空气污染物浓度预报方法及系统与流程
本发明涉及环境工程技术领域,尤其涉及一种空气污染物浓度预报方法及系统。
背景技术:
近年来,随着国家经济的高速发展、城市化进程的加快和工业规模的扩大,空气污染问题日益严重,引起了全球范围内的广泛关注。以细颗粒物PM2.5为首要污染物的空气污染现象日益突出,对公众健康构成较大威胁。因此,有必要开展空气质量预报,更好地反映空气污染的变化趋势,并提供迅速和全面的环境质量信息,为环境管理和避免严重的空气污染事故提供决策支持。
目前,空气质量预报通常采用数值预报模型和统计学预报模型进行空气质量预报。数值预报方法采用采用大气动力学理论来模拟污染物排放、转移、扩散和消散的过程,运用基于模型驱动的方法来对空气质量进行建模和预报。然而,由于不可靠的污染物排放数据,复杂的下垫面(大气下层直接接触的地球表面)状况和不完整的理论基础,模拟结果精度较低。
统计学预报方法则以数据驱动方式使用统计建模手段来预报空气质量,如多元线性回归(Multi-variable Linear Regression,简称MLR)模型和自回归移动平均(Auto Regression Moving Average,简称ARMA)模型都常用于空气质量预报。然而,这些方法因不能模拟空气污染物浓度中的非线性模式而精度较低,在极端空气污染物浓度预报上的精度尤其偏低。
技术实现要素:
本发明的目的在于克服现有技术中存在的上述不足,而提供一种空气污染物浓度预报方法和系统,以解决空气污染物浓度预报精度较低,在极端空气污染物浓度预报上的精度尤其偏低的问题。
第一方面,本发明提供了一种空气污染物浓度预报方法,包括:将输入层的节点个数的多个待选值、栈式自编码器的层数的多个待选值、栈式自编码器的每层的节点个数的多个待选值进行组合确定出多个待定模型,设置每个待定模型的输出层的节点个数为m;其中,输入层的节点个数是输出层的节点个数m的n倍,n为时间步参数;根据时间步参数n的多个待选值和指定的预报时延r,获取来自m个监测站点的空气污染物的多组历史浓度数据,从所述历史浓度数据中提取出训练数据集和验证数据集;使用所述训练数据集对各待定模型进行训练直至待定模型收敛,记录训练完成的各待定模型相应的模型权重矩阵和模型偏置向量;将所述验证数据集中用于输入的数据输入至训练完成的各待定模型,计算各待定模型的输出结果与所述验证数据集中用于验证的数据的综合误差,将最小的综合误差对应的待定模型确定为预报模型,其中,所述预报模型的时间步参数的值为nr;将来自m个监测站点、时间步参数为nr的空气污染物浓度的观测数据组成预报数据集,将所述预报数据集输入至所述预报模型,将所述预报模型的输出结果作为预报时延为r的预报结果。
上述方法还可以具有以下特点:所述使用所述训练数据集对各个待定模型进行训练直至待定模型收敛包括:使用所述训练数据集采用逐层训练法对栈式自编码器的权重矩阵和偏置向量进行训练;将栈式自编码器的最后一层的输出向量作为输出层的输入,并采用反向传播算法对栈式自编码器和输出层的权重矩阵和偏置向量自后向前进行调整直至待定模型收敛。
上述方法还可以具有以下特点:采用逐层训练法对栈式自编码器的权重矩阵和偏置向量进行训练时,采用最小化具有稀疏限制条件的重构误差来调整每层自编码器的权重矩阵W1和W2及偏置向量b和c,所述具有稀疏限制条件的重构误差如下式:
其中,yj=f(W1x+bj),x={x(1),...,x(i),...,x(N)},z(i)=g(W2y+ci),i=1,...,N,j=1,...,HD,λ是正则化项的权重,μ是稀疏项的权重,N是输入的批训练样本个数,HD是当前层自编码器的节点个数,||W1||2是W1的L2范数,||W2||2是W2的L2范数,ρ是稀疏参数,x(i)为当前层自编码器的第i个输入向量,yj为编码后向量的第j个元素,z(i)为当前层自编码器第i个输入向量对应的的解码向量。
上述方法还可以具有以下特点:采用逐层训练法对栈式自编码器的权重矩阵和偏置向量进行训练时,为每层自编码器设置单独的迭代次数和学习速率,并在训练过程中不断减小学习速率;采用反向传播算法对栈式自编码器和输出层的权重矩阵和偏置向量自后向前进行调整时,在调整过程中不断减小学习速率。
上述方法还可以具有以下特点:所述各待定模型的输出结果与所述验证数据集中用于验证的数据的综合误差包括均方根误差、平均绝对误差及平均绝对百分误差。
上述方法还可以具有以下特点:所述获取来自m个监测站点的空气污染物的多组历史浓度数据还包括:根据空气污染物的浓度数据的物理含义,采用箱线图剔除历史浓度数据中的异常值;和/或使用线性插值方法对历史浓度数据中的缺失值进行填补;和/或采用最大最小归一化方法,对历史浓度数据进行归一化处理。
上述方法还可以具有以下特点:所述栈式自编码器中每层自码器的编码器如下式:解码器如下式:
上述方法还可以具有以下特点:每个所述待定模型的输出层的激活函数为
上述方法还可以具有以下特点:所述空气污染物为细颗粒物、可吸入颗粒、二氧化硫、二氧化氮、一氧化碳及臭氧中的任一种。
本发明提供的空气污染物浓度预报方法基于STDL模型进行空气污染物浓度的预报,具体地,采用栈式自编码(Stacked Auto-Encoder,简称SAE)模型来对多个监测站点的空气污染物浓度数据进行建模,从而可以提取空气污染物浓度数据中的深层次特征及数据中隐含的时空相关性,并同步得到多监测站点的预报数据,预报精度高;鉴于STDL模型为非线性模型,因而也可以改善在极端空气污染物浓度预报上的精度。
第二方面,本发明提供了一种空气污染物浓度预报系统,包括:待定模型确定单元,用于将输入层的节点个数的多个待选值、栈式自编码器的层数的多个待选值、栈式自编码器的每层的节点个数的多个待选值进行组合确定出多个待定模型,设置每个待定模型的输出层的节点个数为m;其中,输入层的节点个数是输出层的节点个数m的n倍,n为时间步参数;历史浓度数据处理单元,用于根据时间步参数n的多个待选值和指定的预报时延r,获取来自m个监测站点的空气污染物的多组历史浓度数据,从所述历史浓度数据中提取出训练数据集和验证数据集;待定模型训练单元,用于使用所述训练数据集对各待定模型进行训练直至待定模型收敛,记录训练完成的各待定模型相应的模型权重矩阵和模型偏置向量;预报模型确定单元,用于将所述验证数据集中用于输入的数据输入至训练完成的各待定模型,计算各待定模型的输出结果与所述验证数据集中用于验证的数据的综合误差,将最小的综合误差对应的待定模型确定为预报模型,其中,所述预报模型的时间步参数的值为nr;空气污染物浓度预报单元,用于将来自m个监测站点、时间步参数为nr的空气污染物浓度的观测数据组成预报数据集,将所述预报数据集输入至所述预报模型,将所述预报模型的输出结果作为预报时延为r的预报结果。
本发明提供的空气污染物浓度预报系统基于STDL模型进行空气污染物浓度的预报,可以提取空气污染物浓度数据中隐含的时空相关性,并同步得到多监测站点的预报数据,预报精度高;也可以改善在极端空气污染物浓度预报上的精度。
附图说明
构成本发明的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1是一种空气污染物浓度预报方法的流程图;
图2为一种空气污染物浓度预报系统的组成图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互任意组合。
图1是空气污染物浓度预报方法的流程图。如图1所示,本发明提供的空气污染物浓度预报方法,包括:
步骤S10:将输入层的节点个数的多个待选值、栈式自编码器的层数的多个待选值、栈式自编码器的每层的节点个数的多个待选值进行组合确定出多个待定模型,设置每个待定模型的输出层的节点个数为m;其中,输入层的节点个数是输出层的节点个数m的n倍,n为时间步参数,m和n均为正整数;
步骤S20:根据时间步参数n的多个待选值和指定的预报时延r,获取来自m个监测站点的空气污染物的多组历史浓度数据,从所述历史浓度数据中提取出训练数据集和验证数据集;
步骤S30:使用所述训练数据集对各待定模型进行训练直至待定模型收敛,记录训练完成的各待定模型相应的模型权重矩阵和模型偏置向量;
步骤S40:将所述验证数据集中用于输入的数据输入至训练完成的各待定模型,计算各待定模型的输出结果与所述验证数据集中用于验证的数据的综合误差,将最小的综合误差对应的待定模型确定为预报模型,其中,所述预报模型的时间步参数的值为nr;
步骤S50:将来自m个监测站点、时间步参数为nr的空气污染物浓度的观测数据组成预报数据集,将所述预报数据集输入至所述预报模型,将所述预报模型的输出结果作为预报时延为r的预报结果。
本发明采用时空深度学习(Spatio-Temporal Deep Learning,简称STDL)模型来构建空气污染物浓度预报模型,该STDL模型具有依次连接的输入层、栈式自编码器和输出层;并采用网格搜索(Grid Search,简称GD)方法对该时空深度学习模型的结构参数进行优化。具体地,将输入层的节点个数的多个待选值、栈式自编码器的层数的多个待选值、栈式自编码器的每层的节点个数的多个待选值进行组合,从而确定出多个待定模型,进而从这多个待定模型中找出综合误差最小的待选模型为预报模型。
需要说明的是,与通常可以缩短所需要的优化搜索时间的启发式搜索或者随机搜索方法相比,尽管启发式搜索和随机搜索的效率更高,但是优化效果较差。网格搜索方法尽管所需的时间较长,但其对多组待选参数进行排列组合的方法,近似于穷举,因此可以更大概率地找到最优解,也就是最优的STDL模型的结构参数组合。
具体地,根据空气污染物监测站点的数目m,设置每个待定模型的输出层的节点个数为m,则输入层的节点个数是输出层的节点个数m的n倍,其中,n为时间步参数,m和n均为正整数。
进一步地,根据时间步参数n的多个待选值和指定的预报时延r,获取来自m个监测站点的空气污染物的多组历史浓度数据。每组历史浓度数据具有不同的时间步参数n和相同的预报时延r。每一组历史浓度数据中的来自单个站点的每个样本中包含用于作为输入的n个数据点和用于作为输出的具有预报时延r的1个数据点;每一组历史浓度数据中来自m个监测站点的单个样本集具有相同的数据点数p,具体为:p=m×(n+1)。需要说明的是,每一组历史浓度数据中包括多个具有p个数据点的样本集,用于后续采用批处理的方式对每个待定模型进行批处理训练。
优选地,空气污染物浓度数据的物理含义为空气污染物小时平均浓度,每一组历史浓度数据中的来自单个站点的每个样本中包含的用于作为输入的n个数据点中,相邻数据点之间的时间间隔为1小时;用于作为输出的那一个数据点距离时序上最近的数据点的时间间隔为r小时。
优选地,空气污染物浓度数据的物理含义为空气污染物小时平均浓度,每一组历史浓度数据中的来自单个站点的每个样本中包含的用于作为输入的n个数据点中,相邻数据点之间的时间间隔为r小时;用于作为输出的那一个数据点距离时序上最近的数据点的时间间隔为r小时。
进一步地,将所述历史浓度数据划分为训练数据集和验证数据集。其中,训练数据集和验证数据集均包括多个具有p个数据点的样本集。
在确定了对应于该多个待定模型的训练数据集和验证数据集之后,使用所述训练数据集对各待定模型进行训练直至待定模型收敛,并记录训练完成的各待定模型相应的模型权重矩阵和模型偏置向量。
在确定了该多个待定模型的模型权重矩阵和模型偏置向量之后,将所述验证数据集中用于输入的数据输入至训练完成的各待定模型,计算各待定模型的输出结果与所述验证数据集中用于验证的数据的综合误差,将最小的综合误差对应的待定模型确定为预报模型。
具体地,所述各待定模型的输出结果与所述验证数据集中用于验证的数据的综合误差可以包括均方根误差(Root Mean Square Error,简称RMSE)、平均绝对误差(Mean Absolute Error,简称MAE)和平均绝对百分误差(Mean Absolute Percentage Error,简称MAPE)。其中,RMSE、MAE和MAPE分别具有本技术领域内的通常含义,这里不再详细列出其分别对应的计算公式。
需要说明的是,上述的综合误差可以是有量纲的RMSE和MAE的加权平均值,也可以是无量纲的MAPE的值。如果需要优选出绝对误差小的预报模型,则需要选择有量纲的误差指标;如果需要优选出相对误差小的预报模型,则需要选择无量纲的指标。在物理含义不冲突的情况下,三者可以相互任意组合。
在确定了预报模型之后,将来自m个监测站点、时间步参数为nr的空气污染物浓度的观测数据组成预报数据集,将所述预报数据集输入至所述预报模型,将所述预报模型的输出结果作为预报时延为r的预报结果,即同步得到m个监测站点预报时延为r的空气污染物浓度数据。
本发明提供的空气污染物浓度预报方法基于STDL模型进行空气污染物浓度的预报,具体地,采用栈式自编码(Stacked Auto-Encoder,简称SAE)模型来对多个监测站点的空气污染物浓度数据进行建模,从而可以提取空气污染物浓度数据中的深层次特征及数据中隐含的时空相关性,并同步得到多监测站点的预报数据,预报精度高;鉴于STDL模型为非线性模型,因而也可以改善在极端空气污染物浓度预报上的精度。
具体地,所述使用所述训练数据集对各个待定模型进行训练直至待定模型收敛包括:使用所述训练数据集采用逐层训练法对栈式自编码器的权重矩阵和偏置向量进行训练;将栈式自编码器的最后一层的输出向量作为输出层的输入向量,并采用反向传播算法对栈式自编码器和输出层的权重矩阵和偏置向量自后向前进行调整直至待定模型收敛。
鉴于传统的反向传播算法在训练时空深度学习模型时容易陷入局部极值,采用Hinton提出的逐层训练法(Greedy Layer-wise Training)对栈式自编码器的权重矩阵和偏置向量进行预训练,通过自下而上逐层训练,可以得到收敛、且全局最优的栈式自编码器。
进一步地,将收敛的栈式自编码器的最后一层的输出向量作为输出层的输入,并采用反向传播算法对栈式自编码器和输出层的权重矩阵和偏置向量自后向前进行调整直至待定模型收敛。
在每个待定模型训练时,先采用逐层训练法自下而上对栈式自编码器进行预训练直至收敛,再结合收敛的栈式自编码器,通过反向传播算法自后向前对整个深度学习深度网络进行微调直至待定模型收敛。这种预训练和微调相结合的训练策略训练精度高,训练速度快。
具体地,采用逐层训练法对栈式自编码器的权重矩阵和偏置向量进行训练时,采用最小化具有稀疏限制条件的重构误差来调整每层自编码器的权重矩阵W1和W2及偏置向量b和c,所述具有稀疏限制条件的重构误差如下式:
其中,θ指代上述等式右边式子中包含的所有未知参数,即(W1,W2,b,c),也即J(θ)=J(W1,W2,b,c);为x与z的普通最小二乘误差;(W1||2+||W2||2)为正则化项,||W1||2是W1的L2范数,||W2||2是W2的L2范数,λ是正则化项的权重;是稀疏项,μ是稀疏项的权重,j=1,...,HD,HD是当前层自编码器的节点个数;是对比散度(Kullback–Leibler Divergence),用于增强编码过程的稀疏限制,其定义如下式:其中,ρ是稀疏参数,一般为0或者接近于0;是自编码器的节点j对应于输入向量x的平均激励,其定义如下式:其中,yj为编码后向量的第j个元素,也即编码后第j个节点的值,yj=f(W1x+bj);x为当前层自编码器的输入向量,x={x(1),...,x(i),...x(N)},x(i)∈Rd,x(i)为当前层自编码器的第i个输入向量;另外,z(i)为当前层自编码器第i个输入向量对应的解码向量,z(i)=g(W2y+ci);i=1,...,N,N是输入的批训练样本个数;y为当前层自编码器的编码向量。
本发明提供的空气污染物浓度预报方法采用Ranzato提出的稀疏自编码器来改进常规自编码器,即采用最小化具有稀疏限制条件的重构误差来调整每层自编码器的权重矩阵W1和W2及偏置向量b和c,以避免“简单复制数据”或者“最大化交互信息”,最大化地提取出数据中有代表性的特征。
鉴于在深度神经网络建模时,训练过程(包括预训练和微调过程)中的学习速率过大会导致重构误差震荡而不收敛,学习速率太小会是网络收敛过慢,权值难以趋于稳定,采用逐层训练法对栈式自编码器的权重矩阵和偏置向量进行训练时,训练过程中不断减小学习速率;采用反向传播算法对栈式自编码器和输出层的权重矩阵和偏置向量自后向前进行调整时,在调整过程中不断减小学习速率。
在预训练过程中,每层自学习编码器可以设置单独的迭代次数和学习速率,当重构误差满足收敛条件时,即可停止该层的预训练,从而提高训练速度。
在获取来自m个监测站点的空气污染物的多组历史浓度数据时,需要视数据质量,选择性地采用以下的预处理方法:
根据空气污染物的浓度数据的物理含义,采用箱线图剔除历史浓度数据中的异常值;使用线性插值方法对历史浓度数据中的缺失值进行填补;采用最大最小归一化方法,对历史浓度数据进行归一化处理。
归一化处理可以加快模型训练速度。具体地,最大最小归一化方法通过遍历所有监测站点空气污染物浓度数据,查找其中的最大值a和最小值b,并采用下式对原始空气质量X进行归一化处理:
优选地,本发明采用的时空深度学习模型中,所述栈式自编码器中每层自码器的编码器如下式:解码器如下式:每个所述待定模型的输出层的激活函数为
具体地,每个所述待定模型的输出层为逻辑回归层,其激活函数为逻辑回归函数。逻辑回归函数是实现简单且能够较好对数据中的非线性特征进行建模。另外,所述待定模型的输出层也可以采用SVR回归模型,以实现更好的非线性建模,但实现复杂,消耗的计算资源多。
可选地,本发明提供的空气污染物浓度预报方法中,所述空气污染物为细颗粒物、可吸入颗粒、二氧化硫、二氧化氮、一氧化碳及臭氧中的任一种。也即,本发明提供的空气污染物浓度预报方法可以分别对细颗粒物(PM2.5)、可吸入颗粒(PM10)、二氧化硫(SO2)、二氧化氮(NO2)、一氧化碳(CO)、臭氧(O3)等6种污染物的浓度进行预报。
本发明采用Hinton提出的逐层训练法对栈式自编码器的权重矩阵和偏置向量进行预训练,在预训练结束之后,采用反向传播算法自后向前来微调整个网络的参数。模型训练的具体流程如下:
(a)设定隐含层层数及每层节点数、预训练迭代次数、预训练学习速率、微调迭代次数、微调学习速率、批处理大小。
(b)网络预训练:初始化正则化项和稀疏项的权重,随机初始化网络各层的权重矩阵和偏置向量;使用训练集训练第一层;使用逐层预训练的方式来训练后续训练隐含层。在预训练过程中,每层可设置单独的迭代次数和学习速率,当重构误差满足收敛条件时,即可停止该层的预训练。
(c)网络微调:使用栈式自编码器最后一个隐含层的输出作为逻辑回归层的输入;随机初始化逻辑回归层的权重矩阵和偏置向量;使用反向传播算法自后向前来微调整个网络的参数。在网络微调过程中,当模型预报误差收敛时,即可停止迭代。
另外,在采用优化后的预测模型进行空气污染浓度预测后,可以将预测结果与后续实际测量的空气污染浓度数据进行比较,并若预测精度不能满足预定要求,则可以更换STDL模型中的各结构参数,按照前述最优化预测模型的方法,另外寻找一个优选的预测模型。
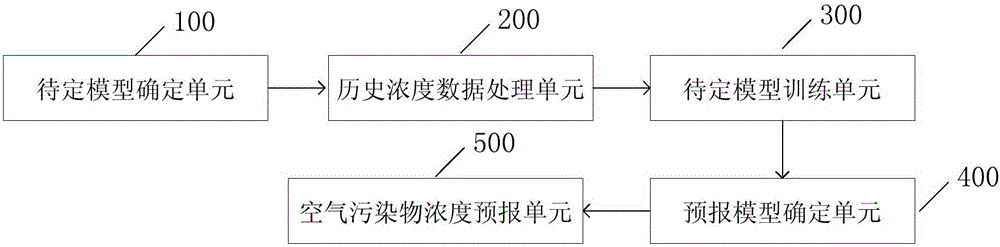
图2为空气污染物浓度预报系统的组成图,空气污染物浓度预报系统是空气污染物浓度预报方法对应的虚拟装置。如图2所示,本发明提供的空气污染物浓度预报系统,包括:待定模型确定单元100,用于将输入层的节点个数的多个待选值、栈式自编码器的层数的多个待选值、栈式自编码器的每层的节点个数的多个待选值进行组合确定出多个待定模型,设置每个待定模型的输出层的节点个数为m;其中,输入层的节点个数是输出层的节点个数m的n倍,n为时间步参数;历史浓度数据处理单元200,用于根据时间步参数n的多个待选值和指定的预报时延r,获取来自m个监测站点的空气污染物的多组历史浓度数据,从所述历史浓度数据中提取出训练数据集和验证数据集;待定模型训练单元300,用于使用所述训练数据集对各待定模型进行训练直至待定模型收敛,记录训练完成的各待定模型相应的模型权重矩阵和模型偏置向量;预报模型确定单元400,用于将所述验证数据集中用于输入的数据输入至训练完成的各待定模型,计算各待定模型的输出结果与所述验证数据集中用于验证的数据的综合误差,将最小的综合误差对应的待定模型确定为预报模型,其中,所述预报模型的时间步参数的值为nr;空气污染物浓度预报单元500,用于将来自m个监测站点、时间步参数为nr的空气污染物浓度的观测数据组成预报数据集,将所述预报数据集输入至所述预报模型,将所述预报模型的输出结果作为预报时延为r的预报结果。
本发明提供的空气污染物浓度预报系统基于STDL模型进行空气污染物浓度的预报,可以提取空气污染物浓度数据中隐含的时空相关性,并同步得到多监测站点的预报数据,预报精度高;也可以改善在极端空气污染物浓度预报上的精度。
实施例:
采用北京市市区12个空气质量监测站2014年1月1日至2016年5月28日逐小时PM2.5平均浓度数据,利用本发明提供的空气污染物浓度预报方法进行PM2.5小时平均浓度数据预报。也即,预报时延r为一小时;每个历史浓度样本中,相邻时序的数据之间的时间间隔均为一小时。
经过预处理之后,历史数据集中包含20196条PM2.5小时平均浓度记录。通过随机挑选60%的数据作为训练集,20%的数据作为验证集,余下20%数据作为测试集。
在待定模型训练和待定模型参数优化过程中,各参数的待选集合如表1所示。
表1空气质量预报待定模型参数
经过网格搜索优化,时间步参数为8且栈式自编码器的层数为3且每层自编码器具有300个节点时,PM2.5小时平均浓度的预报效果最好。针对某一站点,其PM2.5小时平均浓度预报值和真实值比较接近,具体的预报精度指标分别为:MAE=8.44μg/m3,RMSE=14μg/m3,MAPE=18.6%。
进一步地,对本发明提供的空气污染物浓度预报方法使用的STDL模型与时空人工神经网络(Spatio-Temporal Artificial Neural Network,简称STANN)模型、支持向量机模型(Support Vector Machine,简称SVR)和ARMA模型分别进行对比试验。这些模型使用相同的训练集和测试集,但是模型输入略有不同。STANN模型使用相同的数据,能够对多个站点的空气质量进行同步预报。但STANN模型不使用逐层预训练方法,而是使用普通神经网络的训练方式,也即反向传播算法。对于SVR模型和ARMA模型,它们是时间序列模型,因而需要针对每个站点分别进行单独的建模和预报。
上述4种方法的预报精度如表2所示,从表2中可以看出,本发明提供的空气污染物浓度预报方法使用的时空深度学习模型的预报精度是最高的,MAPE提高了5.12%以上。STANN模型的预报精度比其他两种时间序列模型(ARMA模型和SVR模型)的预报精度高,说明了对空气质量数据建模时考虑空间相关性是十分有效的。
表2空气质量预报模型精度对比
上面描述的内容可以单独地或者以各种方式组合起来实施,而这些变型方式都在本发明的保护范围之内。
本领域普通技术人员可以理解上述方法中的全部或部分步骤可通过程序来指令相关硬件完成,所述程序可以存储于计算机可读存储介质中,如只读存储器、磁盘或光盘等。可选地,上述实施例的全部或部分步骤也可以使用一个或多个集成电路来实现,相应地,上述实施例中的各模块/单元可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。本发明不限制于任何特定形式的硬件和软件的结合。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括……”限定的要素,并不排除在包括所述要素的物品或者设备中还存在另外的相同要素。
以上实施例仅用以说明本发明的技术方案而非限制,仅仅参照较佳实施例对本发明进行了详细说明。本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!