一种用于影视素材领域的非结构化数据管理方法与流程
本发明非结构化数据管理领域,尤其是涉及一种用于影视素材领域的非结构化数据管理方法。
背景技术:
影视素材在影视后期制作、教学、研究等多领域被大量应用。能用统一结构表示的数据称为结构化数据;字段长度可变,没有预定义数据模型的数据称为非结构化数据。传统的关系型数据库可以较好管理结构化数据,但在异构数据海量膨胀的背景下,关系型数据库暴露出明显局限性。
影视素材中文本、图像、音频、视频等都属于非结构化数据。相比较结构化数据,其存在存储管理、查询处理和查询优化等问题。因而,在海量的影视素材中,如何有效存储并且查询非结构化的影视数据,是媒资管理中亟需解决的问题。
技术实现要素:
本发明的目的是针对上述问题提供一种用于影视素材领域的非结构化数据管理方法。
本发明的目的可以通过以下技术方案来实现:
一种用于影视素材领域的非结构化数据管理方法,用于对影视素材领域的非结构化数据进行分布式存储、查询和可视化管理,所述分布式存储具体为:
a1)建立影视素材领域的知识本体,包括领域知识库ks和标签分类库ls;
a2)根据建立的影视素材领域的知识本体,确定所接收影视素材的非结构化数据的存储路径,按照存储路径将其存储到hdfs文件系统中,同时将影视素材的非结构化数据的描述信息存储到数据库中;
所述查询和可视化管理具体为:
b1)通过计算语义相似相关度拓展用户的搜索条件;
b2)根据拓展后的用户的搜索条件,利用elasticsearch搜索引擎结合jena推理算法进行搜索,得到搜索结果并反馈给用户;
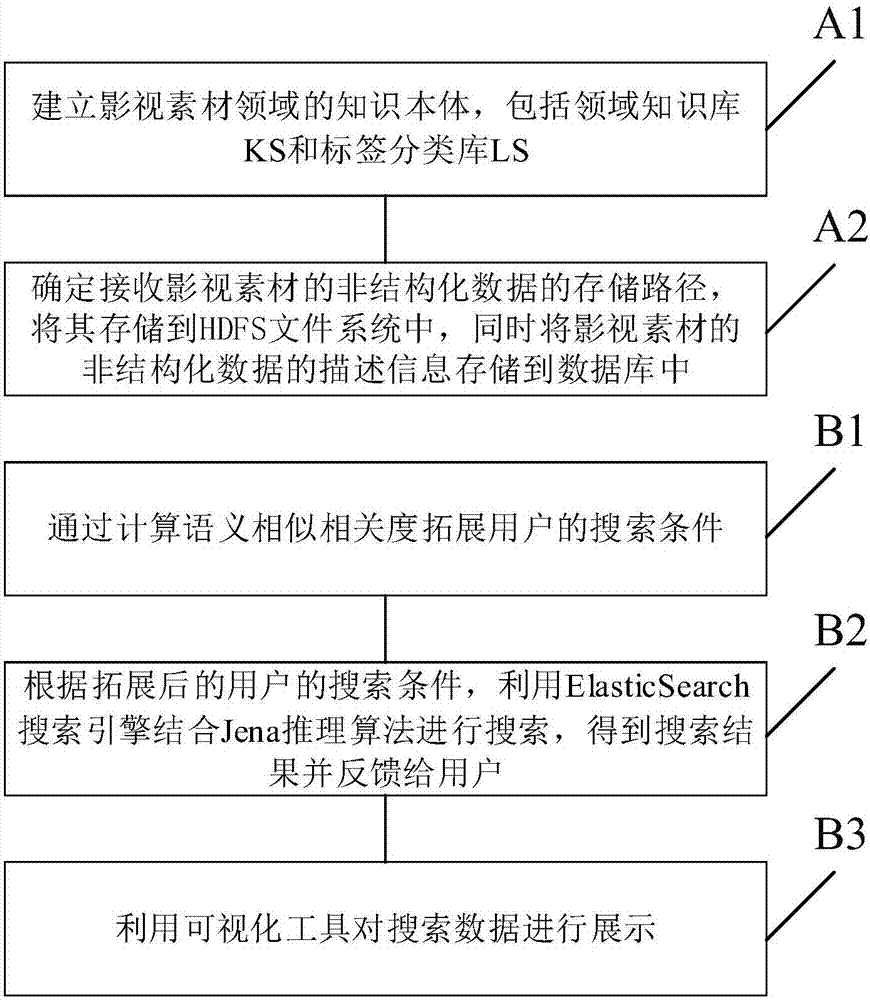
b3)利用可视化工具对搜索数据进行展示。
所述步骤a1)具体为:
a11)对影视素材领域的知识进行分类,得到领域知识库ks;
a12)根据步骤a11)的分类结果建立影视素材领域的知识本体,所述影视素材领域的知识本体为树结构,所述树结构上的结点对应影视素材领域的知识分类;
a13)对步骤a12)中树结构上的结点进行信息描述并设置语义标签,得到标签分类库ls。
所述步骤a2)具体为:
a21)根据领域知识库ks确定接收的影视素材的非结构化数据的相关分类;
a22)根据标签分类库ls确定接收的影视素材的非结构化数据的语义标签;
a23)根据确定的相关分类和语义标签确定影视素材的非结构化数据的存储路径;
a24)按照存储路径将影视素材的非结构化数据存储至hdfs文件系统的主控机器中,主控机器将其分配到其他从属机器进行存储,从属机器同时对影视素材的非结构化数据进行备份;
a25)影视素材的非结构化数据的描述信息存储到数据库中,所述描述信息包括本体结构信息、相关分类、语义标签和存储路径。
所述步骤b1)具体为:
b11)对用户的搜索条件进行自然语言处理;
b12)计算处理后的搜索条件的语义相似相关度,所述语义相似相关度包括字面相似度wordsim(a,b)、语义重合度semcr(a,b)、距离相似度dissim(a,b)和层次深度deph(a,b);
b13)根据计算结果得到拓展后的搜索条件。
所述自然语言处理包括中文分词和过滤预定义的停用词。
所述字面相似度wordsim(a,b)具体为:
所述语义重合度semcr(a,b)具体为:
所述距离相似度dissim(a,b)具体为:
所述层次深度deph(a,b)具体为:
其中,a和b表示影视素材领域的知识本体的两个结点,r表示根节点,wordnum表示汉字数,nodeset表示结点集合,length表示途经长度。
所述步骤b2)具体为:
b21)利用elasticsearch搜索引擎,将拓展后的用户的搜索条件与标签分类库ls进行匹配;
b22)根据标签分类库ls的匹配结果得到对应的领域知识库ks中的结点,利用jena推理算法得到其兄弟结点;
b23)将步骤b22)中得到的结点及其兄弟结点对应的描述信息和影视素材的非结构化数据作为搜索结果;
b24)对步骤b23)得到的搜索结果进行排序并反馈给用户。
所述排序的规则具体为:
b241)对自然语言处理后得到的搜索条件对应的搜索结果优先展示;
b242)对语义相似相关度计算结果高的搜索条件对应的搜索结果次优先展示;
b243)利用elasticsearch搜索引擎的评分算法对搜索条件进行评分,按照评分的高低将对应的搜索结果进行展示。
所述步骤b3)具体为:
b31)按照日期和ip地址对用户的搜索数据进行分析,所述搜索数据包括关键词数据、词频数据和文档下载数据;
b32)选择需要绘制的可视化图形类型,所述可视化图形类型包括柱形图、折线图、饼状图和集群图;
b33)对用户的搜索习惯和搜索地域进行分析,结合步骤b31)的分析结果,按照选择的可视化图形类型进行可视化展示。
与现有技术相比,本发明具有以下有益效果:
(1)构建影视素材领域的知识本体,并通过分布式存储平台hdfs实现了非结构化数据的分布式存储,同时将非结构化数据的存储路径等描述信息存储到数据库中,通过描述信息与非结构化数据进行关联,与结构化数据库相比,存储更为方便灵活,查询也更为便捷。
(2)通过计算语义相似相关度拓展用户的搜索条件,扩大了搜索结果的覆盖范围,更加便于用户查询到相关数据。
(3)利用搜索引擎结合jena推理算法进行搜索,适用于非结构化数据的处理和查询,摆脱了现有的适用于结构化数据搜索的工具的限制。
(4)对于搜索结果按照相关度进行排序,便于用户寻找到最为相关的搜索结果,进一步提高了搜索质量。
(5)进利用可视化工具对搜索数据进行了展示,显示直观。
附图说明
图1为影视素材领域的非结构化数据管理系统的架构图;
图2为本发明的方法流程图;
图3为关键词的处理流程图;
图4为非结构化数据的存储流程图;
图5为返回查询结果的流程图;
图6为领域知识库ks与标签分类库ls的关系图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
如图2所示,本发明提供了一种用于影视素材领域的非结构化数据管理方法,用于对影视素材领域的非结构化数据进行分布式存储、查询和可视化管理,该方法包括下列步骤:
a1)建立影视素材领域的知识本体,包括领域知识库ks和标签分类库ls:
a11)对影视素材领域的知识进行分类,得到领域知识库ks;
a12)根据步骤a11)的分类结果建立影视素材领域的知识本体,所述影视素材领域的知识本体为树结构,所述树结构上的结点对应影视素材领域的知识分类;
a13)对步骤a12)中树结构上的结点进行信息描述并设置语义标签,得到标签分类库ls;
a2)根据建立的影视素材领域的知识本体,确定所接收影视素材的非结构化数据的存储路径,按照存储路径将其存储到hdfs文件系统中,同时将影视素材的非结构化数据的描述信息存储到数据库中:
a21)根据领域知识库ks确定接收的影视素材的非结构化数据的相关分类;
a22)根据标签分类库ls确定接收的影视素材的非结构化数据的语义标签;
a23)根据确定的相关分类和语义标签确定影视素材的非结构化数据的存储路径;
a24)按照存储路径将影视素材的非结构化数据存储至hdfs文件系统的主控机器中,主控机器将其分配到其他从属机器进行存储,从属机器同时对影视素材的非结构化数据进行备份;
a25)影视素材的非结构化数据的描述信息存储到数据库中,所述描述信息包括本体结构信息、相关分类、语义标签和存储路径;
b1)通过计算语义相似相关度拓展用户的搜索条件:
b11)对用户的搜索条件进行自然语言处理;
b12)计算处理后的搜索条件的语义相似相关度,所述语义相似相关度包括字面相似度wordsim(a,b)、语义重合度semcr(a,b)、距离相似度dissim(a,b)和层次深度deph(a,b);
b13)根据计算结果得到拓展后的搜索条件;
b2)根据拓展后的用户的搜索条件,利用elasticsearch搜索引擎结合jena推理算法进行搜索,得到搜索结果并反馈给用户:
b21)利用elasticsearch搜索引擎,将拓展后的用户的搜索条件与标签分类库ls进行匹配;
b22)根据标签分类库ls的匹配结果得到对应的领域知识库ks中的结点,利用jena推理算法得到其兄弟结点;
b23)将步骤b22)中得到的结点及其兄弟结点对应的描述信息和影视素材的非结构化数据作为搜索结果;
b24)对步骤b23)得到的搜索结果进行排序并反馈给用户;
b3)利用可视化工具对搜索数据进行展示:
b31)按照日期和ip地址对用户的搜索数据进行分析,所述搜索数据包括关键词数据、词频数据和文档下载数据;
b32)选择需要绘制的可视化图形类型,所述可视化图形类型包括柱形图、折线图、饼状图和集群图;
b33)对用户的搜索习惯和搜索地域进行分析,结合步骤b31)的分析结果,按照选择的可视化图形类型进行可视化展示。
如图1所示为基于影视素材领域的非结构化数据管理系统,该系统按照上述步骤具体进行管理,具体过程为:
根据影视领域专业知识,用protégé工具建立影视领域本体。设立相关类与实例,为其设置语义标签以及信息描述规范。用户根据所建立的本体,以及不同的标签分类上传影视领域非结构化数据。数据库mongodb中存非结构化数据的相关描述信息(包括数据分类、语义标签等),分布式文件系统hdfs中存储文件实体。用户搜索界面接受用户的查询条件,通过自然语言处理技术,结合ikanalyzer分词器、语义相关度、语义相似度等方法,得到拓展的用户搜索关键词集合。通过搜索引擎elasticsearch组件,查找到标签分类库ls中对应的标签属性,进一步得到该属性在领域知识库ks中对应的结点;通过jena推理机查找到对应结点的兄弟结点信息。按照一定排序规则,将相关搜索结果返回,保证与用户搜索最为密切的搜索结果优先级最高。最后,用d3.js对用户的搜索数据进行可视化分析,增加用户体验。
如图3所示为处理查询关键词的流程,首先,获取用户查询请求后,对查询信息进行自然语言处理,包括用ik分词器进行将用户搜索信息序列切分成单独的词,过滤预定义的停用词等;通过相关文本预处理操作,可得到用户搜索关键词;其次,通过计算语义相似度与语义相关度拓展用户查询条件;
主要通过如下几种相似度对用户查询条件进行拓展:
字面相似度wordsim(a,b):
语义重合度semcr(a,b):
距离相似度dissim(a,b):
层次深度deph(a,b):
其中,a和b表示影视素材领域的知识本体的两个结点,r表示根节点,wordnum表示汉字数,nodeset表示结点集合,length表示途经长度。
字面相似度wordsim(a,b),是指词语间相同汉字的数量占两个词语汉字综述的比重。wordnum(a∩b)表示a与b共同拥有的汉字数,wordnum(a)+wordnum(b)表示结点a与b中所有的汉字数;
语义重合度semcr(a,b),指结点间具有共同的上位结点(包含其父结点和祖先结点)占两个结点所有上位结点的比例。nodeset(a,r)、nodeset(b,r)分别为从a、b向父结点遍历直至根结点,中间经过的结点集合;nodeset(a,r)∩nodeset(b,r)代表从a、b分别向父结点出发直至根结点时,经过的公共结点集合;nodeset(a,r)∪nodeset(b,r)代表从a、b分别向父结点出发直至根结点,一共经过的结点集合;
距离相似度dissim(a,b),指两个结点在本体中距离的远近,如果两个结点无通路,即不可达,则dissim(a,b)=0;length(a,r),length(b,r)指的是从a、b结点向父结点遍历至根结点途经长度。如果a可遍历到b结点,则结点a与b的距离为|length(a,r)-length(b,r)|。
层次深度deph(a,b),指结点在本体中与根结点的距离程度。距离根结点越近,则结点含义越抽象。length(a,r)、length(b,r)分别为从a、b向父结点遍历直至根结点,中间经过的路径长度;length(r)为本体模型的深度。
通过计算不同的相似度,拓展用户搜索的关键词,保证用户搜索结果更为全面。但在对查询结果进行排序时,未经拓展的关键词查询结果优先级最高。根据查询关键词集合搜索得到标签分类库ls中对应的数据语义标签,再根据标签与领域知识库ks的对应关系找到相关结点
如图4所示为本发明非结构化数据存储流程图,用户在上传影视素材后,首先,根据领域知识库ks为素材绑定分类。其次,根据标签分类库ls中的标签属性为非结构化数据添加语义标签,将ls中描述类属性的标签实例化对象。ls中的语义标签,包括素材标题、摘要、创建时间、作者等。最后,将非结构化数据描述信息,包括由ks确定的分类信息、ls确定的语义标签以及非结构化数据存储路径信息存储到mongodb数据库中;根据描述信息中由相关分类和语义标签所确定的存储路径,将影视素材领域的非结构化数据实体存储到hdfs文件系统。
如图5所示为本发明返回查询结果流程图,得到用户查询关键词后,通过搜索引擎以及推理算法,在领域知识库ks中查找对应结点以及与该结点相关的其他兄弟结点,并将查询结果返回用户。首先,利用搜索引擎elasticsearch,找到与用户搜索关键字对应的标签分类库ls中的信息。ls再根据标签属性与分类结点的对应关系,找到对应该属性的ks中的结点;其次,利用jena推理机,推理得出ks中对应结点的父结点,并搜索该父结点的其他子结点;最后,对查询结果进行排序。通过计算字面相似度、语义重合度等,与查询关键字相似度越大的查询结果具有较高优先级。
如图6所示为本发明领域知识库ks与标签分类库ls的关系图,领域知识库ks为根据领域专家知识,采用树结构本体模型tr(n,e)形式建立的影视领域本体类,选用protégé本体编辑器,owl语言描述。标签分类库ls是与领域知识库ks结点一一对应的标签,具有不同属性。属性中可添加实例的描述信息以及影视实体的存储路径。用户上传原始素材时,根据ks对应的分类,找到上传素材所述结点位置。再根据该结点所对应ls中的属性,为非结构化数据添加语义标签。由此生成了具有ls标签属性的ks实例。
- 还没有人留言评论。精彩留言会获得点赞!