一种面向数据稀疏环境下的移动路径混合预测方法与流程
本发明属于移动计算技术领域,特别涉及是一种面向数据稀疏环境下的移动路径混合预测方法。
背景技术:
目前,随着移动定位与追踪技术的快速发展与广泛普及,使得利用位置感知设备以获取移动对象的历史轨迹数据成为可能。通过对历史轨迹数据进行语义化建模与计算求解,以实现历史轨迹大数据的价值提取与知识发现,从而支撑相关移动服务应用,已经成为移动计算领域的一个显著趋势与必然特征,同时引起了学术界与产业界的高度关注。
基于大规模群体感知历史轨迹数据,高效挖掘并提取其中具有普遍性的、规律性的移动特征与行为模式,构建移动行为知识库;通过对移动轨迹的数学建模,利用最大概率推导方法,可实现对移动用户的在线路径精准预测。该技术可以广泛应用于城市交通智能化调度与管理、基于位置的商业精准广告营销、旅游路线推荐等诸多领域。然而,在实际应用中,上述方法存在两个方面的问题,具体表现为:1)上下文及背景知识数据的不易获取使得结合地图匹配(Map Matching Technique)或是交通流量(Traffic Flow)统计方法以改善移动路径预测精度难以奏效;2)感知数据价值密度低这一本质特征所带来的数据稀疏问题(Data Sparsity Problem)使得传统的基于近似度计算或是模式匹配的方法难以奏效。上述问题的存在对于移动路径预测方面的应用服务带来了巨大的挑战。因此,针对海量感知轨迹数据的稀疏性分布特征,如何在上下文及背景知识数据缺失的条件下构建应用性强、可靠性高的移动路径精准预测模型及方法具有十分重要的现实意义与应用价值。
技术实现要素:
发明提供一种面向海量移动轨迹数据稀疏性分布的路径预测方法,所采用的技术方案是:
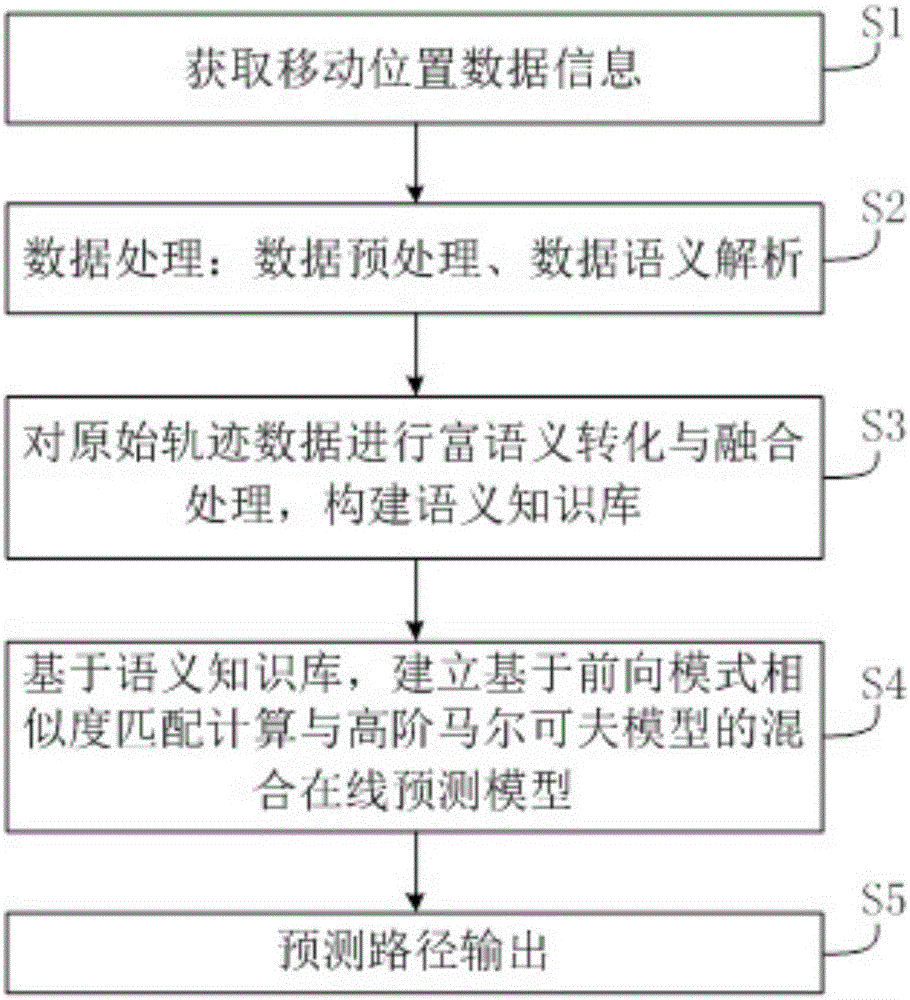
一种面向数据稀疏环境下的移动路径混合预测方法,包括以下步骤:
S1:获取移动位置数据信息;
S2:数据处理:对于数据进行数据预处理和数据语义解析;
S3:构建语义知识库:对原始轨迹数据进行富语义转化与融合处理,构建语义知识库;
S4:构建混合在线预测模型:基于语义知识库,建立基于前向模式相似度匹配计算与高阶马尔可夫模型的混合在线预测模型;
S5:预测路径输出:在混合在线预测模型中输入待预测轨迹片段进行预测,输出预测路径。
进一步地,一种面向数据稀疏环境下的移动路径混合预测方法,所述S1中移动位置数据信息包括待预测轨迹片段。
进一步地,一种面向数据稀疏环境下的移动路径混合预测方法,所述的S2中数据语义解析包括对数据进行统一化的语义坐标转换操作,分割成完整移动轨迹段,并进行标注。
进一步地,一种面向数据稀疏环境下的移动路径混合预测方法,所述的S3中对原始轨迹数据进行富语义化转化和融合处理包括:隐含地图语义化分割、路网骨架简约节点抽取、移动模式知识发现。
进一步地,一种面向数据稀疏环境下的移动路径混合预测方法,所述的S3中对原始轨迹数据进行富语义化转化和融合处理还包括区域级Pair迁移矩阵,所述的区域级Pair迁移矩阵是基于隐含地图语义化分割处理而计算得到。
进一步地,一种面向数据稀疏环境下的移动路径混合预测方法,所述的S3中对原始轨迹数据进行富语义化转化和融合处理还包括多连续状态迁移概率模型,所述多连续状态迁移概率模型用于对分段轨迹序列转化语义数据。
进一步地,一种面向数据稀疏环境下的移动路径混合预测方法,所述的S4中前向模式匹配包括元素匹配和距离计算。
进一步地,一种面向数据稀疏环境下的移动路径混合预测方法,优先执行前向模式匹配预测过程,在匹配过程有解时输出预测路径;在匹配过程无解时,执行Markov概率推理模型,以当前移动状态为基准,前向递推相应阶次连续状态迁移概率分布,以概率最大值者作为所输出的步长为1的预测路径,通过递归循环过程,以所预测的目的地位置信息作为终止条件,输出预测路径。
进一步地,一种面向数据稀疏环境下的移动路径混合预测方法,所述S5中待预测轨迹片段输入前要执行相应的S2中的数据处理。
进一步地,一种面向数据稀疏环境下的移动路径混合预测方法,针对S2中数据预处理与语义解析步骤设计了相应的动态监控管理与消息产生流程控制。
本发明提供了一种面向移动轨迹数据稀疏性分布的路径预测方法,通过历史轨迹数据构建城市地图语义模型以实现对原始轨迹数据的富语义转换与融合,建立历史移动模式匹配计算(Pattern Matching Computing)与高阶马尔科夫(Higher Order Markov Model)混合预测方法,其实质就是构建混合、可替换的协同式预测模型,一方面充分利用前向模式相似度匹配在时序无约束历史信息方面的优势,以提升路径预测精度;另一方面以可替换的高阶马尔科夫模型构建严格时序关系下的分段轨迹移动状态迁移概率矩阵模型,以有效克服数据稀疏所带来的模式匹配失效(No Pattern Matching)问题,同时显著了提升路径预测的准确性,满足了移动服务应用对于实时性、高效性、可预测性等方面的需求。
附图说明
图1为本发明一种面向数据稀疏环境下的移动路径混合预测方法步骤示意图;
图2为本发明一种面向数据稀疏环境下的移动路径混合预测方法前向模式相似度匹配结果示意图;
图3为本发明一种面向数据稀疏环境下的移动路径混合预测方法在线预测轨迹不同已知长度下的路径预测结果;
图4为本发明一种面向数据稀疏环境下的移动路径混合预测方法预测结果示意图。
具体实施方式
一种面向数据稀疏环境下的移动路径混合预测方法,包括以下步骤:
S1:获取移动位置数据信息;
所述信息从多源位置感知源(车载GPS、移动智能手机、PDA等)接收并存储数据。本实施例中移动位置数据信息包括待预测轨迹片段。
S2:数据处理:对数据进行数据预处理和数据语义解析;
如图1所示:其中对数据进行预处理为:对所收集的历史轨迹数据进行预处理操作,具体包括:1)由于定位装置信号强弱变化以及数据传输过程中的信道变化所引入的噪声数据,该模块进行噪声检测与过滤处理;2)由于移动对象快速移动过程中链路连接的不稳定性以及数据传输过程中的丢包现象所导致的数据缺失现象,该模块进行等时间间隔的数据插值操作;
其中数据语义解析包括对数据进行统一化的语义坐标转换操作,分割成完整移动轨迹段,并进行标注:1)由于移动轨迹采集过程的自动化流程以及标注属性的缺失,该模块对连续采集移动轨迹执行基于时间间隔阈值及空间间隔距离阈值的Complete完整轨迹段的语义分割操作;2)由于多源移动定位设备在空间坐标体系选取方面的差异性原因(WGS84坐标系、GGRS87坐标系、GSM坐标系等),该模块执行统一化的语义坐标转换操作。
本实施例中对此步骤S2数据处理步骤设计了相应的动态监控管理与消息产生流程控制,即在移动轨迹数据接收及解析过程中,通过流程控制器控制数据接收及语义解析过程的流程化操作。
S3:构建语义知识库:对原始轨迹数据进行富语义转化与融合处理,构建语义知识库;所述的S3中对原始轨迹数据进行富语义化转化和融合处理包括:
如图3所示,隐含地图语义化分割具体实现过程为:基于大规模历史离线轨迹位置点的空间分布特征计算其二维密度函数,结合二维密度函数与边界逼近值集合,实现对隐含地图地理空间语义拓扑关系的重构与区域级空间面积的二次划分过程;
路网骨架简约节点抽取:与隐含地图语义化分割模块类似,基于大规模移动轨迹数据的空间分布密度特征,抽取带路网约束下的移动受限轨迹数据的隐含位置点,形成路网骨架简约节点集合。
路网骨架简约节点抽取过程以历史移动轨迹中的相邻k个序列的移动转角计算为依据,通过基于密度的聚类方法抽取关键路网节点。
移动模式知识发现具体为以隐含地图语义化分割与路网骨架简约节点输出集合为基础,对原始采集移动轨迹数据进行富语义化转化过程,进而基于序列模式挖掘算法高效提取潜在的移动行为模式集合,为后续的移动路径预测提供知识支撑。
所述的S3中对原始轨迹数据进行富语义化转化和融合处理还包括区域级Pair迁移矩阵,所述的区域级Pair迁移矩阵是基于隐含地图语义化分割处理而计算得到,具体实现为以移动轨迹数据语义解析模块中的Complete完整轨迹段集合为输入数据,提取其中的Pair点集,进而以隐含地图语义的区域级空间面积划分为基础实现相应Pair点集的富语义化转换过程,利用贝叶斯网络构建条件概率下的相应的Pair迁移概率矩阵块。其中pair是指从一个地点到另一个地点的对,包含响应的起点和终点;区域级的pair是指从一个区域开始,到另一个区域终止。
所述的S3中对原始轨迹数据进行富语义化转化和融合处理还包括多连续状态迁移概率模型,所述多连续状态迁移概率模型用于对分段轨迹序列转化语义数据。
其中语义知识库是指存储移动模式知识发现模块所发掘的移动行为模式集合、移动行为关联规则以及多连续状态迁移概率所输出的基于Markov概率过程的高阶状态移动迁移矩阵知识。
S4:构建混合在线预测模型:基于语义知识库,建立基于前向模式相似度匹配计算与高阶马尔可夫模型的混合在线预测模型;
其中前向模式匹配包括元素匹配和距离计算,用于实现在待预测Partial轨迹与所发掘的移动模式之间基于匹配方向与距离的近似度计算过程,同时通过近似度阈值比较输出移动路径预测结果。
其中Markov概率预测模型:用于实现待预测Partial轨迹与所统计的多连续状态迁移概率矩阵之间的以当前移动状态为基准、以高阶Markov阶数为步长的概率计算与预测过程,同时输出步长为1的移动路径预测结果。
本实施例中,优先执行前向模式匹配预测过程,最大化的利用Partial中的历史移动信息,以有效改善输出预测路径的精度,其中前向模式匹配过程通过Partial轨迹片段与所发掘的移动模式之间的同一元素匹配,及同一匹配元素前向距离计算逐个比较移动模式与Partial片段之间的相似程度,在匹配过程有解的情况下返回相应的后缀序列作为输出预测路径;在匹配过程无解的情况下,执行Markov概率推理模型,以当前移动状态为基准,前向递推相应阶次连续状态迁移概率分布,以概率最大值者作为所输出的步长为1的预测路径,通过递归循环过程,以所推导的Partial目的地位置信息作为终止条件,产生最终的输出预测路径。
在混合预测模型中,前向模式相似度匹配计算方法如下:
上式(1)中,degree表示历史移动模式与在线片段移动轨迹之间的相似度取值,cov为二者的模式匹配长度,dis表示在线查询轨迹的当前位置与历史模式之间的复合距离,sup为历史模式的支持度。式(2)中,ek为历史模式中与在线查询轨迹相匹配的所有元素,eend表示在线查询轨迹的当前位置。
对上述前向模式相似度匹配过程做简要阐述,如图2所示,圆形序列为在线查询移动轨迹片段,历史移动模式中分别存在3个可匹配模式,其中三角形表示匹配元素,正方形表示短期预测路径,其中候选模式1的值为2,为1。
在高阶马尔科夫计算模型中,步长为1的下一步潜在位置Rank计算公式为:
arg Max:score(loc)
其中score(loc)表示候选位置loc的Rank值,dorig表示位置loc与片段轨迹的起始位置的距离,ddest为位置loc与片段轨迹推理目的地的距离,pro(loc)为位置loc在所训练的高阶Markov模型中的迁移概率值。通过对m个候选位置loc的Rank值计算,取Rank值最大者为在线查询片段轨迹的下一步预测位置。
S5:预测路径输出:在混合在线预测模型中输入待预测轨迹片段进行预测,输出预测路径。
针对移动轨迹数据的稀疏性分布特征,以上述混合、互补式的预测模式实现对在线查询轨迹片段的未来移动路径预测的目的。对5000条测试轨迹片段分别在已知长度为10%、20%、30%、40%以及50%五种情况下进行预测路径结果比较验证,分别与1阶Markov模型方法与2阶Markov模型方法进行比较,本发明所构建的混合预测模型(Hybrid Moving Route Prediction,HMRP)具有显著优势,见图3、图4。
- 还没有人留言评论。精彩留言会获得点赞!