精确快速低投入的FPGA延时估计方法与流程
本发明涉及FPGA架构优化领域,特别涉及一种FPGA延时计算模型。具体讲,涉及精确快速低投入的FPGA延时估计方法。
背景技术:
随着应用的多样性发展,FPGA的架构不断变化,花费在架构探索上的时间也越来越多。传统的方法需要通过大量的实验才能决定符合延时要求的FPGA架构。架构设计师需要使用电路仿真工具来测量每一种FPGA架构下的关键路径延时,再利用布局布线工具仿真基准电路映射到FPGA架构上的延时,并根据结果对架构性能进行评估。事实上,这种实验的方法不可能探索所有的架构设计,因为这将花费巨大的精力和时间,尤其是在延时仿真阶段。相反,基于数值分析模型的方法能够快速地评估各个FPGA架构的性能。这种方法通过数值分析和典型实验,利用FPGA的架构参数对FPGA岛的典型关键路径进行建模,从而实现对FPGA架构的快速评估。
目前,研究人员已经基于Elmore模型建立了FPGA延时估计的数值分析模型。但是,Elmore模型对晶体管进行了线性等效,导致其精确度不高,而且不能直观地体现晶体管级参数(Vdd和Vt)对延时的影响。例如,延时随架构参数N的增大而增大,随Vdd的增大而减小,如果只考虑架构参数则会错过很多可能的优化结果,使结果不能达到最优。
神经网络具有强大的学习能力,能够学习任何系统的行为,并且可以快速模拟出这些系统对输入做出的响应。利用大量真实的FPGA延时数据来对神经网络进行训练,可以得到其输入与输出之间的关系,建立FPGA的延时模型。但这种方法对神经网络过度依赖,且需要大量的数据支持才能获得高精确度的延时估计结果,需要在前期投入大量的时间。
基于知识的神经网络结合了神经网络的强大学习能力和已有数值分析模型,使神经网络和分析模型彼此互补。所以,利用基于知识的神经网络来构建延时和FPGA架构参数及晶体管级参数之间的关系,是一种既可以提高模型的精度又不会显著增加估计时间的方法。而且相较于传统神经网络而言,基于知识的神经网络可以在较少的训练数据下得到精确的延时估计结果,节省了大量时间。
参考文献:
[1]A.M.Smith,G.A.Constantinides,P.Y.K.Cheung.FPGA architecture optimization using geometric programming[J].Computer-Aided Design of Integrated Circuits and Systems.2010,29(8):1163-1176。
[2]I.Kuon,J.Rose.Exploring area and delay tradeoffs in FPGAs with architecture and automated transistor design[J].Very Large Scale Integration(VLSI)Systems.2011,19(1):71-84。
[3]C.Chiasson,V.Betz.COFFE:Fully-automated transistor sizing for FPGAs[C].//Field-Programmable Technology(FPT),Kyoto,2013:34-41。
技术实现要素:
为克服现有技术的不足,本发明旨在提出一种估计FPGA电路延时的数值分析模型,全面考虑影响电路延时的关键参数,允许在FPGA架构设计阶段协同探索架构级参数和晶体管级参数的可变性。并将延时模型与人工智能神经网络相结合,既体现和保持参数间的物理意义,又减少神经网络的训练数据量,实现快速、精确、低投入的延时估计。为此,本发明采用的技术方案是,精确快速低投入的FPGA延时估计方法,步骤如下:
1)确定拟合参数ɑ和有效迁移率μ;
2)将FPGA中各子电路等效为RC模型,结合FPGA架构参数,确定各子电路中每一类晶体管的负载电容;
3)根据已确定好的拟合参数ɑ、有效迁移率μ和负载电容参数,对FPGA中各子电路分别建立延时模型,即FPGA-macro延时模型;
4)收集训练数据,并对其进行分析和归一化;
5)将FPGA-macro延时模型与神经网络相结合,建立KBNN延时模型并进行训练,求解权重Ω和Φ以及隐藏神经元的数量m使得训练误差Et和验证误差Ev最小。
一个实例中具体步骤进一步细化为:
1.确定拟合参数ɑ和有效迁移率μ
首先,分别建立由10、11、12个非门串联连接的非门链,并利用电路仿真工具HSPICE分别测量各非门链的延时,记为τ10,τ11,τ12,通过计算得到PMOS晶体管的延时为tpmos=τ12-τ11,NMOS晶体管的延时为tnmos=τ11-τ10,利用公式(1)和公式(2)求得拟合参数ɑ和有效迁移率μ的值,(Vt1,Δt1)和(Vt2,Δt2)是在相同Vdd下得到的阈值电压和晶体管延时的组合,其中,We和Le分别是有效沟道宽度和长度,Vdd为供电电压,Vt为阈值电压,Ci和Cox分别代表负载电容和氧化电容,
2.确定负载电容
在获得ɑ和μ的值之后,根据连接块等效模型确定各晶体管的负载电容,连接块中四类晶体管的负载电容获得方法如公式(3)-(6)所示,其中,W为布线通道宽度,Fcin为逻辑块输入引脚所能连接的布线轨道数目,N为逻辑块中基本逻辑单元的数量,K为查找表LUT的输入数量,CCB,mux1,CCB,mux2和CCB,drv1,CCB,drv2分别表示连接块选择器和连接块缓冲器中晶体管的负载电容,其中,Cj,CBmux1,Cj,CBmux2是连接块多路选择器中晶体管的结电容,Cg,CBdrv1,Cg,CBdrv2和Cj,CBdrv1,Cj,CBdrv2分别是连接块缓冲器中晶体管的栅电容和结电容,Cj,localmux1是局部互连多路选择器中晶体管的结电容,ceil()为向上取整函数,floor()为向下取整函数:
CCB,drv 1=Cj,CBdrv 1+Cg,CBdrv 2 (5)
CCB,drv 2=Cj,CBdrv 2+N*K*Cj,localmux 1 (6)
3.建立FPGA-macro延时模型
根据已确定的参数,连接块的延时表示为公式(7)的形式,We,CB,mux1和We,CB,mux2分别为连接块中一级多路选择器和二级多路选择器的晶体管有效沟道宽度,We,CB,drv1和We,CB,drv2为连接块缓冲器中的晶体管有效沟道宽度,典型关键路径的延时由各子电路的加权和得到,表示为公式(8)的形式,TSB为开关块的延时,TCB为连接块延时,Tlocalmux为局部互连块延时,Tfeedback为反馈路径延时,Tgeneral_output为输出路径延时,TLUT为查找表延时,TLUTdrv为查找表缓冲器延时,权重w1-w6由各子电路出现在布局布线后的基准电路的关键路径上的次数决定,
4.数据收集并进行归一化
在训练开始之前,首先要将训练数据归一化到同一个数量级,所以对每个参数x∈{N,K,W,L,I,Fs,Fcin,Fcout,Vdd,Vtn,Vtp,ΔT}进行公示(9)的所示操作,其中,Vtn和Vtp分别为NMOS晶体管和PMOS晶体管的阈值电压,ΔT是真实值与估计值之差,
其中,xmax和xmin是训练数据中x的最大值和最小值,x’max和x’min是由训练者自己确定,Fs为开关块灵活性,Fcout为逻辑块输出引脚所能连接的布线轨道数目,L为线长,I为逻辑块输入数量;
在训练完成后,为了使KBNN的输出处于正确的数量级,还将进行去归一化的过程;
5.建立KBNN延时模型并训练
基于上述已建立的FPGA-macro延时模型,结合神经网络可获得FPGA的KBNN延时模型,这个KBNN结构中共包含五种神经元:输入神经元、隐藏神经元、MLP输出神经元、知识神经元和KBNN输出神经元,输入神经元和隐藏神经元之间的权重为Ω=(ωij,i=1,2,...,m,j=0,1,...,11),隐藏神经元和MLP输出神经元之间的权重为Φ=(φk,k=0,1,...,m),隐藏神经元的激活函数和隐藏神经元的输入分别表示为公式(10)和公式(11)的形式:
三层MLP神经网络的输出为隐藏神经元的加权和,如公式(12)所示:
ΔTMLP是HSPICE仿真得到的真实值与FPGA-macro延时模型得到的估计值之差,而KBNN的输出则为三层MLP神经网络的输出ΔTMLP与知识神经元的输出Tknowledge之和,如公式(13)所示:
TKBNN_macro=Tknowledge+△TMLP (13)
通过FPGA-macro模型和HSPICE获得400组训练数据和20组测试数据,对KBNN延时模型进行训练,找到符合训练误差Et和验证误差Ev的权重Ω和Φ以及隐藏神经元的数量m,训练过程如下:
1)初始化:给出训练数据,测试数据,三层神经网络模型和最大迭代次数Nmax,并对Ω,Φ和m赋初值,iter为迭代次数;
2)找到三层神经网络模型的权重参数Ω和Φ,使得训练误差Et最小;
3)对三层神经网络进行验证,用更新的Ω,Φ和测试数据计算测试误差Ev;
4)调整m;
如果Ev≈0或iter>Nmax,则停止训练;
否则,iter=iter+1;
如果Et≈0,Ev》0,则增加训练数据并返回2);
如果Et》0,则增加隐藏神经元数量,使m=m+1并返回2)。
本发明的特点及有益效果是:
1.相较于传统的利用实验的方法获得延时,该FPGA延时估计方法可以在短时间内完成延时的估计,不仅全面考虑了影响延时的参数,而且更加直观地反映了各参数与延时的关系,可以有效加快FPGA架构探索流程。
2.利用基于知识的人工智能神经网络,既减少了训练数据量又提高了估计精度,同时还摆脱了器件模型的束缚,使延时估计更加快速灵活。
附图说明:
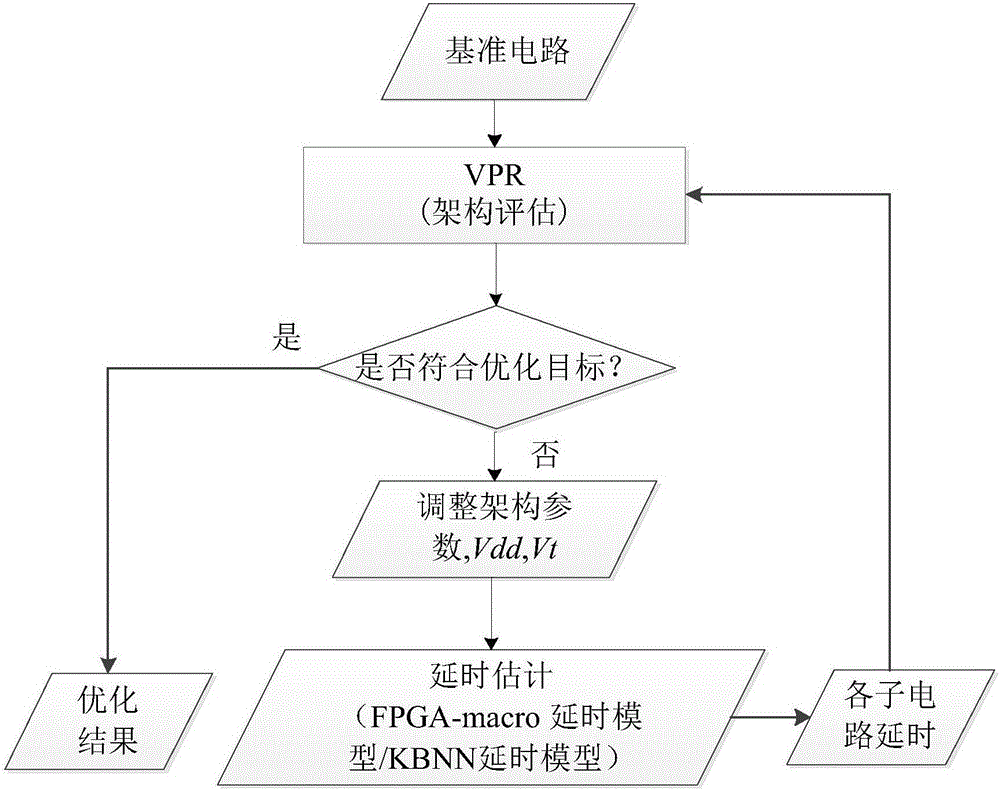
图1为本发明的设计流程图。
图2为本发明应用流程图。
图3为FPGA连接块晶体管级结构及等效模型。
图4为该延时模型的神经网络结构。
图5为实验结果对比。
具体实施方式
本发明提供了一种基于神经网络的融合架构级和晶体管级参数的FPGA电路延时估计方法,可以与架构探索流程相结合,在保证精度的条件下加快架构探索速度。具体技术方案如下:
1)确定拟合参数ɑ和有效迁移率μ。
2)将FPGA中各子电路等效为RC模型,结合FPGA架构参数,确定各子电路中每一类晶体管的负载电容。
3)根据已确定好的拟合参数ɑ、有效迁移率μ和负载电容等参数,对FPGA中各子电路分别建立延时模型,即FPGA-macro延时模型。
4)收集训练数据,并对其进行分析和归一化。
5)将FPGA-macro延时模型与神经网络相结合,建立KBNN延时模型并进行训练,求解权重Ω和Φ以及隐藏神经元的数量m使得训练误差Et和验证误差Ev最小。
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。下面将以FPGA子电路中的连接块为例进行说明。
1.确定拟合参数ɑ和有效迁移率μ
首先,分别建立由10、11、12个非门串联连接的非门链,并利用HSPICE分别测量各非门链的延时,记为τ10,τ11,τ12。通过计算可得PMOS晶体管的延时为tpmos=τ12-τ11,NMOS晶体管的延时为tnmos=τ11-τ10。利用公式(1)和公式(2)求得拟合参数ɑ和有效迁移率μ的值,(Vt1,Δt1)和(Vt2,Δt2)是在相同Vdd下得到的阈值电压和晶体管延时的组合。其中,We和Le分别是有效沟道宽度和长度,Vdd为供电电压,Vt为阈值电压,Ci和Cox分别代表负载电容和氧化电容。
2.确定负载电容
在获得ɑ和μ的值之后,根据图3所示的连接块等效模型确定各晶体管的负载电容。连接块中四类晶体管的负载电容获得方法如公式(3)-(6)所示。其中,W为布线通道宽度,Fcin为逻辑块输入引脚所能连接的布线轨道数目,N为逻辑块中基本逻辑单元的数量,K为LUT的输入数量。CCB,mux1,CCB,mux2和CCB,drv1,CCB,drv2分别表示连接块选择器和连接块缓冲器中晶体管的负载电容,其中,Cj,CBmux1,Cj,CBmux1是连接块多路选择器中晶体管的结电容,Cg,CBdrv1,Cg,CBdrv2和Cj,CBdrv1,Cj,CBdrv2分别是连接块缓冲器中晶体管的栅电容和结电容,Cj,localmux1是局部互连多路选择器中晶体管的结电容,ceil()为向上取整函数,floor()为向下取整函数:
CCB,drv 1=Cj,CBdrv 1+Cg,CBdrv 2 (5)
CCB,drv 2=Cj,CBdrv 2+N*K*Cj,localmux 1 (6)
其它架构参数,如Fs(开关块灵活性),Fcout(逻辑块输出引脚所能连接的布线轨道数目),L(线长),I(逻辑块输入数量)将出现在其它子电路的负载电容公式中。
3.建立FPGA-macro延时模型
根据已确定的参数,连接块的延时可表示为公式(7)的形式,We,CB,mux1和We,CB,mux2分别为连接块中一级多路选择器和二级多路选择器的晶体管有效沟道宽度,We,CB,drv1和We,CB,drv2为连接块缓冲器中的晶体管有效沟道宽度。典型关键路径的延时由各子电路的加权和得到,可以表示为公式(8)的形式,TSB为开关块的延时,TCB为连接块延时,Tlocalmux为局部互连块延时,Tfeedback为反馈路径延时,Tgeneral_output为输出路径延时,TLUT为查找表延时,TLUTdrv为查找表缓冲器延时。其中权重(w1-w6)由各子电路出现在布局布线后的基准电路的关键路径上的次数决定。
4.数据收集并进行归一化
训练数据{N,K,W,L,I,Fs,Fcin,Fcout,Vdd,Vtn,Vtp,ΔT}有很大的数量级差异。如Fcin的取值是(0,1),然而W能够从几十到几百。这个巨大的差异会给训练过程的收敛增加难度,降低训练的KBNN模型的精度。因此,在训练开始之前,首先要将训练数据归一化到同一个数量级。其中,Vtn和Vtp分别为NMOS晶体管和PMOS晶体管的阈值电压,ΔT真实值与估计值之差。所以对每个参数x∈{N,K,W,L,I,Fs,Fcin,Fcout,Vdd,Vtn,Vtp,ΔT}进行公示(9)的所示操作:
其中,xmax和xmin是训练数据中x的最大值和最小值,x’max和x’min是由训练者自己确定的。
在训练完成后,为了使KBNN的输出处于正确的数量级,还将进行去归一化的过程。
5.建立KBNN延时模型并训练
基于上述已建立的FPGA-macro延时模型,结合神经网络可获得FPGA的KBNN延时模型。KBNN延时模型的结构如图4所示,这个KBNN结构中共包含五种神经元:输入神经元、隐藏神经元、MLP输出神经元、知识神经元和KBNN输出神经元。输入神经元和隐藏神经元之间的权重为Ω=(ωij,i=1,2,...,m,j=0,1,...,11),隐藏神经元和MLP输出神经元之间的权重为Φ=(φk,k=0,1,...,m)。其中,隐藏神经元的激活函数和隐藏神经元的输入可分别表示为公式(10)和公式(11)的形式。
三层MLP神经网络的输出为隐藏神经元的权重和,如公式(12)所示:
ΔTMLP是HSPICE仿真得到的真实值与FPGA-macro延时模型得到的估计值之差,而KBNN的输出则为三层MLP神经网络的输出ΔTMLP与知识神经元的输出Tknowledge之和,如公式(13)所示:
TKBNN_macro=Tknowledge+△TMLP (13)
通过FPGA-macro模型和HSPICE获得400组训练数据和20组测试数据,对KBNN延时模型进行训练,找到符合训练误差Et和验证误差Ev的权重Ω和Φ以及隐藏神经元的数量m。训练过程如下:
1)初始化。给出训练数据,测试数据,三层神经网络模型和最大迭代次数Nmax,并对Ω,Φ和m赋初值,iter为迭代次数;
2)找到三层神经网络模型的权重参数Ω和Φ,使得训练误差Et最小;
3)对三层神经网络进行验证,用更新的Ω,Φ和测试数据计算测试误差Ev;
4)调整m;
如果Ev≈0或iter>Nmax,则停止训练;
否则,iter=iter+1;
如果Et≈0,Ev》0,则增加训练数据并返回2);
如果Et》0,则增加隐藏神经元数量,使m=m+1并返回2)。
当训练完成,就可以得到一个可以反复使用的延时模型。通过这个模型,设计者可以快速且精确地判断这个FPGA架构是否符合设计要求,同时可以实现FPGA的架构探索。
- 还没有人留言评论。精彩留言会获得点赞!