计算机文本的特征选择方法、分类特征选择方法及系统与流程
本发明涉及一种人工智能领域,涉及一种计算机文本检索分类特征选择方法及系统。
背景技术:
随着信息技术的发展以及Internet的迅速普及,网络信息资源急剧增长,这些网络信息大多是以计算机文本的形式涌现,而计算机文本大多是非结构化的,需要对文本数据进行预处理,把非结构化的文本数据转变为结构化的形式,特征选择通过删除对文本分类没有多大贡献的特征词条,从而选择出对文本或类别具有较好代表性的特征词条。因此,对计算机文本进行特征选择方法是十分必要的。
技术实现要素:
本发明的目的是提供一种效率高、特征提取率高的计算机文本的特征选择方法。
为了解决上述技术问题,本发明提供了一种计算机文本的特征选择方法,包括如下步骤:
步骤S1,对计算机文本进行处理,得到文本的三维特征数据集;
步骤S2,计算文本的三维特征数据集的重构系数矩阵,并且计算信息熵向量;
步骤S3,按照信息熵向量以及重构系数矩阵计算综合度量指标,并且按照综合度量指标从小到大的顺序进行特征选择;以及
步骤S4,输出经过特征选择获得的文本特征集。
进一步,步骤S1中对计算机文本进行处理,得到文本的特征数据集包括:
对计算机文本进行处理,将其断开并处理成词语集合,以词性作为特征对词语集合进行分类,得到词语集合的类别,将同一个词性的词语分为一类,词性被分为动词、名词、形容词或副词,将词语集合中的词语映射为坐标上的点,坐标上的横坐标为词语集合中的词语在计算机文本中出现的次数,坐标上的纵坐标为词语集合中的词语在其类别中出现的次数,将坐标的值记录,得到文本的三维特征数据集;即
文本的三维特征数据集的数据为三维坐标,一维坐标为词语集合的类别,一维坐标为词语集合在计算机文本中出现的次数,一维坐标为词语集合的类别词语集合中的词语在其类别中出现的次数;
进一步,步骤S2中计算文本的三维特征数据集的重构系数矩阵,并且计算类别区分度包括:
对文本的三维特征数据集进行处理,利用范数最小化的优化方法,得到文本的三维特征数据集中每个数据的重构系数,将每个数据的重构系数与词语集合的类别分别作为文本的特征数据集的重构系数矩阵的行与列,根据词语集合的类别计算词语集合中词语在各个类别的概率分布:
式(1)中:i=1,2,…,i,…,N,变量N记录词语集合中类别的数量,C1,C2,C3,…,Ci,…,CN表示词语集合中的词语在其类别中出现的次数,L1,L2,L3,…,Li,…,LN表示词语集合的中的各个类别中的词语数量,并且计算词语集合的类别Bi的信息熵,定义如下:
式(2)中:H(Bi)表示词语集合的类别Bi的信息熵;将词语集合的中的各个类别的信息熵综合,得到信息熵向量。
进一步,步骤S3中按照信息熵向量以及重构系数矩阵计算综合度量指标,并且按照综合度量指标从小到大的顺序进行特征选择包括:
计算信息熵向量的模,根据重构系数矩阵,提取文本的三维特征数据集中每个数据的重构系数,将信息熵向量的模乘以文本的三维特征数据集中每个数据的重构系数,得到计算词语集合中词语在词语集合的各个类别的综合度量指标,并且在词语集合中词语在词语集合的各个类别的综合度量指标从小到大进行排序,根据词语集合的中的各个类别中的词语数量、信息熵选取特征选择在词语集合的各个类别上的提取数量。
进一步,步骤S4中输出经过特征选择获得的文本特征集包括:
在词语集合的各个类别上输出满足其的提取数量的词语作为文本特征集。
本发明的有益效果是,本发明的特征选择方法不仅能够降低文本特征空间的维数,以利于提高文本分类的效率,而且通过去除对文本分类无效的特征也有利于提高文本分类的分类精度。
第二方面,本发明还提供了一种效率高、与用户习惯搜索关联度高、可行度高的就是计算机文本检索分类特征选择方法及系统。
为了解决上述技术问题,本发明提供了一种计算机文本检索分类特征选择方法,包括如下步骤:
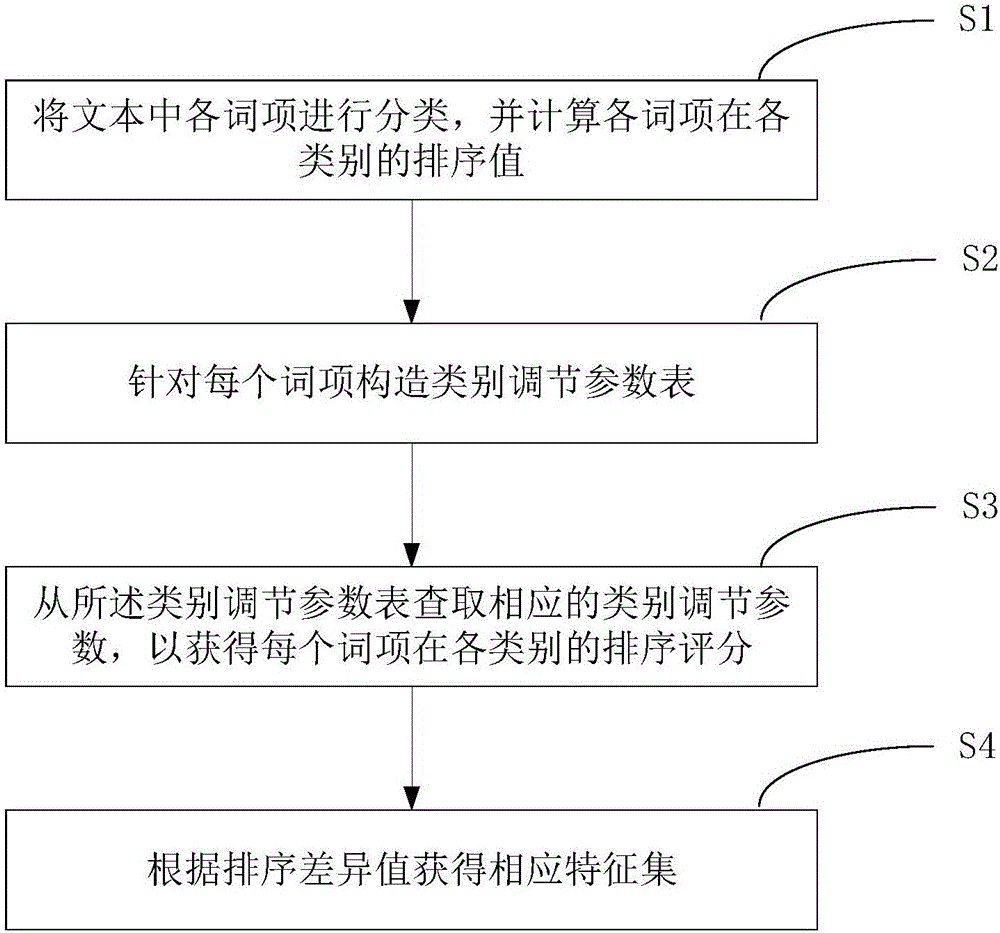
步骤S1,将文本中各词项进行分类,并计算各词项在各类别的排序值;
步骤S2,针对每个词项构造类别调节参数表;
步骤S3,从所述类别调节参数表查取相应的类别调节参数,以获得每个词项在各类别的排序评分;以及
步骤S4,根据排序差异值获得相应特征集。
进一步,所述步骤S1中将文本中各词项进行分类,并计算各词项在各类别的排序值的方法包括:
根据词项的外延数量、词项反映的对象、词项反应事物的属性对文本中的词项进行分类,并根据基于词项的分类结果定义类别,计算每个词项在各个类别的排序值;
所述排序值用于词项的排序,用排序功能函数计算,且所述排序函数的定义如下:
式(3)中,i=1,2,……,m,变量m表示存放记录词项的数量;变量j表示类别的标号;其中r(ti,cj)用于计算词项ti在类别cj的权重,e(ti,cj)表示词项ti在类别j的出现次数,ti表示第i个词项,cj表示第j个类别;v(ti)表示词项ti与初始词项的相邻频度,所述初始词项为用户最初输入的词项。
进一步,所述步骤S2中针对每个词项构造类别调节参数表的方法包括:
所述类别调节参数表的每行记录类别cj、w1(cj)、w2(cj),其以每个类别中词项的分布规则以及词项与初始词项的相邻频度为依据,根据马尔科夫链原理,即
在计算w2(cj)时,将词项在类别cj的权重作为输入,以及
在计算w1(cj)时,将所述排序值与词项的权重作为输入。
进一步,所述步骤S3中从所述类别调节参数表查取相应的类别调节参数,以获得每个词项在各类别的排序评分的方法包括:
对每个词项在各个类别上的排序值进行处理,得到每个词项在各个类别上的排序评分:
score(ti,cj)=w1(cj)×p(ti)+w2(cj)×r(ti,cj) (4);
式(4)中:score(ti,cj)表示词项ti在类别cj的排序评分,w1(cj)、w2(cj)为类别调节参数,用于调节p(ti)、r(ti,cj)之间的比例;
在计算排序评分时,从所述类别调节参数表查取相应的类别调节参数。
进一步,所述步骤S4中根据排序差异值获得相应特征集的方法包括:
按所述排序评分的升序来进行所有词项在各个类别上的排序,建立排序矩阵;
根据所述排序矩阵绘制每个词项在各个类别中的排序变化曲线,且根据所述排序变化曲线计算排序类别差异值;其中
排序类别差异值越大,则该词项在各个类别中排序差异越大,选取差异最大的20%数量的词项作为特征集。
第三方面,为了解决同样的技术问题,本发明还提供了一种计算机文本检索分类特征选择系统。
所述计算机文本检索分类特征选择系统包括:
依次相连的分类排序模块、调节参数表构造模块、排序评分模块和特征集选取模块。
进一步,所述分类排序模块适于将文本中各词项进行分类,并计算各词项在各类别的排序值,即
根据词项的外延数量、词项反映的对象、词项反应事物的属性对文本中的词项进行分类,并根据基于词项的分类结果定义类别,计算每个词项在各个类别的排序值;
所述排序值用于词项的排序,用排序功能函数计算,且所述排序函数的定义如下:
式(3)中,i=1,2,……,m,变量m表示存放记录词项的数量;变量j表示类别的标号;其中r(ti,cj)用于计算词项ti在类别cj的权重,e(ti,cj)表示词项ti在类别j的出现次数,ti表示第i个词项,cj表示第j个类别;v(ti)表示词项ti与初始词项的相邻频度,所述初始词项为用户最初输入的词项。
进一步,所述调节参数表构造模块适于针对每个词项构造类别调节参数表,即
所述类别调节参数表的每行记录类别cj、w1(cj)、w2(cj),其以每个类别中词项的分布规则以及词项与初始词项的相邻频度为依据,根据马尔科夫链原理,即
在计算w2(cj)时,将词项在类别cj的权重作为输入,以及
在计算w1(cj)时,将所述排序值与词项的权重作为输入。
进一步,所述排序评分模块适于从所述类别调节参数表查取相应的类别调节参数,以获得每个词项在各类别的排序评分,即
对每个词项在各个类别上的排序值进行处理,得到每个词项在各个类别上的排序评分:
score(ti,cj)=w1(cj)×p(ti)+w2(cj)×r(ti,cj) (4);
式(4)中:score(ti,cj)表示词项ti在类别cj的排序评分,w1(cj)、w2(cj)为类别调节参数,用于调节p(ti)、r(ti,cj)之间的比例;
在计算排序评分时,从所述类别调节参数表查取相应的类别调节参数。
进一步,所述特征集选取模块适于根据排序差异值获得相应特征集,即
按所述排序评分的升序来进行所有词项在各个类别上的排序,建立排序矩阵;
根据所述排序矩阵绘制每个词项在各个类别中的排序变化曲线,且根据所述排序变化曲线计算排序类别差异值;其中
排序类别差异值越大,则该词项在各个类别中排序差异越大,选取差异最大的20%数量的词项作为特征集。
本发明的有益效果是,若是文本的一个词项在所有的类别中的排序位置都差不多,则说明它对类别区分的能力很差,特征也因此不明显。而那些在不同的类别中位置差别很大的特征,说明其在不同的类别中的重要度有很大区别,则它适用于做区别类别的特征。本发明利用此原理对词项在所有类别进行科学地排序、估值,在此过程中把用户的搜索习惯考虑在内,用户初始搜索的词项体现了初始查询意图,有很大的价值。
附图说明
下面结合附图和实施例对本发明进一步说明。
图1是本发明的计算机文本的特征选择方法的方法流程图;
图2是本发明的计算机文本检索分类特征选择方法的方法流程图;
图3是本发明的计算机文本检索分类特征选择系统的原理框图。
具体实施方式
现在结合附图对本发明作进一步详细的说明。这些附图均为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
实施例1
如图1所示,本实施例1提供了一种计算机文本的特征选择方法,包括如下步骤:
步骤S1,对计算机文本进行处理,得到文本的三维特征数据集;
步骤S2,计算文本的三维特征数据集的重构系数矩阵,并且计算信息熵向量;
步骤S3,按照信息熵向量以及重构系数矩阵计算综合度量指标,并且按照综合度量指标从小到大的顺序进行特征选择;以及
步骤S4,输出经过特征选择获得的文本特征集。
随着网络数据的不断增长,特征选择作为计算机文本的文本分类技术的一个重要研究方向越来越受到人们的重视。计算机文本分类过程中,对其进行分词等预处理后得到的关键词集合构成了文本分类的初始特征词集合,初始特征词集合一般包括几万甚至几十万个初始特征词,其中,很多初始特征词在文本中出现的次数很少,对文本分类没有多大的贡献,甚至成为噪声数据。这些噪声数据会干扰文本分类的效果,通常情况下称这类初始特征词为低频弱关联词。在初始特征词集合中还存在另一类特征词,这些特征词中包含有大量与类别有关的信息,有利于提高中文文本分类的效果,这类特征词为高频强关联词。由于初始特征词集合中的特征词数量非常大,所以当把文本表示成向量空间模型时文本的向量空间维数也相当大,因此特征空间的高维性和文本表示的稀疏性会成为中文文本分类的最大难题。特征选择就是要从初始特征词集合中去除低频弱关联词,选择出能够很好代表类别相关性的高频强关联词集合,并通过特征权重函数给这些特征词条赋予不同的权重来表示特征词语对文本的重要程度,从而完成对文本向量空间的维数缩减工作。这样不仅能够降低了文本向量空间的维数,而且也有利于提高中文文本分类的分类效率和分类效果。近些年来中文文本分类中经常采用的特征选择方法主要有:互信息、信息增益等。
特征词语相对于某个文本的词频是指特征词语在该文本中出现的次数。特征词语的文档频指出现了该特征词语的文档数目。由于特征词语在某个文本中的词频一定程度上代表了特征词语相对于文本的重要性,而本实施例1中步骤S1则对词语集合中的词语在计算机文本中出现的次数,坐标上的纵坐标为词语集合中的词语在其类别中出现的次数进行了统计,而这两个参数则在一定程度上代表了特征词条的类别区分能力,所以可以作为特征词语重要程度度量指标。
在步骤S2中采用了信息熵作为重要的度量以及排序指标,根据词语集合的类别计算词语集合中词语在各个类别的概率分布:
式(1)中:i=1,2,…,i,…,N,变量N记录词语集合中类别的数量,C1,C2,C3,…,Ci,…,CN表示词语集合中的词语在其类别中出现的次数,L1,L2,L3,…,Li,…,LN表示词语集合的中的各个类别中的词语数量,并且计算词语集合的类别Bi的信息熵,定义如下:
式(2)中:H(Bi)表示词语集合的类别Bi的信息熵,特征词语的信息熵的大小体现了特征词条在各个类别中的分布情况。分布越均匀信息熵的值越大,特征词语的类别区分度越小,则该特征词语对分类的贡献也就越小。也就是说特征词语对分类的贡献与特征词语的信息熵的取值成反比。
实施例2
本实施例2包含一种计算机文本的特征选择方法,包括如下步骤:步骤S1,对计算机文本进行处理,得到文本的三维特征数据集;步骤S2,计算文本的三维特征数据集的重构系数矩阵,并且计算信息熵向量;步骤S3,按照信息熵向量以及重构系数矩阵计算综合度量指标,并且按照综合度量指标从小到大的顺序进行特征选择;步骤S4,输出经过特征选择获得的文本特征集。
在本实施例2中步骤S2中利用范数最小化的优化方法,得到文本的三维特征数据集中每个数据的重构系数,范数最小化的优化方法能缓解文本表示的稀疏性,对最优解的求解却非常的困难,凸分析方法并不适用于求解。求解是一个NP-hard问题,要找到一个全局最优解必须要遍历所有的组合。如果假设A矩阵的大小为500*2000,已知最稀疏的解包含20个非零元素,那么共有种可能,在有限时间内很难有效完成的。必须采用近似的计算方法,包含以匹配追踪、正交匹配追踪等为代表的贪婪算法,都能够有效地求出问题的近似解。其中,OMP算法因其简单且高效的性质应用较为广泛,具体算法如下:
算法所用参数:给定矩阵A,向量b,误差阈值ε。
初始化:迭代次数j=0,初始解x0=0,初始残差r0=b-Ax=b,初始索引集下面进行迭代步骤,k=k+1:矩阵A的所有列中找出与残差最相关的列,步骤包括:(1)A的每一列计算系数(2)计算所有列的误差找出误差最小的一列,并且根据该列更新索引集。计算当前解并将索引集用集合记录。更新残差rk=b-Axk,迭代停止条件为||rk||2≤ε。
实施例3
如图2所示,本实施例3提供了一种计算机文本检索分类特征选择方法,包括如下步骤:
步骤S1,将文本中各词项进行分类,并计算各词项在各类别的排序值;
步骤S2,针对每个词项构造类别调节参数表;
步骤S3,从所述类别调节参数表查取相应的类别调节参数,以获得每个词项在各类别的排序评分;以及
步骤S4,根据排序差异值获得相应特征集。
具体的,所述步骤S1中将文本中各词项进行分类,并计算各词项在各类别的排序值的方法包括:
根据词项的外延数量、词项反映的对象、词项反应事物的属性对文本中的词项进行分类,并根据基于词项的分类结果定义类别,计算每个词项在各个类别的排序值;
所述排序值用于词项的排序,用排序功能函数计算,且所述排序函数的定义如下:
式(3)中,i=1,2,……,m,变量m表示存放记录词项的数量;变量j表示类别的标号;其中r(ti,cj)用于计算词项ti在类别cj的权重,e(ti,cj)表示词项ti在类别j的出现次数,ti表示第i个词项,cj表示第j个类别;v(ti)表示词项ti与初始词项的相邻频度,所述初始词项为用户最初输入的词项。
具体的,所述步骤S2中针对每个词项构造类别调节参数表的方法包括:
所述类别调节参数表的每行记录类别cj、w1(cj)、w2(cj),其以每个类别中词项的分布规则以及词项与初始词项的相邻频度为依据,根据马尔科夫链原理,即
在计算w2(cj)时,将词项在类别cj的权重作为输入,以及
在计算w1(cj)时,将所述排序值与词项的权重作为输入。
具体的,所述步骤S3中从所述类别调节参数表查取相应的类别调节参数,以获得每个词项在各类别的排序评分的方法包括:
对每个词项在各个类别上的排序值进行处理,得到每个词项在各个类别上的排序评分:
score(ti,cj)=w1(cj)×p(ti)+w2(cj)×r(ti,cj) (4);
式(4)中:score(ti,cj)表示词项ti在类别cj的排序评分,w1(cj)、w2(cj)为类别调节参数,用于调节p(ti)、r(ti,cj)之间的比例;
在计算排序评分时,从所述类别调节参数表查取相应的类别调节参数。
具体的,所述步骤S4中根据排序差异值获得相应特征集的方法包括:
按所述排序评分的升序来进行所有词项在各个类别上的排序,建立排序矩阵;
根据所述排序矩阵绘制每个词项在各个类别中的排序变化曲线,且根据所述排序变化曲线计算排序类别差异值;其中
排序类别差异值越大,则该词项在各个类别中排序差异越大,选取差异最大的20%数量的词项作为特征集。
实施例4
如图3所示,在实施例3基础上,本实施例4提供了一种计算机文本检索分类特征选择系统。
所述计算机文本检索分类特征选择系统包括:
依次相连的分类排序模块、调节参数表构造模块、排序评分模块和特征集选取模块。
具体的,所述分类排序模块适于将文本中各词项进行分类,并计算各词项在各类别的排序值,即
根据词项的外延数量、词项反映的对象、词项反应事物的属性对文本中的词项进行分类,并根据基于词项的分类结果定义类别,计算每个词项在各个类别的排序值;
所述排序值用于词项的排序,用排序功能函数计算,且所述排序函数的定义如下:
式(3)中,i=1,2,……,m,变量m表示存放记录词项的数量;变量j表示类别的标号;其中r(ti,cj)用于计算词项ti在类别cj的权重,e(ti,cj)表示词项ti在类别j的出现次数,ti表示第i个词项,cj表示第j个类别;v(ti)表示词项ti与初始词项的相邻频度,所述初始词项为用户最初输入的词项。
具体的,所述调节参数表构造模块适于针对每个词项构造类别调节参数表,即
所述类别调节参数表的每行记录类别cj、w1(cj)、w2(cj),其以每个类别中词项的分布规则以及词项与初始词项的相邻频度为依据,根据马尔科夫链原理,即
在计算w2(cj)时,将词项在类别cj的权重作为输入,以及
在计算w1(cj)时,将所述排序值与词项的权重作为输入。
具体的,所述排序评分模块适于从所述类别调节参数表查取相应的类别调节参数,以获得每个词项在各类别的排序评分,即
对每个词项在各个类别上的排序值进行处理,得到每个词项在各个类别上的排序评分:
score(ti,cj)=w1(cj)×p(ti)+w2(cj)×r(ti,cj) (4);
式(4)中:score(ti,cj)表示词项ti在类别cj的排序评分,w1(cj)、w2(cj)为类别调节参数,用于调节p(ti)、r(ti,cj)之间的比例;
在计算排序评分时,从所述类别调节参数表查取相应的类别调节参数。
具体的,所述特征集选取模块适于根据排序差异值获得相应特征集,即
按所述排序评分的升序来进行所有词项在各个类别上的排序,建立排序矩阵;
根据所述排序矩阵绘制每个词项在各个类别中的排序变化曲线,且根据所述排序变化曲线计算排序类别差异值;其中
排序类别差异值越大,则该词项在各个类别中排序差异越大,选取差异最大的20%数量的词项作为特征集。
以上述依据本发明的理想实施例为启示,通过上述的说明内容,相关工作人员完全可以在不偏离本项发明技术思想的范围内,进行多样的变更以及修改。本项发明的技术性范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。
- 还没有人留言评论。精彩留言会获得点赞!