一种基于医学文献数据库的组合药物识别与排序方法与流程
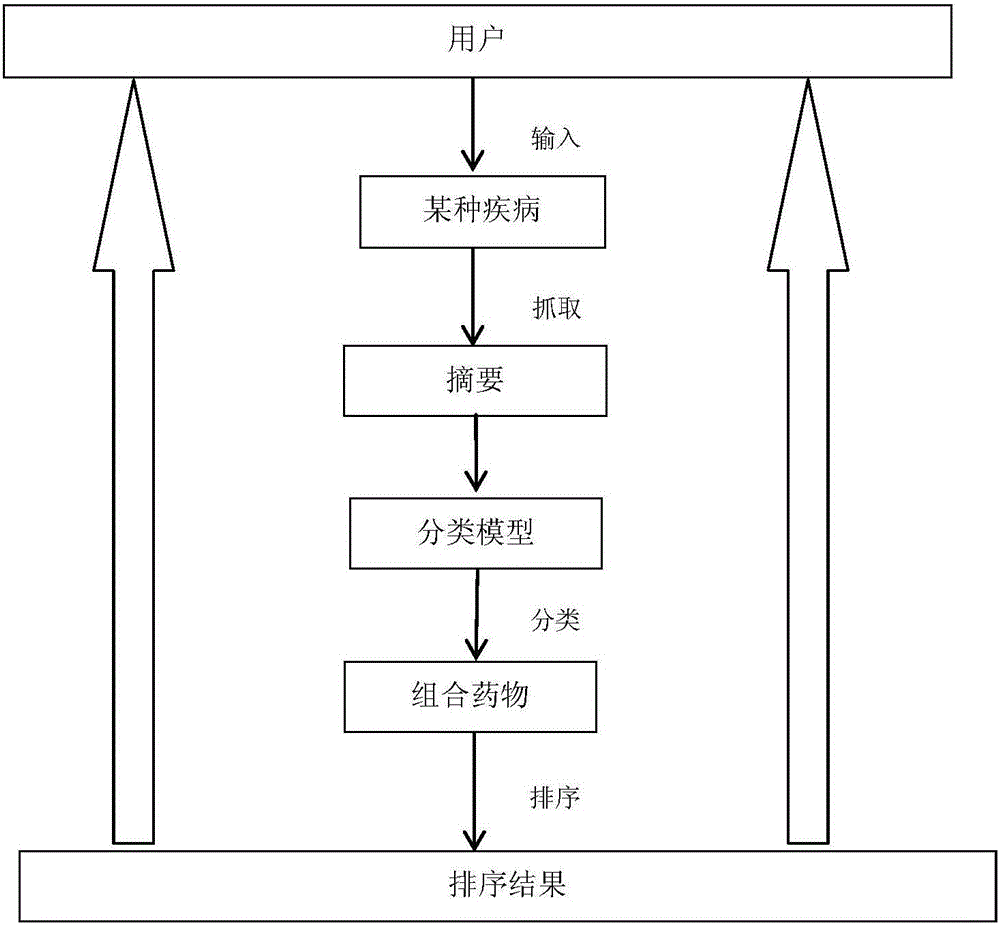
本发明涉及计算机技术在医学临床
技术领域:
,特别是一种基于医学文献数据库的组合药物识别与排序方法。
背景技术:
:众所周知,医学文献已经成为医学研究者和工作者重要的信息来源,但在信息爆炸的当今社会,医学信息也在大量爆发。据统计,医学信息资源占据约30%以上互联网信息资源,医学文献的数量正以惊人的速度增长,全球医药类期刊近3万种,每年发表论文200多万篇并且以每年7%速度递增,医学文献的日益更新成为医学研究者和工作者的一大挑战。临床医生平均每天必须阅读大量的专业文献,才可能跟上现代医学发展的速度,这对医生会造成很大的工作压力,也没有办法全方位地评价所有相关的文献。所以如何从医学文献数据库中学习到先进的医学知识,获得针对某种疾病的最佳治疗方案以辅助医生进行诊断成为急需解决的问题。目前,针对从医学文献中通过计算机相关技术获得针对某种疾病的治疗药物这一问题,已经存在的排序方法有MedRank排序方法。基于医学文献数据库的MedRank方法做的工作是从MEDLINE数据库中提取数据构建了一个医学信息网,然后应用net-clus中排名的方法解决“给定疾病名称,寻找最有效的K种方法”。该方法首先给定疾病,从medline(Medlarsonline医学文献联机数据库)中提取信息构建疾病的星型网络,然后经过medrank算法选出top-k最佳治疗方案,最后利用专家评审评估实验结果。虽然该方法提出了如何科学地对医学文献进行排序的方法,但存在一个问题,MedRank实际提供的是针对某一种疾病的所有涉及的单药的排名,可是现在很多文献提出的针对某一种疾病的治疗方案涉及到多种药物组合,在MedRank中针对这样的文献,就会将文献中提到的多种药物的关系统一定义为并列关系,即每一种药物都对该病有治疗的效果,这对文献想要表达的意思进行了曲解,对结果也造成一定的误差。技术实现要素:本发明的目的是提出一种基于医学文献数据库的组合药物识别与排序方法。本发明的目的是通过以下技术方案来实现的:本发明提供的基于医学文献数据库的组合药物识别与排序方法,包括以下步骤:S1:在医学文献数据库中抓取出包含指定疾病的文章信息,利用药物实体识别出含多种药物的文献信息;将文章中的摘要信息和标题信息作为数据集;S2:将数据集中的一部分作为训练集和测试集进行人工标注,标记为药物为组合关系的文献和非组合关系的文献;S3:使用文本挖掘中的特征选择方法CHI卡方统计法抽取分类关键词,并使用TF/IDF对每一个关键词进行加权作为特征,选择的分类特征包括分类关键词,药物是否出现在同一句话中,词特征、词性特征、逻辑特征以及依存句法特征,将训练集和测试集中的特征进行抽取;S4:使用支持向量机训练分类模型,同时使用遗传优化算法进行优化参数;S5:得到分类的含多种药物和药物之间存在组合关系的文献,将文献作为medrank的输入,使用medrank进行排序得到推荐结果。进一步,所述抽取包含指定疾病的文章并识别出包含多种药物的文献的具体步骤如下:S11:MEDLINE文献数据库提供的mesh词是美国国立医学图书馆编制的权威性主题词表,某篇文献的mesh词可以作为该文献的关键词;针对某一种疾病,在MEDLINE文献数据库抽取出mesh词包含这种疾病的文献信息。得到摘要信息和文献标题信息。S12:针对上一步得到的结果,借助已有的药物实体识别出摘要中的药物,将摘要中含多个药物的文章抽取出来作为数据集。进一步,所述抽取分类关键词的具体步骤如下:S31:将得到的数据集中的摘要信息和标题信息进行人工标记,标记为药物为组合关系的文献和药物为非组合关系的文献;S32:将文本使用向量空间模型进行表示,给定一个文档D(t1,ω1;t2,ω2;...;tn,ωn),D符合两个标准:1)各特征项tk(1≤k≤n)互异;2)各个特征项tk无先后顺序关系;S33:使用文本挖掘中文本特征抽取方法χ2统计法和阈值进行抽取分类关键词;按照以下公式计算得特征项的CHI值:其中,N表示训练集的总数,A表示属于Cj类且包含ti的文档频数,B表示不属于Cj类且包含ti的文档频数,C表示属于Cj类但不包含ti的文档频数,D表示不属于Cj类且不包含ti的文档频数;CHI为特征项ti对Cj的值;再根据阈值挑选出符合要求的特征项作为分类关键词;S34:使用TF-IDF计算出每一个被选中的关键词的权重,权重公式为:其中,ωij表示TF-IDF值;tfij表示特征项在文档中出现的频数;S35:抽取分类关键词的特征。进一步,所述抽取分类关键词的特征的具体步骤如下:S351:将训练数据集中的摘要进行词性标注、语义处理和句法分析;S352:抽取分类特征,按照以下方式判断两种药物是否为组合关系:1)关键词特征:按照以下公式处理关键词特征:Fk=ωaKa+ωtKt;其中,ka为摘要关键词,kt为标题关键词;d1为一种药物;d2为另一种药物;2)词特征:包含d1左边的单词,d2右边的单词,d1与d2中间的单词;3)词性特征:将第二项词特征集中的每一个词的词性作为词特征的补充;4)逻辑特征:包含药物之间的距离,每一个药物离它关键词的最短距离,药物之间其他药物的个数,药物之间的标点符号以及动词的个数;5)依存句法分析特征:进一步,所述分类模型按照以下方式进行建立:S41:将所有特征进行量化和归一化预处理;S42:使用支持向量机建立分类模型,选用RBF作为核函数,并使用遗传算法、粒子群算法对带有的参数c和g进行寻优;进一步,所述medrank进行排序的具体步骤如下:S51:使用分类模型判断所有的文献中的药物关系,并将药物关系为组合的提取出来作为数据集;S52:将得到的数据集进行预处理,并将medrank中输入时需要的药物由单个药物换成数据集中的组合药物;S53:使用medrank进行排序,得到top10的结果作为推荐结果反馈给用户。由于采用了上述技术方案,本发明具有如下的优点:本发明公开了一种基于医学文献数据库的组合药物识别与排序方法,首先抓取公开的医学文献数据库(例如medline或pubMed)上的医学文献摘要,并识别其中的药物实体;然后使用文本挖掘中的抽取特征的方法抽取特征,使用机器学习中的分类算法对文本中提到的药物进行分类,分类为组合关系或非组合关系,分类算法的参数使用优化算法进行优化;最后使用Medrank进行组合药物的排序,得到关于某种疾病的组合用药的推荐方案。本发明提供的基于医学文献数据库的组合药物识别与排序方法,针对海量的以及每年以指数级增长的医学文献,医学研究者无法阅读并发现其中的规律这一难题,利用文本挖掘技术判别文献中提及的药物之间的关系,使用medRank进行排序,让医学工作者可以快速了解到文献中治疗某种疾病的组合药物的排序结果以及历年的变化趋势,使用计算机进行统一阅读文章,减少医学研究者阅读海量文献的压力。本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。附图说明本发明的附图说明如下。图1为本发明的基于医学文献数据库的组合药物识别与排序方法原理图。图2为本发明的基于医学文献数据库的组合药物识别与排序方法流程图。图3为排名前10的组合药物的历年变化趋势图。图4为2013欧洲高血压指南中的药物评估示意图。具体实施方式下面结合附图和实施例对本发明作进一步说明。实施例1如图1所示,图1为原理图;本实施例提供的一种基于医学文献数据库的组合药物识别与排序方法,首先使用文本挖掘的方法在满足要求的摘要中抽取分类特征,其次使用机器学习中的支持向量机模型进行分类,并使用遗传算法对支持向量机模型的参数进行优化;自此可以识别出含多种药物并且药物之间存在组合关系的文献,最后使用medrank算法对这些文献进行排序,得到针对某种疾病的组合药物的推荐结果。其中,抽取分类特征可以使用JAVA语言简单的实现,使用支持向量机模型进行分类可以使用台湾大学林智仁(LinChih-Jen)教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包LIBSVM进行实现,MEDRANK可以使用Java语言进行实现。实施例2本实施例提供的方法如下:首先在MEDLINE文献数据库中抓取出包含指定疾病的文章信息,利用药物实体识别出含多种药物的文献信息;将文章中的摘要信息和标题信息作为数据集,其次将这些数据集中的一部分作为训练集和测试集进行人工标注,标记为药物为组合关系的文献和非组合关系的文献;然后使用文本挖掘中的特征选择方法CHI卡方统计法抽取分类关键词,并使用TF/IDF对每一个关键词进行加权作为特征,选择的分类特征包括分类关键词,药物是否出现在同一句话中,这句话的词特征、词性特征、逻辑特征以及依存句法特征,将训练集和测试集中的这些特征进行抽取;然后使用支持向量机训练分类模型,期间使用遗传算法等优化算法进行优化参数,最后得到分类好的含多种药物并药物之间存在组合关系的文献,将这些文献作为medrank的输入,最后使用medrank得到推荐结果。所述方法的具体实施步骤如下:抽取包含指定疾病的文章并识别出包含多种药物的文献:①MEDLINE文献数据库提供的mesh词是美国国立医学图书馆编制的权威性主题词表,某篇文献的mesh词可以作为该文献的关键词。针对某一种疾病,在MEDLINE文献数据库抽取出mesh词包含这种疾病的文献信息。得到摘要信息和文献标题信息。②针对上一步得到的结果,借助已有的药物实体识别出摘要中的药物,将摘要中含多个药物的文章抽取出来作为数据集。抽取分类关键词:①将得到的数据集中的摘要信息和标题信息进行人工标记,标记为药物为组合关系的文献和药物为非组合关系的文献。②将文本使用向量空间模型进行表示。给定一个文档D(t1,ω1;t2,ω2;...;tn,ωn),D符合两个标准:其中,t1表示特征项;ω1表示权值;1)各特征项tk(1≤k≤n)互异(没有重复);2)各个特征项tk无先后顺序关系。③使用文本挖掘中文本特征抽取方法χ2统计法(CHI)和阈值进行抽取分类关键词。令N表示训练集的总数,A表示属于Cj类且包含ti的文档频数,B表示不属于Cj类且包含ti的文档频数,C表示属于Cj类但不包含ti的文档频数,D表示不属于Cj类且不包含ti的文档频数。那么特征项ti对Cj的CHI值为由式(1)得特征项的CHI值,再根据阈值挑选出符合要求的特征项作为分类关键词④使用TF-IDF计算出每一个被选中的关键词的权重。权重公式为其中,N表示文本数量;ni表示特征项的文本数量;抽取分类特征:①将训练数据集中的摘要进行词性标注、语义处理和句法分析。②抽取分类特征,以判断两种药物是否为组合关系为例,一种药物d1和另一种药物d2的分类特征包含:1)关键词特征:(2)中的摘要关键词ka和标题关键词kt,并包含他们各自的权重,关键词特征为Fk=ωaKa+ωtKt。2)词特征:包含d1左边的单词,d2右边的单词,d1与d2中间的单词。3)词性特征:将第二项词特征集中的每一个词的词性作为词特征的补充,避免词特征的稀疏性。4)逻辑特征:包含药物之间的距离,每一个药物离它关键词的最短距离,药物之间其他药物的个数,药物之间的标点符号以及动词的个数。如下表为逻辑特征集合信息:5)依存句法分析特征:本实施例提供的依存句法分析是一种自然语言处理方法,将其引入到组合关系判断的特征中以提高有效性;它将句子分析成一颗依存句法树,描述出各个词语之间的依存关系,即指出了词语之间在句法上的搭配关系,这种关系是与语义相关联的,使用stanfordparser工具包进行抽取依存句法特征。其特征主要包含:建立分类模型:①将所有特征进行量化、归一化等预处理②使用支持向量机建立分类模型,选用RBF作为核函数,并使用遗传算法、粒子群算法对带有的参数c和g进行寻优。使用Medrank进行排序,得到推荐结果:①使用(4)建立的模型判断所有的文献中的药物关系,并将药物关系为组合的提取出来作为这一步的数据集。②将得到的数据集进行预处理,并将medrank中输入时需要的药物由单个药物换成数据集中的组合药物。③使用medrank进行排序,得到top10的结果作为推荐结果反馈给用户。实施例3本实施样例使用了medline医学文献数据集从1966年到2015的数据。使用medline提供的xml数据集。数据集的格式如下表:其中每一个文献信息以<medlinecitation>开始,以</medlinecitation>结束。包含的关键字段说明如下:该样例研究的疾病为高血压。2、具体步骤:抓取mesh词中包含关键词”humans”and”hypertension”的文献信息;抓取摘要中含多个药物实体的文献,获得7911篇摘要作为原始语料;将其中部分摘要进行人工标注。标注为有组合关系的摘要和没有组合关系的摘要;使用文本挖掘中的文本表示方法和文本特征选择的方法进行抽取分类关键词。最终选择出20个分类关键词,并使用TF-IDF计算他们的权重。词性标注及句法分析:将包含两个及两个以上药物名称的句子进行筛选,共有13829个句子,然后使用Stanford-postagger(http://nlp.stanford.edu/software/tagger.shtml)和Stanfordparser(http://nlp.stanford.edu/downloads/lex-parser.shtml)对这些句子进行词性标注和句法分析。相关特征提取:按照训练和测试SVM模型的特征向量提取方法,从以上预处理语料中提取相应的关键词特征、词特征、词性特征、逻辑特征以及依存句法特征,将这些文字特征量化和归一化,最终使用分类模型判断出药物之间的关系。使用medrank进行排序:将包含判断为组合关系的药物和这些组合药物的文章作为medrank的输入,使用medrank进行排序,得到top10的结果作为推荐结果。3、结果展示使用SVM方法,从高血压疾病语料中得到的组合药物提取关系数据规模如下:文献类型总篇数RCTmeta-analysisCCT总文献1043411051410351943包含多种药物7911330290434包含多种药物并包含组合关系14946981294(1)SVM分类模型评估在试验中,将语料按照2:1的比例,将上面抽取的特征进行训练和测试,分别使用GA遗传算法、PSO粒子群算法和ACO蚁群算法进行优化,将每一种方法平均运行10次,得到的评估结果如下:(2)使用Medrank排序的结果top10,图中排序以图中右边圆点为序,从上到下以下为序号1-10号,具体如下表所示:排序药物Rank值1ACEI/Diuretics0.1121192436237512Diuretics/beta-blockers0.09885393955136663ARB/CCB0.09148803409229194ARB/Diuretics0.08421153259770085ACEI/Diuretics/CCB0.08140421723477786ACEI/CCB0.07655992089868267Diuretics/CCB0.07647884758178388beta-blockers/CCB0.0363070250330649ACEI/beta-blockers0.025588765892999110ACEI/Diuretics/beta-blockers0.025152439415279如图3所示,表示药物在不同年份的使用情况;图3为排名前10的组合药物的历年变化趋势图,说明如下:(1)横坐标为年份,例如1963-1983代表的是发表时间大于等于1963,小于1983的文献数据;all代表所以年份的数据(2)纵坐标指的是相对排名,值为10代表排在第一位,以此类推。4、结果评估如图4所示,图4为指南中给出的药物,使用2013欧洲高血压指南进行评估:其中,图中六边形的六个顶点从最上面起顺时针依次分别为:ThiazideDiuretics;Angioensin-receptoublockers(ARB);Calciumantagonists(CCB);ACEinhibitors(ACEI);OtherAntihypertensives(OTHER);Beta-blockers;图中右边六边形的三条边为绿色,最上面的顶点到下面两个点的连线为绿色,最下面的点到右边上面的点的连线为红色;绿色线为推荐组合用药,虚线为一般推荐组合用药,红色为不能组合用药。推荐药物与结果的对比表如下:排序药物推荐1ACEI/Diuretics是2Diuretics/beta-blockers是3ARB/CCB是4ARB/Diuretics是5ACEI/Diuretics/CCB是6ACEI/CCB是7Diuretics/CCB是8beta-blockers/CCB一般9ACEI/beta-blockers一般10ACEI/Diuretics/beta-blockers一般从结果可以看出,排名前7的组合药物都是指南中推荐用药,说明结果的正确性。最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的保护范围当中。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1