一种基于SAS的图书借阅数据关联规则分析方法与流程
本发明涉及信息管理技术领域,特别是涉及一种基于SAS的图书借阅数据关联规则分析方法。
背景技术:
数据挖掘(Data Mining),又称为数据库中的知识发现(KDD)。数据挖掘技术从二十世纪年代开始受到多方面的青睐,其主要原因是因为计算机技术尤其是数据库管理方面的技术很复杂棘手,数据库中的数据增长很快,使得手动查找信息变得非常困难。数据挖掘技术对于发现和描述关系表中的隐藏模式非常有用,而且数据挖掘提供的算法允许自动模式查找。数据挖掘技术现己广泛应用于电信、电子商务及市场管理方面,大大提高了其管理效率、服务水平和经济效益。
高校数字图书馆随着信息资源的日益丰富、计算机技术运用到日常管理工作中,数据也正在以几何倍数增长同时在处理数据时也暴露出一些问题:
1.在馆藏建设过程中,图书采购目的模糊、针对性不强,常常带有个人的爱好取向,不能反映学校的学科建设方向和发展目标。
2.资源利用率低,检索不精确,不能在有效的时间内取得有效的信息,存在大量的冗余信息。
3.在大多数情况下,当前数据库中的信息由于不能方便地访问、分析,因而没有得到足够的重视或者没有充分使用。
4.一些数据库增长得太快,以至于即使系统管理员也经常不清楚系统中哪些信息可以用于当前需要处理的主要问题,以及系统中的数据与当前问题之间的关系。
5.信息开发利用不足对于海量数据只作一般性维护,没有进一步对其进行开发利用对于网上信息资源,没有进行甄别、筛选和重组,造成信息资源的浪费对于电子文献资源,二次开发不够等等。
以上出现的这些问题,为数据挖掘技术在高校数字图书馆中的应用提供了可能性而数据挖掘技术的日益成熟及数据挖掘产品的日益完善为数据挖掘技术在高校数字图书馆的信息资源管理中应用提供了可行性。
运用数据挖掘技术,有如下优点:
采用数据挖掘技术如聚类、关联规则等,可以对借阅流通记录、数字资源使用数据进行挖掘,发现隐藏的某种联系,得出图书文献借阅趋势、文献的利用率及读者的喜好参数,为图书采购、文献资料的增减提供决策依据,为学科建设提供信息说明和支撑同时也可为读者提供个性化信息服务,提高服务质量。
采用数据挖掘技术如聚类,找出馆内资源的相互关系,即通过聚类确定数据间存在的相似性,具有最相似性的数据聚集成簇并对这些数据进行整合。加强对各种非结构化的数据库如文本数据、图形数据、视频图像数据、声音数据、综合多媒体数据的整合,可丰富信息资源,提高资源的利用率、检索的精确性。
技术实现要素:
本发明的目的是提供一种基于SAS的图书借阅数据关联规则分析方法。
本发明的目的可以通过以下技术方案实现:
一种基于SAS的图书借阅数据关联规则分析方法,包括:
步骤一、将从图书管理系统中导出的数据以文本方式保存后导入到数据库中,通过查询语句进行数据转换、合并、筛选,去除图书馆业务数据中与数据挖掘不相关的冗余项,保存与数据挖掘相关的重要属性;
步骤二、从数据库中提取数据,将从数据库中提取的数据以文本方式保存,然后导入EXCEL表并保存到读者借阅数据预处理文件夹中,对读者证号、索书号数据进行预处理,得到预处理后的读者证号、索书号数据表;
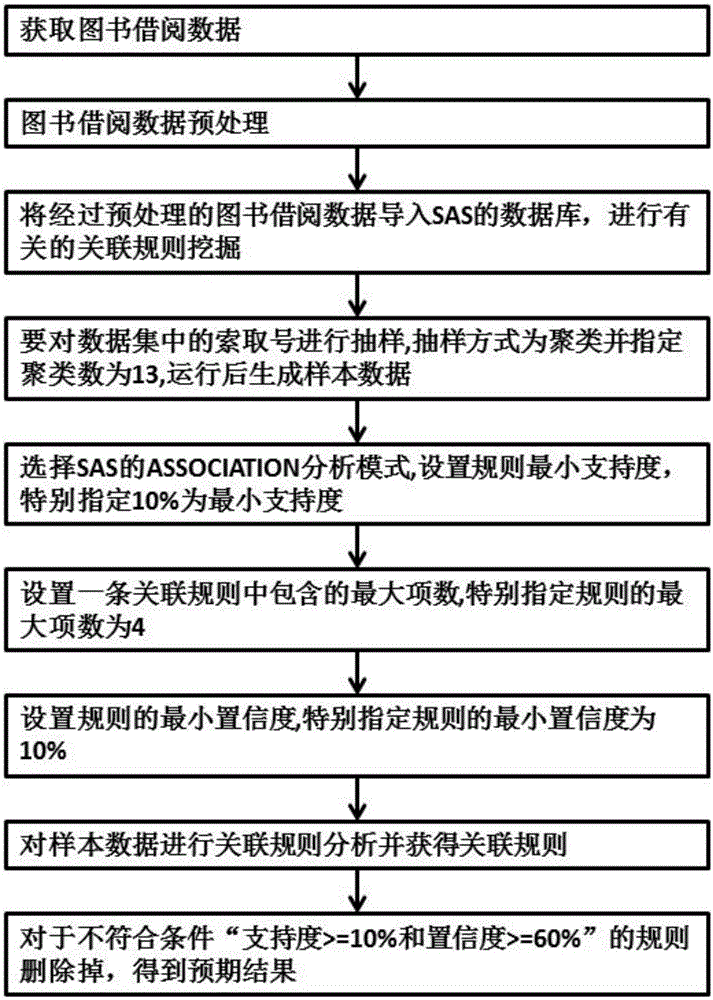
步骤三、将经过预处理的图书借阅数据导入SAS的数据库,进行有关的关联规则挖掘,从而得到关联规则挖掘结果;
步骤四、要对数据集中的索取号进行抽样,抽样方式为聚类并指定聚类数为13,运行后生成样本数据;
步骤五、选择SAS的ASSOCIATION分析模式,设置规则最小支持度,特别指定10%为最小支持度;
步骤六、设置一条关联规则中包含的最大项数,特别指定规则的最大项数为4;
步骤七、设置规则的最小置信度,特别指定规则的最小置信度为10%;
步骤八、对样本数据进行关联规则分析并获得关联规则;
步骤九、对于不符合条件“支持度>=10%和置信度>=60%”的规则删除掉,得到预期结果。
本发明的有益效果:
本发明所提供的一种基于SAS的图书借阅数据关联规则分析方法,运用本方法关联挖掘得到的结果和图书馆实际工作、读者调查相比较结果比较,结果相近;得到的结果对图书馆管理工作起到重要的参考作用,通过运用本方法挖掘出来的关联规则,可以对读者的图书借阅提供建议和推荐图书,从而实现针对特定读者的个性化服务,可以对借阅流通记录、数字资源使用数据进行挖掘,发现隐藏的某种联系,得出图书文献借阅趋势、文献的利用率及读者的喜好参数,为图书采购、文献资料的增减提供决策依据,为学科建设提供信息说明和支撑同时也可为读者提供个性化信息服务,提高服务质量。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1是本发明的方法示意图。
具体实施方式
本发明的核心是提供一种基于SAS的图书借阅数据关联规则分析方法。
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明提供了一种基于SAS的图书借阅数据关联规则分析方法,该方法包括如下步骤:
一种基于SAS的图书借阅数据关联规则分析方法,包括:
步骤一、将从图书管理系统中导出的数据以文本方式保存后导入到SQL Server数据库中中,通过查询语句进行数据转换、合并、筛选,去除图书馆业务数据中与数据挖掘不相关的冗余项,保存与数据挖掘相关的重要属性,如如操作日期、读者证号、索取号、文献条码号。
步骤二、从数据库中提取数据,将从SQL Server提取的数据以文本方式保存并取名为JYZHSQH52,然后导入EXCEL表以JYZHSQH52.XLS保存到读者借阅数据预处理文件夹中,运用SQL对读者证号、索书号数据进行预处理,sql程序如下:
建表Sheet1$
CREATE TABLE[master].[dbo].[sheet1$](
[suoqu]varchar(255)NULL,
[reader_no]bigint NULL)
利用SQL语言对读者证号、索书号数据进行预处理,SQL程序如下:
select读者证号,索取号from sheet1$order by读者证号;
运行后得到预处理后的读者证号、索书号数据表。
步骤三、将经过预处理的图书借阅数据导入SAS的数据库,进行有关的关联规则挖掘,从而得到关联规则挖掘结果;
进入SAS系统后,导入,JYZHSQH52.XSL
保存到sheet1$中。程序如下
proc import out=work.jyzhsqh52
datefile="E:\zzhsqh.xls"
dbms=excel replace;
sheet="Sheet1$";
getnames=yes;
mixed=no;
scantext=yes;
usedate=yes;
run;
在SAS中,选择SASUSER作为永久性Library,Menmber取名为JYZHSQH52,并在C盘中建立名称为JYZHSQH52.SAS的文件夹,以保存可以在SAS系统运行的相关数据,供在以后的相关数据挖掘过程中可以重复调用。最后将在SAS系统中建立名称为SASUSER.JYZHSQH52的数据库,打开SASUSER.JYZHSQH52数据库,可以看到一个由读者证号和索取号组成的表。
步骤四、在SASUSER.JYZHSQH52数据库建立后,要对数据集中的索取号进行抽样,抽样方式为聚类并指定聚类数为13,运行后生66个样本数据。
步骤五、选择SAS的ASSOCIATION分析模式,设置规则最小支持度,特别指定10%为最小支持度。
步骤六、设置一条关联规则中包含的最大项数,特别指定规则的最大项数为4。
步骤七、设置规则的最小置信度,特别指定规则的最小置信度为10%。
步骤八、对样本数据进行关联规则分析并获得关联规则。
步骤九、从产生的规则来看,只有那些支持度>=10%和置信度>=60%的规则才具有实际意义,对于那些支持度和置信度不符合数据挖掘要求的规则要删除掉。
本发明所提供的一种基于SAS的图书借阅数据关联规则分析方法,运用本方法关联挖掘得到的结果和图书馆实际工作、读者调查相比较结果比较,结果相近;得到的结果对图书馆管理工作起到重要的参考作用,通过运用本方法挖掘出来的关联规则,可以对读者的图书借阅提供建议和推荐图书,从而实现针对特定读者的个性化服务,可以对借阅流通记录、数字资源使用数据进行挖掘,发现隐藏的某种联系,得出图书文献借阅趋势、文献的利用率及读者的喜好参数,为图书采购、文献资料的增减提供决策依据,为学科建设提供信息说明和支撑同时也可为读者提供个性化信息服务,提高服务质量。
以上内容仅仅是对本发明结构所作的举例和说明,所属本技术领域的技术人员对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,只要不偏离发明的结构或者超越本权利要求书所定义的范围,均应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!