一种基于卷积神经网络的食物图像自动分类方法与流程
本发明属于一种基于卷积神经网络的食物图像自动分类方法,涉及卷积神经网络,网络爬虫技术及图像分类技术。
背景技术:
近年来,随着人们生活质量的提高,人们对美食的追求越来越多样化,但琳琅满目的菜品也让人目不暇接。此外,健康的饮食正逐渐成为人们追求生活品质的流行趋势之一。而这其中的关键在于食物信息的获取。如何通过简单的图片或照片获取菜品的信息,如热量,营养成分等是简化食物信息获取的重要手段之一,其中食物的自动识别是食物信息获取的重要一步。
食物图像多变复杂且种类繁多,传统的图像识别方法难以有效应对食物图像的自动分类,而卷积神经网络则可以在大数据的基础上较好的解决此问题。卷积神经网络(Convolutional Neural Networks,CNN)是深度学习算法的一种,近年来成为图像识别领域重要的处理分析工具。卷积神经网络算法的优点在于训练模型时不需要使用任何人工标注的特征,算法可以自动探索输入变量所隐含的特征,同时网络的权值共享特性,降低了模型的复杂度,减少了权值的数量。这些优点使原始图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建过程。此外,卷积神经网络的池化层对平移、倾斜具有不变性,提高了算法处理图像的鲁棒性。
由于对食物图像自动分类的研究较少,少量带有正确标签的食物图像数据容易直接获得,而能满足卷积神经网络训练的大量带有正确标签的图像数据却难以直接获取。人工收集此类数据的方法成本较大,而在互联网上则存在大量的带有弱标签的中国菜系图像。如果通过网络爬虫的手段爬取公开的食物图像,再通过计算机程序自动筛选标签正确的图像,就可以用较小的成本获取较大量的带有标签的中国菜系图像数据集,从而通过卷积神经网络训练出具有较高正确率的食物图像分类器。目前常见的网络图像数据源主要包含两种类型:
1、主流图像搜索引擎,如百度(Baidu),谷歌(Google)和必应(Bing)等;
2.、图像分享网站,如Picasa、Flickr和Instagram等。
当使用传统网络爬虫技术获取图像数据(比如食物图像)时,使用图像搜索引擎爬取的图像质量随显示的顺序大体呈现下降的趋势,使用图像分享网站爬取的图像质量尽管与图像搜索引擎相比与显示的顺序相关性较小,但随爬取的数量增加,质量也会有所下降。如果直接使用爬取的数据训练网络,就会出现网络分类器正确率先增后减的情况,最终得到的分类器难以满足需求。
技术实现要素:
为了克服现有技术中网络爬虫得到的食物图像数据存在数据噪声过大造成的训练分类器正确率低的情况的不足,本发明提出了一种有效避免数据噪声过大造成的训练分类器正确率低的情况、正确率较高的基于卷积神经网络的食物图像自动分类方法,卷积神经网络算法直接使用图像作为输入,避免了传统识别算法中复杂的特征提取和数据重建过程,训练得到的分类器的分类精度和鲁棒性都较高。
本发明为解决上述技术问题所采用的技术方案如下:
一种基于卷积神经网络的食物图像自动分类方法,所述方法包括以下步骤:
S1:利用网络爬虫从互联网爬取食物图像数据,人工筛选名称与图像内容相一致的食物图像,保存至数据集InitialData;
S2:使用InitialData数据集训练FoodCNN网络,得到一个初始识别食物子类的图像分类器,对输入的图像输出该图像属于每一子类的概率,按概率从大到小排列子类名单;
S3:利用网络爬虫开始对主流搜索引擎和图像分享网站中搜集大量目标分类的食物图像数据,同时定期利用FoodCNN网络筛选数据;
S4:利用FoodCNN网络对数据判断,将数据将分为CrawlData和NoisyData;
S5:使用扩充后的CrawlData数据更新FoodCNN网络。
S6:判断NoisyData数据量的合理性:统计NoisyData数据集占总数据集的比例,若未超过预设阈值则执行步骤S3,否则执行步骤S7;
S7:使用扩充后的数据训练FoodFinalCNN网络。
进一步:所述步骤S1包含以下内容:
S1.1:网络爬虫的搜索范围包括主流搜索引擎百度、谷歌、必应和图像分享网站Picasa、Flickr和Instagram;
S1.2:数据由人工筛选判定该数据所属分类,数据类型包括属于目标分类的数据集和不属于目标分类的数据集,属于目标分类的数据集为无噪声数据集InitialData,不属于目标分类的数据集为完全噪声数据集NoisyData,保留InitialData。
再进一步,所述步骤S3包括以下步骤:
S3.1:分别爬取主流搜索引擎百度、谷歌和必应的数据,分别爬取分享网站Picasa、Flickr、Instagram的数据;
S3.2:每完成爬取设定数量的图像,执行步骤S4。
更进一步,所述步骤S4包括以下步骤:
S4.1:使用FoodCNN网络对爬虫获取到的数据进行判决;
S4.2:如果数据标签与FoodCNN判定的前五个可能的标签中一个相符,则认为该数据有很大可能属于目标分类,判定该数据属于CrawlData,保存该数据至CrawlData数据集;
S4.3:如果数据标签与FoodCNN判定的前五个可能的标签,没有一个相符,则认为该数据标签与其真实分类不符,判定该数据属于NoisyData,保存该数据至NoisyData数据集;
S4.4:执行步骤S5。
具体来说,本发明所述的方法具有如下的有益效果:
(1)本发明所述的方法通过卷积神经网络对定期对爬虫获取的数据进行判断,适时终止爬虫,提高了爬虫的工作效率,降低了在数据爬取上消耗的时间。
(2)本发明所述的方法利用爬虫获取到的数据训练卷积神经网络,能够不断增强卷积神经网络的鲁棒性,使最终的分类器有一个较优的性能。
(3)本发明所述的方法将卷积神经网络与网络爬虫相结合,实现双向互惠,形成一个不断优化的可持续系统,减少了整个项目投入的人力成本。
附图说明
图1为爬取少量数据训练初始分类器的流程图;
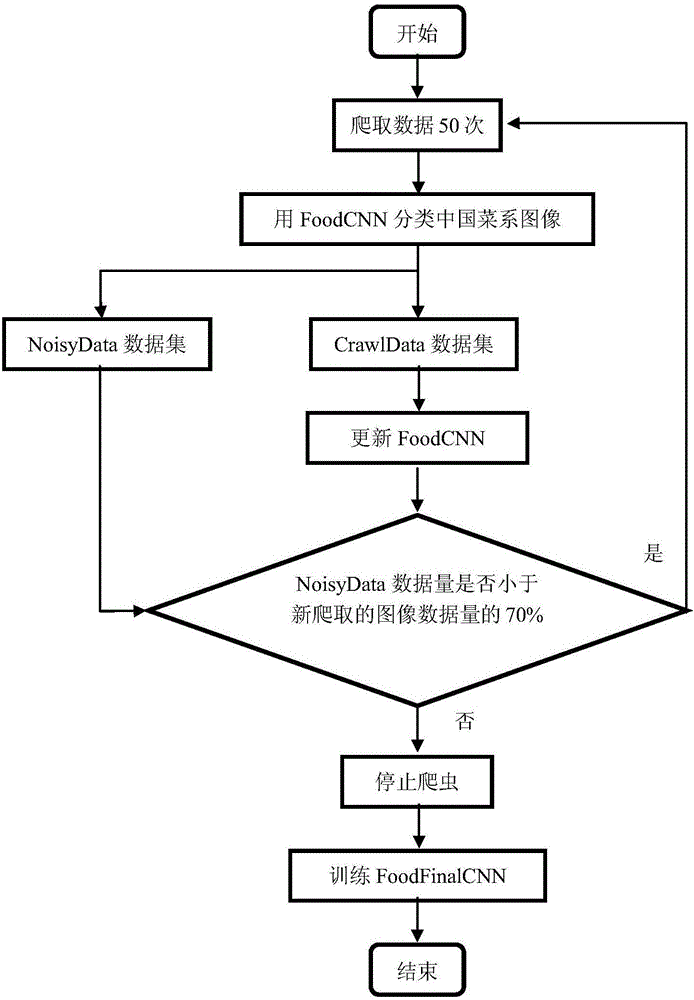
图2为基于爬虫与卷积神经网络相结合的分类器模型更新流程图;
图3为分类器分类效果随迭代次数增加的变化曲线。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1~图3,一种基于卷积神经网络的食物图像分类方法,包括以下步骤:
步骤1:随机获取初始图像数据
利用网络爬虫从主流图像搜索引擎百度、谷歌和图像分享网站Flickr、Instagram中随机获取少量的目标分类的数据,经过人工筛选,判定该数据是否属于目标分类,将属于目标分类的数据集定义为InitialData并作为初始图像训练数据;
步骤2:训练初始卷积神经网络
使用InitialData的数据训练FoodCNN网络,得到一个初始的图像分类器,对输入的图像输出该图像属于每一类的概率,按概率从大到小排列各类别;
步骤3:爬取扩充数据
再次利用爬虫开始对谷歌、百度、必应等主流搜索引擎和Flickr、Instagram等图像分享网站中搜集大量目标分类的图像数据,与此同时,定期执行步骤4;
步骤4:利用FoodCNN网络对数据分类
定期使用FoodCNN网络对爬虫此时获取到的数据进行判决;
如果FoodCNN判定该数据有很大可能属于目标分类,则保存该数据于CrawlData数据集;
如果FoodCNN判定该数据有很大可能不属于目标分类,保存此数据至NoisyData数据集;
执行步骤5;
步骤5:利用CrawlData数据集更新FoodCNN网络
使用CrawlData数据更新FoodCNN网络权重参数,得到新的的分类器;
步骤6:判断NoisyData数据量合理性
若NoisyData的数据量小于新爬取的数据总量的70%,则执行步骤3;
若NoisyData的数据量不小于新爬取的数据总量的70%,则执行步骤7;
步骤7:训练最终分类器
停止爬虫;
使用扩充后的CrawlData数据集训练最终分类器FoodFinalCNN网络。
本发明对互联网公开的图像数据进行数据爬取。以本实例研究对中国菜系的图像分类器训练为例,介绍本发明的具体流程:
步骤1:随机获取初始数据
参照图1,利用网络爬虫从主流搜索引擎百度、谷歌和图像分享网站Flickr、Instagram中对每一种中国菜系图像各爬取100张目标分类的数据,经过人工筛选,将每张属于中国菜系某一类的图像数据集归到InitialData数据集,InitialData数据集由特定种类中国菜系图像的子数据集组成;
步骤2:训练初始卷积神经网络
使用InitialData的数据训练FoodCNN网络,得到一个能够粗略识别中国菜系种类的图像分类器,对输入的图像输出该图像属于每一种类的概率,按概率从大到小排列各类别;
步骤3:爬取数据
参照图2,利用爬虫开始对谷歌、百度、必应等主流搜索引擎和Flickr、Instagram等图像分享网站中搜集大量属于指定中国菜系的图像数据,与此同时,在每个网站各爬取50张图像后执行步骤4;
步骤4:利用FoodCNN网络对数据判断
使用FoodCNN网络对爬虫此时获取到的数据进行判决,若标签与FoodCNN分类前五的结果中有相同,则认为数据标签有很大可能是属于该目标数据,将数据添加至CrawlData数据集;
如果标签与FoodCNN分类前五的结果中没有相同,则判定该数据有很大可能不属于该目标数据,保存数据至NoisyData数据集;
执行步骤5;
步骤5:更新FoodCNN
使用CrawlData数据集更新FoodCNN网络参数,得到识别准确率更高的中国菜系图像分类器;
步骤6:判断NoisyData数据量合理性
对此时获取到的数据进行判决,
若NoisyData数据集的数据量小于新爬取的图像数据总量的70%,则执行步骤3;
若NoisyData数据集的数据量不小于新爬取的图像数据总量的70%,则执行步骤7;
步骤7:最终分类器训练
停止爬虫;
使用此时CrawlData数据集的数据训练最终分类器FoodFinalCNN。FoodFinalCNN分类器的精度关于爬取的图像总量变化如图3;
如上所述为本发明在中国菜系图像子类分类的实施例介绍,本发明通过对图像分类器的迭代更新和网络爬取数据的自动筛选,由初始的少量数据量扩展成大量数据量,同时明显提高了图像分类器的分类精度,减少了大量人力和财力。对发明而言仅仅是说明性的,而非限制性的。本专业技术人员理解,在发明权利要求所限定的精神和范围内可对其进行许多改变,修改,甚至等效,但都将落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!