一种基于TF‑IDF特征提取的短文本分类方法与流程
本发明涉及数据处理领域,尤其是一种基于TF-IDF特征提取的短文本分类方法。
背景技术:
随着社交媒体的兴起,移动短信、Tweet和微博等短文本层出不穷。由于参与者多以及发布频率快,短文本的规模飞速增长。此外,短文本在搜索引擎、自动问答和话题跟踪等领域发挥着重要的作用。而且,随着电子政务建设的推行和不断深化,政府部门也面临着对大量短文本的处理问题。但由于短文本内容较少,特征不明显,因此在短文本数据的处理中,如何实现对大量短文本数据进行简便、有效地分类具有重要的意义。
现有技术中与本发明最相近的一种实现方式是一种电力营销服务热点95598工单自动分类方法(CN105760493A),其方法步骤流程如图1所示,该发明公开了一种电力营销服务热点95598工单自动分类方法,在TF-IDF方法中引入了“增量”和“归一化”概念,把“增量”和“归一化”作为一个变量考虑在特征向量权重的计算过程中,在此基础上针对电力营销服务热点95598工单进行特征选择,并以服务热点为基点形成训练集,再对比多种文本挖掘和分类算法,选择分类效果最佳的算法,形成分类器模型,并对95598工单进行分类处理,能够及时挖掘出电力营销的服务热点事件,支撑电力营销的精益化管理。
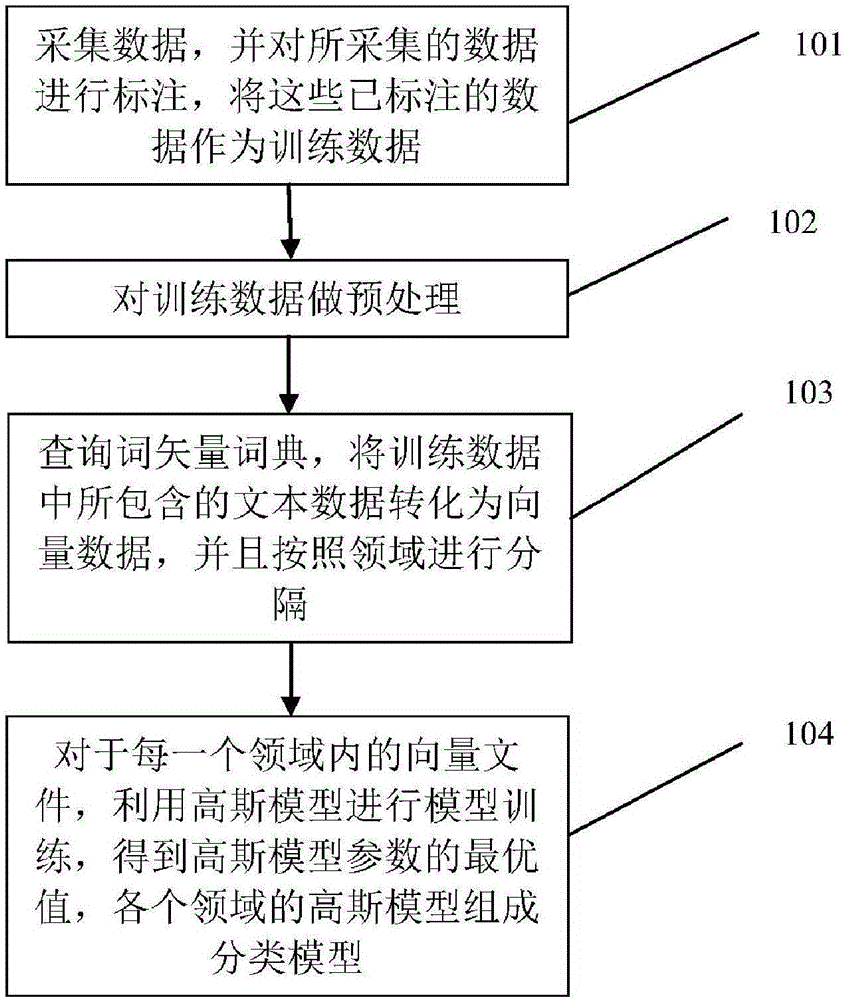
现有技术中与本发明最相近的另一实现方式是一种基于词矢量的短文本分类模型生成方法与分类方法(CN105335446A),其方法步骤流程如图2所示,该发明涉及一种基于词矢量的短文本分类模型生成方法,包括:采集数据,并对所采集的数据进行领域标注,将这些已标注的数据作为训练数据;对训练数据做预处理;查询词矢量词典,将训练数据中所包含的文本数据转化为向量数据,并且将所述向量数据按照领域进行分隔;对每一个领域内的向量数据采用高斯模型进行模型训练,得到高斯模型参数的最优值,从而得到该领域所对应的高斯模型;所有训练数据的各个领域所对应的高斯模型组成分类模型。
结合上述现有技术分析可知,在短文本分类方法中,TF-IDF算法的实际应用效果不佳。短文本中文本特征较少,而且在应用TF-IDF算法提取文本特征时,同类的短文本数据集中具有相同关键词的文本会相互干扰,使得这些关键词计算出来的TF-IDF值大大降低,因此也弱化了这些词对同类的短文本特征表达效果,进而影响了后续分类的效果。而且现有的技术方案依赖于其他词库或者词向量词典等外部资源。如果查询其他词库,需要事先建立该词库;而如果查询词向量词典,则需要一个较大的语料库预先训练出一个词向量词典。如果无法获得这些外部资源,也没有足够的内部资源去预先建立词库和训练词向量词典,则这些技术解决方案无法取得一个较好的解决效果。
技术实现要素:
为了解决上述技术问题,本发明的目的是:提供一种基于TF-IDF特征提取实现无需依赖外部语料库的短文本分类方法。
本发明所采用的技术方案是:一种基于TF-IDF特征提取的短文本分类方法,包括有以下步骤:
A、从总体数据集中抽取短文本数据作为SVM分类器的训练数据,根据分类需求对抽取出来的数据进行分类标注,然后进行分词;
B、根据上述步骤的分类标注抽取数据,并将每一类中的数据按比例随机分为两组,分别作为训练集和测试集,然后将训练集中每一类的所有短文本数据分类拼接成长文本数据,计算出长文本数据对应的TF-IDF特征矩阵;
C、建立一个空的词列表和空的特征词典,根据设定的关于TF-IDF值的阈值k,将每一类的长文本中对应的TF-IDF值大于k的词加入到词列表中,并将该词及其对应的TF-IDF值加入到特征词典中;
D、将训练集中每一条短文本数据映射到词列表中,得到文本特征向量;
E、将训练集和测试集对应的数据生成的文本特征向量,进行SVM分类器的训练,记录总体分类准确率和每一类的分类准确率;
F、调节参数并重复执行步骤C~E,直至分类准确率不再提升,其中参数包括阈值k;
G、根据最后得到的参数保存SVM分类器,用于后续总体数据集的分类。
进一步,所述步骤A中采用结巴分词方法进行分词。
进一步,所述步骤B中将每一类中的数据按2:1比例随机分为训练集和测试集。
进一步,所述步骤C中将词及其对应的TF-IDF值加入特征词典时,如果该词已存在并且该词在目前长文本中对应的TF-IDF值高于该词在特征词典中的值,则将特征词典中的值替换为该词在目前长文本中对应的TF-IDF值。
进一步,所述步骤C还包括:根据设定的关于词数的阈值n,统计每一类数据中被抽取出来加入词列表的词的个数,若某一类被提取出来的词数少于n个,则将该类的长文本对应TF-IDF特征矩阵的值进行降序排序,将前n个词里未被抽取的词抽取出来加入到词列表及特征词典中。
进一步,所述步骤D具体为:对于训练集中每一条短文本,建立一个与词列表长度相同的向量,向量中所有值的初始值都设为0;遍历该短文本包含的所有词,若某个词存在于词列表,则对应词的位置的值改为该词在特征词典中的值,最后得到文本特征向量。
进一步,所述步骤D还包括:将文本特征向量乘以参数λ。
进一步,所述步骤F中的调节参数还包括有阈值n。
进一步,所述步骤F中的调节参数还包括有λ。
本发明的有益效果是:本发明通过将短文本合并成长文本增强短文本的TF-IDF特征,并利用设定的一个关于TF-IDF值的阈值k降维生成特征词列表和特征词字典;同时在建立特征词列表时,利用设定一个关于每一类数据被抽取词数的阈值n对特征相对不明显的类别建立补偿机制,并增强文本特征向量权重,不需要预先构建或训练其他词库或词向量词典,从而能在保证文本特征表达效果的前提下大幅提升算法性能。
附图说明
图1为一种现有技术方案的步骤流程图;
图2为另一现有技术方案的步骤流程图;
图3为本发明方法的步骤流程图;
图4为参数k调优的具体步骤流程图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步说明:
参照图3,一种基于TF-IDF特征提取的短文本分类方法,包括有以下步骤:
步骤A:数据集标注和预处理
从总体数据集中抽取短文本数据作为SVM分类器的训练数据,根据分类需求对抽取出来的数据进行分类标注,然后进行分词,将短文本数据分为多个词;
进一步作为优选的实施方式,所述步骤A中采用结巴分词方法进行分词。
步骤B:计算分类增强的TFIDF向量
根据上述步骤的分类标注抽取数据,并将每一类中的数据按比例随机分为两组,分别作为训练集和测试集,然后将训练集中每一类的所有短文本数据分类拼接成长文本数据,计算出长文本数据对应的TF-IDF特征矩阵;
训练集中每一类的数据都有两种形式,一种是多个短文本,另一种则是上述拼接而成的一条长文本数据。对每一类的长文本数据采用TF-IDF算法计算出对应的TF-IDF特征矩阵。在该矩阵中,每一行对应一个类别的长文本数据,每个值代表该行对应的某一类文本中某个词的TF-IDF特征值。
进一步作为优选的实施方式,所述步骤B中将每一类中的数据按2:1比例随机分为训练集和测试集。
步骤C:生成特征词列表和特征词典
建立一个空的词列表和空的特征词典,根据设定的关于TF-IDF值的阈值k,将每一类的长文本中对应的TF-IDF值大于k的词加入到词列表中,并将该词及其对应的TF-IDF值加入到特征词典中。
进一步作为优选的实施方式,所述步骤C中将词及其对应的TF-IDF值加入特征词典时,如果该词已存在并且该词在目前长文本中对应的TF-IDF值高于该词在特征词典中的值,则将特征词典中的值替换为该词在目前长文本中对应的TF-IDF值。
进一步作为优选的实施方式,所述步骤C还包括:根据设定的关于词数的阈值n,统计每一类数据中被抽取出来加入词列表的词的个数,若某一类被提取出来的词数少于n个,则将该类的长文本对应TF-IDF特征矩阵的值进行降序排序,将前n个词里未被抽取的词抽取出来加入到词列表及特征词典中。
步骤D:建文本特征向量
将训练集中每一条短文本数据映射到词列表中,得到文本特征向量;
对于训练集中每一条短文本,建立一个与词列表长度相同的向量,向量中所有值的初始值都设为0;遍历该短文本包含的所有词,若某个词存在于词列表,则对应词的位置的值改为该词在特征词典中的值,最后得到文本特征向量。
进一步作为优选的实施方式,所述步骤D还包括:将文本特征向量乘以参数λ,新的文本特征向量中非零值得到增强,具有更突出的特征表达效果。
步骤E:训练SVM分类器
将训练集和测试集对应的数据生成的文本特征向量,进行SVM分类器的训练,记录总体分类准确率和每一类的分类准确率;
步骤F:参数调优
调节参数并重复执行步骤C~E,直至分类准确率不再提升,其中参数包括阈值k,参照图4,具体的参数调优可采用以下步骤:
参数k调优:设K0为0,将步骤B中TF-IDF特征矩阵的最大值设为k10,再将k0和k10的差除以10,再分别乘以1、2、3、4、5、6、7、8、9,再加上K0,得到k1、k2、k3、k4、k5、k6、k7、k8、k9,对每一个k值(从k0到k10)重复执行步骤C~E,统计得到的分类准确率结果。然后设其中准确率最高的结果所对应的k值为kn, 将kn-1和kn+1分别作为新的k0和k10,并按上述方法计算新的k1、k2、k3、k4、k5、k6、k7、k8、k9,继续重复执行步骤C~E并统计分类结果。然后进行下一轮的迭代,直到最佳的分类准确率不再提升,此时得到的k值作为最优k值用于后续实验。计算得到分类准确率前后之差小于某个设定的阈值即可认为分类准确率不再提升。
进一步作为优选的实施方式,所述步骤F中的调节参数还包括有阈值n。
参数n调优的具体步骤与参数k的调优步骤类似,可采用以下步骤:分析步骤B中得到的TF-IDF特征矩阵中,每一类中大于等于上述最优阈值k值的词的个数,将最低的词数作为n的初始值,重复执行步骤C~E,统计得到的总体分类准确率结果。然后将n的值加10作为新的n值,继续迭代,直到总体分类准确率不再有明显提升。然后将n的值减10,再继续每次加1作为新的n值进行下一轮迭代,直到总体分类准确率不再有明显提升,此时得到的n值作为最优n值用于后续计算。
此外,若要提升某一类的分类效果,可对n值继续作类似调整,直到该类的分类准确率不再有明显提升。
进一步作为优选的实施方式,所述步骤F中的调节参数还包括有λ,参数λ的调优可采用以下步骤:
设λ的初始值为1,重复执行步骤C~E,统计得到的分类准确率结果。然后将λ的值乘以10作为新的λ值,继续迭代,直到分类准确率不再有明显提升。然后将λ的值除以10,再继续每次乘以3作为新的λ值进行下一轮迭代,直到分类准确率不再有明显提升。接下来将λ的值除以3,再继续每次加1作为新的λ值进行下一轮迭代,直到分类准确率不再有明显提升,此时得到的λ值作为最优λ值用于后续计算。
步骤G:保存SVM分类模型
根据最后得到的参数保存SVM分类器,即利用上述步骤F得到的最优参数值执行步骤C~E,保存得到的SVM分类器模型参数用于后续总体数据集的分类。
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可以作出种种的等同变换或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!