一种基于深度神经网络的数字视频特征提取方法与流程
本发明涉及信号与信息处理技术领域,尤其涉及一种基于深度神经网络的数字视频特征提取方法。
背景技术:
视频数据相对于图片数据具有数据量大、数据具有时序联系特性以及数据冗余较大的特点。视频版权保护、视频检索以及视频数据化管理常常需要一种唯一且极其紧凑的描述符作为视频的内容标签。生成视频描述符的最简单方法是独立从各代表帧中提取描述符,将其级联构成整段视频的描述符。
常见方法有统计学法[1],亮度梯度法[2]和彩色相关性法[3]。但是这类方法无法刻画视觉信息的时序特性。为了实现对视频时空特征的提取,文献[4]相邻块沿时间和空间方向上的亮度差值作为视频描述符,文献[5]以特征点的轨迹作为视频描述符。此外,三维信号变换[6]、张量分解[7]和光流法[8]也都被用于构造能够反映视频时空属性的描述符。
发明人在实现本发明的过程中,发现现有技术中至少存在以下缺点和不足:
现有的特征提取方法具有冗余偏大和时序失真敏感的缺点。而且大部分依赖于人工设计,但人工设计的特征提取方法难以捕捉视频信息在时空方向上的本质属性。
技术实现要素:
本发明提供了一种基于深度神经网络的数字视频特征提取方法,本方法通过深度神经网将视频特征提取为简短的视频描述符,该视频描述符能够实现对视频感知内容的摘要化描述,同时具有良好的鲁棒性和区分性,可实现高效、准确的视频内容识别,详见下文描述:
一种基于深度神经网络的数字视频特征提取方法,所述方法包括以下步骤:
训练一个去噪编码网络实现对视频的初始描述符的维数约简,将条件生成模型和编码器级联构成一组基本的特征提取模块;
连续训练多组特征提取模块,按训练先后顺序对所得模块做自底向上的堆叠构成深度神经网络;
训练后处理网络,将其置于深度神经网络的顶部,用以优化视频描述符的鲁棒性和区分性。
其中,所述方法还包括:
对输入视频做预处理,通过条件生成模型来表达视频内容的时空联系。
其中,所述对输入视频做预处理,通过条件生成模型来表达视频内容的时空联系的步骤具体为:
对视频做低通滤波平滑及降采样,将每一帧图片大小压缩到满足神经网络输入层尺寸需要,对降采样后的视频做正则化,使每一帧的像素平均值为零,方差为1;
将视频数据输入条件玻尔兹曼机(Conditional Restricted Boltzmann Machine,CRBM),将预处理视频的每一帧像素置为可见层的神经元,对CRBM网络进行训练。
其中,所述训练一个去噪编码网络实现对视频的初始描述符的维数约简,将条件生成模型和编码器级联构成一组基本的特征提取模块的步骤具体为:
对每个训练视频施加失真并做预处理操作,将失真视频作为CRBM的输入,生成初始描述符,选取多组原始视频和失真视频的初始描述符作为训练数据,训练一个去噪自编码网络;
将训练所得的编码器E(·)堆叠在CRBM之上,得到第一组特征提取模块。
其中,所述连续训练多组特征提取模块,按训练先后顺序对所得模块做自底向上的堆叠构成深度神经网络的步骤具体为:
利用上述特征提取模块的输出作为训练数据,继续训练一对CRBM和编码器,用所得CRBM和编码器重新建立第二组特征提取模块;
依次训练多个CRBM和编码器模块,每个模块的训练数据由前一个模块的输出组成;
按照训练的先后顺序将各个模块进行自底向上的堆叠,形成深度神经网络。
其中,所述训练后处理网络,将其置于深度神经网络的顶部,用以优化视频描述符的鲁棒性和区分性的步骤具体为:
利用由K个CRBM-E(·)模块所构成的深度神经网络为训练视频生成描述符,通过训练后置处理网络的代价函数进行训练;
完成训练后将该后处理网络置于由CRBM和编码器构成的深度神经网络顶层。
本发明提供的技术方案的有益效果是:
1、本发明通过深度神经网络提取视频特征从而生成视频描述符,CRBM(Conditional Restricted Boltzmann Machine)网络能够刻画视频信息的时空本质属性;
2、自编码网络能够实现对描述符的数据约简及鲁棒性提升,后处理网络能够整体优化描述符的鲁棒性和区分性;
3、本发明无须人工设计特征提取方法,通过训练模型学习得到最优的特征提取方案;
4、本发明程序简单,易于实现,计算复杂度低。在CPU主频为3.2GHz,内存为32GB的计算机上的测试结果表明,本发明所述方法计算500帧视频序列所需的时间平均仅为1.52秒。
附图说明
图1为一种基于深度神经网络的数字视频特征提取方法的流程图;
图2为条件受限玻尔兹曼机结构的示意图;
图3为用于视频特征提取的深度神经网络结构的示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。
实施例1
为了实现对视频内容的简要且鲁棒的描述,本发明实施例提出了一种基于深度神经网络的数字视频特征提取方法,参见图1,该方法包括以下步骤:
101:训练一个去噪编码网络实现对视频的初始描述符的维数约简,将条件生成模型和编码器级联构成一组基本的特征提取模块;
102:连续训练多组特征提取模块,按训练先后顺序对所得模块做自底向上的堆叠构成深度神经网络;
103:训练后处理网络,将其置于深度神经网络的顶部,用以优化视频描述符的鲁棒性和区分性。
其中,在步骤101之前,该方法还包括:
对输入视频做预处理,通过条件生成模型来表达视频内容的时空联系。
其中,上述对对输入视频做预处理,通过条件生成模型来表达视频内容的时空联系的步骤具体为:
对视频做低通滤波平滑及降采样,将每一帧图片大小压缩到满足神经网络输入层尺寸需要,对降采样后的视频做正则化,使每一帧的像素平均值为零,方差为1;
将视频数据输入CRBM,将预处理视频的每一帧像素置为可见层的神经元,对CRBM网络进行训练。
其中,步骤101中的训练一个去噪编码网络实现对视频的初始描述符的维数约简,将条件生成模型和编码器级联构成一组基本的特征提取模块具体为:
对每个训练视频施加失真并做预处理操作,将失真视频作为CRBM的输入,生成初始描述符,选取多组原始视频和失真视频的初始描述符作为训练数据,训练一个去噪自编码网络;
将训练所得的编码器E(·)堆叠在CRBM之上,得到第一组特征提取模块。
其中,步骤102中的连续训练多组特征提取模块,按训练先后顺序对所得模块做自底向上的堆叠构成深度神经网络具体为:
利用上述特征提取模块的输出作为训练数据,继续训练一对CRBM和编码器,用所得CRBM和编码器重新建立第二组特征提取模块;
依次训练多个CRBM和编码器模块,每个模块的训练数据由前一个模块的输出组成;
按照训练的先后顺序将各个模块进行自底向上的堆叠,形成深度神经网络。
其中,步骤103中的训练后处理网络,将其置于深度神经网络的顶部,用以优化视频描述符的鲁棒性和区分性具体为:
利用由K个CRBM-E(·)模块所构成的深度神经网络为训练视频生成描述符,通过训练后置处理网络的代价函数进行训练;
完成训练后将该后处理网络置于由CRBM和编码器构成的深度神经网络顶层。
综上所述,通过深度神经网将视频特征提取为简短的视频描述符,该视频描述符能够实现对视频感知内容的摘要化描述,同时具有良好的鲁棒性和区分性,可实现高效、准确的视频内容识别。
实施例2
下面结合具体的附图2和3、以及计算公式对实施例1中的方案进行详细介绍,详见下文描述:
201:将输入视频做预处理,通过条件生成模型来表达视频内容间的时空联系,并生成视频的初始描述符;
其中,该步骤201具体为:
1)在预处理环节中,首先将其视频每帧输入低通滤波器进行空间上的平滑处理,在时间上对平滑后的视频进行降采样,最后将每帧像素归一化至均值为0、方差为1。本发明实施例对低通滤波器参数不做具体限制。
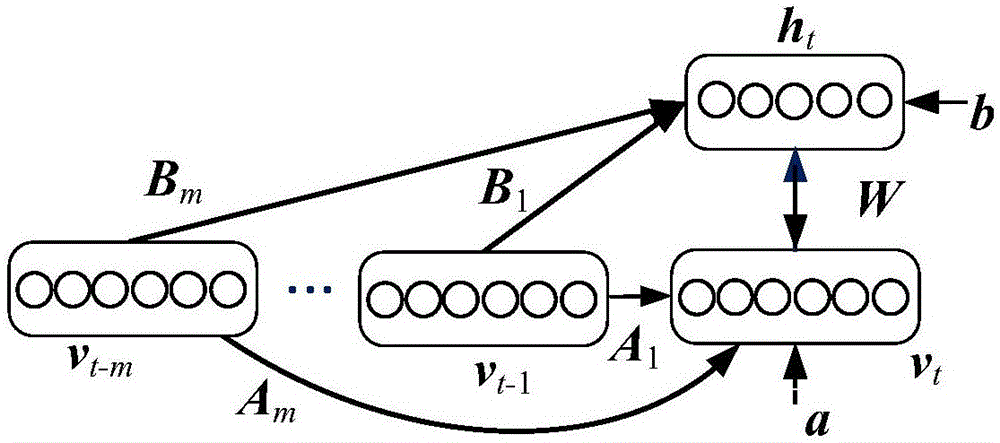
2)用条件受限Boltzmann机(Conditional Restricted Boltzmann Machine,CRBM)[9]生成视频的初始描述符。CRBM能对视频各帧间统计相关性进行建模,结构如图2所示。令当前时刻的可见层(即视频第t帧)表示为vt,第t-m帧为vt-m(m≥1)。当前时刻隐藏层为ht,可见层与隐含层权重参数为W,可见层的偏置为a,隐藏层的偏置为b,可见层前面时刻对当前时刻的权重参数为Ak,可见层前面时刻对隐藏层当前时刻的权重参数为Bk。
具体操作如下:
1、将尺寸为V1×S1×F1的视频(帧数为F1,每一帧图片大小为V1×S1)做低通滤波平滑及降采样,将每一帧图片大小压缩到V2×S2,以满足神经网络输入层尺寸需要,对帧数F1压缩到F2(F2=F1/N,即将每N帧的平均值来替代该N帧)。对降采样后尺寸为V2×S2×F2的视频做正则化,使每一帧的像素平均值为零,方差为1。该实例中选取V2=32,S2=32,F2=4。
2、将视频数据输入CRBM,令CRBM的第t帧对应的可见层为vt∈R1024,本实施例中将预处理视频的每一帧像素置为可见层的神经元。所以可见层的神经元数目为1024。
隐藏层第t帧为ht,本实例设置隐藏层神经元数目为300。CRBM网络中的可见层与隐含层权重参数W∈R1024×300,可见层的偏置a∈R1024,隐藏层的偏置b∈R300,不同时刻之间可见层的权重参数Ak∈R300×300,不同时刻之间隐藏层的权重参数Bk∈R300×1024。可通过最小化如下代价函数实现对CRBM网络的训练:
其中,LCRBM为CRBM的代价函数;p(vt|vt-1,...,vt-m)为在第t-1,…,t-m时刻的帧vt-1,...,vt-m的条件下,当前帧vt的概率值;E(vt,ht)为能量函数。
其中,k=1,…,m为序号;m为CRBM的阶数;vt-k为由第t-k帧的像素值构成的矢量;T为转置符号。本发明实施例对最小化公式(1)的方法和m的取值不做限制。
本实例选取CRBM的阶数m=3,训练视频数目为500,利用反向传导随机梯度下降算法最小化代价函数(1)。
202:训练一个去噪编码网络实现对视频的初始描述符的维数约简,将条件生成模型和编码器级联构成一组基本的特征提取模块;
其中,该步骤202具体为:
1)对每个训练视频施加失真(压缩、加噪,以及旋转等)并做预处理操作,将失真视频作为CRBM的输入,生成初始描述符。选取多组原始视频和失真视频的初始描述符作为训练数据,训练一个去噪自编码网络(Denoising Autoencoder,DAE)[10];用其对由前述CRBM生成的视频描述符进行维数约简。在训练前,分别用CRBM生成原始视频和失真视频(如原始视频经过压缩、加噪等处理后的版本)的描述符,以第n对原始和失真视频为例,令an表示原始视频的描述符,表示失真视频的描述符。训练DAE的目标是从中恢复an。
以第n对训练数据为例,令an∈R300×4表示原始视频的描述符,表示失真视频的描述符。去噪自编码网络的代价函数为:
其中,LDAE为去噪自编码网络的代价函数;λDAE为权重衰减项系数;Wi,j(l)为网络权重,表示连接第l层第i个神经元和第l+1层j个神经元的权重,E(·)为编码器,D(·)为解码器。
利用基于反向传导的随机梯度下降最小化代价函数(2),求得最优权重Wi,j(l),完成训练。本发明实施例对最小化公式(2)的方法和λDAE的取值不做限制。
本实例中去噪自编码网络的输入层和隐含层分别由300和100个神经元构成,λDAE=10-5。
2)将训练所得的编码器E(·)堆叠在CRBM之上,得到第一组特征提取模块,表示为{CRBM-E(·)}1。该特征提取模块由三层神经网络构成,结构为1024-300-100。
203:连续训练多组特征提取模块,按训练先后顺序对训练所得模块做自底向上的堆叠构成深度神经网络;
其中,该步骤203具体为:
利用上述特征提取模块{CRBM-E(·)}1的输出作为训练数据,按照上述步骤继续训练一对CRBM和编码器,用所得CRBM和编码器重新建立第二组特征提取模块,表示为{CRBM-E(·)}2。重复上述过程,依次训练多个CRBM和编码器模块,每个模块的训练数据由前一个模块的输出组成。按照训练的先后顺序将各个模块进行自底向上的堆叠,形成深度神经网络。由K个模块构成的深度神经网络可表示为:{CRBM-E(·)}1-{CRBM-E(·)}2-…-{CRBM-E(·)}K,如图3所示。本发明实施例对模块数目K的取值不做具体限制。
本实施例采用K=2,即利用两组特征提取模块进行说明。利用上述特征提取模块{CRBM-E(·)}1的输出作为训练数据,按照上述步骤继续训练一对CRBM和去噪编码器,用所得CRBM和编码器重新建立第二组特征提取模块{CRBM-E(·)}2。
本实例中,第二组CRBM的输入层和隐含层神经元数目分别为100和80,去噪自编码器的输入层和隐含层神经元数目分别为80和50,因此第二组模块的结构为100-80-50。将两组模块进行自底向上的堆叠,得到结构为1024-300-100-80-50的神经网络。
204:训练后处理网络,将其置于深度神经网络顶部,用以优化视频描述符的鲁棒性和区分性。
其中,该步骤204具体为:
1)利用由K个CRBM-E(·)模块所构成的深度神经网络为训练视频生成描述符。以第n对训练数据为例,(Vn,1,Vn,2,yn),其中Vn,1和Vn,2为两个训练视频的描述符,yn为标签(yn=+1表示两个训练视频具有相同视觉内容,yn=-1表示两视频具有不同视觉内容)。
令φ(·)为后置处理网络所定义的映射,L表示后处理网络的层数(L>1),则训练后置处理网络的代价函数如下:
其中,为网络权重,常数λPost为权重衰减项系数;Vn,1为第n对训练数据中第一个视频的描述符;Vn,2为第二个视频的描述符。最小化代价函数(3),完成训练后将该后处理单元置于由CRBM和编码器构成的深度神经网络顶层,如图3所示。本发明实施例对最小化方法和L、λPost的取值后不做限制。
利用上述2个CRBM-E(·)模块所构成的深度神经网络为训练视频生成描述符,由此构成训练后处理网络的样本。
本实例选取的训练集总共由n=4000对视觉内容相同和不同的视频对构成,其中,具有相同视觉内容的视频对由压缩、加噪和滤波等常见失真生成。
本实例选取后处理网络层数L=2,λPost=10-5,两层神经元个数分别为40和30。通过反向传导算法最小化代价函数(3),完成训练后,将置于前述由CRBM和编码器构成的深度网络顶层,得到结构为1024-300-100-80-50-40-30的特征提取网络。
综上所述,通过深度神经网将视频特征提取为简短的视频描述符,该视频描述符能够实现对视频感知内容的摘要化描述,同时具有良好的鲁棒性和区分性,可实现高效、准确的视频内容识别。
实施例3
下面结合实验数据对实施例1和2中的方案进行可行性验证,详见下文描述:
选取600个视频作为测试视频,为每个视频分别施加如下失真:
1)XVid有损压缩,将原始视频的分辨率降为320×240,帧率降为25fps,比特率降为256kps;
2)中值滤波,滤波器尺寸从10像素到20像素;
3)加高斯噪声,方差值为0.1,0.5或1;
4)旋转,旋转角度:2,5,10度;
5)直方图均值化,灰度级个数:16,32或64;
6)丢帧,丢帧百分比25%;
7)画面缩放,缩放比例:0.2,4。
依次通过上述步骤1)至步骤7)的处理,总共生成9600段失真视频。
用实施例2中所训练的深度神经网络为每个失真视频和原始视频生成特征描述符。逐个选取每个视频为查询视频,在测试库上开展内容识别实验,分别统计查准率P、召回率R以及F1指标。其中F1指标计算方法如下:
F1=2/(1/P+1/R)
测试结果表明,F1指标为0.980,接近理想值1。可知所建的深度网络能够学习到具有良好鲁棒性和区分性的视频特征,能够反映视频的本质视觉属性,在内容识别实验中具有较高的识别准确率。
参考文献
[1]C.D.Roover,C.D.Vleeschouwer,F.Lefèbvre,and B.Macq,“Robust video hashing based on radial projections of key frames,”IEEE Trans.Signal Process.,vol.53,no.10,pp.4020-4037,Oct.2005.
[2]S.Lee and C.D.Yoo,“Robust video fingerprinting for content-based video identification,IEEE Trans.Circuits Syst.Video Technol.,vol.18,no.7,pp.983-988,Jul.2008.
[3]Y.Lei,W.Luo,Y.Wang and J.Huang,“Video sequence matching based on the invariance of color correlation,”IEEE Trans.Circuits Syst.Video Technol.,vol.22,no.9,pp.1332-1343,Sept.2012.
[4]J.C.Oostveen,T.Kalker,and J.Haitsma,“Visual hashing of digital video:applications and techniques,”in Proc.SPIE Applications of Digital Image Processing XXIV,July 2001,vol.4472,pp.121-131.
[5]S.Satoh,M.Takimoto,and J.Adachi,“Scene duplicate detection from videos based on trajectories of feature points,”in Proc.Int.Workshop on Multimedia Information Retrieval,2007,237C244
[6]B.Coskun,B.Sankur,and N.Memon,“Spatio-temporal transform based video hashing,”IEEE Trans.Multimedia,vol.8,no.6,pp.1190–1208,Dec.2006.
[7]M.Li and V.Monga,“Robust video hashing via multilinear subspace projections,”IEEE Trans.Image Process.,vol.21,no.10,pp.4397–4409,Oct.2012.
[8]M.Li and V.Monga,“Twofold video hashing with automatic synchronization,”IEEE Trans.Inf.Forens.Sec.,vol.10,no.8,pp.1727-1738,Aug.2015.
[9]G.W.Taylor,G.E.Hinton,and S.T.Roweis,``Modeling human motion using binary latent variables,”in Proc.Advances in Neural Information Processing Systems,2007,vol.19.
[10]P.Vincent,H.Larochelle,I.Lajoie,Y.Bengio,P.A.Manzagol,Stacked denoising autoencoders:learning useful representations in a deep network with a local denoising criterion,"J Mach.Learn.Res.,vol.11,pp.3371-3408,Dec.2010.
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!