基于FPGA的高级综合实现拟牛顿算法加速的方法与流程
本发明涉及拟牛顿算法(Quasi-Newton,QN)加速技术,具体涉及一种基于现场可编程门阵列(Field Programmable Gate Arrays,FPGA)的高层次综合(High Level Synthesis,HLS)工具优化加速拟牛顿算法的方法。
背景技术:
拟牛顿算法是一种求解非线性优化最有效的方法,被广泛应用于各种领域,如:随机优化,集成电路布局和电力系统的加载频率控制。这些应用的关键性因素是在有限的时间内获得最优的解决方案。然而拟牛顿算法由于内部含有大量的迭代算法导致耗时严重。所以,对拟牛顿算法的加速是一个重要的研究方向。
随着FPGA的快速发展,现在的FPGA平台拥有更多的资源,操作频率能够达到上百MHz。FPGA器件具有可重配置,高并行度,设计灵活(相对与专用集成电路)的特性(见文献[1]),更适合应用于嵌入式场合,FPGA被认为是加速计算量大的应用的最佳选择,例如人工神经网络和图谱计算(见文献[2]及[3])。与其他普适性的计算架构相比,FPGA允许定制化的计算架构和针对特定应用算法的内存子系统。在FPGA内部进行复杂的时序设计一般需要状态机进行开发,这需要花费较多的时间进行分析与设计,而且软件工程师在利用高层次语言C,C++进行开发与硬件工程师利用RTL设计语言设计电路的背景知识存在一定的差距。这导致了FPGA的开发比传统的单片机开发有很大的不同,开发比较困难(见文献[4])。
高层次综合是一种将高层次语言有效地转化为满足设计约束的寄存器传输级(Register Transfer Level,RTL)描述的工具。HLS提高了硬件设计的抽象层次,具有以下突出优点(见文献[5]):1)硬件工程师可以减少设计时间,缩短产品上市周期;2)软件工程师能完成硬件系统设计;3)沟通了软件设计和硬件设计两个领域,展现了一种软硬件联合设计的方法,HLS被认为是下一代半导体工业中的核心角色,在企业界和学术界受到越来越多的关注。
技术实现要素:
本发明的目的在于克服上述现有技术的不足,从加速拟牛顿算法出发,利用高层次综合实现拟牛顿算法,通过FPGA实现对拟牛顿算法加速,降低了FPGA的开发难度。
本发明的技术方案:基于FPGA的高级综合实现拟牛顿算法加速的方法,包括以下步骤:
(1)、分析拟牛顿算法的功能,划分出拟牛顿算法的主要计算模块;
(2)、利用高级语言C,C++实现上述步骤(1)中的各个模块,并且验证算法功能的正确性;
(3)、将上述步骤(2)功能验证正确的拟牛顿算法作为输入文件,利用高层次综合工具,将高级语言转化为RTL级语言,验证生成的RTL代码;
(4)、将生成的RTL代码制作成比特流文件,下载配置到FPGA的可配置逻辑部分。
所述步骤(1)分析拟牛顿算法的功能,将算法划分成三个主要计算模块,分别是梯度计算模块Compute_grad,矩阵更新模块QN_formula和线性搜索模块Line_search;矩阵更新模块以BFGS方式更新矩阵并决定搜索方向,线性搜索模块采用黄金分割法在搜索方向上确定搜索步长,梯度计算模块完成目标函数梯度的计算;另外目标函数Object_function是拟牛顿算法需要求解的目标函数;片外存储单元Off-chip DRAM是用来存储计算工程中需要的计算信息;计算控制单元Computation Scheduling controller是来安排上述几个模块的操作顺序及内存与相对应模块的数据传递。
所述步骤(2)设计的算法考虑到拟牛顿算法的通用性,将不同的算法结构参数化。
所述步骤(2)利用visual studio 2013运行实现的算法,以验证算法功能的正确性。
所述步骤(3)利用高层次综合工具的优化方法来对算法进行优化,优化结果满足设计约束,不仅RTL代码正确,而且运行速度达到预期,其中优化包括代码转换和指令优化,并利用高级综合工具自带的软硬件联合仿真验证生成的RTL代码的正确性。
所述步骤(4)FPGA型号为Net-FPGA SUME(xc7vx690t),对算法的资源利用和运行时间分别作性能测试。
本发明相对于现有技术有以下有益效果:本发明通过高层次综合工具将C,C++设计的拟牛顿算法转化为RTL代码,并在Net-FPGA SUME(xc7vx690t)开发板上综合实现。本发明可达到的有益效果为:
1)设计频率可以达到100MHz;2)三个计算模块Compute_grad,QN_formula和Line_search不受目标函数影响,通用性好;3)相对于软件实现,该方法的运行速度提高了36倍;4)降低了FPGA的开发难度。
附图说明
图1拟牛顿算法的实现模块组成框图。
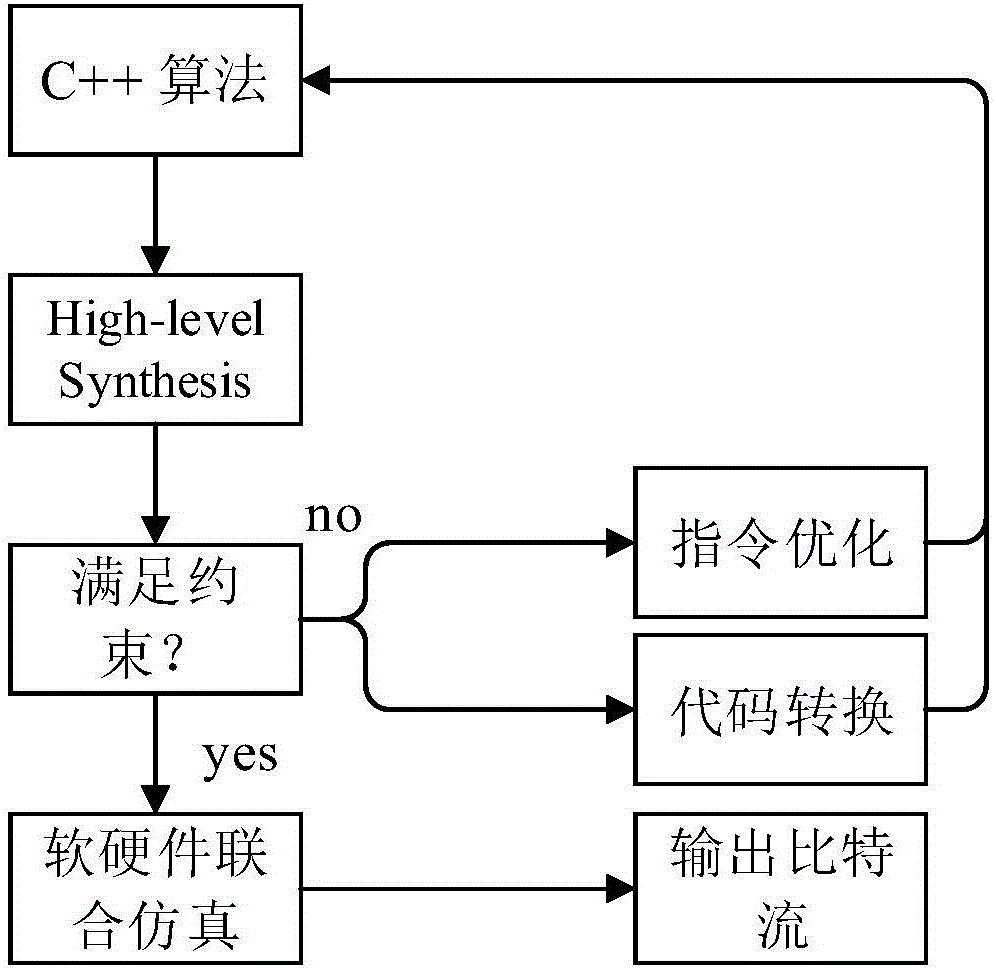
图2本发明高层次综合HLS流程图。
图3不同优化方案优化结果运行时间的对比图。
具体实施方式
下面通过具体实施例和附图对本发明作进一步的说明。本发明的实施例是为了更好地使本领域的技术人员更好地理解本发明,并不对本发明作任何的限制。
本发明基于FPGA的高级综合实现拟牛顿算法加速的方法,包括以下步骤:
(1)、分析拟牛顿算法的功能,划分出拟牛顿算法的主要计算模块,拟牛顿算法的实现模块组成框图如图1所示。具体如下:将算法划分成三个主要计算模块,分别是梯度计算模块Compute_grad,矩阵更新模块QN_formula和线性搜索模块Line_search;矩阵更新模块以BFGS方式更新矩阵并决定搜索方向,线性搜索模块采用黄金分割法在搜索方向上确定搜索步长,梯度计算模块完成目标函数梯度的计算;另外目标函数Object_function是拟牛顿算法需要求解的目标函数;片外存储单元Off-chip DRAM是用来存储计算工程中需要的计算信息;计算控制单元Computation Scheduling controller是来安排上述几个模块的操作顺序及内存与相对应模块的数据传递。
(2)、利用高级语言C,C++实现上述步骤(1)中的各个模块,并且利用visual studio 2013运行实现的算法,以验证算法功能的正确性。
验证算法功能的正确性,设计的算法考虑到拟牛顿算法的通用性,将不同的算法结构参数化。
(3)、将上述步骤(2)功能验证正确的拟牛顿算法作为输入文件,利用高层次综合工具,将高级语言转化为RTL级语言,验证生成的RTL代码;在这个过程中可以利用高层次综合工具的一些优化方法来对算法进行优化,优化结果满足设计约束,不仅RTL代码正确,而且运行速度达到预期,其中,优化包括代码转换和指令优化,并利用高级综合工具自带的软硬件联合仿真验证生成的RTL代码的正确性。
(4)、将生成的RTL代码制作成比特流文件,下载配置到FPGA的可配置逻辑部分。FPGA型号为Net-FPGA SUME(xc7vx690t),分别对算法的资源利用和运行时间作性能测试。本发明的高层次综合流程图如图2所示。
具体实施例:
本发明中将目标函数模块设定为人工神经网络,根据上述步骤(1)至步骤(4),下文将对各个步骤进行详细说明。
拟牛顿算法的实现模块组成框图如图1所示,由梯度计算模块(Compute_grad),矩阵更新模块(QN_formula),线性搜索模块(Line_search)和人工神经网络(Object_function)组成。首先梯度计算模块会根据人工神经网络的每组训练集输出梯度值,基于初始向量和梯度值计算搜寻方向,然后黄金分割法利用搜索方向寻找最佳搜索步长,计算目标函数,也就是人工神经网络的极值。矩阵更新模块中计算最密的操作是矩阵向量乘,利用最佳步长和目标函数极值对矩阵进行更新。
由于人工神经网络的架构是三层神经网络架构,每层有不同的输入和输出个数,那么针对不同的输入输出参数,本发明在设计之初就将这三层神经网络的架构进行了参数化设计,可以每次训练不同的架构时,只需要将参数对应的数字进行修改,不需要重新综合布局布线,方便了训练不同架构的神经网络。
如图2高层次综合流程图所示,HLS高层次综合工具对算法进行综合的过程中,针对拟牛顿算法的代码,本发明做的优化有四种方案:A)循环展开和数组拆分;B)循环融合;C)函数生成;D)循环流水线化。每个优化的方案本发明都同未优化的方案做了对比,运行时间对比结果如图3所示,可以看到优化方法对于方案的优化还是非常有效的。
将得到的RTL代码生成比特流文件,下载到Net-FPGA SUME(xc7vx690tffg1761-3)开发板上进行板级调试。该硬件设计最高时钟频率是100MHz,相对于软件运行速度,提高了36倍,表1示出拟牛顿算法的资源利用情况。
表1拟牛顿算法的资源利用
应当理解的是,这里所讨论的实施方案及实例只是为了说明,对本领域技术人员来说,可以加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
相关文献:
[1]E.Nurvitadhi,J.Sim,D.Sheffield,A.Mishra,S.Krishnan,and D.Marr,“Accelerating recurrent neural networks in analytics servers:Comparison of fpga,cpu,gpu,and asic,”in 2016 26th International Conference on Field Programmable Logic and Applications(FPL),Aug 2016,pp.1–4.
[2]E.Nurvitadhi,J.Sim,D.Sheffield,A.Mishra,S.Krishnan,and D.Marr,“Accelerating recurrent neural networks in analytics servers:Comparison of fpga,cpu,gpu,and asic,”in 2016 26th International Conference on Field Programmable Logic and Applications(FPL),Aug 2016,pp.1–4.
[3]F.Ortega-Zamorano,J.M.Jerez,and L.Franco,“FPGA implementation of the C-mantec neural network constructive algorithm,”IEEE Transactions on Industrial Informatics,vol.10,no.2,pp.1154–1161,May 2014.
[4]党宏社,王黎,王晓倩.基于Vivado HLS的FPGA开发与应用研究[J].陕西科技大学学报,2015,33(1):155-159.
[5]Coussy P,Gajski D D,Meredith M,et al.An introduction to high-level synthesis[J].IEEE Design&Test of Computers,2009,26(4):8-17.
- 还没有人留言评论。精彩留言会获得点赞!