一种基于改进鸡群算法的盲源分离方法与流程
本发明涉及信号处理领域,尤其涉及一种基于改进鸡群算法的盲源分离方法。
背景技术:
盲源分离(blind source separation,BSS)是指在源信号和传递信道等先验信息未知的前提下,根据信号的统计独立特性将源信号从观测到的混合信号中恢复出来。
盲源分离的核心问题是分离矩阵的学习算法,其基本思想是以统计独立的特征作为输入的表示,使目标函数达到极大(或极小)。常用盲源分离方法如InforMax算法、FastICA算法等大多涉及非线性函数的选取问题,这些函数模型的选择主要取决于源信号的概率密度性质,然而实际应用中源信号的概率密度性质在信号分离前是未知的,非线性函数的选取极大地影响了算法的分离能力。
技术实现要素:
为解决上述问题,本发明给出一种基于改进鸡群算法的盲源分离方法,将信号峭度绝对值和负熵加权平均后的负值作为目标函数,通过改进鸡群算法最小化目标函数,得到最优解即最佳分离矩阵,从而实现对混合观测信号的分离。该方法对源信号概率密度性质没有依赖,适用于各种类型混合信号的分离,收敛速度快,精度高,不易陷入局部最优。
为达到上述目的,本发明提供如下技术方案:
一种基于改进鸡群算法的盲源分离方法,包括以下步骤(1)~(3):
(1)采集源信号S(t)=[s1(t),s2(t),...,sM(t)]T,随机产生非奇异混合矩阵A,混合矩阵A对源信号S(t)进行线性混合得到观测信号X(t)=[x1(t),x2(t),...,xM(t)]T,X(t)=AS(t);其中sM(t)是源信号S(t)的第M个分量,xM(t)是观测信号X(t)的第M个分量,t为时间序列,上标T表示共轭转置,M为正整数,A是M×M维矩阵;
(2)对步骤(1)中得到的观测信号X(t)进行中心化和白化后得到预处理信号Z(t),中心化和白化为现有成熟技术,具体原理此处不再赘述;
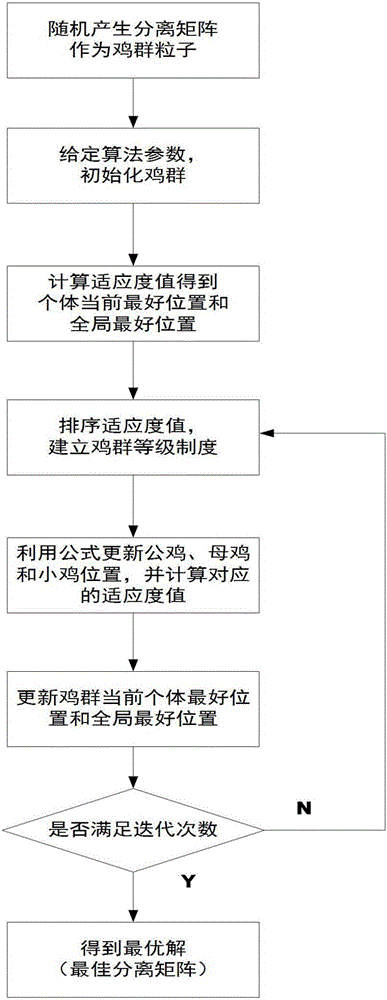
(3)随机产生分离矩阵作为改进鸡群算法初始粒子,根据得到的预处理信号Z(t),利用改进鸡群算法迭代更新得到最优解即最佳分离矩阵W,将X(t)送至W得到最佳分离信号Y(t)=[y1(t),y2(t),...,yM(t)]T,Y(t)=WX(t),完成混合信号的分离。
本发明的一种基于改进鸡群算法的盲源分离方法,所述步骤(3)中利用改进鸡群算法得到最优解即最佳分离矩阵W的具体步骤如下:
(3.1)初始化鸡群,设置最大迭代次数t1=M1,鸡群粒子数N=100,随机产生分离矩阵作为鸡群粒子,定义公鸡粒子个数NR=0.15N,母鸡粒子个数NH=0.7N,小鸡粒子个数NC=0.25N,妈妈母鸡粒子个数NM=0.5NH;
(3.2)设置适应度函数fitness,将预处理后的信号Z(t)送至随机产生的分离矩阵(鸡群粒子)得到初始分离信号,对初始分离信号进行中心化、白化操作,带入适应度函数fitness计算鸡群粒子的适应度值,设定粒子当前最好位置和鸡群全局最好位置,鸡群算法迭代次数t1=1;
(3.3)如果t1/G=1(即当前为第一代),从小到大排序适应度值并根据公鸡、母鸡和小鸡粒子个数确定公鸡、母鸡和小鸡的划分,建立鸡群等级制度,将鸡群分成数个子群并确定母鸡粒子和小鸡粒子的对应母子关系(每个子群中有一个公鸡粒子和若干母鸡粒子和小鸡粒子构成),其中,G表示开始更新等级制度、支配关系和母子关系的代数,G=10;
(3.4)根据公式(1):
xir,j(t1+1)=xir,j(t1)·(1+Φ(0,σ2))………………………………(1)
来更新公鸡粒子位置,其中,xir,j(t1),xir,j(t1+1)分别代表公鸡粒子ir在第t1次和t1+1次迭代中于第j维空间所处的位置;Φ(0,σ2)是一个方差为σ2的高斯分布,σ2表达式为:
其中,fir和fkr代表公鸡粒子ir和公鸡粒子kr的适应度值,ε是一个极小的常数,用来保证分母有意义,NR为整个鸡群公鸡粒子数目,kr为所有公鸡粒子中除去ir后的任一个体,当公鸡粒子ir的适应度值好于公鸡粒子kr的适应度值,方差σ2为1,公鸡粒子ir的搜索空间变大,反之σ2降低,公鸡粒子ir的搜索空间缩小;
(3.5)母鸡粒子将跟随其子群的公鸡粒子进行搜索,同时也跟随其他子群的公鸡粒子进行搜索,根据公式(3)
xih,j(t1+1)=xih,j(t1)+C1·θ·(xr1,j(t1)-xih,j(t1))+C2·θ·(xr2,j(t1)-xih,j(t1))……(3)
更新母鸡粒子位置,其中,xr1,j(t1),xr2,j(t1)分别代表母鸡粒子所属子群的公鸡粒子和其他子群公鸡粒子的位置信息,θ为0到1之间均匀分布的随机数,C1和C2分别代表母鸡粒子参考自身子群和其他子群权重,根据公式(4)、(5)
C1=exp((fih-fr1)/(abs(fir+ε))…………………………………(4)
C2=exp((fr2-fir))……………………………………(5)
得到,其中,fih和fr1分别代表母鸡粒子ih和所属子群公鸡粒子r1的适应度值,fr2代表随机选取的其他子群公鸡粒子的适应度值;
(3.6)小鸡粒子不仅跟随其子群的妈妈母鸡粒子进行搜索,同时向所在子群公鸡学习,根据式(6)
xic,j(t1+1)=w·xic,j(t1)+F·(xm,j(t1)-xic,j(t1))+C·(xr,j(t1)-xic,j(t1))…………(6)
更新小鸡位置,其中,xm,j(t1)代表小鸡粒子所跟随妈妈母鸡粒子的位置信息,xr,j(t1)代表妈妈母鸡粒子自身所在子群中的公鸡粒子位置信息,C为学习因子,取值0.5,表示小鸡粒子向自身所在子群中公鸡粒子学习的程度,w为小鸡粒子自身惯性权重,这里采用自适应惯性权重,通过公式(7)
w=(wmax-wmin)*exp(-(τ*((t1-1)/(M1-1))2)+wmin……………………(7)
得到粒子自身自适应权重,其中,wmax是惯性权重的最大值,wmin是惯性权重的最小值,τ取50,F为跟随系数,表示小鸡粒子跟随妈妈母鸡粒子寻找食物;
(3.7)利用公式(1)~(7)更新公鸡、母鸡和小鸡粒子位置后计算每个粒子的适应度值,更新鸡群的粒子当前最好位置和鸡群全局最好位置;
(3.8)t1=t1+1,若达到迭代次数,则停止迭代,得到最优位置(最优解),即最佳分离矩阵W,否则转到步骤(3.3)。
本发明的一种基于改进鸡群算法的盲源分离方法,所述步骤(3)中改进鸡群算法适应度函数fitness为分离信号负熵与峭度绝对值的加权平均,具体实现为:
fitness=-(|0.4×fitness1+0.6×fitness2|/2)……………………(8)
式(8)中,表示信号负熵,其中yi表示第i个分离信号;表示信号峭度的绝对值,其中kurt(yi)为第i个分离信号的峭度,适应度函数值越小表明分离效果越好。
本发明的有益效果:将分离信号负熵和峭度绝对值的加权平均作为传统鸡群算法的目标函数,避免了常用盲源分离方法如InforMax算法、FastICA算法等涉及的非线性函数选取问题,同时,对传统鸡群算法改进,使小鸡粒子位置具有自适应惯性权重和向所在子群公鸡学习的能力,克服传统鸡群算法小鸡粒子易陷入局部的缺陷,本发明方法具有收敛速度快,串音误差小的优点,在无线通信,信号处理等领域具有广泛的应用前景。
附图说明
图1是一种基于改进鸡群算法的盲源分离方法整体流程图
图2是改进鸡群算法流程图
具体实施方式
本发明提供一种基于改进鸡群算法的盲源分离方法,该方法对源信号概率密度性质没有依赖,适用于各种类型混合信号的分离,收敛速度快,精度高,不易陷入局部最优。
为达成上述目的,本发明的具体实施方式如下:
(1)采集源信号S(t)=[s1(t),s2(t),...,sM(t)]T,随机产生非奇异混合矩阵A,混合矩阵A对源信号S(t)进行线性混合得到观测信号X(t)=[x1(t),x2(t),...,xM(t)]T,X(t)=AS(t);其中sM(t)是源信号S(t)的第M个分量,xM(t)是观测信号X(t)的第M个分量,t为时间序列,上标T表示共轭转置,M为正整数,A是M×M维矩阵;
(2)对步骤(1)中得到的观测信号X(t)进行中心化和白化后得到预处理信号Z(t),中心化和白化为现有成熟技术,具体原理此处不再赘述;
(3)随机产生分离矩阵作为改进鸡群算法初始粒子,根据得到的预处理信号Z(t),利用改进鸡群算法迭代更新得到最优解即最佳分离矩阵W,将X(t)送至W得到最佳分离信号Y(t)=[y1(t),y2(t),...,yM(t)]T,Y(t)=WX(t),完成混合信号的分离。改进鸡群算法得到最优解即最佳分离矩阵W的具体步骤如下:
(3.1)初始化鸡群,设置最大迭代次数t1=M1,鸡群粒子数N=100,随机产生分离矩阵作为鸡群粒子,定义公鸡粒子个数NR=0.15N,母鸡粒子个数NH=0.7N,小鸡粒子个数NC=0.25N,妈妈母鸡粒子个数NM=0.5NH;
(3.2)设置适应度函数fitness,适应度函数fitness为分离信号负熵与峭度绝对值的加权平均,具体实现为:fitness=-(|0.4×fitness1+0.6×fitness2|/2),其中表示信号负熵,其中yi表示第i个分离信号;表示信号峭度的绝对值,其中kurt(yi)为第i个分离信号的峭度,适应度函数值越小表明分离效果越好。将预处理后的信号Z(t)送至随机产生的分离矩阵(鸡群粒子)得到初始分离信号,对初始分离信号进行中心化、白化操作,带入适应度函数fitness计算鸡群粒子的适应度值,设定粒子当前最好位置和鸡群全局最好位置,鸡群算法迭代次数t1=1;
(3.3)如果t1/G=1(即当前为第一代),从小到大排序适应度值并根据公鸡、母鸡和小鸡粒子个数确定公鸡、母鸡和小鸡的划分,建立鸡群等级制度,将鸡群分成数个子群并确定母鸡粒子和小鸡粒子的对应母子关系(每个子群中有一个公鸡粒子和若干母鸡粒子和小鸡粒子构成),其中,G表示开始更新等级制度、支配关系和母子关系的代数,G=10;
(3.4)根据公式(1):
xir,j(t1+1)=xir,j(t1)·(1+Φ(0,σ2))………………………………(1)
来更新公鸡粒子位置,其中,xir,j(t1),xir,j(t1+1)分别代表公鸡粒子ir在第t1次和t1+1次迭代中于第j维空间所处的位置;Φ(0,σ2)是一个方差为σ2的高斯分布,σ2表达式为:
其中,fir和fkr代表公鸡粒子ir和公鸡粒子kr的适应度值,ε是一个极小的常数,用来保证分母有意义,NR为整个鸡群公鸡粒子数目,kr为所有公鸡粒子中除去ir后的任一个体,当公鸡粒子ir的适应度值好于公鸡粒子kr的适应度值,方差σ2为1,公鸡粒子ir的搜索空间变大,反之σ2降低,公鸡粒子ir的搜索空间缩小;
(3.5)母鸡粒子将跟随其子群的公鸡粒子进行搜索,同时也跟随其他子群的公鸡粒子进行搜索,根据公式(3)
xih,j(t1+1)=xih,j(t1)+C1·θ·(xr1,j(t1)-xih,j(t1))+C2·θ·(xr2,j(t1)-xih,j(t1))……(3)
更新母鸡粒子位置,其中,xr1,j(t1),xr2,j(t1)分别代表母鸡粒子所属子群的公鸡粒子和其他子群公鸡粒子的位置信息,θ为0到1之间均匀分布的随机数,C1和C2分别代表母鸡粒子参考自身子群和其他子群权重,根据公式(4)、(5)
C1=exp((fih-fr1)/(abs(fir+ε))……………………………(4)
C2=exp((fr2-fir))…………………………………(5)
得到,其中,fih和fr1分别代表母鸡粒子ih和所属子群公鸡粒子r1的适应度值,fr2代表随机选取的其他子群公鸡粒子的适应度值;
(3.6)小鸡粒子不仅跟随其子群的妈妈母鸡粒子进行搜索,同时向所在子群公鸡学习,根据式(6)
xic,j(t1+1)=w·xic,j(t1)+F·(xm,j(t1)-xic,j(t1))+C·(xr,j(t1)-xic,j(t1))……………(6)
更新小鸡位置,其中,xm,j(t1)代表小鸡粒子所跟随妈妈母鸡粒子的位置信息,xr,j(t1)代表妈妈母鸡粒子自身所在子群中的公鸡粒子位置信息,C为学习因子,取值0.5,表示小鸡粒子向自身所在子群中公鸡粒子学习的程度,w为小鸡粒子自身惯性权重,这里采用自适应惯性权重,通过公式(7)
w=(wmax-wmin)*exp(-(τ*((t1-1)/(M1-1))2)+wmin……………………(7)
得到粒子自身自适应权重,其中,wmax是惯性权重的最大值,wmin是惯性权重的最小值,τ取50,F为跟随系数,表示小鸡粒子跟随妈妈母鸡粒子寻找食物;
(3.7)利用公式(1)~(7)更新公鸡、母鸡和小鸡粒子位置后计算每个粒子的适应度值,更新鸡群的粒子当前最好位置和鸡群全局最好位置;
(3.8)t1=t1+1,若达到迭代次数,则停止迭代,得到最优位置(最优解),即最佳分离矩阵W,否则转到步骤(3.3)。
以上实施例仅为说明本发明的技术思想,不能一次限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方法基础上所做的任何改动,均落入本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!