实时计算方法及装置与流程
本申请涉及计算机应用领域,尤其涉及一种基于jstorm的实时计算方法及装置。
背景技术:
在传统的基于jstorm的实时计算系统的架构中,通常包括实时数据传输平台,和基于jstorm架构的用于流式计算的计算系统。计算系统可以订阅实时数据传输平台中的数据,进行实时的流式数据计算。
然而,传统的基于基于jstorm的实时计算系统,在整体链路上通常为单点模型,一旦计算系统所在的计算节点出现故障,就会导致数据计算中断,造成业务上的整体不可用。
技术实现要素:
本申请提出一种基于jstorm的实时计算方法,应用于实时计算系统中的仲裁子系统,所述实时计算系统还包括基于jstorm架构的若干计算子系统;所述若干计算子系统采用分布式部署;包括:
基于各计算子系统定时发送的心跳消息探测所述若干计算子系统中状态正常的计算子系统;
基于预设的任务分配策略为探测到的各状态正常的计算子系统分别分配计算任务,以由各计算子系统从待计算数据集合中提取对应于所述计算任务的数据子集进行数据计算;
当探测到任一状态正常的计算子系统发生状态异常时,基于所述预设的任务分配策略针对当前状态正常的计算子系统重新分配计算任务。
本申请还提出一种基于jstorm的实时计算方法,应用于实时计算系统中的任一计算子系统,所述实时计算系统包括仲裁子系统,以及基于jstorm架构的若干计算子系统;所述若干计算子系统采用分布式部署;包括:
定时向仲裁子系统发送心跳消息,以由所述仲裁子系统基于所述心跳消息探测所述若干计算子系统中状态正常的计算子系统,并为状态正常的计算子系统分配计算任务;
获取所述仲裁子系统分配的计算任务,基于预设的数据提取策略从待计算数据集合中提取对应于所述计算任务的数据子集进行数据计算;
判断仲裁子系统分配的计算任务是否发生更新;
当所述仲裁子系统分配的计算任务发生更新时,基于所述预设的数据提取策略从预设的待计算数据集合中重新提取对应于更新后的计算任务的数据子集进行数据计算。
本申请还提出一种基于jstorm的实时计算装置,应用于实时计算系统中的仲裁子系统,所述实时计算系统还包括基于jstorm架构的若干计算子系统;所述若干计算子系统采用分布式部署;包括:
探测模块,基于各计算子系统定时发送的心跳消息探测所述若干计算子系统中状态正常的计算子系统;
分配模块,基于预设的任务分配策略为探测到的各状态正常的计算子系统分别分配计算任务,以由各计算子系统从待计算数据集合中提取对应于所述计算任务的数据子集进行数据计算;
所述分配模块,在探测到任一状态正常的计算子系统发生状态异常时,基于所述预设的任务分配策略针对当前状态正常的计算子系统重新分配计算任务。
本申请还提出一种基于jstorm的实时计算装置,应用于实时计算系统中的任一计算子系统,所述实时计算系统包括仲裁子系统,以及基于jstorm架构的若干计算子系统;所述若干计算子系统采用分布式部署;包括:
发送模块,定时向仲裁子系统发送心跳消息,以由所述仲裁子系统基于所述心跳消息探测所述若干计算子系统中状态正常的计算子系统,并为状态正常的计算子系统分配计算任务;
提取模块,获取所述仲裁子系统分配的计算任务,基于预设的数据提取策略从待计算数据集合中提取对应于所述计算任务的数据子集进行数据计算;
判断模块,判断仲裁子系统分配的计算任务是否发生更新;
所述提取模块,在所述仲裁子系统分配的计算任务发生更新时,基于所述预设的数据提取策略从预设的待计算数据集合中重新提取对应于更新后的计算任务的数据子集进行数据计算。
本申请还提出一种基于jstorm的实时计算系统,所述实时计算系统包括仲裁子系统,以及基于jstorm架构的若干计算子系统;所述若干计算子系统采用分布式部署;其中:
仲裁子系统,基于各计算子系统定时发送的心跳消息探测所述若干计算子系统中状态正常的计算子系统;基于预设的任务分配策略为探测到的各状态正常的计算子系统分别分配计算任务;当探测到任一状态正常的计算子系统发生状态异常时,基于所述预设的任务分配策略针对当前状态正常的计算子系统重新分配计算任务;
若干计算子系统,定时向仲裁子系统发送心跳消息;获取所述仲裁子系统分配的计算任务,基于预设的数据提取策略从待计算数据集合中提取对应于所述计算任务的数据子集进行数据计算;判断仲裁子系统分配的计算任务是否发生更新;当所述仲裁子系统分配的计算任务发生更新时,基于所述预设的数据提取策略从预设的待计算数据集合中重新提取对应于更新后的计算任务的数据子集进行数据计算。
本申请中,通过对传统的基于jstorm的实时计算系统的架构进行改进,提出一种新的基于jstorm的实时计算系统的架构,在该新的架构中包括仲裁子系统,以及基于jstorm架构的若干计算子系统;所述若干计算子系统采用分布式部署;仲裁子系统可以基于各计算子系统定时发送的心跳消息探测所述若干计算子系统中状态正常的计算子系统,并针对探测到的状态正常的计算子系统动态的分配计算任务,各状态正常的计算子系统可以基于仲裁子系统分配的计算任务,从待计算数据集合中提取对应于该计算任务的数据子集进行数据计算;
由于各计算子系统采用了分布式部署,并且每一状态正常的计算子系统,仅负责针对待计算数据集合中的部分数据进行计算,因而任一状态正常的计算子系统所在计算节点发生故障,仲裁子系统在将发生故障的计算子系统所承载的计算数据,重新分配给其它状态正常的计算子系统时,仅会针对部分数据的计算造成影响,因而并不会造成业务上的整体不可用,从而提升了实时计算系统的稳定性。
附图说明
图1是本申请一实施例示出的相关技术中基于jstorm的实时计算系统的架构图;
图2是本申请一实施例示出的一种基于jstorm的实时计算方法的处理流程图;
图3是本申请一实施例示出的改进后的基于jstorm的实时计算系统的架构图;
图4是本申请一实施例示出的一种基于jstorm的实时计算装置的逻辑框图;
图5是本申请一实施例提供的承载所述一种基于jstorm的实时计算装置的仲裁子系统的硬件结构图;
图6是本申请一实施例示出的另一种基于jstorm的实时计算装置的逻辑框图;
图7是本申请一实施例提供的承载所述另一种基于jstorm的实时计算装置的计算子系统的硬件结构图。
具体实施方式
请参见图1,图1为示出的在相关技术中一种基于jstorm的实时计算系统的架构图。
在图1示出的实时计算系统的架构中,包括实时数据传输平台,基于jstorm架构的用于流式计算的计算系统(也称之为流式处理应用),以及用于存储实时计算结果的hbase数据库。
上述实时数据传输平台,可以实时的收集与业务相关的海量待计算的数据(比如与业务相关的日志数据)。而上述计算系统,则可以订阅上述实时数据计算平台中的数据,通过与上述实时数据传输平台之间保持的连接,提取上述实时数据传输平台中的数据,进行实时计算,并将实时计算的结果存储至上述hbase数据库。
然而,在图1中示出的实时计算系统的架构,由于在整体链路上为单点模型,即仅由上述计算系统唯一一个节点参与数据的实时计算,因而会存在如下缺陷:
一方面,一旦上述计算系统所在的计算节点出现故障,就会导致数据计算中断,造成业务上的整体不可用。
另一方面,由于仅由上述计算系统唯一一个节点参与数据的实时计算,因此当上述实时数据传输平台中待计算的数据量较大时,可能会由于计算系统实时计算不及时,导致不必要的业务延时。
为解决上述问题,在本申请中对图1示出的传统的基于jstorm的实时计算系统的架构进行改进,提出一种新的基于jstorm的实时计算系统的架构,在该新的架构中包括仲裁子系统,以及基于jstorm架构的若干计算子系统;所述若干计算子系统采用分布式部署;仲裁子系统可以基于各计算子系统定时发送的心跳消息探测所述若干计算子系统中状态正常的计算子系统,并针对探测到的状态正常的计算子系统动态的分配计算任务,各状态正常的计算子系统可以基于仲裁子系统分配的计算任务,从待计算数据集合中提取对应于该计算任务的数据子集进行数据计算;
一方面,由于各计算子系统采用了分布式部署,并且每一状态正常的计算子系统,仅负责针对待计算数据集合中的部分数据进行计算,因而任一状态正常的计算子系统所在计算节点发生故障,仲裁子系统在将发生故障的计算子系统所承载的计算数据,重新分配给其它状态正常的计算子系统时,仅会针对部分数据的计算造成影响,因而并不会造成业务上的整体不可用,从而提升了实时计算系统的稳定性。
另一方面,由于分布式部署的各计算子系统,并行的参与实时计算,因而可以显著的提升上述实时计算系统的计算性能,当待计算数据量过大时,可以有效的降低业务延迟。
下面通过具体实施例并结合具体的应用场景对本申请进行描述。
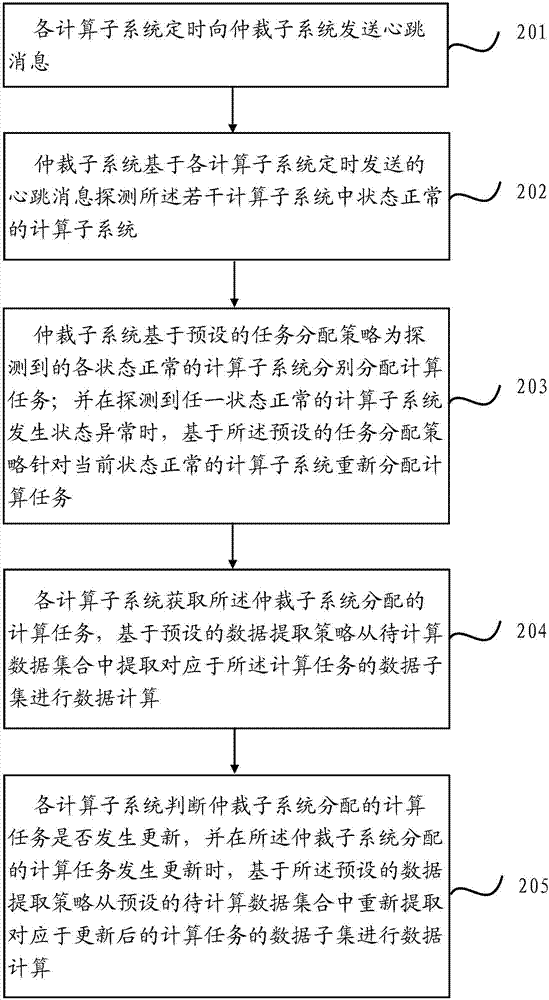
请参考图2,图2是本申请一实施例提供的一种基于jstorm的实时计算方法,应用于实时计算系统,所述实时计算系统包括仲裁子系统,以及基于jstorm架构的若干计算子系统;所述若干计算子系统采用分布式部署;其中,所述仲裁子系统与所述若干计算子系统进行交互,执行以下步骤:
步骤201,各计算子系统定时向仲裁子系统发送心跳消息;
步骤202,仲裁子系统基于各计算子系统定时发送的心跳消息探测所述若干计算子系统中状态正常的计算子系统;
步骤203,仲裁子系统基于预设的任务分配策略为探测到的各状态正常的计算子系统分别分配计算任务;并在探测到任一状态正常的计算子系统发生状态异常时,基于所述预设的任务分配策略针对当前状态正常的计算子系统重新分配计算任务;
步骤204,各计算子系统获取所述仲裁子系统分配的计算任务,基于预设的数据提取策略从待计算数据集合中提取对应于所述计算任务的数据子集进行数据计算;
步骤205,各计算子系统判断仲裁子系统分配的计算任务是否发生更新,并在所述仲裁子系统分配的计算任务发生更新时,基于所述预设的数据提取策略从预设的待计算数据集合中重新提取对应于更新后的计算任务的数据子集进行数据计算。
上述jstorm,是一种流式数据处理框架,广泛应用于实时计算系统中。
上述实时计算系统,可以泛指一切基于jstorm架构的具有海量数据的实时计算处理以及计算能力的计算平台。
上述基于jstorm架构的若干计算子系统,是指采用jstorm框架作为底层引擎的计算子系统。
上述待计算数据,可以是指需要由上述实时计算系统进行实时处理以及计算的与业务相关的数据。在实际应用中,上述待计算数据可以是上述实时计算系统中部署的实时数据传输平台,收集到的海量的与业务相关的日志数据,上述实时计算系统可以对海量的与业务相关的日志数据进行计算,来实现特定的业务功能。
例如,在示出的一种“好友浏览文章推荐”业务场景中,当用户a通过客户端软件查看了某篇文章后,行为数据可以通过日志数据的形式回流到实时计算系统,实时计算系统对回流的日志数据进行实时计算后,可以查询用户a的好友信息,并生成相应的文章推荐策略,然后将生成的文章推荐策略回流到推荐系统,推荐系统可以基于该文章推荐策略向用户a的好友推送类似于“你的好友a看过xx文章”的信息。
在本例中,可以对图1示出的传统的实时计算系统的架构进行改进,通过在传统的实时计算系统的架构的基础上,引入仲裁子系统,以及将原有的计算系统进行分布式部署,划分为若干个计算子单元,从而可以解决图1示出的传统的实时计算系统中所存在的,系统稳定性不足,以及业务延迟的问题。
请参见图3,图3为本例示出的一种的改进后的基于jstorm的实时计算系统的架构图。
在图3示出的实时计算系统的架构中,包括实时数据传输平台,仲裁子系统,以及和基于jstorm架构的用于流式计算的若干计算子系统;该若干计算子系统采用分布式部署。
例如,在示出的一种实施方式中,所述若干计算子系统可以分布式部署于物理地域不同的数据中心;比如,可以分布式部署于位于不同城市的数据中心,通过这种方式,可以实现跨城市级别的数据容灾备份。
其中:
上述实时传输平台,用于实时的收集与业务相关的海量待计算的数据,并将收集到的数据生成固定的大小数据条目,在本地的待计算数据集合(比如数据库)中进行存储。
例如,上述实时传输平台可以是阿里巴巴集团自主研发的timetunnel平台。其中,timetunnel平台是一个基于thrift通讯框架搭建的实时数据传输平台。在timetunnel平台中,通常以队列(queue)作为待处理数据的最小单元,timetunnel平台可以将收集到的海量数据,生成固定大小的队列,在其本地的数据库中进行存储。此时每一个队列都可以称之为一个待计算的数据条目。
上述仲裁子系统,用于基于各计算子系统定时发送的心跳消息,探测所述若干计算子系统中状态正常的计算子系统;并基于预设的任务分配策略为探测到的各状态正常的计算子系统动态分别分配计算任务。
上述若干计算子系统,可以是在功能上相同的计算子系统(比如可以共同处理相同格式的数据),用于定时向仲裁子系统发送心跳消息;获取仲裁子系统分配的计算任务,并基于预设的数据提取策略从实时数据传输平台的数据库中提取对应于仲裁子系统动态分配的计算任务的数据子集进行数据计算。
其中,承载上述实时传输平台、上述仲裁子系统以及上述计算子系统的硬件结构,在本例中不进行特别限定,在实际应用中,可以是一服务器、服务器集群,或者是基于服务器集群构建的云平台,
以下结合图3示出的实时计算系统的架构,对本申请的技术方案进行详细描述。
请参见图3,在示出的一种实施方式中,图3中示出的各计算子系统,可以是包含多个计算节点的分布式系统,各计算子系统在向仲裁子系统发送心跳消息时,可以通过各计算节点分别向仲裁子系统定时发送心跳消息。
其中,所谓计算节点,是指各计算子系统中,可以用于进行独立的数据计算的处理资源;例如,上述计算节点,可以是各计算子系统中的一个可用于独立的数据计算的进程。在这种情况下,上述计算子系统,可以理解为一个多进程的分布式系统。
所谓分布式系统,是指上述计算子系统中可以用于进行独立的数据计算的处理资源,可以分布在不同的物理设备上;例如,当上述计算子系统的硬件架构为一服务器集群时,上述计算子系统中可以用于进行数据计算的进程,可以在不同的物理服务器上运行,并行的参与数据计算。
另外,需要说明的是,上述计算子系统向仲裁子系统定时发送心跳消息的定时发送周期,在本例中不进行特别限定,可以基于实际的用户需求进行自定义设置;
例如,为了确保仲裁子系统能够及时探测到状态异常的计算子系统,可以将定时发送心跳消息的定时发送周期设置为一个较小的周期;比如,每隔1分钟定时发送一次心跳消息。
在本例中,当仲裁子系统接收到各计算子系统中的各计算节点,定时发出的心跳消息后,可以基于接收到的心跳消息探测上述若干计算子系统中状态正常的计算子系统。
在示出的一种实施方式中,上述仲裁子系统在接收各计算子系统中的各计算节点定时发送的心跳消息后,可以分别统计各计算子系统中已成功接收到心跳消息的计算节点的数量,然后基于统计出的数量来探测各计算子系统的状态。
一方面,对于任一计算子系统来说,如果在上述心跳消息的定时发送周期内(比如1分钟内),成功接收到该计算子系统中所有计算节点发送的心跳消息,则可以确定该计算子系统状态正常。
另一方面,对于任一计算子系统来说,如果在上述心跳消息的定时发送周期内,未成功接收到该计算子系统中所有计算节点发送的心跳消息,此时可以进一步统计未成功接收到心跳消息的计算节点的数量,并计算该数量对应于该计算子系统的计算节点总数量的占比。如果该占比达到预设阈值,此时可以确定该计算子系统发生状态异常。
其中,上述预设阈值的大小,可以基于实际的用户需求进行自定义设置,在本例中不进行特别限定。
近似的,如果在下一心跳消息的定时发送周期内(比如2分钟内),对于任一状态异常的计算子系统来说,如果成功接收到该计算子系统中所有计算节点发送的心跳信息,则可以确定该计算子系统状态异常恢复。
例如,假设各计算子系统分别分布式部署在不同城市的数据中心,上述计算节点为各计算子系统中,可用于进行数据计算的进程。此时可以通过上述方式,针对不同城市的数据中心分别进行定时的异常检测。对于任一数据中心来说,如果在在上述心跳消息的定时发送周期内,成功接收到该数据中心中所有进程发送的心跳消息后,可以确定该数据中心当前处于正常状态。
相反,如果在在上述心跳消息的定时发送周期内,未成功接收到该数据中心中所有进程发送的心跳消息后,并且未接收到心跳消息的进程数,对应于总的进程数的占比达到预设阈值(比如50%),由于该数据中心中大部分进程都出现了异常,此时该数据中心可以出现了机房级别的故障,因此可以确定该数据中心当前处于异常状态。另外,如果在下一心跳消息的定时发送周期内,对于任一状态异常的计算子系统来说,如果成功接收到该计算子系统中所有进程发送的心跳信息,则可以确定该计算子系统已经从异常状态恢复。
在本例中,当仲裁子系统探测出各计算子系统中状态正常的计算子系统后,还可以统计当前状态正常的计算子系统的数量,并基于预设的任务分配策略,为状态正常的计算子系统分配计算任务。
在示出的一种实施方式中,上述预设的分配策略具体可以包括获取各计算子系统的标识信息,针对各计算子系统的标识信息进行排序,然后基于针对各计算子系统的标识信息进行排序后的顺序,为各计算子系统分别分配对应的计算任务,并生成对应的任务编号。
其中,各计算子系统的标识信息,可以是指各计算子系统所在数据中心的编号等信息。
例如,请参见图3,假设各计算子系统分别分布式部署于不同城市的数据中心,那么此时各计算子系统的标识信息,可以是其所在数据中心的机房编号。假设上述实时计算系统一共包括4个计算子系统,其所在数据中心的机房编号为zue、ztg、gtj以及su18,那么仲裁子系统在为各计算子系统分配计算任务时,首先可以针对各计算子系统对应的机房编号进行排序;比如可以按照首字母进行排序,当首字符相同再按照下一字符进行排序;此时排序后的顺序为gtj-su18-ztg-zue,在这种情况下,仲裁子系统可以按照该排序后的顺序,为各计算子系统按顺序分配计算任务;比如,此时可以为机房gtj分配计算任务0,为机房su18分配计算任务1,为机房ztg分配计算任务2,为机房zue分配计算任务3。
当然,在实际应用中,除了以上描述的计算任务的分配策略以外,也可以通过其它的策略来实现计算任务的分配,在本例中不再进行一一列举。
在本例中,当仲裁子系统针对各计算子系统分别分配了对应的计算任务后,各计算子系统还可以基于上述心跳消息的定时发送周期,定时从仲裁子系统上查询为自身分配的计算任务的任务编号。
当然,在实际应用中,仲裁子系统为各计算子系统分配的任务编号,也业务可以由上述仲裁子系统,基于上述心跳消息的定时发送周期,定时的推送至各计算子系统,在本例中不进行特别限定。
在本例中,各计算子系统在查询到仲裁系统为自身分配的任务编号后,可以基于预设的数据提取策略,从实时数据传输平台的待计算数据集合中,提取对应于该任务编号的数据子集。
上述预设的数据提取策略可以一种基于当前状态正常的计算子系统的实际数量,对上述待计算数据集合中的数据进行平均分配的策略。
例如,在示出的一种实施方式中,上述预设的数据提取策略可以包括创建对应与该计算任务的任务编号对应的数据子集(初始化一个空的数据子集);将上述待计算数据集合中的待计算数据条目的数据编号,与上述仲裁子系统探测到的状态正常的计算子系统的数量进行取余逻辑运算(%运算);然后将该取余逻辑运算的结果与该计算任务对应的任务编号进行匹配;当上述待计算数据集合中的任一待计算数据条目的上述取余逻辑运算的结果,与该计算任务对应的任务编号匹配时,则可以基于与上述实时数据传输平台之间的数据连接,从上述待计算任务集合中,提取该待计算处理条目,并将该待计算数据条目存储至与该计算任务对应的上述数据子集中。
例如,假设上述实时数据传输平台为tt平台,上述待计算数据集合包含编号为0~127的共128个队列,假设当前共4个状态正常的计算子系统参与针对上述待计算数据集合的实时计算,仲裁系统为该4个计算子系统分配的计算任务分别为0、1、2和3。基于上述预设的数据提取策略,与每一个计算任务对应的数据子集中所包含的队列编号,满足以下公式:
queue_no%m=task_no
其中,queue_no为队列编号,m为正常状态的计算子系统的数量,task_no为对应的任务编号。通过上述公式计算后,针对每一个队列编号将分别计算出一个对应的任务编号,此时可以基于队列编号从上述待计算数据集合中分别提取对应的队列,然后将提取到的队列存储到与计算出的任务编号对应的数据子集中。比如,最终计算出的与各计算子单元的任务编号对应的数据子集分别为[0,4,…,124]、[1,5,…,125]、[2,6,…,126]、[3,7,…,127]。其中,以上示出的数据子集中的每一个数字均对应一个队列编号。
可见,通过这种方式,可以将上述待计算数据集合中的数据条目,平均分配至各数据子系统中进行实时计算。
当然,在实际应用中,除了以上示出的数据提取策略以外,也可以通过其它策略来完成上述数据条目的提取,生成对应于各计算任务的上述数据子集,在本例中不再一一进行列举。
在本例中,当各计算子系统基于以上示出的数据提取策略,从实时数据传输平台的待计算数据集合中,提取出对应于仲裁子系统为自身分配的任务编号的数据子集后,可以针对该数据子集中的数据进行实时的数据计算,并在计算完成后,对计算结果进行存储,以便于相关的业务系统进行调用。
例如,请参见3,对于基于jstorm的计算子系统而言,可以在其系统中部署诸如hbase等分布式的数据库,以用于存储实时计算的结果。
以上详尽描述了仲裁子系统,在探测出当前状态正常的计算子系统后,为各状态正常的计算子系统分配计算任务的处理过程。
由于仲裁子系统,针对各计算子系统的异常检测为定时检测,因此当前已经被明确为状态正常的计算子系统,在下一心跳消息的定时发送周期内,其状态仍然可能发生变化。
因此,为了应对这种变化,仲裁子系统为各状态正常的计算子系统分配计算任务时,可以采用动态分配的方式,即可以基于每一个周期内探测到的状态正常的计算子系统的实际数量,对计算任务的分配结果进行动态调整。
在本例中,对于任一已被确定为状态正常的计算子系统而言,如果在下一心跳消息的定时发送周期内,基于以上示出的相同的异常检测策略,确定出该计算子系统发生状态异常时,由于此时该计算子系统已经被分配了计算任务,因此在这种情况下,上述仲裁子系统可以基于当前状态正常的计算子系统的实际数量,基于以上示出的预设的任务分配策略重新进行计算任务的分配。
相似的,对于任一已被确定为状态异常的计算子系统而言,如果在下一心跳消息的定时发送周期内,基于以上示出的相同的异常检测策略,确定出该计算子系统从异常状态恢复时,上述仲裁子系统也可以基于当前状态正常的计算子系统的实际数量,基于以上示出的预设的任务分配策略重新进行计算任务的分配。
其中,基于上述预设的任务分配策略重新进行计算任务的分配的实时过程,请参见本实施例之前的描述,不再赘述。
可见,通过这种方式,仲裁子系统在任一心跳消息的定时发送周期内,探测到状态正常的计算子系统发生状态异常时,都可以通过重新分配计算任务,将该状态异常的计算子系统承载的计算数据,切换至其它状态正常的计算子系统中,当上述心跳消息的定时发送周期内设置的足够小时,可以显著的增强上述实时计算系统的稳定性;比如,当上述定时发送周期为1分钟,那么上述实时计算系统可以在分钟级别,将状态异常的计算子系统承载的计算数据切换至其它状态正常的计算子系统。
当然,在实际应用中,上述预设的数据提取策略除了可以是以上示出的平均分配的策略以外,也可以不采用这种平均分配的方式。
例如,当任一已被确定为状态正常的计算子系统发生状态异常时,上述仲裁子系统也可以不进行计算任务的重新分配,而是仅将发生状态异常的计算子系统所承载的计算数据,切换至当前所有状态正常的计算子系统中的指定计算子系统(比如当前计算压力最小的计算子系统),并在该计算子系统状态异常恢复后,将切换至该指定计算子系统中的计算数据进行回切,在本例中不在进行详述。
相应的,对于各计算子系统而言,当获取到仲裁子系统为自身分配的任务编号,并且基于上述预设的数据提取策略,从上述待计算数据集合中提取出对应于该数据编号的数据子集后,由于仲裁子系统针对各计算子系统的异常检测为定时检测,并且如果当前状态正常的计算子系统的数量在发生变化后,会触发仲裁子系统对计算任务进行重新分配,因此在这种情况下,为了应对计算任务可能发生的变化,各计算子系统还可以定时判断仲裁子系统为自身分配的计算任务是否发生更新。
其中,各计算子系统在判断仲裁子通为自身分配的计算任务是否发生更新时,可以通过判断为自身分配的计算任务对应的任务编号,以及当前状态正常的计算子系统的数量是否发生变化来实现。
在示出的一种实施方式中,各计算子系统在判断仲裁子通为自身分配的计算任务是否发生更新时,可以将该计算任务对应的任务编号,与仲裁子系统定时探测到的状态正常的计算子系统的数量进行异或逻辑运算(or预算);然后判断异或逻辑运算的结果是否发生变化;如果异或逻辑运算的结果发生变化,则确定仲裁子系统分配的计算任务发生变化。
在本例中,如果仲裁子系统通过以上示出的判断逻辑,判断出仲裁子系统为自身分配的计算任务发生更新后,还可以基于上述预设的数据提取策略,从待计算数据集合中重新提取对应于更新后的计算任务的数据子集,进行实时的数据计算。
其中,基于上述预设的数据提取策略重新提取对应于更新后的计算任务的数据子集的实施过程,请参见本实施例之前的描述,不再赘述。
通过以上实施例可知,本申请通过对传统的基于jstorm的实时计算系统的架构进行改进,提出一种新的基于jstorm的实时计算系统的架构,在该新的架构中包括仲裁子系统,以及基于jstorm架构的若干计算子系统;所述若干计算子系统采用分布式部署;仲裁子系统可以基于各计算子系统定时发送的心跳消息探测所述若干计算子系统中状态正常的计算子系统,并针对探测到的状态正常的计算子系统动态的分配计算任务,各状态正常的计算子系统可以基于仲裁子系统分配的计算任务,从待计算数据集合中提取对应于该计算任务的数据子集进行数据计算;
一方面,由于各计算子系统采用了分布式部署,并且每一状态正常的计算子系统,仅负责针对待计算数据集合中的部分数据进行计算,因而任一状态正常的计算子系统所在计算节点发生故障,仲裁子系统在将发生故障的计算子系统所承载的计算数据,重新分配给其它状态正常的计算子系统时,仅会针对部分数据的计算造成影响,因而并不会造成业务上的整体不可用,从而提升了实时计算系统的稳定性。
另一方面,由于分布式部署的各计算子系统,并行的参与实时计算,因而可以显著的提升上述实时计算系统的计算性能,当待计算数据量过大时,可以有效的降低业务延迟。
与上述方法实施例相对应,本申请还提供了装置的实施例。
请参见图4,本申请提出一种基于jstorm的实时计算装置40,应用于实时计算系统中的仲裁子系统,所述实时计算系统还包括基于jstorm架构的若干计算子系统;所述若干计算子系统采用分布式部署;
请参见图5,作为承载所述基于jstorm的实时计算装置40的仲裁子系统所涉及的硬件架构中,通常包括cpu、内存、非易失性存储器、网络接口以及内部总线等;以软件实现为例,所述实时计算装置40通常可以理解为加载在内存中的计算机程序,通过cpu运行之后形成的软硬件相结合的逻辑装置,所述装置40包括:
探测模块401,基于各计算子系统定时发送的心跳消息探测所述若干计算子系统中状态正常的计算子系统;
分配模块402,基于预设的任务分配策略为探测到的各状态正常的计算子系统分别分配计算任务,以由各计算子系统从待计算数据集合中提取对应于所述计算任务的数据子集进行数据计算;
所述分配模块402,在探测到任一状态正常的计算子系统发生状态异常时,基于所述预设的任务分配策略针对当前状态正常的计算子系统重新分配计算任务。
在本例中,所述计算子系统为包含多个计算节点的分布式系统;
所述探测模块401具体:
接收各计算子系统中的各计算节点定时发送的心跳消息;
统计各计算子系统中成功接收到所述心跳消息的计算节点数量;
当在所述心跳消息的定时发送周期内,成功接收到任一计算子系统中所有计算节点发送的心跳消息时,确定该计算子系统状态正常。
在本例中,所述探测模块401进一步:
当在所述心跳消息的定时发送周期内,未成功接收到任一计算子系统中所有计算节点发送的心跳消息,并且未成功接收到所述心跳消息的计算节点的数量对应于该计算子系统的计算节点总数量的占比达到预设阈值时,则确定该计算子系统状态异常;
当在所述心跳消息的下一定时发送周期内,成功接收到状态异常的计算子系统中所有计算节点发送的心跳信息,则确定该计算子系统状态异常恢复。
在本例中,所述分配模块402进一步:
在探测到任一状态异常的计算子系统状态异常恢复时,基于所述预设的任务分配策略针对当前状态正常的计算子系统重新分配计算任务。
在本例中,所述预设的分配策略包括:
获取各计算子系统的标识信息;
针对各计算子系统的标识信息进行排序;
基于针对各计算子系统的标识信息进行排序后的顺序,为各计算子系统分别分配对应的计算任务,并生成对应的任务编号。
在本例中,所述若干计算子系统分布式部署于物理地域不同的数据中心。
请参见图6,本申请提出另一种基于jstorm的实时计算装置60,应用于实时计算系统中的任一计算子系统,所述实时计算系统包括仲裁子系统,以及基于jstorm架构的若干计算子系统;
所述若干计算子系统采用分布式部署;请参见图7,作为承载所述实时计算装置60的计算子系统所涉及的硬件架构中,通常包括cpu、内存、非易失性存储器、网络接口以及内部总线等;以软件实现为例,所述实时计算装置60通常可以理解为加载在内存中的计算机程序,通过cpu运行之后形成的软硬件相结合的逻辑装置,所述装置60包括:
发送模块601,定时向仲裁子系统发送心跳消息,以由所述仲裁子系统基于所述心跳消息探测所述若干计算子系统中状态正常的计算子系统,并为状态正常的计算子系统分配计算任务;
提取模块602,获取所述仲裁子系统分配的计算任务,基于预设的数据提取策略从待计算数据集合中提取对应于所述计算任务的数据子集进行数据计算;
判断模块603,判断仲裁子系统分配的计算任务是否发生更新;
所述提取模块602,在所述仲裁子系统分配的计算任务发生更新时,基于所述预设的数据提取策略从预设的待计算数据集合中重新提取对应于更新后的计算任务的数据子集进行数据计算。
在本例中,所述计算子系统为包含多个计算节点的分布式系统;
所述发送模块601具体:
通过计算子系统中的各计算节点定时分别向所述仲裁子系统发送心跳消息。
在本例中,所述预设的数据提取策略,包括:
创建对应于所述计算任务的任务编号的数据子集;
将所述待计算数据集合中的待计算数据条目的数据编号,与所述仲裁子系统探测到的所述若干计算子系统中的状态正常的计算子系统的数量进行取余逻辑运算;
将所述取余逻辑运算的结果与所述计算任务对应的任务编号进行匹配;
当任一待计算数据条目的所述取余逻辑运算的结果,与所述计算任务对应的任务编号匹配时,提取该待计算处理条目,并将该待计算数据条目存储至与该计算任务对应的所述数据子集中。
在本例中,所述判断模块603具体:
将所述计算任务对应的任务编号,与所述仲裁子系统探测到的所述若干计算子系统中的状态正常的计算子系统的数量进行异或逻辑运算;
判断所述异或逻辑运算的结果是否发生变化;
如果所述异或逻辑运算的结果发生变化,则确定仲裁子系统分配的计算任务发生变化。
在本例中,所述若干计算子系统分布式部署于物理地域不同的数据中心。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本申请的其它实施方案。本申请旨在涵盖本申请的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本申请的一般性原理并包括本申请未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本申请的真正范围和精神由下面的权利要求指出。
应当理解的是,本申请并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本申请的范围仅由所附的权利要求来限制。
以上所述仅为本申请的较佳实施例而已,并不用以限制本申请,凡在本申请的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本申请保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!