基于人工智能的提示信息推荐方法以及装置与流程
本发明涉及信息处理
技术领域:
,尤其涉及一种基于人工智能的提示信息推荐方法以及装置。
背景技术:
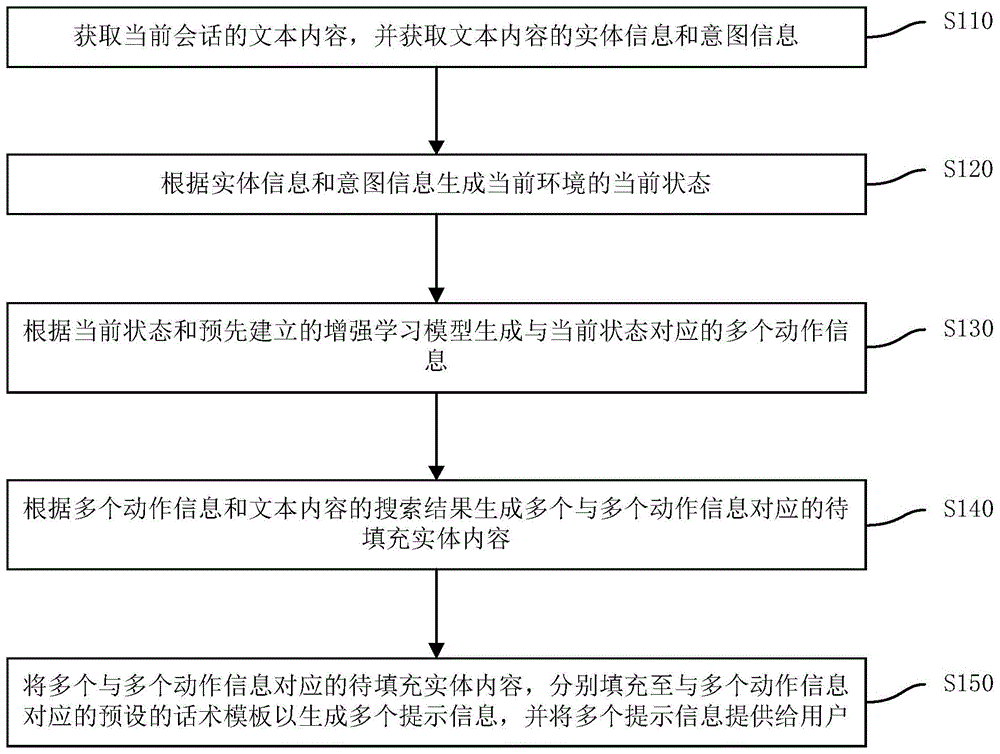
:人工智能(artificialintelligence,英文缩写为ai)是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。随着人工智能的发展,越来越多的产品应用通过利用人工智能以提高用户与产品之间的交互体验,例如,秘书化、私人化的应用程序等。目前的基于人工智能的应用程序一般只关注于当前推荐提示信息(对应英文为hint)的相关性,很有可能当前提示信息是相关的,但是,在用户等点击到该提示信息之后的用户体验与后续的相关性和结果满意度会比较差,从而导致整个会话流会提前中断,导致整个会话中用户体验降低。技术实现要素:本发明的目的旨在至少在一定程度上解决上述的技术问题之一。为此,本发明的第一个目的在于提出一种基于人工智能的提示信息推荐方法。该方法通过考虑每一轮交互的质量指标,可以提高会话的整体满意度为最终指标,可以提升用户在会话中的满意度,提升了整个会话中的用户体验。本发明的第二个目的在于提出一种基于人工智能的提示信息推荐装置。本发明的第三个目的在于提出一种非临时性计算机可读存储介质。本发明的第四个目的在于提出一种计算机程序产品。为达到上述目的,本发明第一方面实施例提出的基于人工智能的提示信息推荐方法,包括:获取当前会话的文本内容,并获取所述文本内容的实体信息和意图信息;根据所述实体信息和所述意图信息生成当前环境的当前状态;根据所述当前状态和预先建立的增强学习模型生成与所述当前状态对应的多个动作信息;根据所述多个动作信息和所述文本内容的搜索结果生成多个与所述多个动作信息对应的待填充实体内容;将所述多个与所述多个动作信息对应的待填充实体内容,分别填充至与所述多个动作信息对应的预设的话术模板以生成多个提示信息,并将所述多个提示信息提供给用户。本发明实施例的基于人工智能的提示信息推荐方法,可获取当前会话的文本内容,并根据该文本内容的实体信息和意图信息生成当前环境的当前状态,之后,根据该当前状态和预先建立的增强学习模型生成与当前状态对应的动作信息,然后,根据动作信息和文本内容的搜索结果生成待填充实体内容,最后,将该待填充实体内容填充至预设的话术模板以生成多个提示信息,并将多个提示信息提供给用户。即通过结合增强学习技术,合理对具体产品进行建模,利用用户画像和文本内容(query)理解等分析技术,有效刻画状态,减少并泛化状态空间,并结合产品提出合理的动作(action)定义和建模方法,同时结合具体产品业务定义合理的收益(reward),用来保持和业务目标的一致性,最终利用增强学习来确保模型和业务整体目标的一致,即通过考虑每一轮交互的质量指标,可以提高会话的整体满意度为最终指标,可以提升用户在会话中的满意度,提升了整个会话中的用户体验。为达到上述目的,本发明第二方面实施例提出的基于人工智能的提示信息推荐装置,包括:获取模块,用于获取当前会话的文本内容,并获取所述文本内容的实体信息和意图信息;第一生成模块,用于根据所述实体信息和所述意图信息生成当前环境的当前状态;第二生成模块,用于根据所述当前状态和预先建立的增强学习模型生成与所述当前状态对应的多个动作信息;第三生成模块,用于根据所述多个动作信息和所述文本内容的搜索结果生成多个与所述多个动作信息对应的待填充实体内容;第四生成模块,用于将所述多个与所述多个动作信息对应的待填充实体内容,分别填充至与所述多个动作信息对应的预设的话术模板以生成多个提示信息;提供模块,用于将所述多个提示信息提供给用户。本发明实施例的基于人工智能的提示信息推荐装置,可通过获取模块获取当前会话的文本内容,第一生成模块根据该文本内容的实体信息和意图信息生成当前环境的当前状态,第二生成模块根据该当前状态和预先建立的增强学习模型生成与当前状态对应的动作信息,第三生成模块根据动作信息和文本内容的搜索结果生成待填充实体内容,第四生成模块将该待填充实体内容填充至预设的话术模板以生成多个提示信息,提供模块将多个提示信息提供给用户。即通过结合增强学习技术,合理对具体产品进行建模,利用用户画像和文本内容(query)理解等分析技术,有效刻画状态,减少并泛化状态空间,并结合产品提出合理的动作(action)定义和建模方法,同时结合具体产品业务定义合理的收益(reward),用来保持和业务目标的一致性,最终利用增强学习来确保模型和业务整体目标的一致,即通过考虑每一轮交互的质量指标,可以提高会话的整体满意度为最终指标,可以提升用户在会话中的满意度,提升了整个会话中的用户体验。为达到上述目的,本发明第三方面实施例提出的非临时性计算机可读存储介质,当所述存储介质中的指令由移动终端的处理器被执行时,使得移动终端能够执行一种基于人工智能的提示信息推荐方法,所述方法包括:获取当前会话的文本内容,并获取所述文本内容的实体信息和意图信息;根据所述实体信息和所述意图信息生成当前环境的当前状态;根据所述当前状态和预先建立的增强学习模型生成与所述当前状态对应的多个动作信息;根据所述多个动作信息和所述文本内容的搜索结果生成多个与所述多个动作信息对应的待填充实体内容;将所述多个与所述多个动作信息对应的待填充实体内容,分别填充至与所述多个动作信息对应的预设的话术模板以生成多个提示信息,并将所述多个提示信息提供给用户。为达到上述目的,本发明第四方面实施例提出的计算机程序产品,当所述计算机程序产品中的指令处理器执行时,执行一种基于人工智能的提示信息推荐方法,所述方法包括:获取当前会话的文本内容,并获取所述文本内容的实体信息和意图信息;根据所述实体信息和所述意图信息生成当前环境的当前状态;根据所述当前状态和预先建立的增强学习模型生成与所述当前状态对应的多个动作信息;根据所述多个动作信息和所述文本内容的搜索结果生成多个与所述多个动作信息对应的待填充实体内容;将所述多个与所述多个动作信息对应的待填充实体内容,分别填充至与所述多个动作信息对应的预设的话术模板以生成多个提示信息,并将所述多个提示信息提供给用户。本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。附图说明本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:图1是根据本发明一个实施例的基于人工智能的提示信息推荐方法的流程图;图2是根据本发明一个实施例的建立增强学习模型的方法的流程图;图3(a)是根据本发明一个实施例的基于人工智能的提示信息推荐方法的示例图;图3(b)为现有技术与本发明针对相同的文本内容而得到不同的提示信息的示例图;图4是根据本发明一个实施例的基于人工智能的提示信息推荐装置的结构示意图;图5是根据本发明一个具体实施例的基于人工智能的提示信息推荐装置的结构示意图;图6是根据本发明一个实施例的第二生成模块的结构示意图;图7是根据本发明一个实施例的第三生成模块的结构示意图。具体实施方式下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。下面参考附图描述本发明实施例的基于人工智能的提示信息推荐方法以及装置。图1是根据本发明一个实施例的基于人工智能的提示信息推荐方法的流程图。需要说明的是,本发明实施例的基于人工智能的提示信息推荐方法可应用于基于人工智能的提示信息推荐装置中。如图1所示,该基于人工智能的提示信息推荐方法可以包括:s110,获取当前会话的文本内容,并获取文本内容的实体信息和意图信息。举例而言,假设本发明实施例的基于人工智能的提示信息推荐方法应用于具有问答搜索功能的应用程序中,该应用程序可为用户提供问题输入界面、答案结果展现界面以及提示信息展示界面等,在检测到用户通过该问题输入界面输入问题的文本内容时,可根据文本内容搜索对应的答案并将其展示在答案结果展现界面中,同时可提供与该文本内容相关的提示信息并展示在提示信息展示界面中。这样,在检测到用户使用该应用程序的问答搜索功能时,可通过该应用程序获取当前会话的文本内容,其中,该当前会话的文本内容即理解为当前用户输入的文本内容。在获取到当前会话的文本内容时,可对该文本内容进行实体识别和意图识别处理,得到该文本内容的实体信息和意图信息。例如,可对文本内容进行分词、语法及语义分析等,得到该文本内容的实体信息和意图信息。s120,根据实体信息和意图信息生成当前环境的当前状态。需要说明的是,本发明实施例的基于人工智能的提示信息推荐方法,是通过利用增强学习来实现交互式的问答场景。可以理解,在增强学习算法中,需要确定增强学习中的当前状态,这样以便后续根据该当前状态和预先建立的增强学习模型即可得到与该当前状态对应的动作信息。还可以理解,增强学习中的当前状态是用于刻画当前环境的状况。基于该原由,本步骤可先确定上述得到的实体信息对应的实体类型,并将该实体类型和上述得到的意图信息组合成状态,该状态即为当前环境的当前状态。例如,以当前会话的文本内容为“沈阳大学哪些专业好?”为例,可得到该文本内容的实体信息“沈阳大学”,意图信息为“专业信息”(即询问专业的相关信息),可确定该实体信息的实体类型为“学校”,并将该文本内容的主要信息,即实体类型和意图信息作为状态的刻画,即得到当前环境的当前状态为:{"学校","意图":"专业信息"}。s130,根据当前状态和预先建立的增强学习模型生成与当前状态对应的多个动作信息。需要说明的是,本发明实施例的基于人工智能的提示信息推荐方法,是通过利用增强学习来实现交互式的问答场景。为了能够改进会话流的整体效果,而不局限于会话的当前效果,比如相关性、满意度之类,需考虑全局收益,以提高整个会话流的效果,为此,本发明可预先建立一个增强学习模型,即采用增强学习的方法来对具体问题进行建模,首先增强学习十分贴合交互式场景,增强学习中的重要元素可以在交互式应用场景中找到对应关系。作为一种示例,如图2所示,该增强学习模型可以通过以下步骤预先建立的:s210,获取样本文本内容的样本实体信息和样本意图信息。例如,可获取大量用户的历史输入的样本文本内容,并对这些样本文本内容进行分词、语法及语义分析等,得到这些样本文本内容的样本实体信息和样本意图信息。为了保证本发明的可用性以及可行性,上述样本意图信息可根据实际应用进行预先设定,例如,假设本发明应用于高考咨询场景中,则可根据该场景预先定义一些在高考咨询场景中出现的意图信息,如下面表1所示:表1school_cmp学校比较score_line分数线查询(一本、二本线之类)school_major_choose学校专业信息school_info学校信息school_choose学校选择major_info专业信息general_demand泛需求querymajor_choose专业选择junxiao军校相关信息询问pingxingzhiyuan平行志愿相关询问tiaoji调剂相关询问xuexiaoruantiaojian宿舍、食堂之类的学校软条件exam高考题volunteer志愿填报信息major_test专业测试score_search查分major_cmp专业比较可以理解,上述给出的仅是应用于高考咨询场景中时,预先定义的意图信息如上述表1所示,还可根据其他应用场景来预先定义该场景下的意图信息,即上述表1仅是给出的一种示例,而并不能作为本发明的具体限定。s220,根据样本实体信息和样本意图信息生成当前环境的样本当前状态。具体地,可确定这些样本实体信息的实体类型,并将该样本实体信息的实体类型和样本意图信息组合成当前环境的样本当前状态。s230,根据样本意图信息生成每种样本动作信息。需要说明的是,增强学习中动作是指针对当前状态,环境做出的选择,在实际应用场景中,环境做出的选择就是提示信息(如hint引导),例如,如图3(a)中输入框下方的“沈阳大学在贵州英语分数线”、“建筑学专业的就业前景”、“建筑学哪些学校好”等,均为提示信息。为了泛化动作(action),本发明考虑将样本意图信息转化为动作(action),即利用样本意图信息生成每种样本动作信息。例如,以样本意图为“学校比较”为例,可将该样本意图信息转化为样本动作信息分别为:选择学校a、选择学校b等。s240,获取针对每种样本动作信息的反馈信息,并根据反馈信息计算对样本当前状态下每种样本动作得到的总体回报的样本估计值。举例而言,针对高考之类的信息服务垂类来说,每一轮不同类的结果的正负反馈的reward(收益)会有所不同,例如,针对某个提示信息(hint),正反馈为满足结果(1),无反馈为澄清(-1);而对于外卖等服务类的垂类来说,最终的下单是最重要的,reward(收益)设计会有所侧重,从而和业务目标保持一致,此处的reward(收益)设计有所区分,例如,针对某个提示信息(hint),正反馈为下单(10)、其他(-1),无反馈为下单(-10)、其他(-10)。其中,可以理解,可以根据用户针对样本文本内容或者提示信息的行为信息来获取对应的反馈信息。在获取到针对每种样本动作信息的反馈信息时,可根据该反馈信息计算对样本当前状态下每种样本动作得到的总体回报的样本估计值q(s,a)。s250,根据目标函数和样本估计值,建立样本当前状态与每种样本动作信息之间的对应关系。作为一种示例,该目标函数可理解为整个会话流的全局估计值,其中,该目标函数为收敛函数。其中,该目标函数可为如下公式(1)所示:其中,value为整个会话流的全局收益,rk为第k轮的收益,γ为衰减细系数。可以看出,value是每一轮可以与业务目标,即整个会话流全局收益的保持一致。在得到样本当前状态下每种样本动作得到的总体回报的样本估计值之后,可将这些样本估计值代入目标函数中,并在目标函数值收敛时,建立该样本当前状态与每种样本动作信息之间的对应关系。s260,根据对应关系建立增强学习模型。由此,该增强学习模型中含有当前状态、该当前状态对应的每种样本动作、以及该样本当前状态下每种样本动作得到的总体回报的样本估计值。综上,通过结合增强学习技术,合理对具体产品进行建模,利用用户画像和文本内容(query)理解等分析技术,有效刻画状态,减少并泛化状态空间,并结合产品提出合理的动作(action)定义和建模方法,同时结合具体产品业务定义合理的收益(reward),用来保持和业务目标的一致性,最终利用增强学习来确保模型和业务整体目标的一致。在预先建立该增强学习模型之后,可在实际应用中,直接使用该增强学习模型来生成合理的提示信息进行推荐。具体地,在本发明的一个实施例中,上述根据当前状态和预先建立的增强学习模型生成与当前状态对应的多个动作信息的具体实现过程可如下:将当前状态代入增强学习模型中,得到与当前状态对应的全部候选动作信息、和对当前状态下每种候选动作得到的总体回报的估计值;根据对当前状态下每种候选动作得到的总体回报的估计值,对全部候选动作信息进行排序,得到排序结果前n的候选动作信息,其中,n为正整数;将排序结果前n的候选动作信息作为多个动作信息。举例而言,以当前状态为:{"学校","意图":"专业信息"}为例,可将该当前状态代入增强学习模型,根据该增强学习模型的模型结果q(s,a)(即对当前状态s下每种候选动作得到的总体汇报的估计值),来对当前状态s:{"学校","意图":"专业信息"}的所有候选动作进行排序,得到排序结果前n的候选动作信息,该排序结果前n的候选动作信息即为上述多个动作信息,例如,排序结果top3的候选动作信息分别为:分数线查询、专业信息以及学校选择,这三个候选动作信息即为上述根据当前状态而得到的多个动作信息。s140,根据多个动作信息和文本内容的搜索结果生成多个与多个动作信息对应的待填充实体内容。具体而言,在本发明的一个实施例中,针对每个动作信息,可根据文本内容的实体信息、以及文本内容的搜索结果,对每个动作信息进行内容排序以生成与每个动作信息对应的实体信息,最后,将与每个动作信息对应的实体信息作为待填充实体内容。举例而言,以文本内容为“沈阳大学哪些专业好?”为例,实体信息为“沈阳大学”,该文本内容所对应的搜索结果信息为:建筑学、英语、机械等信息,针对每个动作信息,可根据该实体信息、该搜索结果对每个动作信息进行内容排序,得到排序结果靠前的内容为:建筑学、英语、机械等信息,并确定这些内容对应的实体信息,最后,将这些实体信息作为待填充实体内容。s150,将多个与多个动作信息对应的待填充实体内容,分别填充至与多个动作信息对应的预设的话术模板以生成多个提示信息,并将多个提示信息提供给用户。可以理解,每个动作信息对应一个预设的话术模板。这样,针对每个动作信息,在得到该动作信息的待填充实体内容之后,可将该待填充实体内容填充到该动作信息对应的话术模板中,生成提示信息。例如,以话术模板为“<专业>哪些学校好?”为例,将待填充实体内容“建筑学”填充至该话术模板,得到提示信息“建筑学哪些学校好?”。综上,本发明实施例的基于人工智能的提示信息推荐方法,通过利用增强学习的方式来实现交互式场景下的提示信息的推荐功能,在整个过程中,通过考虑整个会话流中每一轮交互的质量指标,提高了会话的整体满意度,提升了用户在会话中的满意度。如图3(b)所示,为现有技术与本发明针对相同的文本内容而得到不同的提示信息,可以看出,虽然单轮选择中并没有去完全选中单步收益最高的提示信息(hint),但是使用增强学习模型后的多轮收益要明显高出仅仅考虑单轮收益的贪婪算法。本发明实施例的基于人工智能的提示信息推荐方法,可获取当前会话的文本内容,并根据该文本内容的实体信息和意图信息生成当前环境的当前状态,之后,根据该当前状态和预先建立的增强学习模型生成与当前状态对应的动作信息,然后,根据动作信息和文本内容的搜索结果生成待填充实体内容,最后,将该待填充实体内容填充至预设的话术模板以生成多个提示信息,并将多个提示信息提供给用户。即通过结合增强学习技术,合理对具体产品进行建模,利用用户画像和文本内容(query)理解等分析技术,有效刻画状态,减少并泛化状态空间,并结合产品提出合理的动作(action)定义和建模方法,同时结合具体产品业务定义合理的收益(reward),用来保持和业务目标的一致性,最终利用增强学习来确保模型和业务整体目标的一致,即通过考虑每一轮交互的质量指标,可以提高会话的整体满意度为最终指标,可以提升用户在会话中的满意度,提升了整个会话中的用户体验。与上述几种实施例提供的基于人工智能的提示信息推荐方法相对应,本发明的一种实施例还提供一种基于人工智能的提示信息推荐装置,由于本发明实施例提供的基于人工智能的提示信息推荐装置与上述几种实施例提供的基于人工智能的提示信息推荐方法相对应,因此在前述基于人工智能的提示信息推荐方法的实施方式也适用于本实施例提供的基于人工智能的提示信息推荐装置,在本实施例中不再详细描述。图4是根据本发明一个实施例的基于人工智能的提示信息推荐装置的结构示意图。如图4所示,该基于人工智能的提示信息推荐装置可以包括:获取模块410、第一生成模块420、第二生成模块430、第三生成模块440、第四生成模块450和提供模块460。具体地,获取模块410可用于获取当前会话的文本内容,并获取文本内容的实体信息和意图信息。第一生成模块420可用于根据实体信息和意图信息生成当前环境的当前状态。第二生成模块430可用于根据当前状态和预先建立的增强学习模型生成与当前状态对应的多个动作信息。作为一种示例,如图5所示,该基于人工智能的提示信息推荐装置还可包括:预先建立模块470,用于预先建立增强学习模型。其中,在示例中,如图5所示,该预先建立模块470可包括:第一获取单元471、第一生成单元472、第二生成单元473、第二获取单元474、计算单元475、第一建立单元476和第二建立单元477。其中,第一获取单元471可用于获取样本文本内容的样本实体信息和样本意图信息。第一生成单元472可用于根据样本实体信息和样本意图信息生成当前环境的样本当前状态。第二生成单元473可用于根据样本意图信息生成每种样本动作信息。第二获取单元474可用于获取针对每种样本动作信息的反馈信息。计算单元475可用于根据反馈信息计算对样本当前状态下每种样本动作得到的总体回报的样本估计值。第一建立单元476可用于根据目标函数和样本估计值,建立样本当前状态与每种样本动作信息之间的对应关系。第二建立单元477可用于根据对应关系建立增强学习模型。作为一种示例,该目标函数可理解为整个会话流的全局估计值,其中,目标函数为收敛函数。具体而言,在本发明的一个实施例中,如图6所示,该第二生成模块430可包括:计算单元431、排序单元432和生成单元433。其中,计算单元431用于将当前状态代入增强学习模型中,得到与当前状态对应的全部候选动作信息、和对当前状态下每种候选动作得到的总体回报的估计值。排序单元432用于根据对当前状态下每种候选动作得到的总体回报的估计值,对全部候选动作信息进行排序,得到排序结果前n的候选动作信息,其中,n为正整数。生成单元433用于将排序结果前n的候选动作信息作为多个动作信息。第三生成模块440可用于根据多个动作信息和文本内容的搜索结果生成多个与多个动作信息对应的待填充实体内容。作为一种示例,如图7所示,该第三生成模块440可包括第一生成单元441和第二生成单元442。其中,第一生成单元441用于针对每个动作信息,根据文本内容的实体信息、以及文本内容的搜索结果,对每个动作信息进行内容排序以生成与每个动作信息对应的实体信息。第二生成单元442用于将与每个动作信息对应的实体信息作为待填充实体内容。第四生成模块450可用于将多个与多个动作信息对应的待填充实体内容,分别填充至与多个动作信息对应的预设的话术模板以生成多个提示信息。提供模块460可用于将多个提示信息提供给用户。本发明实施例的基于人工智能的提示信息推荐装置,可通过获取模块获取当前会话的文本内容,第一生成模块根据该文本内容的实体信息和意图信息生成当前环境的当前状态,第二生成模块根据该当前状态和预先建立的增强学习模型生成与当前状态对应的动作信息,第三生成模块根据动作信息和文本内容的搜索结果生成待填充实体内容,第四生成模块将该待填充实体内容填充至预设的话术模板以生成多个提示信息,提供模块将多个提示信息提供给用户。即通过结合增强学习技术,合理对具体产品进行建模,利用用户画像和文本内容(query)理解等分析技术,有效刻画状态,减少并泛化状态空间,并结合产品提出合理的动作(action)定义和建模方法,同时结合具体产品业务定义合理的收益(reward),用来保持和业务目标的一致性,最终利用增强学习来确保模型和业务整体目标的一致,即通过考虑每一轮交互的质量指标,可以提高会话的整体满意度为最终指标,可以提升用户在会话中的满意度,提升了整个会话中的用户体验。在本发明的描述中,需要理解的是,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本发明的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本发明的实施例所属
技术领域:
的技术人员所理解。在流程图中表示或在此以其他方式描述的逻辑和/或步骤,例如,可以被认为是用于实现逻辑功能的可执行指令的定序列表,可以具体实现在任何计算机可读介质中,以供指令执行系统、装置或设备(如基于计算机的系统、包括处理器的系统或其他可以从指令执行系统、装置或设备取指令并执行指令的系统)使用,或结合这些指令执行系统、装置或设备而使用。就本说明书而言,"计算机可读介质"可以是任何可以包含、存储、通信、传播或传输程序以供指令执行系统、装置或设备或结合这些指令执行系统、装置或设备而使用的装置。计算机可读介质的更具体的示例(非穷尽性列表)包括以下:具有一个或多个布线的电连接部(电子装置),便携式计算机盘盒(磁装置),随机存取存储器(ram),只读存储器(rom),可擦除可编辑只读存储器(eprom或闪速存储器),光纤装置,以及便携式光盘只读存储器(cdrom)。另外,计算机可读介质甚至可以是可在其上打印所述程序的纸或其他合适的介质,因为可以例如通过对纸或其他介质进行光学扫描,接着进行编辑、解译或必要时以其他合适方式进行处理来以电子方式获得所述程序,然后将其存储在计算机存储器中。应当理解,本发明的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(pga),现场可编程门阵列(fpga)等。本
技术领域:
的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。此外,在本发明各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。上述提到的存储介质可以是只读存储器,磁盘或光盘等。尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1