基于矩阵和张量联合分解的汽车推荐方法及系统与流程
本发明涉及一种基于矩阵和张量联合分解的汽车推荐方法及系统。
背景技术:
推荐问题由来已经,即按照用户与产品之间已有的信息来向用户推荐新产品或者可能购买的产品。常见的方法往往是根据用户与产品的联系,如用户的购买记录或用户的打分记录,来预测用户可能喜爱的产品来推荐给用户。在汽车领域,则会根据一个用户对某车型的打分来预测其他车型的打分情况。而这样的打分记录往往是极为稀疏的。
张量分解补全技术考虑了用户与车型之间多方面的联系,比如用户-车型-评价指标的打分,能够更好地分析三者之间的潜在联系。其主要原理是,构造一个张量,里面的值是具体的打分(1到5分),缺失值为0,利用张量中常用的CP分解来对张量进行补全,来预测缺失值的真实打分。然而,在常见的张量分解补全的过程中,并没有考虑到其他的辅助信息。
技术实现要素:
本发明的目的就是为了解决上述问题,提供一种基于矩阵和张量联合分解的汽车推荐方法及系统,它利用汽车制造商和汽车零部件供应商之间的供应关系以及按照汽车所属的车系和制造商所形成的树状层次关系来进行约束损失函数,以达到更好的预测结果。
为了实现上述目的,本发明采用如下技术方案:
一种基于矩阵和张量联合分解的汽车推荐方法,包括以下步骤:
S1、构造汽车打分张量X,构造汽车制造商与供应商关系矩阵E,构造汽车产品结构树T,汽车制造商与供应商关系矩阵E和汽车产品结构树T都是完整的,用来协助预测张量X中缺失的具体值;
S2、根据汽车产品结构树T,引入树组套索模型Tree-guided Group Lasso来对最终的损失函数进行规约,得到权重W(v);
S3、根据S1得到的汽车打分张量X、汽车制造商与供应商关系矩阵E以及S2得到的权重W(v),建立损失函数,用交替最小二乘法法ALS对损失函数进行迭代;对损失函数求导置零,然后求出矩阵A、B、C、S和M的迭代函数;
S4、矩阵A、B和C通过S3中的迭代后,通过矩阵A,B,C的外积来还原张量X,即补全张量X的缺失值;计算出迭代的RMSE和MAE,RMSE和MAE的数值越小说明预测结果越好,RMSE和MAE的数值越小说明预测数值与实际数值相差越小;
S5、判断S4中求得的RMSE是否满足设定的收敛条件或判断迭代次数是否满足设定的收敛条件,若满足则循环结束,否则返回S3;
S6、针对不同的用户,依据补全的张量X中的元素,按照打分的从高到低的次序依次给用户推荐用户喜欢的车型。
S1的步骤为:
构造汽车打分张量X,汽车打分张量维度为I×J×K,I为用户个数,J为车型数量,K为评分标准个数;
构造汽车制造商与供应商关系矩阵E;矩阵E的两个维度分别是制造商和供应商。矩阵E的维度是U×V,其中U表示制造商个数,V表示供应商个数;矩阵中的值Euv表示的是制造商u是否与供应商v存在供应关系;若等于1,则表示制造商u和供应商v之间存在供应关系。相反,若等于0,则不存在供应关系;
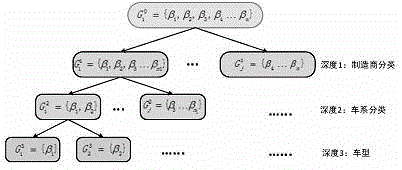
构造汽车产品结构树T;根据汽车领域中,车型-车系-制造商之间的从属关系构建出一棵树;每一个叶子节点为每个车型,中间节点为按照车型所属的车系或制造商所构成的集合,根节点为所有车型所组成的大集合;每个子节点只有一个父节点,并且同一层节点没有重叠。
S1中,汽车打分张量X中的元素表示的是用户i对车型j的评分标准k的打分;汽车打分张量X的缺失值是需要预测的;评分标准包括:空间、动力、舒适性、油耗、操控、外观、内饰和性价比。
所述树组套索模型Tree-guided Group Lasso:
其中,a代表的是汽车产品结构树T的中间节点的权重,b代表的是汽车产品结构树T叶子节点的权重;gv是中间节点所包含车型的个数、车系的打分情况和制造商评级三者的乘积,然后对乘积进行归一化,归一化到0-1之间,而sv=1-gv;GV代表的是树中的任意一个节点(可能是叶子节点,也可能是中间节点或根节点),是车型的集合;在对应矩阵B(矩阵B是张量X通过CP分解出来的第二个因子矩阵,维度是J×R,J代表车型数量,R代表张量的秩)的若干行,所述若干行所对应的车型属于树中的节点GV,||*||表示的是欧几里得范数;|*|代表的是L1范数;c是结构树T中节点v的子节点。
所述损失函数如下:
f(A,B,C,M,S)=Tensor(A,B,C)+Enterp(M,S)+Weight(B)+Manu(M,B)
其中,Tensor(A,B,C),Enterp(M,S),Manu(M,B),Weight(B)分别为:
其中,所涉及到的A、B和C是张量X通过CP分解出来的因子矩阵,维度分别为I×R,J×R,K×R,其中R为张量的秩;CP的英文全称是:CANDECOMP/PARAFAC decomposition;
M和S为矩阵E通过矩阵分解出来的因子矩阵,维度分别为U×R,V×R,Bk代表的矩阵B的第k行,其中,0≤k<J;λT是函数Tensor(A,B,C)的正则化参数,λE是函数Enterp(M,S)的正则化参数、λM是函数Manu(M,B)的正则化参数、λW是函数Weight(B)的正则化参数。A||F、||B||F、||C||F分别对应着矩阵A,B,C的F-范数。Mj表示的是矩阵M的第j列,其中0≤j<U,即制造商j的特征向量。代表的是第一层的第j个节点,即j个叶子节点;
代表的是汽车产品结构树T第i层第j个集合,是汽车产品结构树T第i层第j个集合的权重,X(2)是张量X按照2阶展开mode-2展开,λ是正则化参数,⊙表示Khatri-Rao乘积。
对矩阵E和张量X进行联合分解,并使得Mj和差值最小,即对应约束函数Manu(M,B);对张量X分解采用CP分解,对矩阵分解采用基本的矩阵分解E=M×ST。
矩阵A、B、C、S和M的迭代函数:
C=(X(3)(B⊙A))(BTB*ATA+λTIR)-1
S=ETM(MTM+λEIR)-1
X(1)代表张量X按照1阶展开mode-1展开;X(2)代表张量X按照mode-2展开;X(3)代表张量X按照mode-3展开;IR代表的是R×R的单位矩阵;AT、BT、CT、ET、MT、ST表示矩阵A、B、C、E、M、S的转置。
所述计算出迭代的RMSE和MAE:
是张量原先缺失值的预测结果,而yi是张量原先缺失值的真实结果,n代表的是缺失值的总数。
所述S5设置迭代次数为50次,并设置RMSE为0.7,当迭代次数超过50或者RMSE低于0.7的时候,则停止循环。
一种基于矩阵和张量联合分解的汽车推荐系统,包括:
构造单元:用于构造汽车打分张量X,构造汽车制造商与供应商关系矩阵E,构造汽车产品结构树T,汽车制造商与供应商关系矩阵E和汽车产品结构树T都是完整的,用来协助预测张量X中缺失的具体值;
规约单元:用于根据汽车产品结构树T,引入树组套索模型Tree-guided Group Lasso来对最终的损失函数进行规约,得到权重W(v);
损失函数建立单元:用于根据汽车打分张量X、汽车制造商与供应商关系矩阵E以及权重W(v),建立损失函数,用交替最小二乘法法ALS对损失函数进行迭代;对损失函数求导置零,然后求出矩阵A、B、C、S和M的迭代函数;
张量还原单元:矩阵A、B和C通过迭代后,通过矩阵A,B,C的外积来还原张量X,即补全张量X的缺失值;计算出迭代的RMSE和MAE,RMSE和MAE的数值越小说明预测结果越好,RMSE和MAE的数值越小说明预测数值与实际数值相差越小;
判断单元:用于判断求得的RMSE是否满足设定的收敛条件或判断迭代次数是否满足设定的收敛条件,若满足则循环结束,否则返回损失函数建立单元;
推荐单元:用于针对不同的用户,依据补全的张量X中的元素,按照打分的从高到低的次序依次给用户推荐用户喜欢的车型。
构造单元包括:
汽车打分张量构造模块,用于构造汽车打分张量X,汽车打分张量维度为I×J×K,I为用户个数,J为车型数量,K为评分标准个数;
关系矩阵构造模块,用于构造汽车制造商与供应商关系矩阵E;矩阵E的两个维度分别是制造商和供应商;矩阵E的维度是U×V,其中U表示制造商个数,V表示供应商个数;矩阵中的值Euv表示的是制造商u是否与供应商v存在供应关系;若等于1,则表示制造商u和供应商v之间存在供应关系。相反,若等于0,则不存在供应关系;
汽车产品结构树构造模块,用于构造汽车产品结构树T;根据汽车领域中,车型-车系-制造商之间的从属关系构建出一棵树;每一个叶子节点为每个车型,中间节点为按照车型所属的车系或制造商所构成的集合,根节点为所有车型所组成的大集合;每个子节点只有一个父节点,并且同一层节点没有重叠。
树组套索模型是一种基于正则化方法的能够同时实现稀疏特征变量选择和模型参数估计的方法。有时样本的多个特征变量之间存在组结构,把输入变量之间的组结构作为先验信息,提出了组套索模型。许多数据不但具有组结构,而且组之间存在偏序关系,即树结构。当处理这种数据时,需要充分利用树结构作为先验信息,利用上述先验信息得到的树组套索模型
本发明的有益效果:
1充分利用汽车与其所属车系、制造商之间的结构关系以及制造商与供应商之间的耦合关系,实现汽车选购的推荐方法;
2本发明在利用张量补全进行打分预测的过程中增加对产品潜在的结构以及制造商和供应商之间的供应关系的考虑,可以较为明显的提高打分预测的准确度。从均方根误差(RMSE)和平均误差(MAE)两个指标上可以看出,本发明提供的模型较其他常见方法有较大提升。
3在汽车领域,我们可以根据车型-车系-制造商之间的树形层次结构以及制造商和供应商之间的供应关系,来帮助预测用户关于某个车型的评分指标的打分,即张量中的缺失值。
因为往往用户在购买汽车车型或者给汽车评分的时候,会考虑一个车型所属的车系,厂商以及汽车零部件的供应商。最终按照预测出来的用户对于车型指标的打分,将打分较高的车型推荐给用户。
附图说明
图1为本发明提供的树引导的多关系张量分解模型流程图。
图2(a)为张量X;
图2(b)矩阵E;
图2(c)结构树T;
图3为汽车领域数据集上RMSE和MAE的实验对比结果。
图4为探究汽车供应链对于本方法在汽车领域的影响。
图5为探究由汽车车型类别关系所组成结构树深度对于该方法的影响。
具体实施方式
下面结合附图与实施例对本发明作进一步说明。
本发明提供了一种基于矩阵和张量联合分解的方法,并利用制造商和供应商之间的供应关系以及车型按照所属的车系、制造商所形成的树状层次关系来进行约束。如图1所示,包括以下步骤:
Step1、构造张量X,矩阵E和树T,如图2(a)-图2(c)所示;
Step1.1、构造张量X,张量的三个维度是用户-车型-评分标准。张量X中的用户必须是评论过至少一辆车的所有属性,同样的,其中的车型必须被至少一个用户打过分。评分标准有8个,分别为:空间、动力、舒适性、油耗、操控、外观、内饰和性价比。Xijk表示的是用户i对车型j的评价指标k打分,其打分区间为1到5.用户对这些评分标准进行1-5分的打分。张量X∈RI×J×K,I为用户个数,J为车型数量,k为评分标准,即数量为8.
Step1.2、构造矩阵E,矩阵E的两个维度分别是制造商和供应商。矩阵E∈RU×V,其中U表示制造商个数,V表示供应商个数。矩阵中的值Euv表示的是制造商u是否与供应商v存在供应关系。若Euv等于1,则表示制造商u和供应商v之间存在供应关系。相反,若等于0,则不存在供应关系。
Step1.3、构造结构树T,根据汽车领域中,车型-车系-制造商之间的从属关系可以构建出一棵树。每一个叶子节点为每个车型,如2017款320Li M运动型。中间节点为按照车型所属的车系或制造商所构成的集合,例如2017款320Li M运动型属于宝马3系,宝马3系是由宝马公司制造。根节点为所有车型所组成的大集合。
另外,算法运行前矩阵E和结构树T都是完整的,用来协助预测张量中缺失的具体值。
Step2、据树T计算每个车型v的权重W(v)。
根据S1中产品所产生的结构树T,每个子节点只有一个父节点,并且同一层节点没有重叠,因为一个车型有且只属于一个车系,一个车系有且只属于一个制造商。基于这种异构信息我们引入tree-guided group lasso来对最终的损失函数进行规约,其约束函数为:
这里的λW是代表函数Weight(B)的正则化参数,Bk表示的是矩阵B的第k行,对应着第k个车型,代表的是结构树第i层第j个集合,是对应该集合的权重。
其中(a)代表的是树的中间节点的权重值,(b)代表的是叶子节点的权重,gv是由节点包含车型的个数以及其所属车系和制造商的rank值所决定,而sv=1-gv。在对应矩阵B的若干行,这些行所对应的车型属于树中的节点GV,|*|表示的是L1范数,||*||表示的是欧几里得范数。
Step3、整个模型的损失函数为:
f(A,B,C,M,S)=Tensor(A,B,C)+Enterp(M,S)+Weight(B)+Manu(M,B)
这里面涉及到的Tensor(A,B,C),Enterp(M,S),Manu(M,B),Weight(B)为:
其中所涉及到的A,B,C是张量X分解出来的因子矩阵,维度分别为I×R,J×R,K×R,其中R为张量的秩。M、S为矩阵E分解出来的因子矩阵,维度分别为U×R,V×R,Bk代表的矩阵B的第k行,Mj代表矩阵M的第j行。X(2)是张量X按照模2展开,λ是对应不同函数的正则化参数,⊙表示Khatri-Rao乘积。
Step4、用交替最小二乘法法(ALS)对损失函数进行迭代
对矩阵E和张量X进行联合分解,并使得尽量相近,即Manu(M,B)。对张量X分解我们采用CP分解,对矩阵分解采用基本的矩阵分解。使Step3中的损失函数对矩阵A,B,C,M,S求偏导,然后使偏导等于零。可以求得矩阵A,B,C,M,S的迭代函数:
C=(X(3)(B⊙A))(BTB*ATA+λTIR)-1
S=ETM(MTM+λEIR)-1
其中是X(n)代表张量X按照mode-n展开,IR代表的是R×R的单位矩阵。代表的是第一层的第j个节点,即j个叶子节点。代表矩阵B中除k之外的其他行。
Step5、矩阵A,B,C经过上述的迭代之后,可以通过来还原张量X,即补全之前的缺失值。根据一下的计算方法可以计算出此次迭代的RMSE和MAE,RMSE和MAE的数值越小说明预测结果越好,预测数值与实际数值相差越小。
这里的代表是对张量原先缺失值的预测结果,而yi是张量原先缺失值的真实结果。这里的n代表的是缺失值的总数。
Step6、判断每次迭代之后求得的RMSE或迭代次数是否满足设定的收敛条件,若满足则循环结束,否则继续迭代。
设置迭代次数为50次,并设置RMSE为0.7,当迭代次数超过50或者RMSE低于0.7的时候,则停止循环。
Step7、针对不同的用户,我们按照预测出来的结果,按照打分的从高到低的次序依次让用户推荐车型。
如图3-图5所示,本发明提供的在汽车领域的推荐方法与现有技术中的各算法相比,均方根误差(RMSE)和平均误差(MAE)更小,预测的准确度越高,较之现有技术都有较大的提升。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!