结合Redis内存数据库的分布式RDF关键词近似搜索方法与流程
本发明涉及一种结合Redis内存数据库的分布式RDF关键词近似搜索方法。
背景技术:
随着语义网的快速发展,资源描述框架(Resource Description Framework,RDF)作为语义数据的描述标准被广泛应用。众多机构和项目均采用RDF来表达元数据,如Wikipedia、DBLP、IBM的“智慧地球”项目。面对如此爆炸式增长的数据压力,如何存储和搜索大规模RDF数据成为亟待解决的问题。传统的存储技术在日益增长的数据面前暴露出许多不可克服的问题。然而结构简单的Redis数据库在存储海量的RDF数据时也能具备优秀的性能,满足了大规模RDF数据储存的需求。
关键词搜索作为一种从RDF数据图检索信息的有效途径,普通用户在不需要熟悉任何标准的查询语言结构和底层数据模式的情况下就能快速有效地检索数据。根据查询处理方式的不同,RDF上的关键词查询大致可以分为两类。第一类是由关键词构造出形式化查询语句再得到查询结果。该类方法通常包括关键词映射、构建查询和查询排序三大步骤。Gkirtzou K等人结合数据图将包含用户查询关键词的子图映射并翻译成SPARQL查询语句,进行查询操作后返回结果。但是这类方法需要构建关键词索引和数据图的模式索引,又要构建形式化查询语句,难于满足海量RDF数据存储和搜索的需求。第二类是由关键词直接构造查询的结果。这类方法通常需要借助有效的索引来快速定位子图并搜索结果,最常用的索引是倒排索引。文献以实体三元组关联图为模型,封装文本信息到关联图顶点标签上,利用斯坦纳树问题的近似算法解决RDF数据的关键词查询问题。但是这类方法需要构建并维护索引,在处理海量数据的时候显得力不从心。
随着分布式思想的普及,要求关键词搜索不断演化为并行搜索分布式存储的大规模RDF数据。De Virgilio R[12]等利用MapReduce计算模型将图并行问题转换为数据并行处理问题,实现了分布式RDF关键词的搜索。
现有的分布式关键词搜索方法一般都是借助有效的索引机制,直接从大规模的RDF数据图中找到与关键词匹配的节点,进行复杂的连接操作后返回结果,并且现存的关键词搜索方法中用到的存储媒介一般都是基于磁盘读取的,这需要昂贵的计算成本且搜索效果不理想。大规模的RDF数据图中拥有数百万甚至上亿的节点,规模大小一般都是GB甚至TB级别的,直接从中找到匹配的节点并进行连接需要多次的迭代计算,这会耗费很多时间。同时,目前的关键词搜索中是假定用户明确自己的搜索意图,但是实际上用户对本体的结构和内容有可能并不了解,不同用户对同一事物的描述可能存在差异,用户可能也不明确自己的搜索意图。在这种情况下即使用户使用了明确的搜索关键词,搜索中仍然有可能返回空或少量的搜索结果。由于RDF本体涵盖了资源和属性的分类及关联,而且规模大小一般都为KB级别的,通过本体可以推导出任意两个类或者属性的关联关系。
技术实现要素:
有鉴于此,本发明的目的在于提供一种结合Redis内存数据库的分布式RDF关键词近似搜索方法,解决了海量数据无法快速搜索和搜索效果不理想的问题,并且支持返回用户可能感兴趣的结果,具有深远的理论和实际意义。
为实现上述目的,本发明采用如下技术方案:一种结合Redis内存数据库的分布式RDF关键词近似搜索方法,其特征在于,包括以下步骤:
步骤S1:对RDF本体和RDF实例数据进行预处理,并生成相应
的文件;
步骤S2:结合Redis分布式数据库集群的特点,将步骤S1中生成的文件内容分门别类地存储在Redis数据库集群的Set集合中;
步骤S3:根据RDF本体信息和输入的关键词集合Q,先把关键词映射成对应的类或属性,然后在本体图上找到类或属性匹配的模式三元组,对所述模式三元组进行三元组连接,生成关键词集合对应的本体子图;
步骤S4:利用语义评分函数对构建的本体子图进行打分并排序,得分高的优先进行分布式搜索,跳到步骤S5;
步骤S5:Map阶段搜索本体子图中各个模式三元组对应的实例三元组;
步骤S6:Reduce阶段则将接收到的实例三元组进行连接,得到结果子图,并返回结果子图;
步骤S7:判断结果子图中的实例三元组是否达到k条,如果已经达到,则结束搜索,跳到步骤S12,否则跳到步骤S8;
步骤S8:判断是否还有本体子图没有进行分布式搜索,如果有,则跳到步骤S4,否则跳到步骤S9;
步骤S9:判断是否有扩展后的近似本体子图未进行分布式搜索,如果有,则跳到步骤S11,否则跳到步骤S10;
步骤S10:根据本体扩展规则按步骤S4中的排序对本体子图进行扩展并生成近似本体子图,跳到步骤S11;
步骤S11:利用语义相似度函数对生成的近似本体子图进行打分并排序,得分高的优先进行分布式搜索,跳到步骤S5;
步骤S12:算法结束。
进一步的,所述步骤S2中Set集合的具体存储方案如下:
Class用于存储RDF本体信息中定义的类信息:Class={C1,C2,...,Ci,...,Cn},其中Ci表示类;
Property用于储存RDF本体中定义的属性、属性的定义域以及值域信息:Property={P1,P2,...,Pi,...,Pn},其中Pi={dr1,dr2,...,drj,...,drm},drj=(dj,rj),Pi表示属性,dj表示Pi的一个定义域,rj表示dj对应的值域;
Class_Sup用于存储类的父类信息:Class_Sup={CS1,CS2,...,CSi,...,CSn},其中CSi={S1,S2,...,Sj,...,Sm},CSi表示类,Sj表示CSi的一个父类;
Property_Sup用于存储属性的父属性信息:Property_Sup={PS1,PS2,...,PSi,...,PSn},其中PSi={S1,S2,...,Sj,...,Sm},PSi表示属性,Sj表示PSi的一个父属性;
OntoTriple用于存储所有的模式三元组信息:OntoTriple={S1,S2,...,Si,...,Sn},其中Si={PO1,PO2,...,POj,...,POm},POj=(Pj,Oj),Si表示模式三元组的主语,Pj表示Si的一个谓语,Oj表示Pj对应的宾语;
OntoTriple_Reverse用于存储所有模式三元组的反转备份:OntoTriple_Reverse={O1,O2,...,Oi,...,On},其中Oi={PS1,PS2,...,PSj,...,PSm},PSj=(Pj,Sj),Oi表示模式三元组的宾语,Pj表示Oi的一个谓语,Sj表示Pj对应的主语;
Instance_Class用于储存RDF实例数据中的实例与实例所属类的映射关系:Instance_Class={IC1,IC2,...,ICi,...,ICn},其中ICi={I1,I2,...,Ij,...,Im},ICi表示类,Ij表示ICi的一个实例;
Literal_Class用于储存RDF数据图中的文本与包含该文本的实例三元组主语所属类的映射关系:Literal_Class={LC1,LC2,...,LCi,...,LCn},其中LCi={L1,L2,...,Lj,...,Lm},Lj表示一个文本,LCi表示Lj所在实例三元组主语所属的类;
P_C_SO将具有相同谓语且主语所属类相同的实例三元组,存储在同一个Set中,以S,O的形式存储:P_C_SO={PiCj_SO},1≤i≤n,1≤j≤m,n表示属性的个数,m表示属性Pi的定义域中类的个数,其中PiCj_SO={SO1,SO2,...,SOk,...,SOq},SOk=(Sk,Ok),Sk表示谓语为Pi且主语所属类为Cj的实例三元组的主语,Ok表示Sk对应的宾语;
P_C_SO用于存储P_C_SO的反转备份,具有相同谓语且宾语所属类相同的实例三元组,存储在同一个Set中,以O,S的形式存储:P_C_OS={PiCj_OS},1≤i≤n,1≤j≤m,n表示属性的个数,m表示属性Pi的值域中类的个数,其中PiCj_OS={OS1,OS2,…,OSk,…,OSq},OSk=(Ok,Sk),Ok表示谓语为Pi且宾语所属类为Cj的实例三元组的宾语,Sk表示Ok对应的主语。
进一步的,所述步骤S3中三元组连接的内容为:任意两个三元组通过主语、宾语或者其他三元组连接起来,三元组连接的形式化表示:对于模式三元组或者实例三元组集合Set={T1,T2,...,Ti,...,Tm},给定Ti(Si,Pi,Oi)和Tj(Sj,Pj,Oj),其中如果(Si=Sj&&Oi≠Oj)或者(Si=Oj&&Oi≠Sj)或者(Oi=Sj&&Si≠Oj)或者(Oi=Sj&&Si≠Oj),则称Ti与Tj相邻,可以进行三元组连接,所述三元组为模式三元组或实例三元组。
进一步的,所述步骤S4中语义评分函数的具体内容为:设本体子图Gs={T1,T2,...,Ti,...,Tm},该本体子图中包含的类集合C={c1,c2,...,ci,...,cp},该本体子图中包含的属性集合P={p1,p2,...,pi,...,pq},则该本体子图的语义评分函数可以表示为:
其中,CCDis(Gs)=∑i,j∈1,2,...,pdis(ci,cj),
PPDis(Gs)=∑i,j∈1,2,...,qdis(pi,pj)
语义评分函数SSF(Gs)由语义内容CCDis(Gs)和语义结构PPDis(Gs)两部分组成,α是调节参数,当α=0.5时,表示两者的影响程度一样,dis(ci,cj)表示类ci与类cj之间的语义距离:
其中n是这两个类之间最短路径上边的条数,类间距离之和越小,的值越大,说明该本体子图的语义内容越紧密;
dis(pi,pj)表示属性pi与属性pj之间的语义距离:
其中d是这两个属性之间最短路径上模式三元组的个数,属性间距离之和越小,的值越大,说明该本体子图的语义结构与搜索结果越相似。
进一步的,所述步骤S5中Map阶段的具体内容如下:
Map阶段:依据构建好的本体子图,本体子图以模式三元组集合的形式表示,针对本体子图中的每个模式三元组,并行搜索P_C_SO和P_C_OS中与该模式三元组匹配的实例三元组,并将得到的结果传给Reduce阶段。
进一步的,所述步骤S6中Reduce阶段的具体内容如下:
Reduce阶段:接收Map阶段传过来的实例三元组集合,根据本体子图中已有的连接关系,对实例三元组进行三元组连接,得到结果子图并返回。
进一步的,所述步骤S10中本体扩展的具体内容如下:模式三元组上的本体扩展是将本体扩展规则应用在RDF本体信息的上下文中,设onto为RDF数据图的本体,closure(onto)为onto的闭包,给定模式三元组T1,并且如果用以下三条规则的任一规则或者多条规则,可以由T1得到T1′,并且则记为T1∪onto∪rules→T1′,则称T1′是T1的一个近似模式三元组:
rule1(a,sp,b)(x,a,y)→(x,b,y)
rule2(a,sc,b)(a,p,y)→(b,p,y)
rule3(a,sc,b)(x,p,a)→(x,p,b)
其中:sc表示rdfs:subClassOf,sp表示rdfs:subPropertyOf;
本体扩展包括属性扩展和类扩展,类扩展又可以分为对模式三元组的主语或者宾语进行的扩展:
(1)模式三元组谓语的扩展:如果(a,sp,b)∈closure(onto)成立,模式三元组(x,a,y)可扩展为(x,b,y);
(2)模式三元组主语的扩展:如果(a,sc,b)∈closure(onto)成立,模式三元组(a,p,y)可扩展为(b,p,y);
(3)模式三元组宾语的扩展:如果(a,sc,b)∈closure(onto)成立,模式三元组(x,p,a)可扩展为(x,p,b)。
进一步的,所述步骤S11中语义相似度函数的具体内容为:语义相似度计算过程中基于最小公共祖先的概念和语义相似度计算方法完成类节点之间、属性节点之间、模式三元组之间以及本体子图之间的语义相似度计算。
类节点之间的语义相似度
模式三元组中的主语或宾语是一个类,在RDFs本体层次结构中可以看成一个节点,那么初始本体子图上的节点c1和c1扩展后对应的节点c1′之间的语义相似度公式如下:
s(c1,c1′)=d(c1)+d(c1′)-2×d(LCA(c1,c1′)) (4)
其中,d(c)是指节点c在本体层次结构图中的深度。
属性节点之间的语义相似度
模式三元组中的谓语是一个属性,在RDFs本体层次结构中也可以看成一个节点,那么初始本体子图上的属性节点p1和p1扩展后对应的属性节点p1′之间的语义相似度公式s(p1,p1′)与公式(4)类似:
s(p1,p1′)=d(p1)+d(p1′)-2×d(LCA(p1,p1′)) (5)
其中,d(p)是指节点p在本体层次结构图中的深度。
模式三元组之间的语义相似度
设初始本体子图中的模式三元组T1(S1,P1,O1)和近似本体子图中对应的模式三元组T1′(S1′,P1′,O1′),综合公式(4)和(5),本文T1和T1′的语义相似度公式如下:
s(T1,T1′)=s(S1S1′)+s(P1,P1′)+s(O1,O1′) (6)
本体子图之间的语义相似度
设初始本体子图G1={T1,T2,…,Ti,...,Tm}和近似本体子图G1′={T1′,T2′,...,Ti′,...,Tm′},本文G1和G1′的语义相似度公式如下:
初始本体子图与近似本体子图之间的语义相似度越大,说明该近似本体子图与初始本体子图越相似,那么该近似本体子图越优先进行分布式搜索,这样就能保证在返回结果没有达到Top-k的情况下进行的近似分布式搜索,也能返回用户最想要的结果。
本发明与现有技术相比具有以下有益效果:本发明利用Redis数据库集群来存储大规模的RDF数据,借助分布式Hadoop平台中的MapReduce计算框架,提出分布式RDF关键词近似搜索算法DKASR(Distributed Keyword Approximate Search method for RDF),支持对实例、文本、类和属性的搜索。该算法首先结合RDF本体信息构建关键词集合对应的本体子图,利用语义评分函数对生成的本体子图进行排序;接着利用MapReduce计算框架实现分布式搜索,进行连接操作后返回Top-k结果;如果返回的结果没有达到Top-k,则对本体子图进行扩展,得到近似本体子图,再用语义相似度函数对近似本体子图进行排序,然后进行分布式近似搜索,直到返回Top-k结果为止。本文算法解决了海量数据无法快速搜索和搜索效果不理想的问题,并且支持返回用户可能感兴趣的结果,具有深远的理论和实际意义。
附图说明
图1是本发明的算法总体框图。
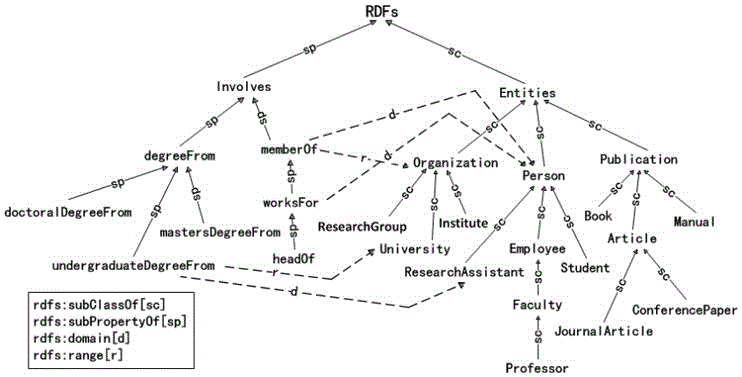
图2是本发明本体层次结构图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
DKASR算法为了避免直接在大规模的RDF数据图上进行耗时的迭代搜索,利用RDF本体的特点构造输入关键词集合对应的本体子图,并且综合考虑语义内容和语义结构对本体子图进行评分排序,评分高的优先进行分布式搜索,然后利用MapReduce计算框架并行搜索返回Top-k结果;如果得到的结果没有达到Top-k,则对本体子图进行扩展,生成近似本体子图,利用语义相似度函数对生成的近似本体子图进行语义相似度评分,评分高的优先进行分布式搜索,直到返回Top-k结果为止。由于RDF本体涵盖了资源和属性的分类及关联,而且RDF本体通常是确定的规模为KB级别的数据,因此构造本体子图或近似本体子图都是非常高效的。
以下给出本文的相关定义。
问题定义:给定关键词集合Q={q1,q2,…,qi,…,qm}和RDF数据图g,根据语义评分函数和语义相似度函数分别对本体子图和近似本体子图进行打分,分布式搜索返回与关键词集合匹配程度最高的Top-k结果。
定义1.实例三元组:设t(s,p,o)表示实例三元组,s∈(I∪B),p∈(I∪B),o∈(I∪B∪L),其中s为主语,p为谓语,o为宾语,I是IRIs顶点集合,B是空白顶点集合,L是文本顶点集合,多个实例三元组组成一个RDF数据图。
定义2.模式三元组:设T(S,P,O)表示模式三元组,S∈D,P∈A,O∈R,其中S为主语,P为谓语,O为宾语,A是RDF本体中定义的属性集合,属性有对象属性和数据属性两类,D是RDF本体中定义的属性的定义域集合,R是RDF本体中定义的属性的值域集合。
定义3.本体扩展:模式三元组上的本体扩展是将本体扩展规则应用在本体的上下文中。设onto为RDF数据图的本体,closure(onto)为onto的闭包,给定模式三元组T1,并且如果用以下三条规则的任一规则或者多条规则,可以由T1得到T1′,并且则记为T1∪onto∪rules→T1′,则称T1′是T1的一个近似模式三元组:
rule1(a,sp,b)(x,a,y)→(x,b,y)
rule2(a,sc,b)(a,p,y)→(b,p,y)
rule3(a,sc,b)(x,p,a)→(x,p,b)
其中:sc表示rdfs:subClassOf,sp表示rdfs:subPropertyOf;
本体扩展包括属性扩展和类扩展,类扩展又可以分为对模式三元组的主语或者宾语进行的扩展:
(1)模式三元组谓语的扩展如果(a,sp,b)∈closure(onto)成立,模式三元组(x,z,y)可扩展为(x,b,y)。
(2)模式三元组主语的扩展如果(a,sc,b)∈closure(onto)成立,模式三元组(a,p,y)可扩展为(b,p,y)。
(3)模式三元组宾语的扩展如果(a,sc,b)∈closure(onto)成立,模式三元组(x,p,a)可扩展为(x,p,b)。
定义4.近似模式三元组:对于给定的模式三元组T,通过应用定义3进行扩展得到T′,则称T′为T的一个近似模式三元组。
定义5.RDF数据图:设g={t1,t2,...,ti,...,tn}表示RDF数据图,RDF数据图由实例三元组组成。每个实例三元组ti(si,pi,oi)中的主语si和宾语oi作为g中的节点,谓语pi作为由主语节点指向宾语节点的一条有向边。
定义6.本体图:设G={T1,T2,...,Ti,...,Tn}表示本体图,本体图由模式三元组组成,是RDF本体的三元组表现形式。每个模式三元组Ti(Si,Pi,Oi)中的主语Si和宾语Oi作为G中的节点,谓语Pi作为由主语节点指向宾语节点的一条有向边。
定义7.本体子图:设Gs={T1,T2,...,Ti,...,Tm}表示本体子图,本体子图是将所有关键词匹配的模式三元组按照定义10进行连接构成的子图。已知关键词集合Q={q1,q2,...,qi,...,qk}和本体图G={T1,T2,...,Ti,...,Tn},对于Q中的每个关键词qi(1≤i≤k),首先将qi映射成对应的类ci或者属性pi;然后在G中搜索包含ci或者pi的模式三元组,并将匹配的模式三元组加入集合Set={T1,T2,...,Ti,...,Tr},对于集合Set中的模式三元组Ti(Si,Pi,Oi)和Tj(Sj,Pj,Oj),其中有Si≠Sj&&Pi≠Pj&&Oi≠Oj;最后依次从Set中取出模式三元组按照定义10进行连接,形成本体子图Gs。Gs以模式三元组集合的形式表示,两个模式三元组集合中的三元组不完全相同,则认为是不同的本体子图。
定义8.近似本体子图:对于给定的本体子图Gs,通过应用定义3对本体子图中至少一个模式三元组进行扩展得到Gs′,则称Gs′为Gs的一个近似本体子图。
定义9.结果子图:设gs={t1,t2,...,ti,...,tm}表示结果子图,结果子图是本体子图或者近似本体子图在RDF数据图中分布式搜索的结果,是由所有关键词匹配的实例三元组按照定义10进行连接构成的子图,包含了关键词集合中所有的关键词。结果子图以实例三元组集合的形式表示,两个实例三元组集合中的三元组不完全相同,则认为是不同的结果子图。
定义10.三元组连接:在构造本体子图或者结果子图的时候,对于匹配的模式三元组或者实例三元组要进行三元组连接操作,其中任意两个三元组通过主语、宾语或者其他三元组连接起来。三元组连接的形式化表示:对于模式三元组或者实例三元组集合Set={T1,T2,...,Ti,...,Tm},给定Ti(Si,Pi,Oi)和Tj(Sj,Pj,Oj),其中如果(Si=Sj&&Oi≠Oj)或者(Si=Oj&&Oi≠Sj)或者(Oi=Sj&&Si≠Oj)或者(Oi=Oj&&Si≠Sj),则称Ti与Tj相邻,可以进行三元组连接。
定义11.语义评分函数:对于得到的多个本体子图,本文利用语义评分函数进行打分,得分高的优先进行分布式搜索。设本体子图Gs={T1,T2,...,Ti,...,Tm},该本体子图中包含的类集合C={c1,c2,...,ci,...,cp},该本体子图中包含的属性集合P={p1,p2,...,pi,...,pq},则该本体子图的语义评分函数可以表示为:
其中,CCDis(Gs)=∑i,j∈1,2,...,pdis(ci,cj),
PPDis(Gs)=∑i,j∈1,2,...,qdis(pi,pj)
语义评分函数SSF(Gs)由语义内容CCDis(Gs)和语义结构PPDis(Gs)两部分组成。α是调节参数,当α=0.5时,表示两者的影响程度一样。dis(ci,cj)表示类ci与类cj之间的语义距离:
其中n是这两个类之间最短路径上边的条数。类间距离之和越小,的值越大,说明该本体子图的语义内容越紧密。
dis(pi,pj)表示属性pi与属性pj之间的语义距离:
其中d是这两个属性之间最短路径上模式三元组的个数。属性间距离之和越小,的值越大,说明该本体子图的语义结构与用户想要的搜索结果越相似。利用语义评分函数SSF(Gs),使得评分高的本体子图优先进行分布式搜索。
定义12.语义相似度函数:本文利用语义相似度函数来衡量初始本体子图与扩展后的近似本体子图之间的相似程度,相似度越大的越优先执行分布式搜索。语义相似度计算过程中涉及类节点之间、属性节点之间、模式三元组之间以及本体子图之间的语义相似度计算。本文最小公共祖先(Least Common Ancestor,LCA)的概念和语义相似度计算方法来完成本文的语义相似度计算。
类节点之间的语义相似度
模式三元组中的主语或宾语是一个类,在RDFs本体层次结构中可以看成一个节点,那么初始本体子图上的节点c1和c1扩展后对应的节点c1′之间的语义相似度公式如下:
s(c1,c1′)=d(c1)+d(c1′)-2×d(LCA(c1,c1′)) (4)
其中,d(c)是指节点c在本体层次结构图中的深度。
属性节点之间的语义相似度
模式三元组中的谓语是一个属性,在RDFs本体层次结构中也可以看成一个节点,那么初始本体子图上的属性节点p1和p1扩展后对应的属性节点p1′之间的语义相似度公式s(p1,p1′)与公式(4)类似:
s(p1,p1′)=d(p1)+d(p1′)-2×d(LCA(p1,p1′)) (5)
其中,d(p)是指节点p在本体层次结构图中的深度。
模式三元组之间的语义相似度
设初始本体子图中的模式三元组T1(S1,P1,O1)和近似本体子图中对应的模式三元组T1′(S1′,P1′,O1′),综合公式(4)和(5),本文T1和T1′的语义相似度公式如下:
s(T1,T1′)=s(S1,S1′)+s(P1,P1′)+s(O1,O1′) (6)
本体子图之间的语义相似度
设初始本体子图G1={T1,T2,...,Ti,...,Tm}和近似本体子图G1′={T1′,T2′,...,Ti′,...,Tm′},本文G1和G1′的语义相似度公式如下:
本文中,初始本体子图与近似本体子图之间的语义相似度越大,说明该近似本体子图与初始本体子图越相似,那么该近似本体子图越优先进行分布式搜索,这样就能保证在返回结果没有达到Top-k的情况下进行的近似分布式搜索,也能返回用户最想要的结果。
请参照图1,本发明提供一种结合Redis内存数据库的分布式RDF关键词近似搜索方法,其特征在于,包括以下步骤:
步骤S1:对RDF本体和RDF实例数据进行预处理,并生成相应的文件;
步骤S2:结合Redis分布式数据库集群的特点,将步骤S1中生成的文件内容分门别类地存储在Redis数据库集群的Set集合中;
步骤S3:根据RDF本体信息和输入的关键词集合Q,先把关键词映射成对应的类或属性,然后在本体图上找到类或属性匹配的模式三元组,对所述模式三元组进行三元组连接,生成关键词集合对应的本体子图;
步骤S4:利用语义评分函数对构建的本体子图进行打分并排序,得分高的优先进行分布式搜索,跳到步骤S5;
步骤S5:Map阶段搜索本体子图中各个模式三元组对应的实例三元组;
步骤S6:Reduce阶段则将接收到的实例三元组进行连接,得到结果子图,并返回结果子图;
步骤S7:判断结果子图中的实例三元组是否达到k条,如果已经达到,则结束搜索,跳到步骤S12,否则跳到步骤S8;
步骤S8:判断是否还有本体子图没有进行分布式搜索,如果有,则跳到步骤S4,否则跳到步骤S9;
步骤S9:判断是否有扩展后的近似本体子图未进行分布式搜索,如果有,则跳到步骤S11,否则跳到步骤S10;
步骤S10:根据本体扩展规则按步骤S4中的排序对本体子图进行扩展并生成近似本体子图,跳到步骤S11;
步骤S11:利用语义相似度函数对生成的近似本体子图进行打分并排序,得分高的优先进行分布式搜索,跳到步骤S5;
步骤S12:算法结束。
其具体内容如下:
步骤S1-步骤S2:DKASR算法利用Redis内存数据库集群作为数据存储的媒介,集群中Redis内存数据库的个数可以根据需求动态增减。由于Redis中对Set集合的添加、删除和查找的复杂度都是O(1),本步骤将RDF本体信息和大规模的RDF实例数据进行预处理,分别生成实例数据文件和本体信息文件,分门别类地存储在Redis内存数据库集群的Set集合中;具体存储方案如下表所示:
其中,Class、Property、Onto Triple和Onto Triple_Reverse集合用来存储RDF本体的信息。根据存储的本体信息、Instance_Class和Literal_Class集合中的信息可以快速判断输入的关键词是类、属性、实例还是文本,并且可以快速定位到每个关键词匹配的模式三元组,为构建本体子图做好准备。Class_Sup用来存储类的父类信息,Property_Sup用来存储属性的父属性信息,在使用定义3进行本体扩展时,根据Class_Sup和Property_Sup集合可以将本体子图扩展为近似本体子图。P_C_SO和P_C_OS用来存储RDF实例数据,在进行分布式搜索时,根据本体子图中模式三元组的信息,可以大大缩小搜索范围并且能够快速搜索到每个模式三元组对应的实例三元组,做到高效的分布式并行搜索。
步骤S3:根据RDF本体信息的语义结构特征Q,先把关键词映射成对应的类或属性,然后在本体图上找到类或属性匹配的模式三元组,对所述模式三元组进行三元组连接(请参照定义10),生成本体子图;
步骤S4:由于关键词对应的类或属性可能存在多个,因此会生成多个本体子图,利用语义评分函数(即定义11)对每个本体子图进行评分,评分高的优先进行分布式搜索,所述分布式搜索包括Map阶段和Reduce阶段,跳到步骤S5并在大规模的RDF数据图中搜索本体子图匹配的结果子图;因为RDF本体图是RDF数据图的浓缩摘要,涵盖了资源和属性的分类及关联,而且规模大小一般都为KB级别的(RDF本体中定义的类和属性个数一般是几十到几百级别的),通过本体可以推导出任意两个类或者属性的关联关系,并且可以快速构建出关键词集合对应的本体子图,确定关键词之间的关系。在RDF本体图上先进行搜索和连接操作,会大大减少耗时,提高搜索效率。
于本实施例中,步骤S3至步骤S4的过程如算法1所示:
算法1:为输入的关键词集合构建本体子图算法
输入:关键词集合Q,RDF本体信息OntoInfo
输出:排好序的本体子图大堆
其伪代码如下所示:
为了能快速地从大规模的RDF数据图中搜索出结果子图,本文借助MapReduce并行计算模型来完成分布式的搜索。MapReduce的每个作业包括两个阶段:Map阶段和Reduce阶段。Map阶段会根据某个元素的键值对(key/value)输入数据并进行划分;Reduce阶段将相同的key进行合并产生输出结果。
本文的Map阶段搜索本体子图中每个模式三元组匹配的实例三元组,Reduce阶段则完成实例三元组的连接操作并且返回结果子图。
步骤S5:Map阶段:依据依据构建好的本体子图,本体子图以模式三元组集合的形式表示,针对本体子图中的每个模式三元组,并行搜索P_C_SO和P_C_OS中与该模式三元组匹配的实例三元组,并将得到的结果传给Reduce阶段;
Map阶段的具体过程如算法3所示。
算法3:Map阶段
输入:key为行号,value为本体子图的标记与模式三元组的组合
输出:key为本体子图的标记,value为实例三元组集合
其伪代码如下所示:
步骤S6:Reduce阶段:接收Map阶段传过来的实例三元组集合,根据本体子图中已有的连接关系,对实例三元组进行三元组连接,得到结果子图并返回。
Reduce阶段的具体过程如算法4所示。
算法4:Reduce阶段
输入:算法3的输出
输出:key为结果子图,value为任意值
其伪代码如下所示:
目前的关键词搜索中是假定用户明确自己的搜索意图,但是实际上用户对本体的结构和内容有可能并不了解,不同的用户对同一事物的描述可能存在差异,用户可能也不明确自己的搜索意图。在这种情况下即使用户使用了明确的搜索关键词,搜索中仍然有可能返回空或少量的搜索结果。同时,在大多数情况下用户很难通过几个简单的关键词准确真实地表达自己的搜索需求,因此这可能导致搜索的结果和用户需求之间存在一定的差异。
步骤S7:对于初始本体子图中的一个模式三元组,该模式三元组中的主语或宾语表示的是一个类,谓语表示的是一个属性。在上文进行分布式搜索时,若结果子图中实例三元组达到k条,则搜索结束,跳到步骤S12;若结果子图中实例三元组的数量未达到k条,则跳到步骤S8;则对初始本体子图中的模式三元组按照定义3进行本体扩展,那么类可以扩展为其对应的超类,属性可以扩展为其对应的超属性,相应地就得到近似模式三元组;
步骤S8:判断是否还有本体子图没有进行分布式搜索,若有则跳到步骤S4,否则跳到步骤S9;
步骤S9:判断是否有扩展后的近似本体子图未进行分布式搜索,若有则跳到步骤S11,否则跳到步骤S10;
步骤S10:对所述近似模式三元组进行三元组连接,由于扩展方式的多样性,生成多个近似本体子图;
步骤S11:通过语义相似度函数(即定义12)对每个近似本体子图进行评分,评分高的优先进行分布式搜索,这样就能有效地返回与用户意图相近、用户可能感兴趣的结果即结果子图并返回步骤S5。
构建所述近似本体子图的过程如算法2所示:
算法2:构建近似本体子图算法
输入:算法1的输出H1
输出:排好序的近似本体子图大堆集合,集合中每个大堆存储H1中本体子图对应的近似本体子图
其伪代码如下所示:
步骤S11中的定义12是用来衡量初始本体子图与近似本体子图之间的语义相似程度。两个本体子图的语义相似度越大,说明二者越相似,即在语义上具有越强的相似性。语义相似度的计算主要考虑RDFs所体现的本体层次结构,如图2所示。RDF本体中定义了类与属性、值域与定义域在属性上的约束以及子类与子属性的包蕴关系,通过对RDF本体的分析,可以推导得到类与类、类与属性以及属性与属性之间的语义关联。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!