一种网络学术报告的关键字段自动提取方法与流程
本发明属于信息技术中的文本处理领域,主要涉及一种网络学术报告预告信息的关键字段自动提取方法。
背景技术:
随着互联网技术的迅速发展,人类社会进入了信息时代,在庞大而复杂的互联网中隐藏了大量的学术报告信息。学术报告是针对规定的学科课题,为了更好地交流专业知识、学术成果、经验以及共同讨论分析解决问题的方法,有相关的研究者和学习者参加并进行探讨、论证和研究的学术活动。学术报告作为学术交流的重要组成部分,对科学技术的传播和发展起着巨大作用,也是培养人才的一种重要手段。
各高校和科研机构定期会发布一些学术报告预告,有些机构在其官网上专门开辟了一个学术报告模块用来发布学术报告预告。虽然在众多学术讲座中不乏优秀的学术报告,但是由于科研工作者无法也不可能逐一浏览各机构所发布的学术报告预告信息,因而会错过优秀的或其感兴趣的学术讲座。因此,对各高校和科研机构所发布的学术报告进行汇聚,方便科研工作者及时获取报告信息,具有实际的应用意义。
网络爬虫是一个自动提取网页的程序,它为搜索引擎从互联网上下载网页,是搜索引擎的重要组成部分。网络爬虫从一个或若干个初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断地从当前页面上抽取出新的网页URL放入队列中,直到满足系统一定的停止条件。
目前,获得网络学术报告预告信息的方法主要可以分为两大类:1、人工收集;2、利用网络爬虫技术进行收集。利用人工对网络学术报告进行收集,该方法虽然简单,但是需要投入大量的人力和精力,不仅费时费力,而且也无法收集全网络学术报告,实用性差。在利用网络爬虫进行网络学术报告收集时,针对某一特定网络学术报告站点,虽然能够有效地抽取出网络学术报告的关键信息,但是对于其他的网络学术报告站点,并不一定通用。
技术实现要素:
本发明是为了解决上述现有技术存在的不足之处,提出一种基于网络学术报告的关键字段自动提取方法,以期能提高网络学术报告关键信息抽取的准确性和通用性,从而能有效地抽取出网络学术报告的关键信息。
本发明为解决技术问题采用如下技术方案:
本发明一种网络学术报告的关键字段自动提取方法的特点是按如下步骤进行:
步骤1、收集学术报告站点的信息,构成学术报告站点数据库;
所述学术报告站点数据库中包括:各学术报告站点的起始URL、各站点的学术报告列表URL正则表达式、各站点的学术报告详细页URL正则表达式、各站点的报告内容所在HTML标签的组合选择器表达式CE以及各站点的报告标题所在HTML标签的组合选择器表达式TE;
步骤2、根据所述各学术报告站点的起始URL、各站点的学术报告列表URL正则表达式以及各站点的学术报告详细页URL正则表达式,利用网络爬虫爬取任意一个学术报告站点S,得到任意一个页面P并相应解析成DOM树格式;
步骤3、根据所述页面P利用网络爬虫得到相应的Jsoup Document对象D;
步骤4、根据所述组合选择器表达式CE和所述Jsoup Document对象D,利用网络爬虫获取所述组合选择器表达式CE所对应的HTML标签内的报告内容C;
步骤5、对所述报告内容C进行关键词的抽取和封装,得到仅包含关键字的报告类实例R;所述关键字包括:报告标题,报告简介,报告人,报告人简介,报告举办时间,报告举办地点和报告举办单位;由关键字及其对应的内容构成关键字段;
步骤6、判断所述报告内容C是否包含<img>标签;若包含,则执行步骤7;若不包含,则执行步骤8;
步骤7、判断所述报告内容C中包含的文字数n≤所设定文字数量阈值NM是否成立,若成立,则表示所述报告内容C为纯图片报告,并设置所述报告类实例R的remark字段为“纯图片报告”后,执行步骤11;若不成立,则直接执行步骤11;
步骤8、构造标签集合L,所述标签集合L中包含:HTML标签的块级结束标签</div>、</p>、</pre>、</ul>、</ol>、</li>、</h1>、</h2>、</h3>、</h4>、</h5>、</h6>,以及HTML标签的行级结束标签</br>;
将所述报告内容C中属于标签集合L中的元素均替换为指定字符串S,并去除所述报告内容C中其他所有的HTML标签,从而得到纯文本Cp;
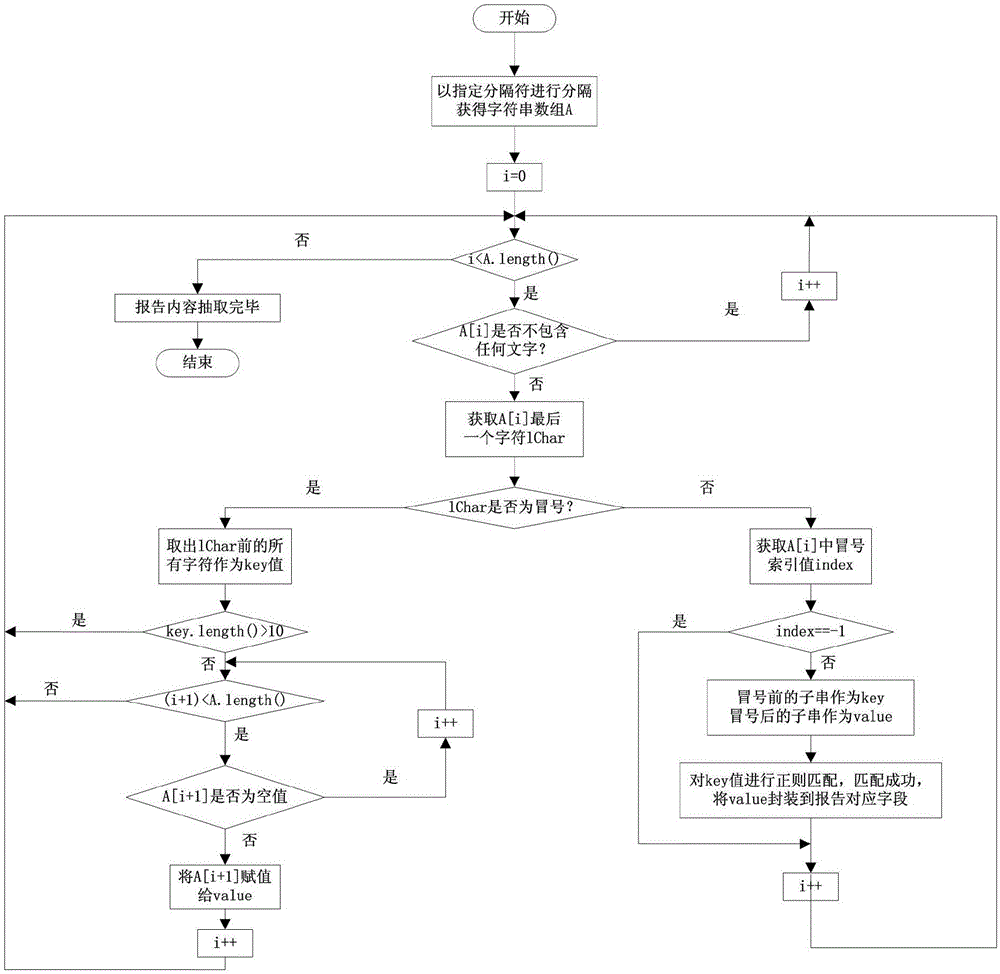
步骤9、以所述指定字符串S为分隔符,对所述纯文本Cp进行分隔,获得字符串数组A;
步骤10、遍历所述字符串数组A,对每一个字符串进行文本处理,抽取所述关键字所对应的关键内容,并相应填充到所述报告实例R中,得到初步报告实例R′;
步骤11、对所述初步报告实例R′中的报告标题关键字所对应的内容进行空值判断;若所述报告标题关键字所对应的内容为空,则执行步骤12;否则,执行步骤15;
步骤12、对所述学术报告站点S的组合选择器表达式TE进行空值判断,若所述组合选择器表达式TE为空,则执行步骤14;否则,执行步骤13;
步骤13、根据所述Jsoup Document对象D和组合选择器表达式TE,抽取所述组合选择器表达式TE所对应的HTML标签内的内容TC;
对所述组合选择器表达式TE所对应的HTML标签内的内容TC进行空值判断,若所述组合选择器表达式TE对应的HTML标签内的内容TC为空,则执行步骤14;否则,设置所述组合选择器表达式TE对应的HTML标签内的内容TC作为报告标题的内容;从而得到准报告实例R,并执行步骤15;
步骤14、设置初步报告实例R′中的报告标题关键字所对应的内容为网页标题所对应的内容;从而得到准报告实例R;
步骤15、对所述准报告实例R中的报告举办时间关键字所对应的内容进行空值判断,若为空,则表示所述准报告实例R非网络学术报告,并丢弃所述准报告实例R,若不为空,则继续判断所述报告举办地点所对应的内容是否为空,若为空,则表示所述准报告实例R非网络学术报告,并丢弃所述准报告实例R,若不为空,则表示所述准报告实例R为网络学术报告并存入学术报告数据库中用于预告和展示。
本发明所述的网络学术报告预告信息的关键字段自动提取方法的特点也在于,所述步骤10是按如下步骤进行:
步骤10.1、定义变量i,并初始化i=0;
步骤10.2、判断所述字符串数组A中的第i个字符串是否为空值,若为空值或空串,则将i+1赋值给i后,判断i>N是否成立,若成立,则表示完成所述字符串数组A的遍历;否则,重复执行步骤10.2;若不为空值或空串,则执行步骤10.3;N表示所述字符串数组A的长度;
步骤10.3、去除所述字符串数组A中的第i个字符串两端的控制符和全角空格,获取第i个字符串的最后一个字符,并判断最后一个字符是否为半角冒号“:”或全角冒号“:”;若是,则执行步骤10.4;否则,执行步骤10.8;
步骤10.4、取出所述第i个字符串的最后一个字符之前的子串,并记为keyi;
步骤10.5、判断keyi≥a是否成立,若不成立,则表示所述第i个字符串的最后一个字符之前的子串keyi为报告关键字,执行步骤10.6;否则,将i+1赋值给i后,判断i>N是否成立,若成立,则表示完成所述字符串数组A的遍历;否则,返回执行步骤10.2;a表示所设定的关键词长度的阈值;
步骤10.6、去除所述子串keyi所包含的标点符号和数字,得到预处理后的子串key′i;
步骤10.7、判断第i+1个字符串是否为空串,若是,则将i+1赋值给i,判断i>N是否成立,若成立,则表示完成所述字符串数组A的遍历;若不成立,则重复执行步骤10.7;否则,取出所述第i+1个字符串作为关键字所对应的内容;
步骤10.8、搜索所述第i个字符串中是否存在半角冒号“:”或全角冒号“:”,若存在,则记录第一个半角冒号“:”或全角冒号“:”所在的位置,记为Pi,并将位置Pi之前的子串记为keyi,位置Pi之后的子串作为关键字所对应的内容;若不存在,将i+1赋值给i,判断i>N是否成立;若成立,则表示完成所述字符串数组A的遍历;否则,返回执行步骤10.2。
与现有技术相比,本发明的有益效果在于:
1、本发明针对上述对学术报告进行汇聚的需求以及基于现有的网络学术报告收集技术存在的问题,通过对各学术报告站点中报告主体内容所处的HTML标签对应的CSS组合选择器表达式的收集以及对报告主体内容关键字的匹配,抽取出每一则学术报告的报告标题、报告简介、报告人、报告人简介、报告举办地点、报告时间、及报告举办单位等关键信息对应的内容,解决了网络学术报告关键信息抽取的通用性问题,从而准确有效地抽取学术报告关键信息,实现了网络学术报告关键信息的结构化封装。
2、本发明收集各学术报告站点报告主体内容所处的HTML标签对应的CSS组合选择器表达式CE,通过CE能够准确、有效地定位到学术报告的内容块,便于网络学术报告关键信息地抽取;
3、本发明将抽取出的报告内容块中的HTML块级、行级标签的结束标签替换成预定义的分隔符,利用该分隔符分隔报告内容块中每一报告关键条目,再通过冒号来匹配报告关键字段及其对应内容,从而有效地抽取出报告关键信息。
附图说明
图1为本发明的整体流程图;
图2为本发明抽取学术报告关键内容的流程图。
具体实施方式
在本实施例中,一种网络学术报告预告信息的关键字段自动提取方法,通过收集学术报告站点作为网络爬虫的爬取种子以及各学术报告站点中报告主体内容所处的HTML标签对应的CSS组合选择器表达式,利用网络爬虫技术爬取学术报告,匹配报告主体内容关键词,抽取出每一则学术报告的报告标题、报告简介、报告人、报告人简介、报告举办地点、报告时间、及报告举办单位等关键信息对应的内容,抽取流程如图2所示,从而准确、有效地抽取出网络学术报告的关键信息,整体流程如图1所示,并按照如下步骤进行:
步骤1、收集学术报告站点的信息,构成学术报告站点数据库;
学术报告站点数据库中包括:各学术报告站点的起始URL、各站点的学术报告列表URL正则表达式、各站点的学术报告详细页URL正则表达式、各站点的报告内容所在HTML标签的组合选择器表达式CE以及各站点的报告标题所在HTML标签的组合选择器表达式TE;
步骤1.1、收集各学术报告站点的学术报告列表的起始列表页URL;
步骤1.2、观察和比较各报告站点的报告列表页各页面的URL差异,归纳总结出报告列表页URL的正则表达式;
步骤1.3、观察和比较各报告站点的报告详细页各页面的URL差异,归纳总结出报告详细页URL的正则表达式;
步骤1.4、找出各站点的报告详细页中报告主体内容所在HTML标签,写出抽取报告内容的CSS组合选择器表达式CE;
步骤1.5、找出各站点的报告详细页中报告标题所在HTML标签,写出抽取报告标题的CSS组合选择器表达式TE;
步骤2、根据所各学术报告站点的起始URL、各站点的学术报告列表URL正则表达式以及各站点的学术报告详细页URL正则表达式,利用网络爬虫爬取任意一个学术报告站点S,得到任意一个页面P并相应解析成DOM树格式;
步骤3、根据页面P利用网络爬虫得到相应的Jsoup Document对象D;
步骤4、根据组合选择器表达式CE和Jsoup Document对象D,利用网络爬虫获取组合选择器表达式CE所对应的HTML标签内的报告内容C;
步骤5、对报告内容C进行关键词的抽取和封装,得到仅包含关键字的报告类实例R;关键字包括:报告标题,报告简介,报告人,报告人简介,报告举办时间,报告举办地点和报告举办单位;由关键字及其对应的内容构成关键字段;
步骤6、判断报告内容C是否包含<img>标签;若包含,则执行步骤7;若不包含,则执行步骤8;
步骤7、判断报告内容C中包含的文字数n≤所设定文字数量阈值NM是否成立,若成立,则表示报告内容C为纯图片报告,并设置报告类实例R的remark字段为“纯图片报告”后,执行步骤11;若不成立,则直接执行步骤11;
步骤8、构造标签集合L,标签集合L中包含:HTML标签的块级结束标签</div>、</p>、</pre>、</ul>、</ol>、</li>、</h1>、</h2>、</h3>、</h4>、</h5>、</h6>,以及HTML标签的行级结束标签</br>;
将报告内容C中属于标签集合L中的元素均替换为指定字符串S,并去除报告内容C中其他所有的HTML标签,从而得到纯文本Cp;
步骤9、以指定字符串S为分隔符,对纯文本Cp进行分隔,获得字符串数组A;
步骤10、遍历字符串数组A,对每一个字符串进行处理,如图2所示,抽取关键字所对应的关键内容,并相应填充到报告实例R中,得到初步报告实例R′;
步骤10.1、定义变量i,并初始化i=0;
步骤10.2、判断字符串数组A中的第i个字符串是否为空值,若为空值或空串,则将i+1赋值给i后,判断i>N是否成立,若成立,则表示完成字符串数组A的遍历;否则,重复执行步骤10.2;若不为空值或空串,则执行步骤10.3;N表示字符串数组A的长度;
步骤10.3、去除字符串数组A中的第i个字符串两端的控制符和全角空格,获取第i个字符串的最后一个字符,并判断最后一个字符是否为半角冒号“:”或全角冒号“:”;若是,则执行步骤10.4;否则,执行步骤10.9;
步骤10.4、取出第i个字符串的最后一个字符之前的子串,并记为keyi;
步骤10.5、判断keyi≥a是否成立,若不成立,则表示第i个字符串的最后一个字符之前的子串keyi为报告关键字,执行步骤10.6;否则,表示第i个字符串的最后一个字符之前的子串keyi不是报告关键字。将i+1赋值给i后,判断i>N是否成立,若成立,则表示完成字符串数组A的遍历;否则,返回执行步骤10.2;a表示所设定的关键词长度的阈值;
步骤10.6、去除子串keyi所包含的标点符号和数字,得到预处理后的子串key′i;
步骤10.7、判断第i+1个字符串是否为空串,若是,则将i+1赋值给i,判断i>N是否成立;若成立,则表示完成字符串数组A的遍历;若不成立,则重复执行步骤10.7;否则,取出第i+1个字符串作为关键字所对应的内容;
步骤10.8、搜索第i个字符串中是否存在半角冒号“:”或全角冒号“:”,若存在,则记录第一个半角冒号“:”或全角冒号“:”所在的位置,记为Pi,并将位置Pi之前的子串记为keyi,位置Pi之后的子串作为关键字所对应的内容;若不存在,将i+1赋值给i,判断i>N是否成立;若成立,则表示完成字符串数组A的遍历;否则,返回执行步骤10.2;
步骤11、对初步报告实例R′中的报告标题关键字所对应的内容进行空值判断;若报告标题关键字所对应的内容为空,则执行步骤12;否则,执行步骤15;
步骤12、对学术报告站点S的组合选择器表达式TE进行空值判断,若组合选择器表达式TE为空,则执行步骤14;否则,执行步骤13;
步骤13、根据Jsoup Document对象D和组合选择器表达式TE,抽取组合选择器表达式TE所对应的HTML标签内的内容TC;
对组合选择器表达式TE所对应的HTML标签内的内容TC进行空值判断,若组合选择器表达式TE对应的HTML标签内的内容TC为空,则执行步骤14;否则,设置组合选择器表达式TE对应的HTML标签内的内容TC作为报告标题的内容;从而得到准报告实例R,执行步骤15;
步骤14、设置初步报告实例R′中的报告标题关键字所对应的内容为网页标题所对应的内容;从而得到准报告实例R;
步骤15、对准报告实例R中的报告举办时间关键字所对应的内容进行空值判断,若为空,则表示准报告实例R非网络学术报告,并丢弃准报告实例R,若不为空,则继续判断报告举办地点所对应的内容是否为空,若为空,则表示准报告实例R非网络学术报告,并丢弃准报告实例R,若不为空,则表示准报告实例R为网络学术报告并存入学术报告数据库中用于预告和展示。
- 还没有人留言评论。精彩留言会获得点赞!