一种用于大量样本数据的电力负荷优化预测方法与流程
背景技术:
:
在电力系统中,电力负荷预测分为超短期负荷预测、短期负荷预测和中长期负荷预测。一般电力负荷预测主要以宏观统计层面预测为主,如对一个地区、行业等较大的统计口径进行预测。
对于大量的小粒度的统计口径(如按用户、设备、小区、街道等)的样本数据进行负荷预测,由于在微观层面电力负荷变化的随机性很大,预测准确率不高,计算量巨大等难点,因此在实际的工作中,小粒度负荷预测的应用比较少,相关研究也开展得不多。
在专利号为“CN201510147127.0”的发明中,提到了一种基于大数据技术的电力负荷预测模型,主要根据电网电气连接模型构造适合电力负荷预测的新型模型,实现对电力负荷的预测。但这种方法主要是对电网中的主要线路和负荷点进行数据预测,样本数据量相比海量的电力用户数量有限,没能解决对海量样本数据进行预测的计算效率问题。
在专利号为“CN201210228966.1”的发明中,提出了一种基于大用户智能终端采集的电力负荷预测方法,该方法主要采集实时的分布式发电量及用户用电信息,并根据所述发电量、所述用电信息以及用户历史用电信息,建立用电分析模型,进行分布式发电量的预测以及负荷用电量的预测。这种方法也主要是针对电力系统中的大用户进行数据采集和预测,其数量也较少,同样没能解决海量样本数据进行预测的问题。
随着国家新能源战略的实施,包括风能、太阳能、电池储能等不同形式的分布式能源的电源将会对现有的电网格局带来巨大的变革,含分布式能源的智能微网、智能配网将成为电网中不可缺少的一部分。因此对整个电网的规划设计、运行控制、维护管理等工作的模式和体系也将产生巨大的改变,其中基于微观粒度的负荷预测也必然将成为未来智能微网和配电网运行控制和管理的基础技术支持手段。
在电网企业客户服务方面,可以提高差异化服务质量。通过小粒度的负荷预测,可以得到每一个用户的准确负荷预测结果,因此能够针对大客户、VIP客户的用电特性和用电需求,制定更加有效的差异化服务策略。
在电网城市配网规划设计、配网运行方式的重大指导作用。通过小粒度的负荷预测,可以得到空间地理纬度的负荷预测信息,因此能够更直观、更准确的掌握城市配电网的负荷需求分布情况,对城市配网的规划设计有更好的指导作用。
不难看出,大数据和机器学习技术已成为当下IT技术发展的热点和方向,对这些技术进行学习掌握并有效的吸收和转化,推进其在电网企业生产经营业务中的应用,不断提升负荷预测工作的技术含量和科技创新水平,对于企业来说是很有意义的。
技术实现要素:
:
本发明正是为了克服上述现有技术存在的不足之处:提出了一种用于海量样本数据的电力系统负荷预测的新方法,解决对大量小粒度的负荷样本数据建模困难和计算量大的问题,通过大幅提高计算效率和预测准确率,实现对海量的小粒度负荷样本数据的分析和预测。
本发明采用的技术方案如下:
所述用于大量样本数据的电力负荷优化预测方法,本发明特征在于,包括数据预处理、数据分组、模型拟合、优化分组、优化估计、数据预测、误差估计、预测模型;方法原理图见图1,所述数据预处理方法将含大量样本数据的小粒度电力负荷记录数据进行预处理、整理、清洗,去除和纠正无效和错误的样本数据、所述数据分组方法对所述样本数据进行初步分组,所述模型拟合方法使用负荷预测模型模型对所述分组数据进行模型拟合和参数估计,所述优化分组对所述样本模型和初步估计参数进行优化分组,即相同模型和相同参数的样本数据作为一组,采用同一个模型进行参数的精确估计,再利用所述精确估计的参数应用于样本数据,进行精确预测;
所述预测方法通过数据预处理(1)、数据分组(2)、模型拟合(3)、优化分组(4)、优化估计(5)、数据预测(6)、误差估计(7)、预测模型(8)将大量样本数据进行分组,同一分组的样本数据采用同一个模型进行精确估计计算,大幅减少了模型拟合估计的计算量,同时通过精确的优化计算方法,提高预测精度;
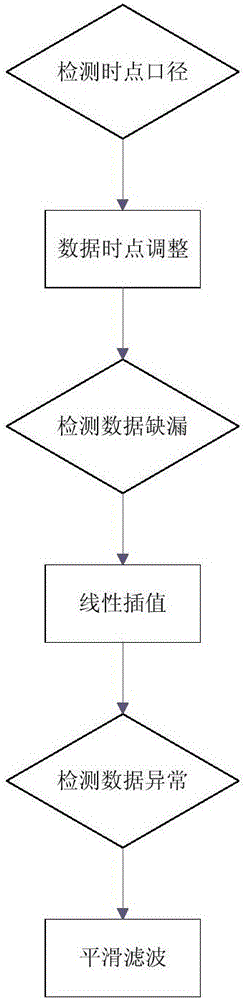
所述数据预处理(1)检测所有样本数据是否是同一序列,时间统计口径是否一致、起止月份是否一致,数据是否缺漏、以及存在异常(例如负值、零值、空值、超大量)等。对所有样本数据进行时间序列对齐和校正,统一到同一时间口径。采用平滑滤波器对样本数据中的缺漏、异常值进行补缺和纠正;
所述数据分组(2)对所有样本数据进行分组,具体根据电量级别,用户用电性质(行业),起止月份等参数,将所有样本分为若干个组;所述电量级别指标、用电性质分类等参数,根据样本所处地区特点应有所区分;
所述模型拟合(3)对所述数据分组(2)中输出的每一个样本数据确定一个模型可行集,对模型可行集中的每一个模型进行初步模型拟合和参数估计,并选择最优拟合的模型和初步参数估计;根据样本数据的自相关函数、确定模型的可行集,对模型可行集中的每一个模型,采用;
所述优化分组(4)对所述模型拟合(3)得到的最佳拟合模型和初步参数估计,根据误差估计(7)方法,对数据分组(2)所述的数据分组进行误差估计,并根据所述的误差估计对样本数据进行优化分组,将相同模型和相同参数的样本数据作为同一分组;
所述优化估计(5)根据预测模型(8)所述方法,对所述优化分组(4)输出的优化分组数据进行精确的模型拟合和参数估计,得到一组样本的最优参数估计值;
所述数据预测(6)采用所述模型拟合(3)输出的最佳拟合模型以及所述优化估计(5)输出的最优参数估计值,根据预测模型(8)所述预测方法,对样本数据进行优化预测;
所述误差估计(7)根据所述数据分组(2)、优化分组(4)提供的样本数据和相关数据(电量、负荷性质等)、以及模型拟合(3)输出的模型种类、参数估计值,对分组中的数据误差范围进行估计;
所述预测模型(8)对模型拟合(3)、优化估计(4)提供的样本数据提供模型定义、模型拟合的方法;预测模型(8)是可替换的模型,可以根据负荷数据不同,采用不同的预测模型方法。
本发明所述数据分组(2)、优化分组(4)与误差估计(7)相连接,利用误差估计方法对样本数据进行优化分组,减小样本数据计算量。
本发明所述优化分组(4)、优化估计(5)相连接,对数据进行分组,并对分组数据进行优化估计。
本发明所述优化估计(5)、预测(6)相连接,优化估计(5)计算最优参数估计值,预测(6)将所述最优参数估计值用于对样本数据的预测。
本发明模型拟合(3)、优化估计(5)、预测(6)与预测模型(8)相连接,利用预测模型(8)所述方法进行模型拟合和参数估计,预测模型(8)是可替换的。
本发明的有益效果是:
通过对海量样本数据进行分组拟合,极大的减少了模型拟合的计算量,提升运算速度。
通过采用精确拟合估计算法,使模型参数估计更加准确,提升了预测准确率。
相比传统的预测方法,本方法可以用于对大量微观统计口径的负荷样本数据(如按用户、按设备)进行分别建模和预测。
附图说明:图1为总体结构图;
图2为数据预处理过程图;
图3为数据分组过程图;
图4为模型拟合过程图;
图5为优化分组过程图;
图6为优化估计过程图;
图7为预测过程图。
具体实施方式:
所述数据预处理(1)采用的施行方法为:
对样本数据进行清洗、整理和预先处理。包括
检测所有样本数据是否统一序列。
检测所有样本数据的时间统计口径是否一致、检测所有样本数据的起止月份是否一致,检测所有样本数据的数据是否缺漏、
检测所有样本数据是否存在异常值(例如负值、零值、空值、超大量)等。对于负值、零值、空值等异常量的检测方法,可具体采用数值比较方法。
对于超大量的检测,可具体采用方差检验方法,主要包括单因素分析、假设检验等统计方法。
对所有样本数据进行时间序列校正和对齐,统一到同一时间口径。由于电网企业营销电费回收方法和策略不同,有部分用户按照每月结算电费、有部分用户每两月结算一次电费、部分用户每月结算两次电费,因此可能基于用户的负荷电量数据的时点并不一致。因此需将其统一到同一时间口径上,具体统一到何种时间口径上,可根据实际应用的需求进行设定。并不需要指定一种。方法原理图见图2。
数据时点对齐方法为(以月度为单位):
1.对于以半月时点的数据,将两个同月时点的数据相加得到月度时点数据
2.对于以双月时点的数据,将双月时点数据除以2得到月度时点数据
对于时点数据中缺漏的数据值。可采用线性插值方法对样本数据中的缺漏、异常值进行补缺和纠正。
对于时点数据中明显错误的数据值(如负值、方差异常)。可采用平滑滤波器对样本数据中的异常值进行修正。
所述数据分组(2)采用的施行方法为:
数据分组对所有样本数据进行分组,具体根据电量级别,用户用电性质(行业),起止月份等参数,将所有样本分为若干个组。所述电量级别指标、用电性质分类等参数,根据样本所处地区特点应有所区分。方法原理图见图3。
具体方法为:
1.计算各样本数据的统计量,包括电量均值、电量方差、中位数、最大值、最小值等。
2.根据样本数据负荷点的负荷性质、行业性质等辅助信息对样本数据进行初步分组。例如将居民用电分为一组、商业用电分为一组。
3.根据计算得到的统计量对样本数据进行第二次分组,一般可以使用电量均值和方差作为分组标准,例如将电量均值在200以内、方差为100以内的样本数据作为一组。具体分组使用的标准阈值需要根据本地区用电特点和供电公司实际情况进行确定。
所述模型拟合(3)采用的施行方法为:
根据预测模型(8)所述方法,对所述数据分组(2)中输出的每一个样本数据确定一个模型可行集,对模型可行集中的每一个模型进行初步模型拟合和参数估计,并选择最优拟合的模型和初步参数估计。具体实施方法可能与选择的模型方法有关,但大致过程相同,如采用时间序列模型方法,方法原理图见图4。
具体实施过程如下:
1.计算样本数据的自相关函数、偏相关函数。
2.按照Jenkens-Boxes方法,根据样本的自相关函数和偏相关函数选择样本的可选模型集
3.根据样本数据的负荷性质、行业特征、地区特点添加经验模型集
4.汇总样本数据的可行模型集
5.采用极大似然估计,对样本数据的可选模型集中的每一个模型进行初步的拟合和参数估计,计算其贝叶斯信息量(BIC)值。BIC值的计算公式如下:
BIC=-2log(p(y1,y2,y3,...yn))+klo.
其中:p(y1,y2,y3,...yn)是时间序列的极大似然估计,k=p+q。
6.选取BIC值最小的模型作为样本数据的优选模型
所述优化分组(4)采用的实施方法为:
对所述模型拟合(3)得到的最佳拟合模型和初步参数估计,根据误差估计(7)方法,对数据分组(2)所述的数据分组进行误差估计,并根据所述的误差估计对样本数据进行优化分组,将相同模型和相同参数的样本数据作为同一分组。方法原理图见图5。
具体实施方法为:
1.从总体数据中,选择一组样本数据
2.根据每组样本数据的模型种类对样本数据进行第一次分组,将模型相同的样本数据分为一组
3.根据误差估计(7)所述方法,对模型参数计算误差系数。
4.根据所述误差系数和样本数据模型参数初步估计值,计算误差范围。
5.根据所述误差范围,对样本数据进行再次分组,将误差范围相同的数据分为一组。误差范围计算公式为:
E=P×Ex
其中P为参数值,Ex为误差范围系数
6.循环1~6的步骤,直至所有样本数据处理完毕
所述优化估计(5)采用的实施方法为:
优化估计(5)根据预测模型(8)所述方法,对所述优化分组(4)输出的优化分组数据进行精确的模型拟合和参数估计,得到一组样本的最优参数估计值。方法原理图见图6。
具体实施方法为:
1.从总体样本数据中,选择一组数据。所述的一组数据是指经过优化分组(4)方法得到的优化分组数据。
2.合并分组数据,将分组数据进行累加,合并成为一个样本数据。
3.采用预测模型(8)提供的方法对之前所述的样本数据进行精确的拟合和参数估计,如预测模型采用时间序列模型,则精确估计可采用基于卡尔曼滤波的状态空间模型方法来进行精确估计。具体地,基于卡尔曼滤波的状态空间模型方法采用卡尔曼滤波原理对时间序列ARIMA模型的预测值进行反馈和修正,得出更精确的模型预报值,进而对ARIMA模型的极大似然量进行更准确的估计,最终得到准确的ARIMA参数估计。更多关于卡尔曼滤波和ARIMA时间序列模型的细节信息,请参考相关资料和文档。
4.基于模型的精确拟合成果,计算模型的精确参数。
5.重复1~4步骤,直至所有样本数据处理完毕。
所述预测(6)采用的施行方法为:
采用所述模型拟合(3)输出的最佳拟合模型以及所述优化估计(5)输出的最优参数估计值,根据预测模型(8)所述预测方法,对样本数据进行优化预测。方法原理图见图7。
具体实施方法为:
1.从总体数据中,选择一组数据,所述的一组数据是指经过优化分组(4)方法得到的优化分组数据。
2.在所选的一组数据中,取出一个样本数据
3.根据所述优化估计(5)输出的最优参数估计值,写出样本数据时间序列模型的差分方程表达式。
4.对样本数据进行平稳性和可逆性校验。具体地,根据基于差分方程表达式,得出差分方程对应的特征多项式,求解该特征多项式得出特征多项式的根φ,根据ARIMA模型的平稳性条件|φ|>1,判断模型的平稳性条件。
5.根据4所述的ARIMA模型的差分方程表达式,代入参数值和时点负荷值,得出样本数据的预测值。
6.重复2~5的步骤直到所有数据处理完毕
7.重复1~6的步骤,直至所有数据处理完毕。
所述误差估计(7)采用的实施方法为:
所述误差估计根据所述数据分组(2)、优化分组(4)提供的样本数据和相关数据(电量、负荷性质等)、以及模型拟合(3)输出的模型种类、参数估计值,对分组中的数据误差范围进行估计。
具体方法为:
1.误差标准设定,根据负荷预测的目标要求设定误差标准Ec,一般按照电网企业的负荷预测准确度要求,误差标准取值为0.01
2.设定分组负荷比例系数,分组比例系数以数据分组(2)所述数据分组为单位,每组设定一个负荷比例系数。比例系数计算方法为:
其中:Wg为组内样本负荷均值,Wa为总体样本负荷均值,σx为样本方差补偿系数、
4.根据分组负荷比例系数和负荷预测标准,计算误差范围系数:
所述预测模型(8)采用的施行方法为:
所述预测模型(8)对模型拟合(3)、优化估计(4)提供的样本数据提供模型定义、模型拟合的方法。预测模型(8)是可替换的模型,可以根据负荷数据不同,采用不同的预测模型方法。
预测模型采用时间序列模型技术,时间序列分析(Time series analysis)是一种动态数据处理的统计方法。该方法基于随机过程理论和数理统计学方法,研究随机数据序列所遵从的统计规律,以用于解决实际问题。
模型拟合的方法为:
用电负荷数据之间有很强的相关性,同时还具有季节性特征,因此采用非平稳季节性模型(ARIMA)来拟合用电负荷样本数据。
一般定义季节的乘法季节ARMA(p,q)×(P,Q)s,模型是AR特征多项式为φ(x)Φ(x),MA特征多项式为θ(x)θ(x)的模型,其中:
相关系数为:
γk=θγk-12,k≥2
对于特定的样本数据,首先需要选择模型的滑动过程阶数等基本参数,即p,q,P,Q,s,d,再利用样本数据进行具体的参数估计和计算。对于经典的统计分析方法,选择模型主要是依靠统计专家的经验来进行选择的。但作为计算机程序,需要一个自动化的算法来代替统计专家的经验,从多种参数组合中选择最优拟合度的模型。也就是对模型的拟合优度进行分析。
基于卡尔曼滤波和状态空间模型进行精确估计的方法具体是:
卡尔曼滤波是一个预测值-测量值的反馈修正过程,假设输入在t时刻时的状态为X(t),则根据系统状态转移函数,系统在t时刻的输出值,记为根据系统量测方程,可以得到系统在t+1时刻的测量值,记为Y(t+1)。通过将预测值和测量值Y(t+1)进行加权平均,即可得到系统在t+1时刻的最优估计值加权系数K(t+1)也称为卡尔曼增益系数。计算卡尔曼增益系数和最优估计值的相关公式称为卡尔曼滤波方程组,如以下公式所示。
1.定义系统状态转移方程,计算公式如下:
Yt=ΦYt-1+Ψαt
2.定义系统量测方程,计算公式如下:
Zt=zt+Nt=[1 0 ... 0]Yt+Nt=HYt+Nt
3.计算t时刻预测值和协方差矩阵,计算公式如下:
Vt|t-1=ΦtVt-1|t-1
4.计算卡尔曼增益系数,计算公式如下:
Kt=yt|t-1HtT[Htyt|t-1HtT+HσN
5.计算精确预测值和协方差矩阵,计算公式如下:
Vt|t=[I-KtHt]V
上面结合附图对本发明进行了示例性的描述,显然本发明具体实现并不受上述方式的限制,只要采用了本发明的方法构思和技术方案进行的各种非实质性的改进,或未经改进将本发明的构思和技术方案应用于其它场合的,均在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!