的处理、优化上。HBase等分布式数据存储系统主要在可靠性、扩展性、存储量等方面有着明显的优势。以上系统虽然会在存储或查询上做出优化,但是以轨迹点元组为基础,存储和查询仍然存在上述问题。
通过上面的分析可以发现:
首先,车联网等大规模时空应用系统中的轨迹存在着大量重复,以轨迹点元组的形式表示,存储存在冗余的问题。
其次,车联网等大规模时空应用系统中的轨迹查询主要集中在道路网络上,以轨迹点元组的形式表示轨迹,查询存在效率低的问题。
因此,如何在满足车联网多样化查询的要求下,利用道路网络和历史轨迹信息,减少轨迹的存储冗余,加快轨迹查询速度是车联网等时空数据系统的重要研究内容。
因此,本发明实施例中的方法针对上述问题进行改进。
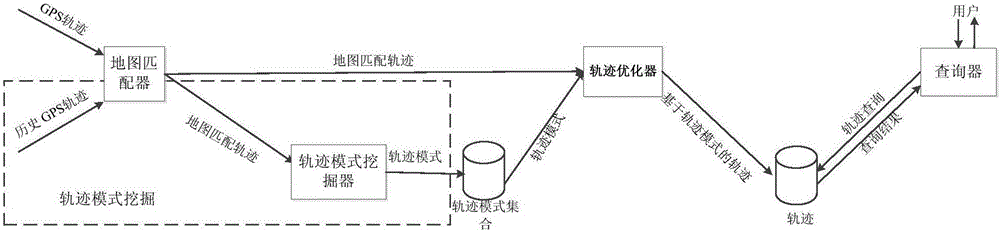
图2为本发明实施例的系统组件示意图。本发明实施例的系统主要包括地图匹配器(Map Matcher)、轨迹模式挖掘器(Trajectory Pattern Miner)、轨迹优化器(Trajectory Optimizer)、查询器(Querier)等部分。主要组件如图2所示,地图匹配器对原始轨迹T进行预处理,并将其匹配到道路网络RN中;轨迹模式挖掘器从大量匹配轨迹MMT集合中挖掘轨迹模式;轨迹优化器对匹配后的轨迹MMT选取合理的轨迹模式进行组合,并引用轨迹模式生成新轨迹NT;用户使用查询器进行常用的轨迹查询。
图3为本发明数据管理方法一实施例的流程示意图。图4为本发明数据管理方法一实施例的地图匹配示意图。如图3所示,本实施例的方法,包括:
步骤301、通过地图匹配方法将原始轨迹点匹配到道路网络中,获取地图匹配后的轨迹集合;
本步骤中,地图匹配是轨迹应用的基础,由于GPS设备的限制、采样误差、实际道路环境等的制约,原始轨迹点并不一定准确,这就需要地图匹配技术完成原始轨迹点到地图道路段的匹配。车联网系统上传轨迹点的时间为秒级,产生的轨迹密集。同时,数据中还包括车辆速度、驾驶方向等,为精细化匹配提供了可能。以轨迹点元组表示的历史轨迹已经在系统中存在,我们采用全局匹配的方法。
在匹配预处理阶段,我们根据前后轨迹点(轨迹点按照时间排序)的距离、时间来进行轨迹切分。匹配时,我们对每个轨迹点与候选道路的距离、方向的匹配度和单双向行驶规则,获取该轨迹点对应的候选道路集合。对多个候选道路集合组成的候选子图,搜索出与原始轨迹点的距离最优匹配的路径,形成轨迹集合。同时,在道路网络中搜索前后点的路径时,算法对前后两个道路段根据实际的道路连通性、驾驶距离、速度进行判断,并不是简单地使用最短路径。经过地图匹配,原始轨迹T变为地图匹配轨迹MMT,原始轨迹转化为道路网络的表示方法。如图4所示,对由轨迹点Pi到Pj组成的轨迹,对其中的每一个点,分别得到候选道路集n为某个道路对应的候选轨迹模式集合的大小,对由Ci到Cj构成的子图,搜索每一条路径,得到与原始轨迹点的距离匹配的最优路径。
步骤302、根据训练数据确定不同的道路类型对应的最小支持度和最小路段数量;
图5为空间线-线关系示意图。轨迹模式和道路网络紧密相关,空间中的线线关系如图5所示,主要为相离、相交、叠加、相接、包含、包含于、相等等七种关系。TP=<pid,(RS1,RS2…RSp),attributes>。其中,TP中任意一个RSi在MMT集合中出现次数超过最小支持度(次数)min_sup,TP长度p超过最小路段数量min_len,pid是TP的id,(RS1,RS2,…RSi)是RN中一条有效连通路径,attributes是轨迹模式的属性,如大小、长度、方向等。一个轨迹模式TP是一个有效连通的RS序列。由轨迹模式TP定义可知,轨迹模式由道路段组成,轨迹模式间明显存在着相离、叠加、相接、包含等关系。在频繁项的挖掘问题中,候选子集是一个挑战。一个项是频繁的,则它的每个子集也是频繁的。因此,一个轨迹模式的每个子集也是轨迹模式,我们需要从大量的历史轨迹中识别出轨迹模式,在挖掘时子集会产生大量的轨迹模式。同时,不同的道路有不同的交通流量,城市环路、主干道明显有更多的轨迹。如果挖掘时使用较大的min_sup,包含很多道路的轨迹模式会被忽略;如果使用较小的min_sup,又会产生大量的轨迹模式。不同轨迹的长度也不同,不同的min_len也会产生类似的问题。如何全面地挖掘道路网络中的轨迹模式,具有重要的意义。
然而,传统的频繁模式挖掘算法在挖掘过程中会产生大量子集,对车联网这种大量历史轨迹集的挖掘并不适用。图6为轨迹模式示意图。结合轨迹模式的关系,我们可以从图6中得到,图6中包含道路R1、R2、R3、R4、R5、R6、R7、R8,轨迹模式TP1与TP3、TP4相离,TP4与TP2在道路a叠加,TP2与TP3在交叉路口V6相接,TP3包含TP4(相同道路b)。在图中,道路V13V9包括路段r1,r2…rn,假设V13V9为轨迹模式,min_len=1,我们很容易得到r1,r2,…rn,r1r2,r2r3,…rn-1rn,…,r1r2…rn均为轨迹模式。即ri…rj(1<=i<=j<=n)均是轨迹模式,此时该道路产生的轨迹模式数量为如果min_len=m,则轨迹模式数量为由于包含关系,一个道路段长度为n的轨迹模式会产生数量为n2的子轨迹模式。
在实际驾驶过程中,汽车轨迹一般在交叉路口发生变化,路口能够很好地反应轨迹模式间的关系,特别是叠加和相接关系。我们已经知道不同的道路有不同的道路流量。例如根据OpenStreetMap地图,北京市的道路分为不同的道路类型。实际上,我们通过相接关系可以灵活地使用轨迹模式。例如,将两个相接关系的轨迹模式组合起来,可以生成新的轨迹模式。我们通过对路口进行挖掘,可以提取出大量相接关系的轨迹模式。针对不同道路的不同交通流量,我们提出结合道路类型的min_sup自适应挖掘方法。
挖掘前,我们从车联网系统中抽取了部分轨迹作为训练数据集合。图7为道路类型分布示意图。我们对北京市的道路网络进行了统计,不同道路类型分布如图7所示。我们统计了经过不同道路类型的轨迹数量,挖掘时以此作为不同类型的道路对应的min_sup的值。图8为轨迹长度分布示意图。同时,我们统计了这些轨迹的长度,轨迹长度的分布如图8所示。由于地图匹配后,绝大多数的轨迹长度在100以下,我们在挖掘时设置了低于100的不同的min_len。
步骤303、根据所述轨迹集合建立轨迹树,并建立以所述轨迹树中的各个节点为起点的轨迹子树;所述轨迹树和所述轨迹子树包括:至少一个节点;所述各个节点为所述道路网络中的交叉路口;
其中,在实际应用中,建立以所述轨迹树中的各个节点为起点的轨迹子树之前,还包括:
根据所述轨迹集合建立节点项列表;
相应的,建立以所述轨迹树中的各个节点为起点的轨迹子树,包括:
根据所述轨迹树和所述节点项列表通过深度优先搜索,建立以所述轨迹树中的各个节点为起点的轨迹子树。
步骤304、根据所述轨迹子树,确定经过所述各个节点满足所述最小支持度和最小路段数量的轨迹模式;
具体的,给定一个道路网络RN,地图匹配后的历史轨迹集合Set<MMT>,从Set<MMT>中挖掘出符合最小支持度min_sup和最小路段数量min_len的轨迹模式集合Set<TP>。
本发明实施例的方法中利用了基于轨迹模式关系的自适应轨迹模式挖掘算法,其利用交叉路口作为起始挖掘节点,对不同类型的道路采用不同的最小支持度min_sup。首先,对全部匹配过的历史轨迹,构建一棵轨迹树Root和节点项列表List。其中,Root中的每个节点表示某一路口或路段,以及经过该节点的轨迹数量。节点项列表List包括某一路口或路段在轨迹树中出现的所有位置。然后,利用道路网络的交叉路口,根据节点项列表List、轨迹树Root构建以该路口为起点的轨迹子树。之后,根据每棵轨迹子树的节点信息,主要包括经过该节点的轨迹数量、道路类型等,动态确定该路口的轨迹模式的min_sup。即根据预先确定的不同的道路类型对应的最小支持度和最小路段数量,确定该路口的轨迹模式的min_sup。最后,统计经过该节点,且满足min_sup、min_len的轨迹作为轨迹模式,并保存该轨迹模式的道路段列表、距离、长度、方向等信息。上述过程中根据每个交叉路口的轨迹数量、道路类型,动态调整轨迹模式的min_sup,并充分利用了轨迹模式的关系。
图9为本发明实施例中轨迹模式挖掘过程示意图。如图9所示,轨迹树Root由道路段或路口A、B……I组成,节点项列表List包含Node列表。对于图中路口C,其在Root中3个位置出现。在生成轨迹树Root和节点项列表List后,对每个路口创建轨迹子树。路口C在轨迹子树中出现了4次,如果min_sup=2和min_len=2,我们可以轻易地从图中得到路径CF是一个轨迹模式。
图10为本发明实施例中轨迹模式组合优化示意图。
步骤305、将各个节点的轨迹模式进行去冗余处理,生成新的轨迹模式,并存储。
具体地,给定一个轨迹模式集合Set<TP>,一条地图匹配轨迹MMT,如何从Set<TP>中选择合适的轨迹模式来生成NT,使其满足如下公式(1):
其中,对于某一路段RSi,TPSi为其对应的候选轨迹模式集合。为TPSi中用来生成NT的轨迹模式,目标为使NT中引用的轨迹模式集合的并集最小。
轨迹模式TP=<pid,(RS1,RS2…RSp),attributes>。其中,TP中任意一个RSi在MMT集合中出现次数超过最小支持度(次数)min_sup,TP长度p超过最小路段数量min_len,pid是TP的id,(RS1,RS2,…RSi)是RN中一条有效连通路径,attributes是轨迹模式的属性,如大小、长度、方向等。一个轨迹模式TP是一个有效连通的RS序列。
轨迹模式元组TPT=<pid,(<dis1,t1>,<dis2,t2>,…<disq,tq>)>,其中,pid为轨迹模式id,dis表示某个轨迹点距离轨迹模式起点的距离,t表示时间戳。轨迹模式元组是一个包含轨迹模式的距离、时间戳序列。轨迹模式元组是基于轨迹模式的轨迹表示。
新轨迹NT=<TPT1,TPT2,MMPi…TPTr>,r为NT中TPT的数目。新轨迹是一个TPT的序列,其通过引用轨迹模式来表示轨迹。
在RN中,一个路段可能属于多个TP,MMT中的一个MMP可以使用多个TP来表示,使用不同的TP对去冗余有不同的效果。由于轨迹模式不能覆盖全部道路,部分路段可能不属于任何轨迹模式。我们希望尽可能多地使用轨迹模式来表示轨迹,同时,希望使用轨迹模式来达到最好的去冗余率,此时,引用的轨迹模式的总数量要尽可能地少,如公式(1)所示。对于某条MMT=<MMP1,MMP2,…MMPj>,MMPi中路段对应的轨迹模式集合为组合优化过程如图10所示,此时,选出最优的组合需要遍历TPS1到TPSj等元素构成的子图,问题的时间复杂度为O(mj)。车联网系统中数据采集频率为秒级,一条轨迹包含许多轨迹点,使用上述方法显然不能满足需求。轨迹组合优化算法需要在短时间内选出较优的轨迹模式。
根据以上的分析,我们需要对轨迹模式进行组合优化来获得新轨迹。为了取得最优的效果,我们需要遍历多个轨迹模式集合构成的子图,找到最优方案的时间代价太大。本发明实施例中提出轨迹模式局部最长匹配的近似解算法。算法对MMT中的每一个MMP,查找MMP所属的道路段对应的所有轨迹模式currentCandidate;然后,与上一路段(相邻路段)的候选轨迹模式求交集;持续进行该过程直至交集为空。最后,选出任意一个轨迹模式,得到局部最长匹配的轨迹模式,并将其添加到结果集中。根据上述算法,我们只引用局部最长匹配的轨迹模式,可以大大减少候选轨迹模式的数量。两个相邻匹配轨迹点的轨迹模式交集的时间复杂度为O(m2),算法的整体时间复杂度为O(m2n)。与现有的算法相比,本发明实施例算法的效率明显更高,适用于车联网的应用场景。
本实施例的方法,通过地图匹配方法将原始轨迹点匹配到道路网络中,获取地图匹配后的轨迹集合;根据训练数据确定不同的道路类型对应的最小支持度和最小路段数量;根据所述轨迹集合建立轨迹树,并建立以所述轨迹树中的各个节点为起点的轨迹子树;所述轨迹树和所述轨迹子树包括:至少一个节点;所述各个节点为所述道路网络中的交叉路口;进一步的,根据所述轨迹子树,确定经过所述各个节点满足所述最小支持度和最小路段数量的轨迹模式;将各个节点的轨迹模式进行去冗余处理,生成新的轨迹模式,并存储,上述方法使用道路网络和历史轨迹,抽取出以道路网络为基础的轨迹模式,然后通过对轨迹模式的组合优化,实现以轨迹模式为基础的存储。最终,达到减少轨迹数据存储冗余,同时也能够实现加快轨迹查询速度的目的。
在上述实施例的基础上,本实施例中,轨迹模式挖掘的代码实现如下:
轨迹模式挖掘算法伪代码如Algorithm 1所示。算法使用历史匹配轨迹集合Set<MMT>和道路网络RN作为输入,轨迹模式集合Set<TP>作为输出。算法第4行表示将地图匹配后的轨迹加入到轨迹树Root中,第8行表示自适应地确定每个路口的min_sup和min_len,第9行表示创建该路口的轨迹子树,第10行根据min_sup、min_len从轨迹子树nodeTrie中查找符合的子轨迹作为轨迹模式,第11行表示将挖掘到的轨迹模式加入到轨迹模式集合中。
在上述实施例的基础上,本实施例中,步骤305中将各个节点的轨迹模式进行去冗余处理,生成新的轨迹模式,包括:
步骤a、对轨迹集合中每一条地图匹配轨迹MMT中的每一个地图匹配点MMP,查找所述MMP所属的道路段对应的所有轨迹模式,获取第一候选轨迹模式集合,与相邻道路段的第二候选轨迹模式集合求交集;
步骤b、重复执行步骤a,直至所述交集为空;将第二候选轨迹模式集合中的任意一个轨迹模式作为局部最长匹配的轨迹模式。
去冗余处理的代码实现如下:
在上述实施例的基础上,本实施例中的方法,还包括如下步骤:
对包含至少一个轨迹点的轨迹进行查询,获取所述轨迹经过的道路段以及所述轨迹的距离。
具体的,本实施例中是基于轨迹模式的轨迹查询。其中,通过引用轨迹模式生成的新轨迹模式已经减少了数据项的数目,实现了去冗余的效果。轨迹查询操作直接引用轨迹模式对距离进行计算。以路径path查询为例,path查询是对轨迹经过的道路列表和距离的查询。如图1中的轨迹T,包含P1至P9等9个轨迹点,假设longitude、latitude为double类型,t为int类型,存储double类型需要8bytes,int类型为4bytes,存储轨迹T需要180bytes。使用轨迹模式表示后,假设pid、t为int类型,dis为double类型,存储新轨迹NT只需要112bytes。查询轨迹T经过的路径时,根据新轨迹NT包含的V7V4、V4V1、V1V2、V2V3等路段信息,轨迹起始距离dis1、dis9,可以直接得到该轨迹模式这两个距离内的路径。其他常用查询操作过程类似,均使用轨迹模式和距离信息。
通过对本发明实施例方法的实际测试,本发明可以有效减少约38%的轨迹存储冗余,加快约40%的轨迹查询速度。整体上说,第一,本发明实现了道路网络中基于轨迹模式关系的自适应挖掘方法,并实现了轨迹模式的组合优化方法,减少了轨迹的存储冗余,节约存储空间。第二,本发明实现了基于轨迹模式的查询,加快查询速度。
下面对上述实施例进行仿真测试,仿真结果如下:
图11为本发明基于轨迹模式关系的自适应算法和一般频繁算法挖掘的轨迹模式道路覆盖率随最小支持度和最小路段数量变化的示意图。
道路覆盖率RC=NRS’/NRS,NRS’为TP集合中的道路段数目,NRS为RN中的道路段数目。
从图11中可以看出,两种算法的道路覆盖率RC随最小路段数量的增大而减小。本发明方法的道路覆盖率RC高于一般频繁算法。
图12为本发明基于轨迹模式关系的自适应算法和一般频繁算法挖掘的轨迹模式邻接关系比率随最小支持度和最小路段数量变化的示意图。
图13为本发明基于轨迹模式关系的自适应算法和一般频繁算法挖掘的轨迹模式包含关系比率随最小支持度和最小路段数量变化的示意图。
从图12、图13中可以看出,两种算法挖掘的邻接、包含关系的比率随最小路段数量的增大而增大。在最小路段数量相同的情况下,本发明方法的邻接关系高于一般频繁算法,包含关系却低于一般频繁算法。通过本实验可以看出,本发明方法的道路覆盖率最高,而且,产生了较少包含关系的轨迹模式。
轨迹存储去冗余的效果:
以PT表示轨迹点,PT=<longitude,latitude,t>,假设longitude、latitude为double类型,t为int类型,存储double类型占用8bytes,存储int类型占用4bytes,存储一个轨迹点元组占用20bytes。以MMP表示地图匹配点,MMP=<rid,dis,t>,假设rid、t为int类型,dis为double类型,存储匹配后的地图匹配点占用16bytes。以TPT表示新轨迹模式元组,假设pid、t为int类型,dis为double类型。以MMP代替PT,无损去冗余率CR为(n为轨迹点个数,16n为用MMP表示轨迹的存储空间,20n为用PT表示轨迹的存储空间)。用NT代替PT,无损去冗余率CR为(n为轨迹点个数,m为轨迹模式的个数,其中,1=<m<=n,4m+12n为以NT表示轨迹的存储空间,20n为以PT表示轨迹的存储空间)。根据m的取值范围,无损压缩率在20%~40%之间。当然,存储轨迹模式集合也需要一部分空间,使用自适应算法,在min_len=10时,轨迹模式的数量为12万多个,占用约137MB的存储空间,在大量的轨迹面前,轨迹模式集合所占的空间可以接受。
图14为本发明基于轨迹模式关系的自适应算法和一般频繁算法挖掘的去冗余率随最小支持度和最小路段数量变化的示意图。
去冗余率CR=1-T’/T,T为原始轨迹的存储空间,T’为去冗余后的轨迹存储空间。
从图14中可以看到,经过组合优化算法,轨迹在本发明方法、一般频繁项挖掘算法中的去冗余率可以达到38%,接近于40%的理论极限值,取得了很好的效果。
轨迹查询的效果
图15为路径查询的查询时间比率示意图。
查询时间比率QTR=QTP/QLL,QTP是本发明方法基于轨迹模式的查询时间,QLL是现有的基于轨迹点元组的查询时间。
我们分别对轨迹点元组、基于轨迹模式的轨迹进行了path查询对比实验。从图15中可以看到,对于绝大多数轨迹,基于轨迹模式的path查询时间是基于轨迹点元组的60%,查询效率要高40%。
图16为本发明数据管理装置一实施例的结构示意图。如图16所示,本实施例的数据管理装置,包括:
获取模块,用于通过地图匹配方法将原始轨迹点匹配到道路网络中,获取地图匹配后的轨迹集合;
确定模块,用于根据训练数据确定不同的道路类型对应的最小支持度和最小路段数量;
建立模块,用于根据所述轨迹集合建立轨迹树,并建立以所述轨迹树中的各个节点为起点的轨迹子树;所述轨迹树和所述轨迹子树包括:至少一个节点;所述各个节点为所述道路网络中的交叉路口;
所述确定模块,还用于根据所述轨迹子树,确定经过所述各个节点满足所述最小支持度和最小路段数量的轨迹模式;
处理模块,用于将各个节点的轨迹模式进行去冗余处理,生成新的轨迹模式;
存储模块,用于存储所述新的轨迹模式。
可选地,作为一种可实施的方式,所述获取模块,具体用于:
获取所述原始轨迹点对应的候选道路集合;
对多个候选道路集合组成的候选子图,搜索出与所述原始轨迹点的距离最优匹配的轨迹集合。
可选地,作为一种可实施的方式,所述处理模块,具体用于执行如下步骤:
步骤a、对轨迹集合中每一条地图匹配轨迹MMT中的每一个地图匹配点MMP,查找所述MMP所属的道路段对应的所有轨迹模式,获取第一候选轨迹模式集合,与相邻道路段的第二候选轨迹模式集合求交集;
步骤b、重复执行步骤a,直至所述交集为空;将第二候选轨迹模式集合中的任意一个轨迹模式作为局部最长匹配的轨迹模式。
可选地,作为一种可实施的方式,还包括:
查询模块,用于对包含至少一个轨迹点的轨迹进行查询,获取所述轨迹经过的道路段以及所述轨迹的距离。
可选地,作为一种可实施的方式,所述轨迹树和所述轨迹子树中包括各个节点的节点信息,所述节点信息包括:经过所述节点的轨迹数量、道路类型。
可选地,作为一种可实施的方式,建立模块,还用于:
根据所述轨迹集合建立节点项列表;
相应的,建立模块,具体用于:
根据所述轨迹树和所述节点项列表通过深度优先搜索,建立以所述轨迹树中的各个节点为起点的轨迹子树。
本实施例的装置,可以用于执行上述方法实施例的技术方案,其实现原理和技术效果类似,此处不再赘述。
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于一计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:ROM、RAM、磁碟或者光盘等各种可以存储程序代码的介质。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!