聚类实现方法和装置与流程
本发明实施例涉及数据处理技术,尤其涉及一种聚类实现方法和装置。
背景技术:
所谓聚类,是指将物理或抽象对象的集合分成由类似的对象组成的多个类的过程。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法,同时也是数据挖掘的一个重要算法。
其中,K-means(也称为K均值)是一类非常经典的基于划分的聚类分析方法,是十大经典数据挖掘算法之一,其算法简单、收敛速度快且易于实现,应用领域非常广泛。K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近它们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
在超大规模图片(典型的,百亿级)聚类中一般需要使用K-means算法,但是在对图片的聚类过程中对算法的时间消耗和空间消耗都非常大。因此,如何降低K-means算法的计算复杂度,以及减少空间消耗,是当前人们广泛研究的重点问题。
技术实现要素:
有鉴于此,本发明实施例提供一种聚类实现方法和装置,以优化现有的K-means聚类算法,降低K-means聚类算法的计算复杂度。
第一方面,本发明实施例提供了一种聚类实现方法,包括:
对待聚类数据集的聚类中心进行初始化,其中,初始化聚类中心的数量与预设的聚类数目相匹配;
根据所述聚类中心,计算与所述待聚类数据集中的各数据点分别对应的最近聚类中心,其中,在计算所述最近聚类中心过程中消除了数据点自身平方计算带来的冗余;
根据所述待聚类数据集中的各数据点的所述最近聚类中心的计算结果,更新所述聚类中心;
返回执行根据所述聚类中心,计算与所述待聚类数据集中的各数据点分别对应的最近聚类中心的操作,直至满足聚类迭代结束条件。
第二方面,本发明实施例还提供了一种聚类实现装置,包括:
聚类中心初始化模块,用于对待聚类数据集的聚类中心进行初始化,其中,初始化聚类中心的数量与预设的聚类数目相匹配;
最近聚类中心计算模块,用于根据所述聚类中心,计算与所述待聚类数据集中的各数据点分别对应的最近聚类中心,其中,在计算所述最近聚类中心过程中消除了数据点自身平方计算带来的冗余;
聚类中心更新模块,用于根据所述待聚类数据集中的各数据点的所述最近聚类中心的计算结果,更新所述聚类中心;
重复迭代模块,用于返回执行根据所述聚类中心,计算与所述待聚类数据集中的各数据点分别对应的最近聚类中心的操作,直至满足聚类迭代结束条件。
本发明实施例提供的聚类实现方法及装置,在使用K-means聚类算法的过程中,通过分析确定K-means聚类算法自身算法的执行步骤中存在的冗余,使用巧妙的变换消除了在计算各个数据点的最小聚类中心时,数据点自身平方计算带来的冗余,优化了现有的K-means聚类算法,降低了K-means聚类算法的计算复杂度。
附图说明
图1是现有技术中的K-means聚类算法的实现流程图;
图2是本发明实施例一提供的一种聚类实现方法的流程图;
图3a是本发明实施例二提供的一种聚类实现方法的流程图;
图3b是本发明实施例二提供的聚类实现方法与现有的聚类实现方法之间的计算量对比图;
图4a是本发明实施例三提供的一种聚类实现方法的流程图;
图4b是本发明实施例三提供的一种聚类实现方法的具体应用示意图;
图4c是本发明实施例三提供的一种聚类实现方法的数据流式处理示意图;
图5是本发明实施例提供的一种具体应用场景的示意图;
图6是本发明实施例四提供的一种聚类实现装置的结构图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部内容。在更加详细地讨论示例性实施例之前应当提到的是,一些示例性实施例被描述成作为流程图描绘的处理或方法。虽然流程图将各项操作(或步骤)描述成顺序的处理,但是其中的许多操作可以被并行地、并发地或者同时实施。此外,各项操作的顺序可以被重新安排。当其操作完成时所述处理可以被终止,但是还可以具有未包括在附图中的附加步骤。所述处理可以对应于方法、函数、规程、子例程、子程序等等。
首先,为了便于理解,首先将现有的K-means聚类算法的实现原理进行简单介绍。
在图1中示出了现有的K-means聚类算法的实现流程图。其中,根据算法流程,给定的输入数据集如下:
输入数据集x(n*m):给定数据集x,包含n个数据点x[0]…x[n-1],其中,每个数据点是一个m维向量;另外,给定聚类的数目为k。
现有的K-means聚类算法的实现流程如下:
1、首先,对数据集x初始化,例如:归一化;
2、之后,选择k个初始聚类中心,例如:c[0]=data[0],…,c[k-1]=data[k-1];
3、对于数据集x[0]…x[n-1],分别计算其与聚类中心c[0],…,c[k-1]之间的欧式距离,得到d[i][j](表示数据集x中的第i个数据点x[i]与聚类中心c的第j个中心点c[j]的欧式距离);
4、对于x的每一个数据点x[i],取最近的聚类中心c[j]=argminj(d[i]j)(其中,j=0,1,…,k-1),作为该点所属的新类别。
5、对于每个聚类中心c[j],根据新的划分重新计算新的聚类中心;
6、重复执行3、4、5,直到所有的c[j]值的变化小于给定阈值或达到最大迭代次数。
通过对现有的K-means聚类算法的实现流程进行复杂度分析,可以看出该算法的主要计算量在第3和第4两个步骤上,时间复杂度达到O(n*k*m),空间复杂度达到O(n*k*m)。
针对K-means聚类算法,目前主要的算法加速方式包括:通过对数据集进行划分,然后通过MPI(Message Passing Interface,信息传递接口)、OpenMP(Open Multi-Processing,共享存储并行编程)或MapReduce(一种大规模数据集的并行运算)的方式进行多线程、多进程、或多机的方式加速。
而现有的针对K-means聚类算法的实现流程的主要缺陷在于:单机数据聚类的上限比较低,主要受限于时间和空间复杂度;已有的算法加速方案没有考虑到K-means算法的多个计算步骤中的一些冗余性;已有方案没有考虑到当今主流的硬件体系结构和指令集,无法充分发挥硬件的计算效能。
实施例一
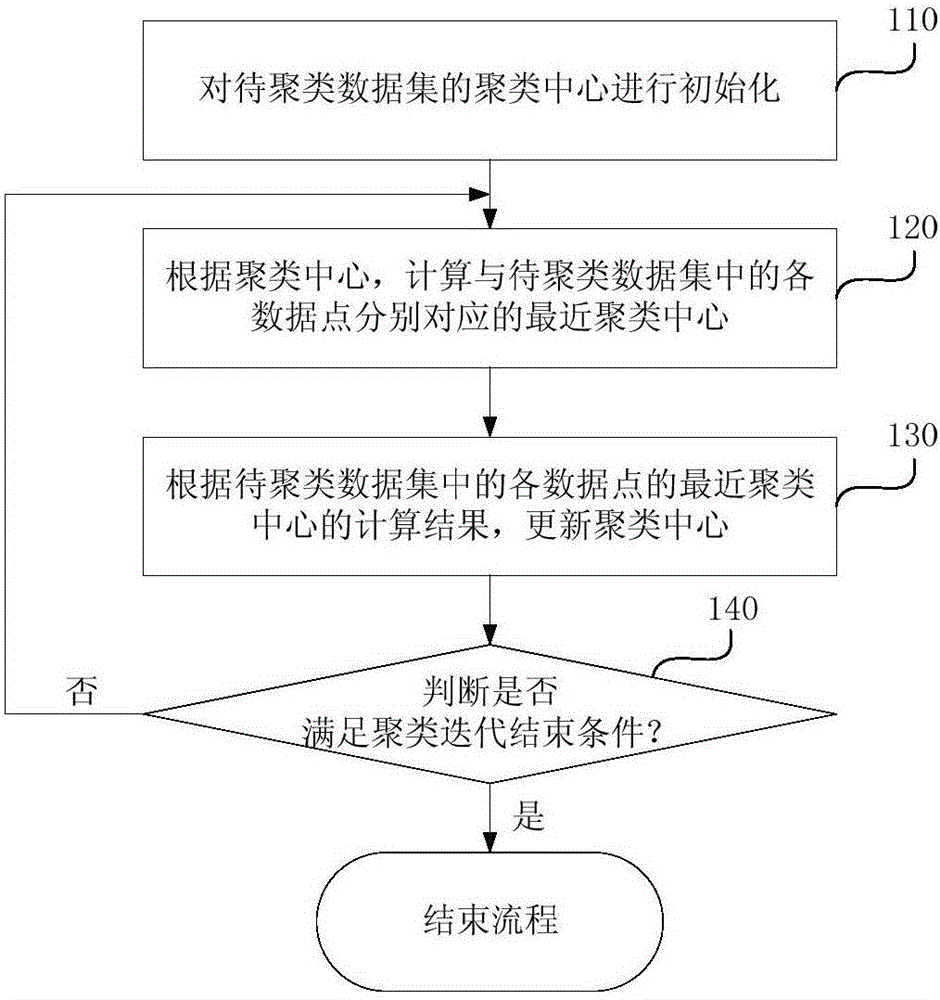
图1为本发明实施例一提供的一种聚类实现方法的流程图,该方法可以由聚类实现装置执行,该装置可由软件和/或硬件实现,并一般可集成于用于完成聚类功能的服务器或者终端设备中,并一般可以由所述服务器或者终端设备的CPU(Central Processing Unit,中央处理器)或者GPU(Graphics Processing Unit,图形处理器)来执行。如图1所示,本实施例的方法具体包括:
110、对待聚类数据集的聚类中心进行初始化。
其中,初始化聚类中心的数量与预设的聚类数目相匹配。所述聚类数目具体是指最终需要聚类出的聚类类别的数量值。
在本实施例中,所述待聚类数据集中包括多个需要进行聚类的数据点,可以结合所述数据点以及所述聚类数目,对所述待聚类数据集的聚类中心进行初始化。例如,从M个所述数据点中选择k数据点作为所述k个聚类中心的初始化值。
其中,M为所述待聚类数据集中包括的数据点总数,k为所述聚类数目。
120、根据所述聚类中心,计算与所述待聚类数据集中的各数据点分别对应的最近聚类中心。
通过对现有的K-means聚类算法的实现流程进行分析可知:K-means聚类算法中主要的计算量集中在算法迭代过程,主要为:1、计算待聚类数据集中各数据点与各聚类中心的欧式距离;2、利用上一步得出的欧式距离计算待聚类数据集中每个数据点的标签(即,与所有聚类中心最小欧式距离对应的聚类中心);3、利用新的数据点标签更新聚类中心。在上述迭代过程中,主要计算量集中在计算欧式距离,此处我们将其展开:
其中,如前所述,待聚类数据集x(n*m),包含n个数据点,其中,每个数据点是一个m维向量;另外,给定聚类的数目为k。
由上式可知,在常规的K-means计算中,对于待聚类数据集中的每一个数据点xi,都需计算k次对于聚类中心中的每一个中心点cj都需计算n次
由于最终计算的是xi与每一个cj的欧式距离的最小值,对所有的cj,是等价的,故计算可以省略,也即:在本实施例中,在计算所述最近聚类中心过程中消除了数据点自身平方计算带来的冗余。
相应的,在计算di,j时,不再计算的平方,仅通过计算可以大大化简计算量。
130、根据所述待聚类数据集中的各数据点的所述最近聚类中心的计算结果,更新所述聚类中心。
在本实施例中,在确定与各数据点分别对应的最近聚类中心后,可以将各数据点分别归集于对应的最近聚类中心所属的类别中,以实现对各个数据点进行一次聚类。
在一次聚类完成后,可以进而选取各个类别中包括的各数据点的均值作为该类别的新的聚类中心,以实现对所述聚类中心的更新。
140、判断是否满足聚类迭代结束条件:若是,结束流程;否则,返回执行120。
在本实施例中,所述聚类迭代结束条件可以根据实际情况进行预设,例如:聚类中心的一次更新值小于设定阈值,或者迭代次数超过设定迭代门限值等,本实施例对此并不进行限制。
本发明实施例提供的聚类实现方法,在使用K-means聚类算法的过程中,通过分析确定K-means聚类算法自身算法的执行步骤中存在的冗余,使用巧妙的变换消除了在计算各个数据点的最小聚类中心时,数据点自身平方计算带来的冗余,优化了现有的K-means聚类算法,降低了K-means聚类算法的计算复杂度。
实施例二
图3a为本发明实施例二提供的一种聚类实现方法的流程示意图。本实施例以上述实施例为基础进行具体化,在本实施例中,将根据所述聚类中心,计算与所述待聚类数据集中的各数据点分别对应的最近聚类中心具体为:根据公式:计算所述待聚类数据集中第i个数据点xi的最近聚类中心Ci;其中,cj为第j个聚类中心,N为所述聚类数目,i∈[1,M],M为所述待聚类数据集中包括的数据点总数。相应的,本实施例的方法具体包括:
210、对待聚类数据集的聚类中心进行初始化,其中,初始化聚类中心的数量与预设的聚类数目相匹配。
220、获取所述待聚类数据集中的一个数据点xi,执行230。
如前所述,需要计算待聚类数据集中的每个数据点的最小聚类中心,因此,需要分别获取所述待聚类数据集中的各数据点,相应的,i∈[1,M],M为所述待聚类数据集中包括的数据点总数。
230、根据公式:计算所述待聚类数据集中第i个数据点xi的最近聚类中心Ci。
如实施例一所述,在计算最小聚类中心时通过对欧式距离的计算公式进行展开,可以约去数据点自身平方项。
相应的,可以通过公式:来计算每个数据点xi的最小聚类中心Ci‘。
其中,argminjf(x)代表当f(x)取得最小值是x的取值。
通过对公式:进行进一步分析可知,在计算最小聚类中心过程中,针对每个数据点,需要计算n*k次的乘2计算,以及k次
因此,可以将计算最小距离di,j等价于计算:
通过将等价于可以将n*k次乘2的乘法运算变为k次乘1/2的乘法运算,进一步减少计算量。
其中,在图3b示出了本发明实施例二提供的聚类实现方法与现有的聚类实现方法之间的计算量对比图。
具体的,优化前后运算量对比分析如表1所示。
表1
如表1所示,通过上述优化方法对K-means聚类算法进行优化后的计算量减少n*k*(m-1)–2*k*m次操作。另外,优化后算法更适合当今主流计算体系架构。因为在算法优化过程中,将平方操作(xi-cj)2优化出一个乘加操作(xi*cj)在当前流行的计算体系架构里,单指令可以直接支持乘加操作,比如ARM(Advanced RISC Machines,精简指令集计算机微处理器)架构里的MLA(Multiply Accumulate,乘加)指令可以实现乘加操作。
因此,最终优化后的实现方式,执行指令数将减少n*k*m+n*k*(m-1)–2*k*m=2*n*k*m+n*k–2*k*m。
240、判断是否完成对所述待聚类数据集中全部数据点的最近聚类中心的计算:若是,执行250;否则,返回执行220。
250、根据所述待聚类数据集中的各数据点的所述最近聚类中心的计算结果,更新所述聚类中心。
260、判断是否满足聚类迭代结束条件:若是,结束流程;否则,返回执行220。
在确定不满足聚类迭代结束条件,需要返回220,重新开始依次获取待聚类数据集中的一个数据点,并分别计算与各数据点分别对应的最近聚类中心。
本发明实施例的技术方案通过公式:计算与所述待聚类数据集中的各数据点分别对应的最近聚类中心,充分利用到了K-means聚类算法执行步骤中存在的冗余,并通过巧妙的方式将计算任务转换成硬件擅长计算的指令,进一步优化了现有的K-means聚类算法,降低了K-means聚类算法的计算复杂度。
实施例三
图4a为本发明实施例三提供的一种聚类实现方法的流程示意图。本实施例以上述实施例为基础进行具体化,在本实施例中,将根据所述聚类中心,计算与所述待聚类数据集中的各数据点分别对应的最近聚类中心进一步具体为:将所述待聚类数据集切分为至少两个数据子集;获取一个数据子集作为当前操作数据子集;将所述当前操作数据子集拷贝至显存中,并通过访问所述显存计算与所述当前操作数据子集中的各数据点分别对应的最近聚类中心;返回执行获取一个数据子集作为当前操作数据子集的操作,直至完成对所述待聚类数据集中全部数据子集的处理。相应的,本实施例的方法具体包括:
310、对待聚类数据集的聚类中心进行初始化,其中,初始化聚类中心的数量与预设的聚类数目相匹配。
320、将所述待聚类数据集切分为至少两个数据子集。
除了计算复杂度,K-means聚类算法中另一核心问题是空间复杂度,优化计算复杂度使算法收敛更快,优化空间复杂度使算法规模更大,适用于更广泛的领域。
一般来说,通过CPU执行对所述待聚类数据的K-means聚类算法,无需考虑内存容量问题,但是如果通过GPU实现上述K-means聚类算法,考虑到显存的大小限制,往往无法实现大规模数据的聚类,此时常见的方案是通过多机的方式突破单机的存储限制。针对这一问题,发明人创造性的提出了:对待聚类数据集分批处理的方式以在单机模式下支持更大的数据规模。
在GPU模式下,由于GPU显存限制,无法将整个数据集放在显存中。假设当前显存可支撑处理数据集x(大小为n*m)的任务,而现有数据集的大小为p*n*m,无法全部放到显存中。考虑到矩阵乘法(算法优化后的K-means聚类算法中主要的计算过程为矩阵乘法)的可分离性,可以将数据集x(p*n*m)切分为p个(n*m)的子数据集,在单次迭代中,依次将一个数据子集从内存中拷贝到GPU显存中完成计算。其中,在图4b中示出了本发明实施例三提供的一种聚类实现方法的具体应用示意图。
在本实施例中,为了实现在单机模式下支持更大的数据规模,需要对待聚类数据集进行分批处理。即:将所述待聚类数据集切分为至少两个数据子集,其中,切分的数据子集中包括的数据点可以相同也可以不同,但是,为了保证每次迭代的运算速度,可选的,各所述数据子集中包括的数据点均相同。
其中,为了保证切分的每个数据子集中包括的数据点均相同,所述将所述待聚类数据集切分为至少两个数据子集可以包括:
预先设定切分数量Q;根据公式B=M%Q,计算待滤除数据点数量B,其中,M为所述待聚类数据集中包括的数据点总数,%为求余运算;从所述待聚类数据集中滤除B个数据点后,生成齐整待聚类数据集;将所述齐整待聚类数据集切分为Q个包含相同数量数据点的数据子集。
在一个具体例子中,待聚类数据集中包括的数据点总数为300,预先设定的切分数量为7,显然,无法保证每个数据子集中包括的数据点均相同。因此,可以首先计算300%7=6,因此,可以首先在待聚类数据集中去除6个数据点,进而可以保证剩下的294个数据点可以均匀的分配在7个数据子集中。
330、获取一个数据子集作为当前操作数据子集。
340、将所述当前操作数据子集拷贝至显存中,并通过访问所述显存计算与所述当前操作数据子集中的各数据点分别对应的最近聚类中心。
在本实施例中,将所述当前操作数据子集拷贝至显存中可以包括:通过统一计算设备架构流将所述当前操作数据子集拷贝至显存中。
在本实施例的一个可选的实施方式中,为了进一步加快K-means聚类算法的收敛速度,可以使用CUDA(Compute Unified Device Architecture,统一计算设备架构流)将数据拷贝过程进行隐藏,其中,在图4c示出了本发明实施例三提供的一种聚类实现方法的数据流式处理示意图。
如图4c所示,当计算完当前显存中数据子集与各聚类中心的欧式距离之后,对该数据子集所占用的空间即可释放,此时即可开始下一批数据的传输,而无需等待所有的计算完成,以此可实现数据拷贝的隐藏。
350、判断是否完成对所述待聚类数据集中全部数据子集的处理:若是,执行360;否则,返回执行330。
360、根据所述待聚类数据集中的各数据点的所述最近聚类中心的计算结果,更新所述聚类中心。
370、判断是否满足聚类迭代结束条件:若是,结束流程;否则,返回执行320。
本实施例的技术方案通过对待聚类数据集进行数据切分,实现对待聚类数据集的分批处理,通过显存复用,可在同样计算资源下完成更大规模的数据聚类。另外,利用CUDA的流式操作将数据拷贝进行隐藏,可进一步加快K-means聚类算法的收敛速度。
进一步的,在图5中示出了本发明实施例的一种具体的应用场景的示意图,在本具体应用场景中,所述待聚类数据集中包括的数据点为图片数据点,其中,所述图片数据点中包括至少两个维度的图片特征。
另外,需要说明的是,在发明人实现本发明的过程中使用的图片特征一般是远大于2维的,通常会达到上千维,实验时采用的是1024维;通过对图5所示的应用场景进行反复试验发现,本发明实施例的技术方案可以极大加速超大规模图片聚类流程,其中的K-means聚类算法执行时间速度提升至少在10倍以上。而最好的GPU版本比最差的CPU版本快300倍以上。
实施例四
图6为本发明实施例四提供的一种聚类实现装置的结构图。如图6所示,所述装置包括:聚类中心初始化模块41、最近聚类中心计算模块42、聚类中心更新模块43以及重复迭代模块44。
聚类中心初始化模块41,用于对待聚类数据集的聚类中心进行初始化,其中,初始化聚类中心的数量与预设的聚类数目相匹配。
最近聚类中心计算模块42,用于根据所述聚类中心,计算与所述待聚类数据集中的各数据点分别对应的最近聚类中心,其中,在计算所述最近聚类中心过程中消除了数据点自身平方计算带来的冗余。
聚类中心更新模块43,用于根据所述待聚类数据集中的各数据点的所述最近聚类中心的计算结果,更新所述聚类中心。
重复迭代模块44,用于返回执行根据所述聚类中心,计算与所述待聚类数据集中的各数据点分别对应的最近聚类中心的操作,直至满足聚类迭代结束条件。
本发明实施例提供的聚类实现装置,在使用K-means聚类算法的过程中,通过分析确定K-means聚类算法自身算法的执行步骤中存在的冗余,使用巧妙的变换消除了在计算各个数据点的最小聚类中心时,数据点自身平方计算带来的冗余,优化了现有的K-means聚类算法,降低了K-means聚类算法的计算复杂度。
在上述各实施例的基础上,所述最近聚类中心计算模块,具体可以用于:
根据公式:计算所述待聚类数据集中第i个数据点xi的最近聚类中心Ci;
其中,cj为第j个聚类中心,N为所述聚类数目,i∈[1,M],M为所述待聚类数据集中包括的数据点总数。
在上述各实施例的基础上,所述最近聚类中心计算模块进一步可以包括:
待聚类数据集切分单元,用于将所述待聚类数据集切分为至少两个数据子集;
当前操作数据子集获取单元,用于获取一个数据子集作为当前操作数据子集;
最近聚类中心显存计算单元,用于将所述当前操作数据子集拷贝至显存中,并通过访问所述显存计算与所述当前操作数据子集中的各数据点分别对应的最近聚类中心;
重复处理单元,用于返回执行获取一个数据子集作为当前操作数据子集的操作,直至完成对所述待聚类数据集中全部数据子集的处理。
在上述各实施例的基础上,所述待聚类数据集切分单元具体可以用于:
预先设定切分数量Q;
根据公式:B=M%Q,计算待滤除数据点数量B,其中,M为所述待聚类数据集中包括的数据点总数,%为求余运算;
从所述待聚类数据集中滤除B个数据点后,生成齐整待聚类数据集;
将所述齐整待聚类数据集切分为Q个包含相同数量数据点的数据子集。
在上述各实施例的基础上,所述最近聚类中心显存计算单元具体可以用于:
通过统一计算设备架构流将所述当前操作数据子集拷贝至显存中。
在上述各实施例的基础上,所述待聚类数据集中包括的数据点可以为图片数据点,其中,所述图片数据点中可以包括至少两个维度的图片特征。
本发明实施例所提供的聚类实现装置可用于执行本发明任意实施例提供的聚类实现方法,具备相应的功能模块,实现相同的有益效果。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!