一种基于密度平衡的近邻迁移分区方法与流程
本发明涉及一种分布式环境下的数据分区方法,根据不同节点的存储密度就近动态调整分区大小,完成数据迁移,该方法同时支持复制因子的概念。主要适用于分布式存储、分布式计算等技术领域。
背景技术:
在分布式存储系统设计时,一个不可避免需要解决的问题是数据在不同节点间如何分区,该算法的选择直接关系数据分布的均衡性以及整个系统的高可靠性、高可扩展性。
常见的分区算法一般包含两类,通用算法以及专用算法。其中专用算法一般都是跟业务场景紧密耦合的,例如根据不同地区、不同渠道、不同关键字进行分区等;通用算法比较常用的是对数据进行hash后进行分区,例如hash后取模操作能跟根据节点数进行分区,也有相对更加完善的一致性hash算法,在重分区上能够规避大量的数据迁移。
另外还有一种基于hash块的分区算法,大体思路是将hash过后的值分为若干个hash块,然后不同的hash块可以落在不同的节点上,从而能够给数据迁移带来更加便捷的操作。然而,目前大多数hash块分区算法有以下不完善的地方:hash块的分布未考虑不同机器的存储容量,由于不同机器的可用空间是不同的,如果完全平衡分区,就会导致存储空间大的机器无法充分利用存储空间;分布式节点变动时,迁移量比较大,存在从任意节点到任意节点的迁移。
技术实现要素:
本发明的目的在于针对现有技术的不足,提供一种基于密度平衡的近邻迁移分区方法。
本发明的目的是通过以下技术方案来实现的:一种基于密度平衡的近邻迁移分区方法,具体为:存在一个分布式集群C={Node1,Node2,…,Noden},其对应的存储容量为{Size1,Size2,…,Sizen},且有h块数据{d1,d2,…dh}分布在集群C中(h>n),集群中任意节点x对应数据块数目为Countx,具体分布为[di,dj](1<=i<=j<=h,Countx=j+1-i,表示第i块数据到第j块数据存在节点x中),节点x对应的存储密度Densityx=Countx/Sizex;整个集群C的上述数据块分配方案记为一个数据块分布环,即节点n的下一个节点是节点1,表述为Node1(d1-di)=>Node2(di+1,dj)=>…=>Noden(dz,dh)。同一物理节点同时作为部分数据块的master节点,同时又是部分数据块的slave节点,通过slave数据块分布环实现高可用性,分配原则为:master数据块分布环顺时针/逆时针转动一次,Node1(d1-di)=>Node2(di+1,dj)=>…=>Noden(dz,dh)经过顺时针旋转可得到slave数据块分布环Noden(d1-di)=>Node1(di+1,dj)=>…=>Noden-1(dz,dh),逆时针旋转可得到Node2(d1-di)=>Node3(di+1,dj)=>…=>Node1(dz,dh)。通过顺时针/逆时针移动一次实现master-slave的高可用机制,同时也可以通过移动1次、2次、n次分别实现复制因子为2、3、n+1的多副本可用性设计。
进一步地,当新节点m加入集群C时,具体扩展执行方法为:
(1)找到集群中密度最大的节点,记为节点o:计算所有节点的密度(单位存储存放数据块的多少,即上文所示的Density),并找出密度最高的节点;如果多个节点密度一样,取数据块分配较多max(Count)的节点;如果数据块一样多,取节点索引值小min(i)的节点。
(2)重新计算平衡状态,计算迁移动作:节点m加入集群C重新平衡后,节点o的数据块大小为new_Counto=Sizeo*Counto/(Sizeo+Sizem),节点m分得的hash块大小为new_Countm=Counto-new_Counto;于此同时计算数据迁移的迁移指令记为mv new_Countmo m(mv表示move动作,第一个参数表示待迁移数据块,第二个参数表示源节点,第三个参数表示目标节点);当复制因子>=2,需要同时计算slave数据块分布环相应数据的迁移指令。
(3)执行迁移动作:执行上面步骤完成的迁移指令。
进一步地,当节点b失效离开集群时(复制因子为2),master数据块分布环为Node1(d1-di)=>Node2(di+1,dj)=>…=>Noden(dz,dh),slave数据块分布环为Noden(d1-di)=>Node1(di+1,dj)=>…=>Noden-1(dz,dh),具体收缩方法为:
(1)失效节点b两端找到密度较小的节点,记为节点a;
(2)失效节点b对应的数据块归入节点a:如果复制因子<2,那么节点b对应的数据块将会丢失,原本会存储到节点b的新数据块将会被存储到节点a。复制因子>=2时,因为节点b同时是数据块i-j的master节点,同时又是数据块p-t的slave节点,这些数据需要重新恢复及备份。具体做法是b节点作为master存储的数据块,需要找到slave分布环中对应的数据节点c,产生迁移指令cp i-j c a(cp表示copy命令),同时找到slave数据块p-t对应的master节点d,产生迁移指令cp p-t d c。
(3)执行迁移动作:执行上面步骤完成的迁移指令。
本发明的有益效果是:本发明方法是一种基于密度平衡的、低迁移成本、高可用、高可伸缩设计的分布式集群管理方法。其根据不同节点的存储密度就近动态调整分区大小,完成数据迁移,该方法同时支持复制因子(以确保高可用性)的概念。使用该发明专利后,分布式节点加入集群、离开集群时整个集群能够快速基于密度进行最少数据块的近邻数据迁移,完成平衡动作,同时不会丢失数据及确保客户端访问集群的0miss特性。
附图说明
图1为DBPA请求工作流程图;
图2为扩展性示意图;
图3为可靠性示意图。
具体实施方式
本发明提出了一种密度平衡分区算法(Density Balanced Partition Algorithm),简称DBPA算法,是一种典型的基于hash块进行分区的分区算法。
DBPA算法的核心设计主要包括三部分:正常访问流程、高可用性设计及可伸缩性设计,下面分别阐述这三部分是如何实现的。
一、正常访问流程,主要工作流程如图1所示。
(1)计算hash块:对原始数据进行hash(如sha256,MD5,CRC以及XXHash等),hash后取4字节数据共32比特,前面12比特为对应hash块信息,共4096个hash块。
(2)查询分区表:根据本地存储的分区表(里面保存哪些hash块存储于哪个节点等信息),查找对应的数据存储位置。
(3)查询路由节点:根据查询到的存储位置,客户端发起请求到指定的节点查询或者存储数据。
(4)计算存储索引:存储节点在收到请求后,马上根据相同的hash算法计算出32比特hash值,并取后20比特作为存储索引信息在本地存储中查询或存储数据。如果这期间数据分区发生变动,重新完成1),2),3)步骤。
(5)返回结果:存储节点将请求结果返回调用的客户端。
二、高可用性的实现:
(1)同一物理节点同时作为部分hash块的master节点,同时又是部分hash块的slave节点。
(2)其高可用设计主要通过slave hash环来实现,分配原则可以简单总结为masterhash环顺时针/逆时针转动一次,如masterhash环如果是A(0-3)=>C(4-5)=>B(6-8),slave环经过顺时针旋转变为B(0-3)=>A(4-5)=>C(6-8),逆时针旋转变为C(0-3)=>B(4-5)=>A(6-8)。如果按照顺时针走法,那么可以理解为hash环中有9个hash块,其中索引为0-3块master节点在A,slave节点在B。
(3)通过顺时针/逆时针移动一次实现master-slave的高可用机制,同时也可以通过移动1次、2次、n次分别实现复制因子为2、3、n+1等的多副本可用性设计。
三、可伸缩性的实现:
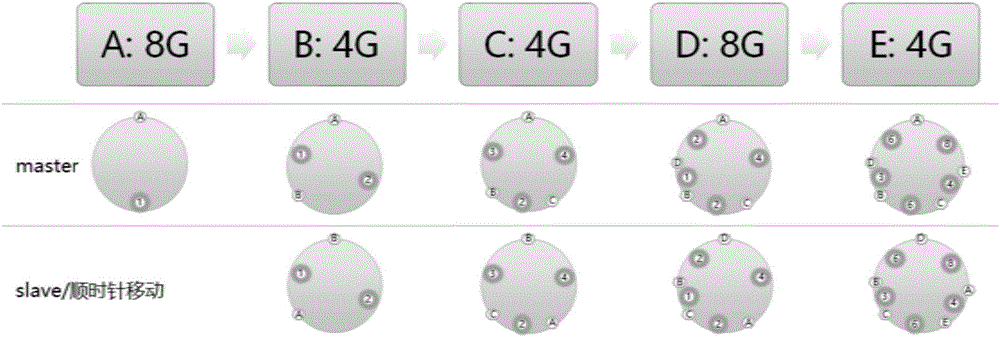
如图2所示,当新节点m加入集群时,假设原来集群是A(0-3)=>C(4-5)=>B(6-8),扩展方法为:
(1)找到集群中密度最大的节点,记为节点o:计算所有节点的密度(单位存储存放数据块的多少,即上文所示的Density),并找出密度最高的节点;如果多个节点密度一样,取数据块分配较多max(Count)的节点;如果数据块一样多,取节点索引值小min(i)的节点。
(2)重新计算平衡状态,计算迁移动作:节点m加入集群C重新平衡后,节点o的数据块大小为new_Counto=Sizeo*Counto/(Sizeo+Sizem),节点m分得的hash块大小为new_Countm=Counto-new_Counto;于此同时计算数据迁移的迁移指令记为mv new_Countm o m(mv表示move动作,第一个参数表示待迁移数据块,第二个参数表示源节点,第三个参数表示目标节点);当复制因子>=2,需要同时计算slave数据块分布环相应数据的迁移指令。
(3)执行迁移动作:执行上面步骤完成的迁移指令。
如图3所示,当节点B失效离开集群时(复制因子为2),masterhash环为A(0-7)=>E(8-11)=>C(12-17)=>B(18-20)=>D(21-26),slavehash环为D(0-7)=>A(8-11)=>E(12-17)=>C(18-20)=>B(21-26),具体收缩方法为:
(1)失效节点两端找到密度较小的节点,记为节点D:按照前面同样的思路找到失效节点近邻密度较小的节点。
(2)失效节点B对应的hash块归入节点D:如果复制因子<2,那么节点B对应的老数据将会丢失,原本会存储到节点B的新数据将会被存储到节点D。复制因子>=2时,因为节点B同时是18-20块的master节点,同时又是21-26块的slave节点,这些数据需要重新恢复及备份。具体做法是B节点作为master存储的部分数据,需要找到slave存储位置C,产生迁移指令cp 18-20C D(cp表示copy命令),同时找到slave 21-26对应的master节点D,产生迁移指令cp 21-26D C。
(3)执行迁移动作:执行上面步骤完成的迁移指令。
- 还没有人留言评论。精彩留言会获得点赞!