一种数据存储方法、装置及通信网关机与流程
本发明属于智能变电站数据通信领域,具体涉及一种数据储存方法、装置及通信网关机。
背景技术:
近几年,智能变电站处理的数据体量从TB级别跃升到PB级别,电力数据类型也从单一的结构化数据变为多样的结构化数据、半结构化数据和非结构化数据,因此,智能变电站的电力数据的存储面临着体量巨大、类型繁多的困难。
目前,数据的存储一般采用关系数据库,按照一定的关系规则对相应的数据进行分析、查询等处理,传统的关系数据库只能处理含有固定字段的结构化数据,并不能处理包含主题、关键词、描述等信息的半结构化数据和包含文件属性、文件后缀等信息的非结构化数据。
技术实现要素:
本发明的目的是提供一种数据存储方法、装置及通信网关机,用于解决面向结构化数据存储的关系型数据库不能处理半结构化数据和非结构化数据的问题。
为解决上述技术问题,本发明提出一种数据存储方法,包括以下步骤:
1)根据数据源的类型创建三个基类,分别为结构化数据类、半结构化数据类、非结构化数据类;
2)将接收的数据源通过聚类算法分成结构化数据、半结构化数据和非结构化数据三类;
3)分类后的数据源与所述基类匹配,当数据源与所述基类匹配一致时,创建数据对象,或者通过该数据源所属的基类派生出新的数据类型,并根据新的数据类型创建数据对象;
4)建立所述数据对象与关系数据库的映射关系,将数据源按照该映射关系存储到相应的关系数据库中,实现分类存储。
将所述数据对象切分成粒度均匀的元数据存储到相应的关系数据库。
当数据源与其对应基类的匹配度超过设定的百分值时,且当该数据源包含对应基类不具有的属性时,通过该数据源对应的基类派生出新的数据类型,并根据新的数据类型创建数据对象;
当数据源与其对应基类的匹配度超过设定的百分值时,且当该数据源不存在对应基类不具有的属性时,通过该数据源对应的基类直接创建数据对象。
为解决上述技术问题,本发明还提出一种通信网关机,包括:
基类创建单元:根据数据源的类型创建三个基类,分别为结构化数据类、半结构化数据类、非结构化数据类;
分类单元:将接收的数据源通过聚类算法分成结构化数据、半结构化数据和非结构化数据三类;
匹配单元:分类后的数据源与所述基类匹配,当数据源与所述基类匹配一致时,创建数据对象;当数据源与所述基类匹配不一致时,通过该数据源所属的基类派生出新的数据类型,根据新的数据类型创建数据对象;
映射单元:建立所述数据对象与关系数据库的映射关系,将数据源按照该映射关系存储到相应的关系数据库中,实现分类存储。
还包括用于将所述数据对象切分成粒度均匀的元数据存储到相应关系数据库的单元。
当数据源与其对应基类的匹配度超过设定的百分值时,且当该数据源包含对应基类不具有的属性时,通过该数据源对应的基类派生出新的数据类型,并根据新的数据类型创建数据对象;
当数据源与其对应基类的匹配度超过设定的百分值时,且当该数据源不存在对应基类不具有的属性时,通过该数据源对应的基类直接创建数据对象。
为解决上述技术问题,本发明还提出一种数据存储装置,包括结构化数据库群、半结构化数据库群和非结构化数据库群,根据通信网关机建立的映射关系存储相应的数据。
所述各个数据库群都至少包括两个数据库。
本发明的有益效果是:本发明提出一种数据存储方法、装置及通信网关机,该方法根据数据的三种类型即结构化数据、半结构化数据和非结构化数据分别创建基类,每种数据源对基类进行继承并创建数据对象,最终通过数据对象与关系数据库的映射关系实现海量数据的分布式存储。
附图说明
图1是本发明一种通信网关机的数据存储架构图;
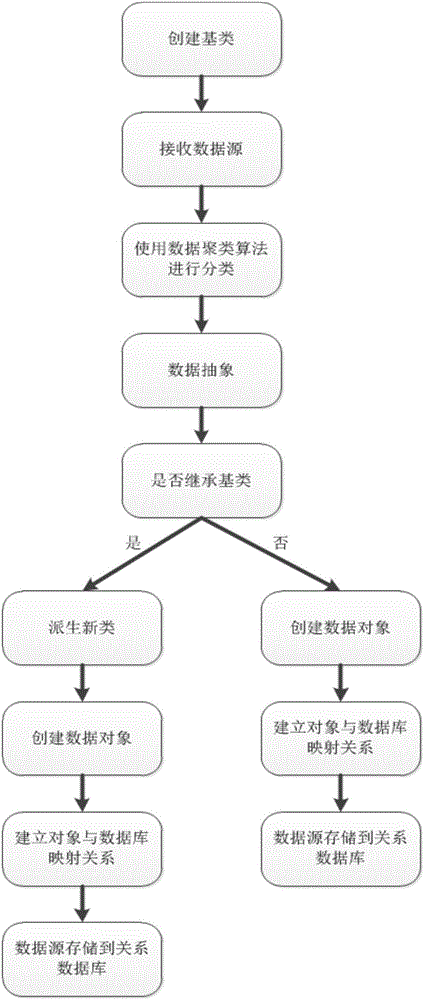
图2是本发明一种数据存储方法流程图;
图3是数据源应用聚类算法进行分类的流程图;
图4是数据源分布式存储示意图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步的说明。
本发明的一种通信网关机的实施例,包括基类创建单元、分类单元、匹配单元和映射单元,还包括用于将映射单元中数据对象切分成粒度均匀的元数据存储到关系数据库的单元,具体地:
基类创建单元:根据电力系统中数据源的类型,利用面向对象的思想创建三个基类,分别为结构化数据类、半结构化数据类、非结构化数据类,每个基类根据自身的特点包含特定属性及方法。其中,结构化数据类包含固定字段、关系数据库操作方法等信息,半结构化数据类包含主题、关键词、描述等信息,非结构化数据类中包含文件属性、文件后缀等信息。
分类单元:将接收的数据源通过聚类算法分成结构化数据、半结构化数据和非结构化数据三类,具体方法如下:
首先,将数据源的属性与非结构化数据类中的属性进行匹配,匹配的内容包括文件后缀名、文件属性等信息,如果非结构化数据类中后缀名组中包含数据源的文件后缀名且文件属性一致则匹配成功;
其次,当数据源与非结构化数据类没有匹配成功时,再将该数据源的属性与半结构化数据类进行属性匹配,如果数据源的主题、关键字、或描述信息与半结构化数据类的相关属性有一组匹配成功,则此数据属于半结构化数据类型;
最后,如果数据源与以上两种数据类都匹配失败,则将该数据源的属性与结构化数据类的字段属性进行匹配,如果匹配成功则此数据属于结构化数据类型;当以上三种数据类型均未匹配成功时,则认为该数据源没有存储的价值,将此数据源删除。
匹配单元:分类后的数据源与所述基类匹配,当数据源与所述基类匹配一致时,创建数据对象;当数据源与所述基类匹配不一致时,通过该数据源所属的基类派生出新的数据类型,根据新的数据类型创建数据对象。
具体的,当数据源与其对应基类的匹配度超过设定的百分值时,且当该数据源包含对应基类不具有的属性时,即数据源中的一小部分属性基类中没有涵盖到,需要通过该数据源对应的基类派生出新的数据类型,并根据新的数据类型创建数据对象,创建成功后便实例化数据对象存储到内存中。
当数据源与其对应基类的匹配度超过设定的百分值时,且当该数据源不存在对应基类不具有的属性时,通过该数据源对应的基类直接创建数据对象。为了使数据源是否继承或创建对象有一个清晰地判断,这里设定一个百分比,如果与基类60%的属性匹配成功则进行继承基类操作。
映射单元:以映射表的形式建立上述数据对象与关系数据库的映射关系,将数据源按照该射关系存储于数据存储装置,映射表的内容包括数据类型、数据属性、数据库群ID、数据库名称、数据库地址、表名称等信息。
上述数据存储装置是以关系数据库的形式存储的,包括三类数据库群,分别为结构化数据库群、半结构化数据库群和非结构化数据库群,不同的数据类型存放在不同的数据库群中。
为了减轻单个数据库的存储压力,需要在数据存储装置的每个数据库群中至少设置两个数据库,在数据网关机中设置用于将映射单元中数据对象切分成粒度均匀的元数据存储到关系数据库的单元,达到数据库负载均衡的目的。
本发明的一种数据存储方法的实施例,包括以下步骤:
1)根据数据源的类型创建三个基类,分别为结构化数据类、半结构化数据类、非结构化数据类;
2)将接收的数据源通过聚类算法分成结构化数据、半结构化数据和非结构化数据三类;
3)分类后的数据源与所述基类匹配,当数据源与所述基类匹配一致时,创建数据对象,或者通过该数据源所属的基类派生出新的数据类型,并根据新的数据类型创建数据对象;
4)建立所述数据对象与关系数据库的映射关系,将数据源存储到关系数据库。
本发明的一种数据存储装置的实施例:
包括结构化数据库群、半结构化数据库群和非结构化数据库群,根据通信网关机建立的映射关系存储相应的数据。
本发明的数据存储方法及装置已经在一种数据网关机的实施例中进行了详细的介绍,这里不再对数据存储方法及装置的实施例进行详细描述。
- 还没有人留言评论。精彩留言会获得点赞!