一种适用于网络节点分类方法评估的仿真网络生成方法与流程
本发明涉及一种仿真网络生成方法。
背景技术:
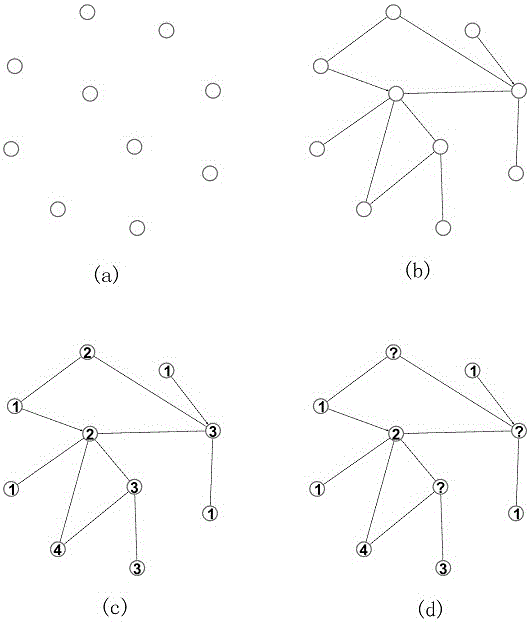
:作为网络科学的重要研究领域之一,网络节点分类技术已经得到了广泛关注,并且在身份识别、反恐、信息推荐等领域有着重要的应用价值。网络节点分类技术是指:利用网络中一部分已知节点的类别去预测其余未知节点的类别。传统分类技术通常假设数据之间是独立同分布的,然而网络数据之间往往存在较强的关联,这使得节点的类别不仅与自身的属性相关,还与邻居节点、拓扑结构等网络属性有着密切的联系。节点分类方法可以利用上述特征来提高分类性能。例如,当认为网络中同质性较强的时候(即节点倾向于和自身类别相似的节点连接),利用邻居节点加权投票的方法就能够获得更为满意的结果。不同的分类方法依赖的网络属性有所不同,因此,为了评价一种分类方法的适用领域,往往需要在具有不同特征的网络上进行对比分析。然而,在当前阶段,适用于网络分类评估的真实网络还相对较少,其网络特征也较为单一,无法充分评估分类方法的性能,这也使得生成具有不同网络特征的仿真网络成为评价分类方法性能的重要手段。传统的网络生成方法关注拓扑结构的生成,其核心思想是生成与真实网络拓扑结构(小世界、无标度)更为相近的仿真网络。然而,由于生成的网络并没有标签信息,往往无法直接使用这些网络对节点分类方法进行评估。此外,也有学者尝试根据同质性等指标,生成带有标签的仿真网络。然而,这些带有标签的生成方法对于拓扑结构的约束较少,使得其生成的网络拓扑结构与真实的网络差距较大(例如,并不带有典型的社区结构等),导致这类方法生成的网络也不适合对分类方法进行评估。技术实现要素:针对上述现有技术中存在的技术问题,本发明提供一种新颖的仿真网络生成方法,用来准确地评估节点分类方法对不同网络属性(同质性、节点分布比例、网络的社区结构、网络的密度等)的敏感程度。近些年来,网络科学的研究进展很快,已经发现复杂网络有着一些不同以往的特征(例如小世界、幂律分布、同质性等)。因此,现有的节点分类方法不只关注于节点自身的属性,也在利用不同的网络特征来辅助分类过程。然而,分类方法的建模角度有所差别,使得其受到网络特征的影响程度也有所不同。总体来看,对于节点分类有影响的网络特征主要有以下两类:(1)拓扑特征:我们关注的问题是复杂网络中的节点分类问题,而不同的网络有着不同的拓扑特征,例如密度(density)、直径、度分布、聚类系数等,这些特征都是网络生成过程中表现出的一些特有规律,其对于分类方法的影响程度也有所不同,例如,已经知道网络的密度对于协同分类有着较大的影响;(2)标签特征:网络中节点之间并不是互相独立的,而是彼此相连,这使得节点的类别不仅与自身的属性相关,在很大程度上还依赖于邻居节点的标签,因此,网络中节点的标签表现出来的分布规律,我们称之为网络的标签特征,也在很大程度上影响着分类方法的表现。为了更好地分析不同网络特征对分类方法的影响,本发明提出一种仿真网络生成方法,来生成具有不同网络特征的仿真网络。该方法包括:首先,根据指定的拓扑结构参数,如节点数量、边的数量、最大度、平均度分布、小世界以及社区结构等,生成接近于真实网络的初步仿真网络结构;其次,根据指定的标签特征,如标签分布比例和同质性等,生成网络中每个节点的标签,进而得到一个适合评估网络节点分类器的带有标签的仿真网络。进一步地,在评估分类方法性能的时候,根据已知标签的节点所占的比例的设定,随机设定相应数量的节点标签为已知,得到一个待预测的仿真网络,此时,得到的待预测的仿真网络就可以用来评估一种分类方法在指定特征下的表现,分类方法根据当前网络的拓扑结构和已知节点来预测未知节点的标签。本发明的有益效果在于:1.相对于传统的网络生成方法,本发明不仅能够生成接近真实网络的拓扑结构,并且考虑了节点的标签信息,使得生成的仿真网络更利于全面地评估节点分类方法。2.本发明在生成网络的过程中将拓扑结构和标签生成过程分开,可以有效地保证参数影响的独立化,能够更加准确的评估分类方法对于不同属性的依赖程度。附图说明图1是本发明方法的预测框架图。图2是本发明仿真网络的生成过程示例。具体实施方式如图1所示,本发明的一种适用于网络节点分类方法评估的仿真网络生成方法中,首先要保证生成的网络拓扑结构更加接近真实网络,这样才能更好地评估分类方法在真实世界中的表现。因此,本方法中,对于给定网络拓扑结构参数集合T={n,d,c,…},其中n表示节点数量,d表示密度,c表示社区结构等,首先生成网络的拓扑结构G=<V,E>,其中V表示了网络中的节点集合,E表示网络中的边集合;其次,分类方法需要利用已知节点来预测未知节点,因此需要指定与标签相关的特征集合L={h,ld,…},其中h为网络中的同质性,ld为标签分布比例等,按照L的限制生成网络中每个节点的标签,得到一个带有标签的仿真网络GL=<V,E,LN>,其中LN为节点的标签集合。在评估分类方法性能的时候,可以根据已知标签的节点所占的比例lp的设定,随机设定相应数量的节点标签为已知,得到一个待预测的仿真网络GLP=<V,E,LN,UN>,其中V为节点集合,E为边的集合,LN为已知节点的标签集合,UN为未知节点的标签集合。此时,标签网络GLP就可以用来评估一种分类方法NC1在指定特征<T,L>下的表现。例如,当我们选取准确度作为预测指标的时候,就是评估NC1预测的未知节点的标签集合PN与UN的差异。图2展示了一个示例网络的生成过程,其中:(a)是首先指定网络中节点的数量;(b)是根据网络的拓扑结构参数生成的仿真网络拓扑结构;(c)是根据网络的标签分布参数生成的仿真网络,此时的网络已经生成完毕;(d)为了评估分类方法的表现,根据设定的训练集比例,随机选取网络中部分节点为已知,其余节点为未知后,得到的标签网络。分类方法需要根据当前网络的拓扑结构和已知节点来预测未知节点的标签。作为复杂网络的研究热点之一,目前已经涌现出大量的网络节点分类方法。由于每种方法利用的网络特征有所不同,其受到网络属性的影响也有所不同。我们选取其中有代表性的几种方法(直接邻居:wvRN;局部结构:CN;社区结构:socioDim),来验证其在不同网络属性下的表现。在网络生成阶段,我们选取ANC(AttributedNetworkswithCommunitiesGenerator)的方法来生成网络的拓扑结构。其优点是可以生成带有社区结构的网络,更加贴近真实网络的生成过程,也可以更好地评估socioDim这类利用社区结构进行分类的方法。在网络属性方面,我们着重分析同质性h,标签分布比例ld以及网络的拓扑结构T。拓扑结构T重点关注密度和社区结构的影响。需要注意的是,在分类过程已知节点的标注比例LP也会对分类性能产生影响。例如以下两种情况:LP=0.9,即网络中90%的节点类别已知,来预测10%的未知节点;LP=0.1即网络中10%的节点类别已知,来预测90%的未知节点。可以明显的看出,同样的方法在两种情况下得到的准确度是不同的,后者的情况预测过程会更加困难。对于LP=0.1这类情况下的分类,其属于稀疏标注的问题,近些年来也得到了广泛关注。虽然在下面的实验中,我们也会展示LP也会对分类性能带来的影响,但是我们并不将其划入网络属性中。这是因为,我们认为其并没有在网络的生成过程中起到任何作用,也没有反映出网络生成过程的任何规律。LP的变化只是在一个已经标注完全的数据集上的测试手段,用来测试分类方法在大数据时代标注稀疏情况下的泛化能力而已。下面将验证给定的3种有代表性的分类方法,受不同网络属性的影响程度。1.固定同质性h、标签分布比例ld,变化网络的拓扑结构T。设定节点数量为500,变化T生成4个仿真网络的拓扑结构,参数如表1。表1:我们固定h=0.6,ld=0.5,生成每个网络的标签。在仿真每个网络上,我们设定不同的标注比例LP(from0.5to0.9),测试3种方法在上述数据集上的表现。其中socioDim方法需要设定隐含社交维度的数量d,由于其普遍采取社区发现算法来抽取隐含的社交维度,因此我们设定d=k,即为生成网络时指定的社区个数。结果如表2所示。表2:CN0.50.60.70.80.9k=40.583360.57510.5841330.57360.5656k=400.58120.58460.5845330.58140.5824k=800.577840.57460.5773330.58620.5884k=1000.552880.55650.5541330.56840.5468wvRN0.50.60.70.80.9k=40.60320.5980.6005330.60260.6016k=400.588240.59060.59520.59760.6012k=800.573120.57230.57360.58340.5868k=1000.574880.58350.5937330.61260.5996socioDim0.50.60.70.80.9k=40.596920.602580.603440.609180.615k=400.5894080.597440.60360.604840.60844k=800.5885840.593590.600320.605440.615k=1000.5465920.548050.5570270.566020.57688可以看出,当其他参数固定,而网络拓扑结构发生变化的时候,都会直接影响分类方法的表现。这是由于在网络拓扑结构发现变化的时候,边的数量和结构会影响协同分类的性能。因此,wvRN虽然只依赖于直接邻居节点,但是由于采取协同推理机制,使得其在不同拓扑结构上的表现也有所波动。CN和socioDim方法在前三个网络上表现较为稳定,而在最后一个网络上表现较差。这是由于在我们限制网络中边的比例的情况下,继续增加社区数量会导致网络出现多个联通片。这使得CN方法中,节点的局部结构变化较为明显,一些较小的联通片中,未知节点的共同邻居数量变少,对CN的分类表现产生了一定的影响。对于socioDim方法来说,当我们设定其社交维度与真实网络中的社区数量一致的时候,其表现较为稳定。而在网络出现联通片后,其会认定较小的联通片中的节点同属于一个社交维度,因此对其中的节点的区分能力变差。因此,在评估不同分类方法表现的时候,必须要注意到拓扑结构对分类性能的影响。2.固定同质性h、网络的拓扑结构T,变化标签分布比例ld。设定节点数量为500,社区数量为4,生成一个仿真网络的拓扑结构。继而固定h=0.6,变化1d的值(from0.5to0.9),生成每个网络的标签。在仿真每个网络上,我们设定不同的标注比例LP(from0.5to0.9),测试3种方法在上述数据集上的表现。结果如表3所示。表3:CNlp=0.5lp=0.6lp=0.7lp=0.8lp=0.9ld=0.50.583360.57510.5841330.57360.5656ld=0.60.594480.59420.6101330.60520.5992ld=0.70.697280.6910.6980.70080.7124ld=0.80.80280.80230.7954670.79660.796ld=0.90.900960.90430.9069330.89320.8996socioDimlp=0.5lp=0.6lp=0.7lp=0.8lp=0.9ld=0.50.5958880.602240.603360.607180.61332ld=0.60.590120.592610.59540.597860.59892ld=0.70.7010240.699960.6970130.699660.70092ld=0.80.8002960.801630.800520.80080.80148ld=0.90.90060.900890.9009330.900860.90132wvRNlp=0.5lp=0.6lp=0.7lp=0.8lp=0.9ld=0.50.60320.5980.6005330.60260.6016ld=0.60.600480.60180.6165330.61320.6064ld=0.70.67680.67830.68440.68860.7068ld=0.80.778640.78170.7829330.78760.7868ld=0.90.870960.87760.8870670.880.8896可以看出,随着网络中节点的标签分布比例发生变化,三种方法的准确度都有着明显的变化,说明分类方法对于标签分布比例的变化是较为敏感的。标签分布比例的升高,意味着网络中某一类标签(假设标签为LO)的节点占据了多数。对于wvRN来说,虽然只利用了局部的邻居节点,但当大量的邻居节点拥有标签LO的时候,wvRN方法也会倾向于将节点分为LO。CN方法由于使用了网络中所有节点参与分类,因此当网络中某一类别的节点占绝大多数的时候,其倾向于将节点分为该多数类。socioDim方法包含有训练SVM模型的过程,因此当训练集中某一分类的比例占多数时,其也倾向于将节点分为该多数类。因此,在面对非平衡数据的分类任务时,节点分类方法需要引入控制策略(例如,可以选取top-K,或者加大多数类的惩罚因子等)来应对不平衡分类带来的挑战。同时我们发现,在上面的过程分类过程中,已知节点的标注比例变化(from0.5to0.9)对于分类性能的影响相对较小。这是由于在网络的标签生成过程中,我们先按照统一的模式生成所有节点的标签特征,进而通过随机的方式指定训练和测试集合,这样可以有效地保证测试集和训练集的特征分布一致,能够更好地评估分类方法的性能。因此,当节点标注比例发生变化的时候对分类性能的影响较小。然而,我们将在下一节的实验中看到,当网络中其它特征发生变化的时候,如果分类方法的表现与此特征密切相关的时候,LP的变化也会对分类性能有着较为明显的影响。3.固定标签分布比例1d、网络的拓扑结构T,变化同质性h。设定节点数量为500,社区数量为4,生成一个仿真网络的拓扑结构。继而固定ld=0.5,变化h的值(from0.4to0.8),生成每个网络的标签。在仿真每个网络上,我们设定不同的标注比例LP(from0.5to0.9),测试3种方法在上述数据集上的表现。结果如表4所示。表4:CNlp=0.5lp=0.6lp=0.7lp=0.8lp=0.9h=0.40.548720.5380.5561330.56420.5736h=0.50.5020.5060.5069330.49620.51h=0.60.584640.58560.5866670.58340.5736h=0.70.682320.66960.6754670.68220.6776h=0.80.761120.75770.7562670.74460.7548socioDim4lp=0.5lp=0.6lp=0.7lp=0.8lp=0.9h=0.40.5378480.543690.5491470.556380.55912h=0.50.4880240.487530.4872130.48780.48948h=0.60.5960480.599240.6036670.610640.61016h=0.70.6359360.636930.6392670.641820.64196h=0.80.7417760.74390.744720.745860.74144wvRNlp=0.5lp=0.6lp=0.7lp=0.8lp=0.9h=0.40.30960.27410.2381330.20180.1496h=0.50.512240.51470.51960.52060.5172h=0.60.601040.60570.6080.60980.6116h=0.70.69680.68920.6954670.70760.7096h=0.80.77320.77080.7710670.76480.786网络的同质性等于网络中相邻的两个节点类别相同的边的比例。wvRN依赖于节点的直接邻居进行分类,在同质性较低的网络中,大多数邻居节点与未知节点的类别不同,因此其在同质性较低的网络中表现较差。而随着同质性的增加,邻居节点倾向于拥有相同的类别,因此wvRN方法的表现也有大幅提高。另外我们发现,在同质性较低的时候(h=0.4),wvRN在标注比例较低的时候的表现,反而比标注比例高的时候要好。这是由于在h=0.4的时候,邻居节点之间倾向于拥有不同的类别,因此,当已知节点为90%的时候,这样现象会更加明显,因为未知节点的邻居节点大多数都是已知的,都会参与分类过程,会使得准确度较低;相反,当已知节点为50%的时候,未知节点的邻居节点大多数是未知的,这会使得同质性的影响稍稍减弱,反而有利于wvRN方法得到较为满意的结果。CN方法依赖于共同邻居进行分类,因此可以克服同质性带来的影响,在同质性较低的网络上也有较好表现。而当同质性增加到一定程度的时候,绝大部分邻居节点都倾向于拥有相同的类别,因此在局部结构中,未知节点与大部分已知节点都倾向于拥有相同的类别,因此准确度也有所提升。同样的,socioDim利用网络中的社区结构进行分类,因此其受同质性的影响也相对较小。而当网络的同质性增高的时候,同一个社区内部连接较为紧密,其内部倾向于拥有相同的类别,也会使得其分类性能有所提升。此外我们发现,在h=0.5的时候,二者的准确度都有一个明显的降低。这是由于在h=0.5的时候,网络中50%的边的顶点类别相同,而另外50%的边顶点类别不同,这说明网络中节点的连接情况较为随机,没有明显的规律出现,因此无论是利用共同邻居还是社区结构,都无法在这种随机特征的网络中得到满意的分类结果。本发明设计了一个标签网络的生成框架,用来评估分类方法在不同网络属性下的表现。为了保证生成的仿真网络更加接近真实网络,该方法可以集成不同的拓扑结构生成方法,极大地拓展了其应用领域。在标签生成阶段,重点关注同质性与标签分布比例对分类方法的影响。实验表明,本发明提供的方法可以快速地生成满足要求的标签网络,能够有效地评估不同分类方法的适用领域。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1